经典文献阅读之--Vision-based Large-scale 3D Semantic Mapping...(自动驾驶的大规模三维视觉语义地图的构建)
0. 简介
3D语义信息地图的构建对于构建地图来说非常关键,所以《Vision-based Large-scale 3D Semantic Mapping for AutonomousDriving Applications》一文提出了一种完整的流程,基于立体相机系统实现的3D语义地图构建,该流程包括直接稀疏视觉里程计前端以及全局优化的后端,包括GNSS集成和语义三维点云标记。我们提出了一种简单但有效的时间投票方案,改善了3D点云标记的质量和一致性,并对KITTI-360数据集进行了定性和定量评估。
1. 主要贡献
目前的状态是除了在线感知之外,环境模型通过静态道路设施的拓扑信息来进行补充,HD地图可以提供冗余丰富的信息,以支持在线传感器数据,然而,由于道路基础设施的快速变化,特别是在城市环境中,保持这类地图的实时性非常重要。因此,与昂贵的建图传感器和手动标注过程相比,轻量级且可扩展的在线建图流程变得更加受青睐。文中流程仅通过立体视觉系统生成大规模的3D语义地图,如图2所示。
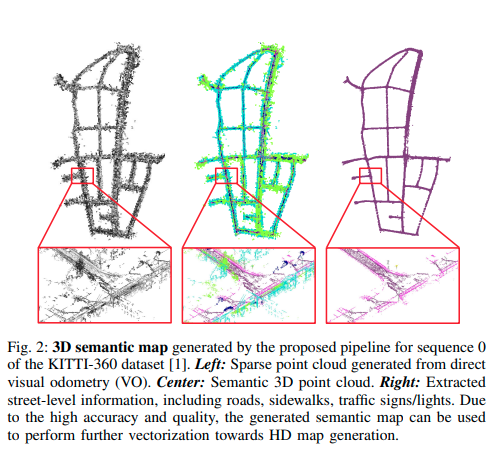
图2:由所提出的流程生成的KITTI-360数据集[1]序列0的3D语义地图。左侧:由直接视觉里程计(VO)生成的稀疏点云。中间:语义3D点云。右侧:提取的街道级别信息,包括道路、人行道、交通标志/信号灯。由于高精度和高质量,生成的语义地图可用于进一步进行向高清地图生成的矢量化处理。
我们相信所提出的流程展示了纯视觉化建图系统在自动驾驶应用中的潜力,并可以扩展到提取车道标线等信息,尽管目前尚未提供完全矢量化的高精地图,图1展示了我们的方法可以基于车队创建城市规模的地图。
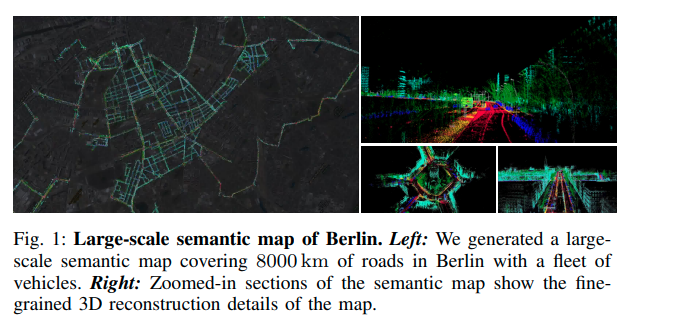
图1:柏林的大规模语义地图。左图:我们使用一支车队在柏林的8000公里道路上生成了一张大规模的语义地图。右图:放大的语义地图部分展示了地图的精细的3D重建细节。
我们的具体贡献如下:
? 一个完全自动的基于视觉的3D建图流程,能够高效地创建大规模的3D语义地图。
? 一个简单而有效的时间一致的点标记方案,通过考虑视觉里程计前端提供的结构信息,提高了3D点标记的准确性。
? 一个用于基于视觉的3D语义地图流程的基准,融合了3D激光雷达和2D图像的地面真值标签。
2. 大规模三维语义建图
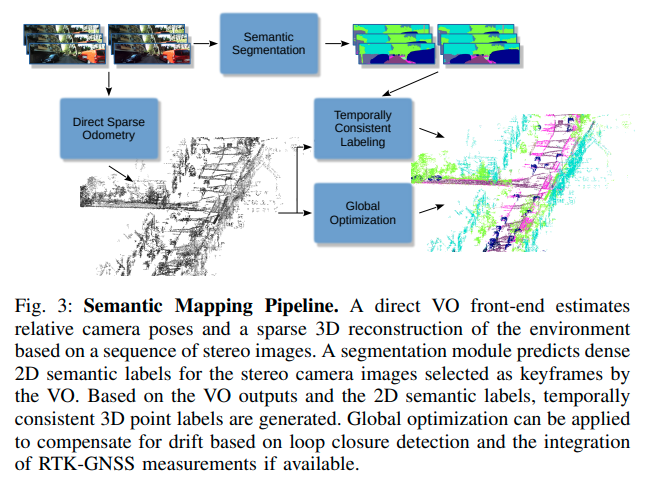
所提出的三维语义建图系统仅利用立体图像和可选的传感器数据,如GNSS(全球导航卫星系统)用于全球定位和IMU测量。图3显示了我们语义建图流程的概述。我们的流程中的直接视觉里程计模块估计相机的相对姿态和环境的稀疏三维重建(第2.1节)。基于闭环检测,进行全局地图优化。如果可用,RTK-GNSS测量将被整合以获得地理参考和全局精确的地图。我们使用最先进的语义分割网络(第2.2节)为VO前端定义的关键帧对应的立体图像的每个像素生成准确的语义标签。此外,我们的时间一致标注模块可以基于VO输出和2D语义标签生成时间一致的三维点标签(第2.3节)。当利用GNSS数据将三维重建提升到全球地理参考框架时,可以通过将车队的重建拼接在一起创建城市规模的地图,如图1所示。
