数据库基础(超详细版)
目录
简介:
数据库(DataBase,DB):指长期保存在计算机的存储设备上,按照一定规则组织起来,可以被各种用户或应用共享的数据集合。
数据库管理系统(DataBase Management System,DBMS):指一种操作和管理数据库的大型软件,用于建立、使用和维护数据库,对数据库进行统一管理和控制,以保证数据库的安全性和完整性。
用户通过数据库管理系统访问数据库中的数据。
数据库软件应该为数据库管理系统,数据库是通过数据库管理系统创建和操作的。
数据库:存储、维护和管理数据的集合。
三大范式:
第一范式:无重复的列。当关系模式R的所有属性都不能在分解为更基本的数据单位时,称R是满足第一范式的,简记为1NF。满足第一范式是关系模式规范化的最低要求,否则,将有很多基本操作在这样的关系模式中实现不了。
第二范式:属性完全依赖于主键 [ 消除部分子函数依赖 ]。如果关系模式R满足第一范式,并且R得所有非主属性都完全依赖于R的每一个候选关键属性,称R满足第二范式,简记为2NF。第二范式(2NF)是在第一范式(1NF)的基础上建立起来的,即满足第二范式(2NF)必须先满足第一范式(1NF)。第二范式(2NF)要求数据库表中的每个实例或行必须可以被唯一地区分。为实现区分通常需要为表加上一个列,以存储各个实例的唯一标识。这个唯一属性列被称为主关键字或主键、主码。
第三范式:属性不依赖于其它非主属性 [ 消除传递依赖 ]。设R是一个满足第一范式条件的关系模式,X是R的任意属性集,如果X非传递依赖于R的任意一个候选关键字,称R满足第三范式,简记为3NF. 满足第三范式(3NF)必须先满足第二范式(2NF)。第三范式(3NF)要求一个数据库表中不包含已在其它表中已包含的非主关键字信息。(eg:第一张表是学生表,主要信息为姓名,次要信息为成绩,那么其他的表中,就不能包含成绩。)
注:关系实质上是一张二维表,其中每一行是一个元组,每一列是一个属性
第二范式(2NF)和第三范式(3NF)的概念很容易混淆,区分它们的关键点在于,2NF:非主键列是否完全依赖于主键,还是依赖于主键的一部分;3NF:非主键列是直接依赖于主键,还是直接依赖于非主键列。
sql语句分类:
- DDL(Data Definition Language):数据定义语言,用来定义数据库对象:库、表、列等。
- DML(Data Manipulation Language):数据操作语言,用来定义数据库记录(数据)增删改。
- DCL(Data Control Language):数据控制语言,用来定义访问权限和安全级别。
- DQL(Data Query Language):数据查询语言,用来查询记录(数据)查询。
注意:sql语句以;结尾
mysql中的关键字不区分大小写
DDL操作数据库:
DDL是用来增加、删除、修改数据库中的表的操作。
在cdm窗口,先找到数据库的路径:
如:我的路径:D:\mysql\mysql-8.0.28-winx64\bin
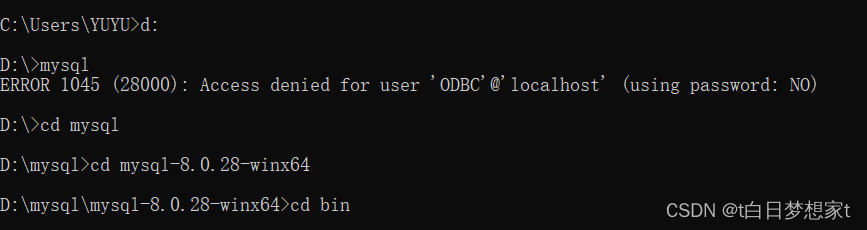
?打开后,登录数据库:
mysql -u root -p
登录成功后:
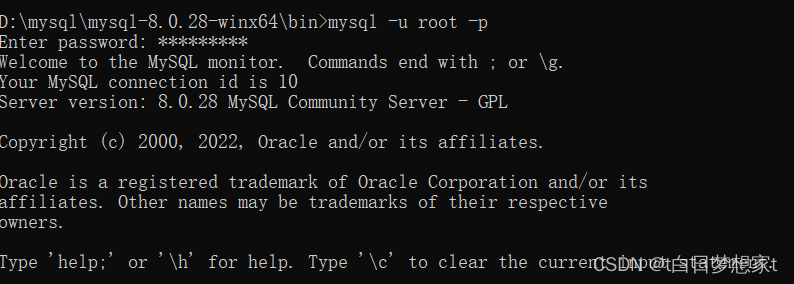
?创建数据库的命令:
?create database?语句用于创建新的数据库
如何验证是否创建成功呢?
查看数据库:
?show databases;用来查看所有数据库
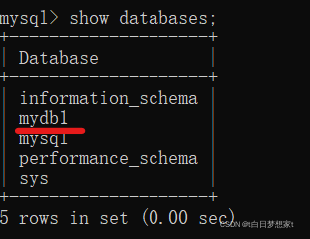
创建成功(其余的数据库都是在安装过程中默认创建好的,不能删除!)
?修改数据库:
alter database 数据库名 character set 编码方式

删除数据库:?
drop database?数据库名;

再次显示所有数据库:
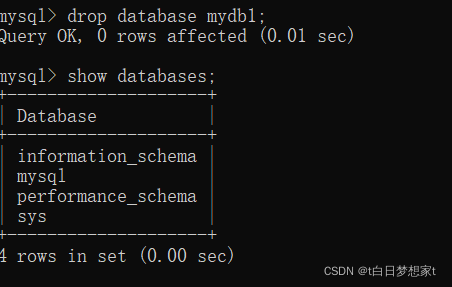
可以看到mydb1已经删除了。
查看当前使用的数据库 :
Select database();?
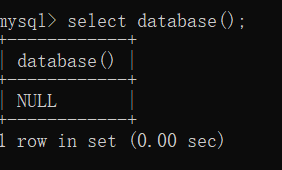
当前未链接数据库。
那么我们来连接一个数据库:?
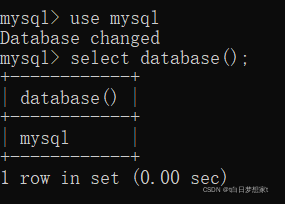
连接后显示当前数据库,即连接成功。
创建数据表:
CREATE TABLE 表名(
列名1 数据类型 [约束],
列名2 数据类型 [约束],
列名n 数据类型 [约束]
);?
注意:表名,列名是自定义,多列之间使用逗号间隔,最后一列的逗号不能写
[约束] 表示可有可无。
(常用数据类型:
int:整型
double:浮点型,例如double(5,2)表示最多5位,其中必须有2位小数,即最大值为
999.99;默认支持四舍五入
char:固定长度字符串类型; char(10) 'aaa ' 占10位
varchar:可变长度字符串类型; varchar(10) 'aaa' 占3位
text:字符串类型,比如小说信息;
blob:字节类型,保存文件信息(视频,音频,图片);
date:日期类型,格式为:yyyy-MM-dd;
time:时间类型,格式为:hh:mm:ss
timestamp:时间戳类型 yyyy-MM-dd hh:mm:ss 会自动赋值
datetime:日期时间类型 yyyy-MM-dd hh:mm:ss)
我们创建一个新的数据库来创建数据表:数据库yhp
显示当前数据库:
?创建数据表:列有:name,age,sex。

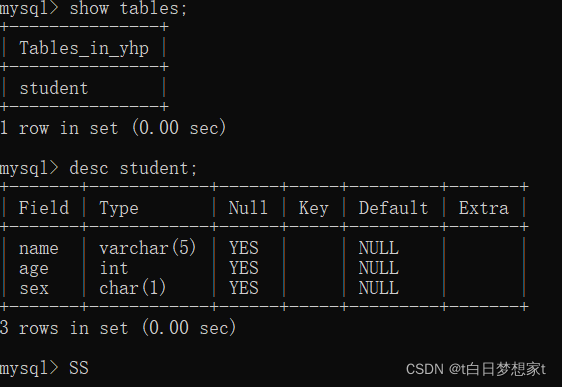
查看表:?show?tables;
查看列信息:desc student;
?