2.1 视觉里程计和三维建图
所提出的语义建图流程的核心是一种先进的视觉SLAM算法。为了提供关于三维环境的丰富信息,需要对周围环境进行详细的重建,达到一定的密度水平。所提出的语义建图流程依赖于直接SLAM前端进行三维地图生成,与间接(基于关键点)SLAM方法相比,提供了更密集和更详细的环境重建。 具体而言,我们采用了一种直接稀疏SLAM公式,该公式适用于立体图像,正如[19]中所提出的。在局部光度束调整中,同时估计了六自由度(6DoF)姿态和稀疏的环境三维重建,并根据光度能量函数进行优化。

在等式(1)中, F F F是优化窗口中所有关键帧的集合, P i P_i Pi?是托管在关键帧 i i i中的稀疏点集。点 p ∈ P i p ∈ P_i p∈Pi?由其在图像中的固定2D像素位置和在优化过程中估计的逆深度d定义。 o b s t ( p ) obs^t(p) obst(p)定义了点 p p p在优化窗口中所有其他关键帧的左图像上的投影。此外, E i s p E^p_{is} Eisp?定义了基于点 p p p在相应右图像中的投影的附加光度能量项。有关详细信息,请参阅[18],[19]。
此外,如果可用,我们的视觉里程计系统还能够紧密集成来自惯性测量单元(IMU)的惯性测量,如[62]所述。通过将视觉里程计输出与GNSS测量融合,并进行闭环检测,可以获得全局一致的3D地图。总体而言,我们流水线中使用的建图前端与[7]中提出的类似。
2.2 语义分割
语义分割在我们的流程中起着重要的作用,它为我们的语义点云质量奠定了基础。由于已经有了丰富的优秀作品,我们基于它们构建了我们的流程。由于我们的流程具有模块化的特点,语义分割组件仅消耗图像,因此与流程的其他部分无关。因此,任何最先进的方法都可以集成到我们的流程中。 在本文中,我们基于[50]构建我们的流程。[50]中提出的方法在KITTI语义分割基准[63]中的所有开源提交中表现最佳。它通过使用联合图像-标签传播模型生成的合成样本来扩充训练集,并采用边界标签放松策略使模型对噪声边界具有鲁棒性,从而实现了最先进的性能。 在我们的流程中,语义分割模块为VO模块定义的关键帧对应的立体相机图像对预测出全分辨率的语义地图,然后将连续的地图输入到时间一致的标记模块中(第2.3节)。
2.3 时间一致性标签(重点工作)
尽管过去几年中,基于图像的语义分割的深度神经网络(DNNs)取得了显著的改进,但这些网络仍然存在预测标签中的噪声以及在时间序列图像的估计中的时间不一致性的问题。一方面,由于透视成像过程,物体的外观通常会发生显著变化。另一方面,DNNs的预测能力仍在发展中,因此往往会出现不完美的估计和时间上的不一致性。
然而,对于自动驾驶任务来说,人们通常更关注时间上一致的三维语义标签,而不是图像空间中的二维标签。因此,我们提出了一种简单但有效的方案,仅通过图像来获得准确且一致的三维标签。