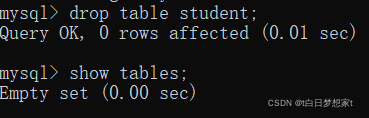
?删除表:drop table student;
?删除后再次查看即为空。
?修改数据表(刚刚删除的学生数据表已重新创建):
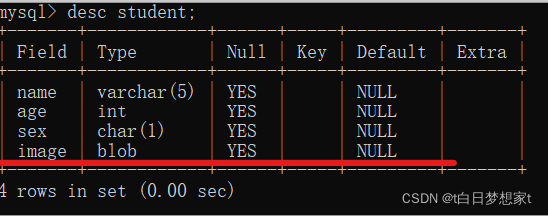
1、添加列:alter table 表名 add 新列名 新的数据类型?

添加成功:
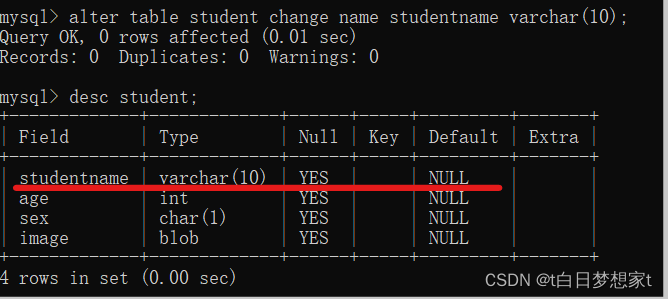
2、修改列:alter table 表名 change 旧列名 新列名 新的数据类型?
将name?修改为studentname:
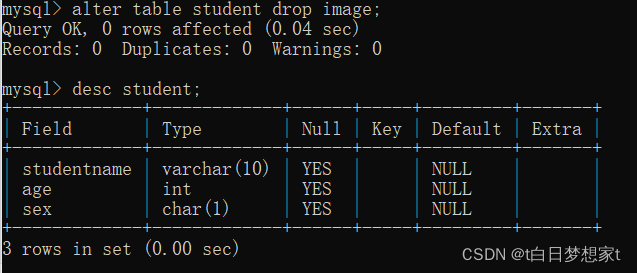
?3、删除列:alter table 表名 drop 列名
删除image:
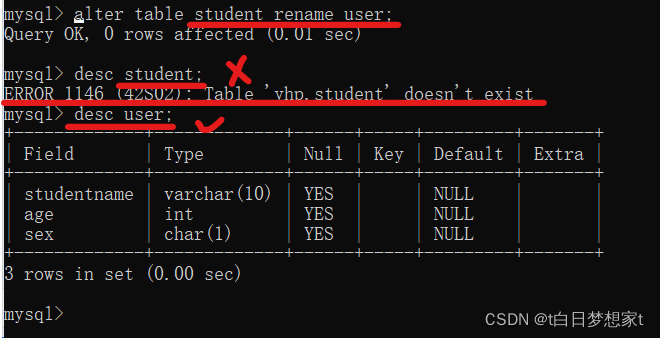
4、修改表名:alter table 旧表名 rename 新表名;?
将student改为user:?
?5、查看表格的创建细节:
show create table 表名;
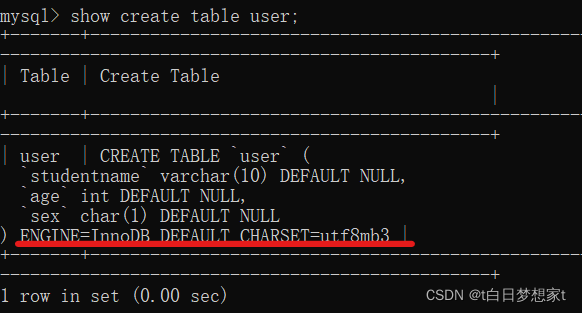
可以看到创建表的语句,还有默认的引擎为utf8;?
6、修改字符集:(若已经是utf8,就最好不要随便修改)
alter table 表名 character set 编码方式。
DML操作:?
DML是对表中的数据进行增insert、删delete、改update的操作。
?还是在原始的student中演示:
1、插入操作?insert:
insert into 表名(列名) values(数据值);
eg:insert into student(stuname,stuage,stusex,birthday) values('小白',18,'a','2002-6-9');
注意:1多列和多个列值之间使用逗号隔开?
????????2.列名要和列值一一对应?
????????3.非数值的列值两侧需要加单引号
?在表中插入数据:?

?注意:?添加数据的时候可以将列名省略,但是!必须是当给所有列添加数据的时候才可以。
此时列值的顺序按照数据表中列的顺序执行。
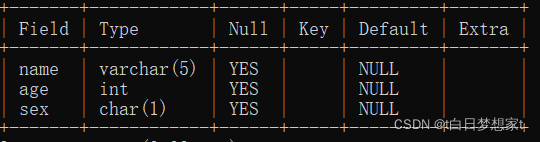
?此时,表中的列顺序为name?age?sex。所以我们添加的顺序也必须是?name?age?sex

注意:也可以同时添加多行 :
insert into 表名(列名) values(第一行数据),(第二行数据),(),();

如图提示,4rows(即四行添加成功)
查询所有数据:select *from?表名:?
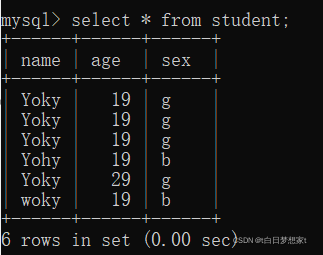
总结:列名与列值的类型、个数、顺序要一一对应。
参数值不要超出列定义的长度。
如果插入空值,请使用null
插入的日期和字符一样,都使用引号括起来。?
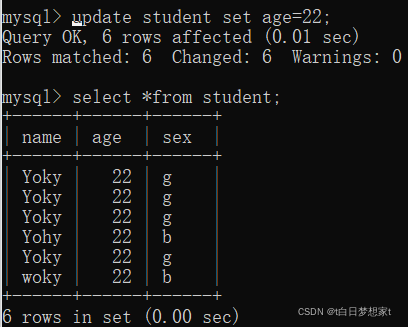
2、修改(更新)操作:update:
update 表名?set?列名1=列值1,列名2=列值2 ...?where?列名=值 (不需要限定即全改的话就不用where)
将所有age改为22:?
?限定:限定语句也可以为多条,每条之间用逗号隔开。
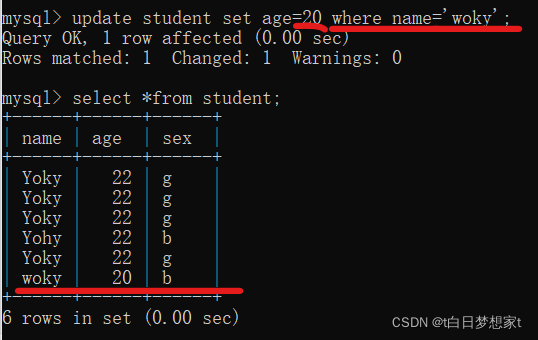
改一行的多列:
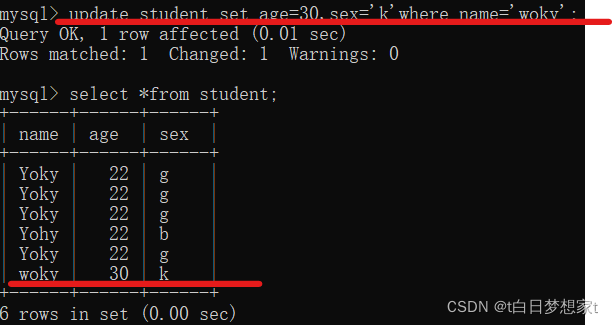
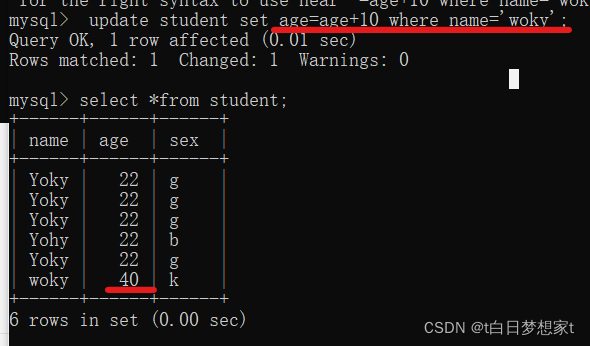
?在woky的age上加10:
sql中的运算符:
(1)算术运算符:+,-,*,/(除法),求余(%)
示例:
????????5/2
????????5%2
????????2/5
????????2%5
(2)赋值运算符:=
?注:赋值方向:从右往左赋值
示例: name='张三'
(3) 逻辑运算符:
and(并且),or(或者),not(取非)
作用:用于连接多个条件时使用
(4) 关系运算符:
>,<,>=,<=,!=(不等于),=(等于),<>(不等于)
补充:
等于空:xxx = ' '或者写xxx?is null;
如果一列做判断时有两个值:eg:年龄既不是19也不是20应该怎么写?