如第2.1节所述,我们的直接稀疏VO系统[18],[19]生成一组稀疏点 P : = { P 0 , P i , ? ? ? , P N } P := \{P_0,P_i,···,P_N\} P:={P0?,Pi?,???,PN?}来定义三维重建。这里的点 p ∈ P i p ∈ P_i p∈Pi?由其所在关键帧 i ∈ F i ∈ F i∈F 中的像素坐标 ( u , v ) (u,v) (u,v) 以及相应的逆深度 d d d 定义。因此,可以使用相应的关键帧姿态 ξ i ∈ s e ( 3 ) ξ_i ∈ se(3) ξi?∈se(3)将点投影到全局三维坐标系中。一般来说,跟踪的点被视为彼此之间统计独立。此外,点选择方案避免了在不同帧中托管的多个图像点对应于同一对象点。
在第3.2节中描述的分割过程中,序列的各个图像被视为彼此独立。而直接VO前端隐式地建立了连续图像之间的对应关系,如公式(1)所定义。因此,我们可以利用这些对应关系来提高三维点标签的质量。类似于公式(1)中的光度能量公式,我们将每个点 p ∈ P i p ∈ P_i p∈Pi?从其所在关键帧i投影到邻域中所有其他关键帧 j j j对应的左图像,以生成与该点对应的一组共视点。我们还将这组左图像点投影到它们各自的右图像,以获得另一组对应点。左右图像流中的两组点构成最终的共视点集。然后,我们为每个点 p p p定义一组 C C C个投票 V : = { v 1 , v 2 , ? ? ? , v C } V := \{v_1,v_2,···,v_C\} V:={v1?,v2?,???,vC?},其中 v c v_c vc?是基于所有共视点对于一个语义类别 c c c的权重 w j w_j wj?累积的投票, C C C是类别的总数。

这里 Q Q Q是所有可见点的集合,包括点 p p p本身, d j d_j dj?是点 q j q_j qj?的逆深度, L j L_j Lj?是对应于关键帧 j j j的二维语义地图。 d i s t m i n dist_{min} distmin?定义了一个最小物体距离。通过利用逆深度 d j d_j dj?作为相应投票的加权因子,我们考虑到相机远离的点的预测通常比靠近的点不准确。与此同时,非常靠近物体的图像区域通常会受到显著的运动模糊和强烈的透视畸变的影响,这也导致了不准确的预测。在投票过程中,通过设置最小距离阈值 d i s t m i n dist_{min} distmin?来考虑这一点。
基于集合 V V V,点 p p p被赋予最高权重的标签。
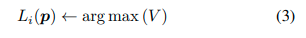
通过考虑时间语义分割信息,可以获得点标签。由于视觉里程计前端仅提供稀疏的点集,因此仅为该点集提供了时间上一致的标签。
2.4 语义化的三维点云生成
我们流程的最后一步是生成带有语义标签的三维点云。基于第2.2节和第2.3节中介绍的模块,我们能够为由视觉里程计(第2.1节)生成的点赋予语义标签。最后,这些带有标签的二维点被投影到三维空间,并转换为一个全局一致的三维框架,形成一个稀疏的三维语义地图,如图2所示。
…详情请参照古月居
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!