应该写成:age!=19?or age !=20.而不能写成:age!=19?or 20.这就错了!
?3、删除:delete:可以删除全部,也可以删除某一条或某一部分。
?delete?from 表名 【where?列名=值】 (where同为限定作用)
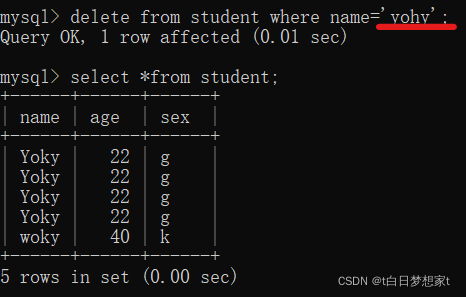
删除表中所有信息:表中信息没了,但是表还在!
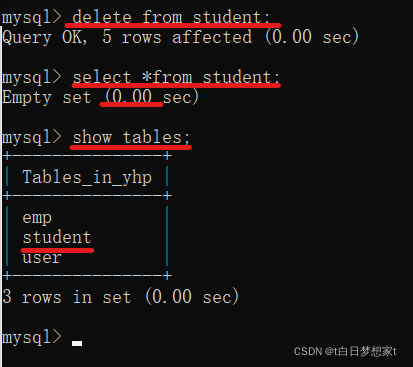
?第二种删除:truncate?table?表名;
与delete的区别:?DELETE 删除表中的数据,表结构还在;删除后的数据可以找回
- TRUNCATE 删除是把表直接DROP掉,然后再创建一个同样的新表。
- 删除的数据不能找回。执行速度比DELETE快。
?DCL
dcl是用来设置或更改数据库用户或角色权限的语句。
创建用户:有三种方法:
一、create user 用户名@指定ip identified by 密码;
在此处,我们创建一个用户名为:yhpa的用户,localhost为本机ip。密码:abc
二、create user 用户名@客户端ip identified by 密码; 指定IP才能登陆
eg:create user test456@10.4.10.18 IDENTIFIED by 'test456'
三、create user 用户名@‘% ’ identified by 密码 任意IP均可登陆 (通常用于给团队其他成员授权)
eg:create user test7@'%' IDENTIFIED by 'test7'?
给用户授权:
一、给指定的用户授予指定的数据库里的所有的表的指定的权限。
grant 权限1,权限2,........,权限n on 数据库名.* to 用户名@IP;? (其中的数据库名
.*的意思就是这个数据库中的所有表)
在此处我们授予ypha用户yhp数据库的增删改查权限。?

?二、给指定的用户授予所有的数据库中的所有的表的所有权限
grant all on *.* to?用户名@IP;?
用户查询权限:show grants for 用户名@IP;?
查询yhpa的权限??
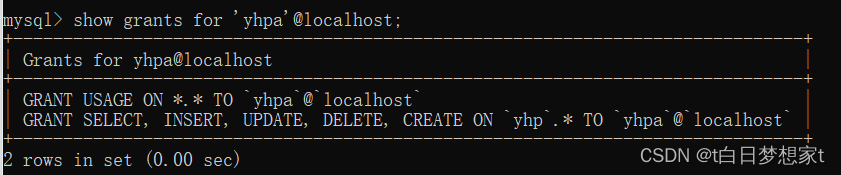
?撤销用户权限:revoke 权限1,权限2,........,权限n on 数据库名.* from 用户名@IP;?
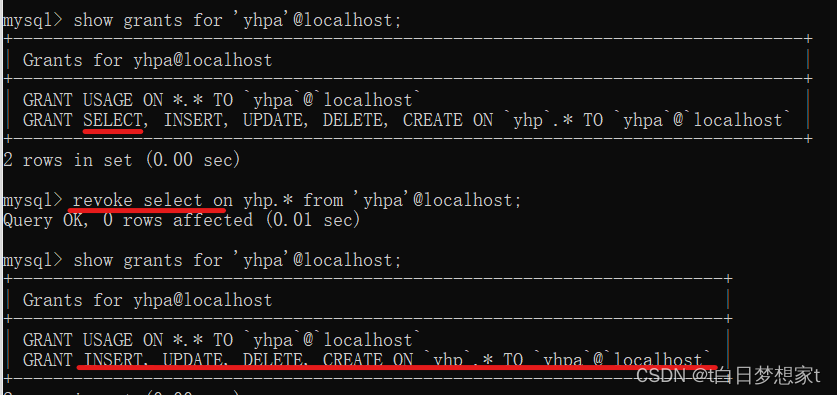 ?由此易见删除了select?查找权限?。
?由此易见删除了select?查找权限?。
删除用户:drop user 用户名@IP;

检查一下是否删除了:
先退出,再重新用yhpa登录:结果显示不存在!

?DQL
?DQL是数据库查询语言。(重要)
?数据库执行DQL语句不会对数据进行改变,而是让数据库发送结果集给客户端。查询返回的结果是一张虚拟表。
查询关键字:SELECT
语法: SELECT 列名 FROM 表名 【WHERE --> BROUP BY-->HAVING--> ORDER BY】
*?代替列明表示所有列。
| 关键字 | 作用 |
| SELECT ? | 要查询的列名称 |
| FROM ? | 表名称 |
| WHERE | 限定条件 /*行条件*/ |
| GROUP BY grouping_columns | /*对结果分组*/ |
| HAVING condition | /*分组后的行条件*/ |
| ORDER BY sorting_columns | /*对结果分组*/ |
| LIMIT offset_start, row_count | /*结果限定*/ |
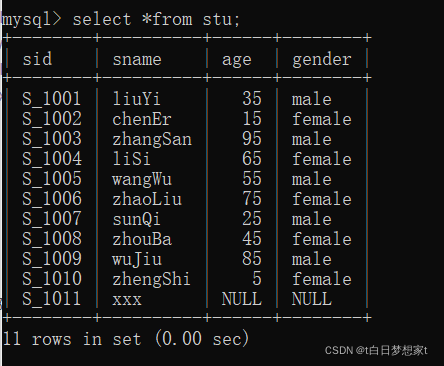
?此处我们创建一个学生表并添加数据:
#创建表stu
CREATE TABLE stu (
sid CHAR(6),
sname VARCHAR(50),
age INT,
gender VARCHAR(50)
);
#添加数据
INSERT INTO stu VALUES('S_1001', 'liuYi', 35, 'male');
INSERT INTO stu VALUES('S_1002', 'chenEr', 15, 'female');
INSERT INTO stu VALUES('S_1003', 'zhangSan', 95, 'male');
INSERT INTO stu VALUES('S_1004', 'liSi', 65, 'female');
INSERT INTO stu VALUES('S_1005', 'wangWu', 55, 'male');
INSERT INTO stu VALUES('S_1006', 'zhaoLiu', 75, 'female');
INSERT INTO stu VALUES('S_1007', 'sunQi', 25, 'male');
INSERT INTO stu VALUES('S_1008', 'zhouBa', 45, 'female');
INSERT INTO stu VALUES('S_1009', 'wuJiu', 85, 'male');
INSERT INTO stu VALUES('S_1010', 'zhengShi', 5, 'female');
INSERT INTO stu VALUES('S_1011', 'xxx', NULL, NULL);
下面进行操作演示:
1、查询所有列:select *?from? 表名;
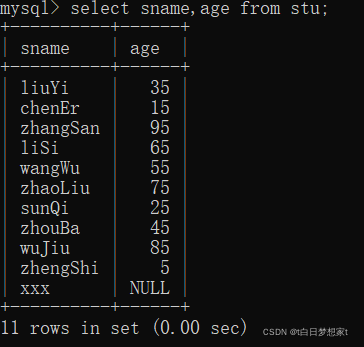
2、查询指定列:select?列名1,列名2,。。。from?表名;
eg:查询sname列和age列:?
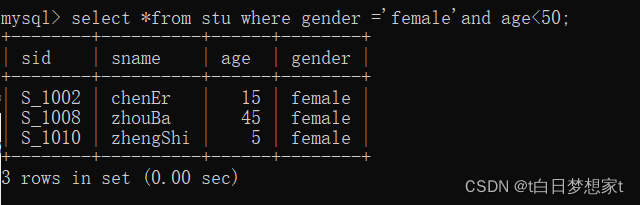
3、条件查询:就是使用where关键词来限定,条件查询中也会用到逻辑用算符(在上面有写)
select *from?表名 where?限定语句;
eg:查找学生表中性别为女并且年龄小于50的所有信息。
?
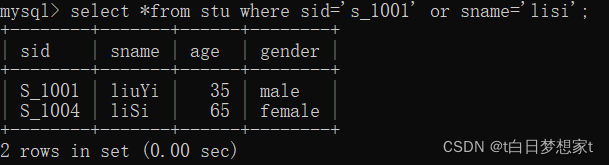
?eg:查找学号为s_1001或者姓名为lisi的
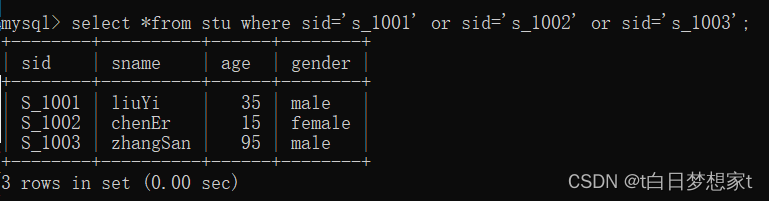
?eg:查找学号为s_1001,s_1002,s_1003的学生。
注意:用or?而不是and。并且必须每个前面都要写sid=
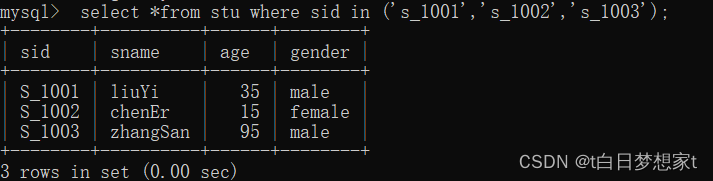
?范围查询:
上面这条语句还可以写成:列名 in (列值1,列值2):这样就可以省去不停的写id=这种繁琐的语句
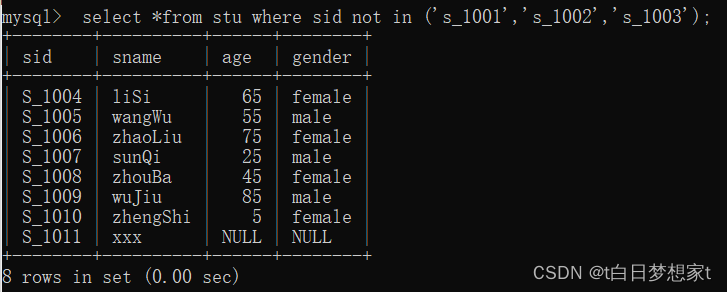
?eg:查找学号不是s_1001,s_1002,s_1003的学生。
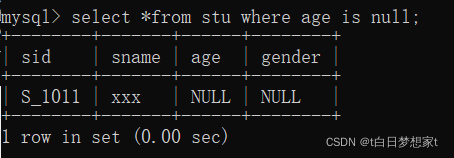
eg:查询年龄为null:
用关键词?is null;?
?
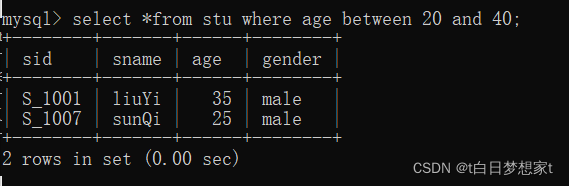
eg:查询年龄在20到40之间的学生记录:
列名 between 开始值 and 结束值;
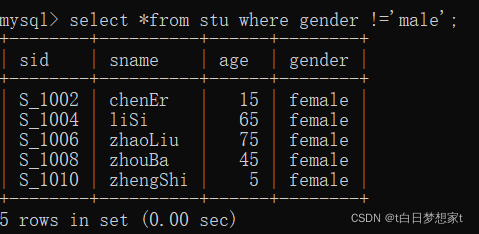
?eg:查询性别非男的学生记录:
SELECT * FROM stu WHERE gender!='male';
或者:SELECT * FROM stu WHERE gender<>'male';
这就是常见的查询操作。?
模糊查询
类似于在浏览器中的关键词查询,例如:查询姓名中包含a的学生信息。这时候就要用到模糊查询了。
语法: 列名 like '表达式' //表达式必须是字符串
通配符:
_(下划线): 任意一个字符
%:任意0~n个字符,'张%'
?eg:“白_” 代表白某,而 “白%” 则代表白某或者白某某(任意长度)
我们先拿到stu表。
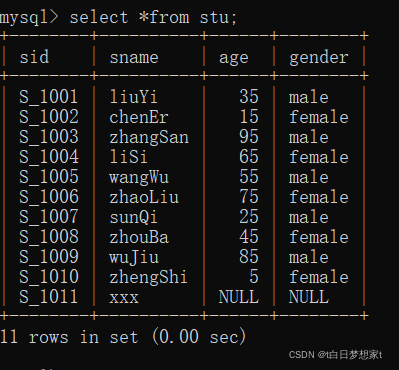
操作练习:?
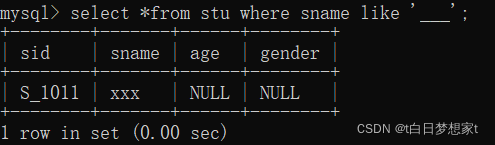
1、查询姓名由三个字构成的学生信息
?SELECT * FROM stu WHERE sname LIKE '___';(此处为三个下划线)
?
?2、查询姓名由五个字母构成,并且第五个字母为“i”的学生记录
SELECT * FROM stu WHERE sname LIKE '____i'; (前面为四个下划线)
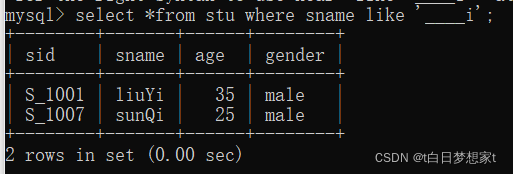
3、查询姓名以“z”开头的学生记录
SELECT * FROM stu WHERE sname LIKE 'z%';
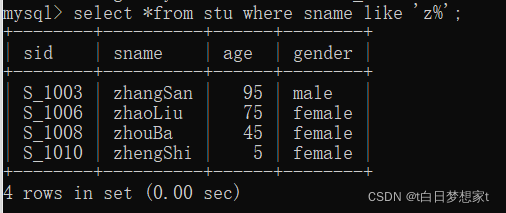
4、查询姓名中第二个字母为“i”的学生记录
SELECT * FROM stu WHERE sname LIKE '_i%';?
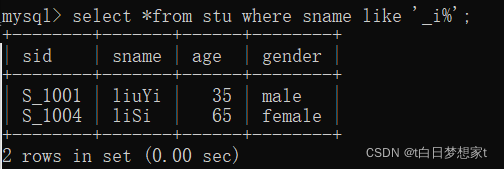
?5、查询姓名中包含“a”字母的学生记录
SELECT * FROM stu WHERE sname LIKE '%a%';
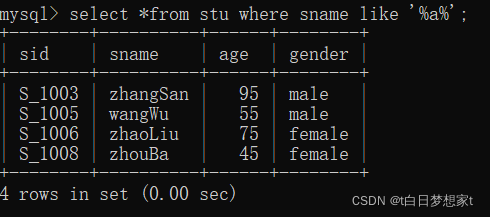
字段控制查询?
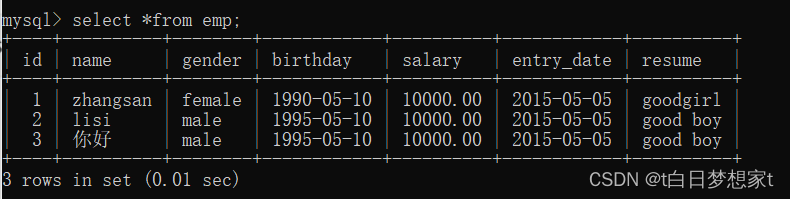
用到的表:
1、去除重复记录
去除重复记录(两行或两行以上记录中,列的数据都相同),比如说此表,我们想查询一共包含几种性别,我们显示性别列:
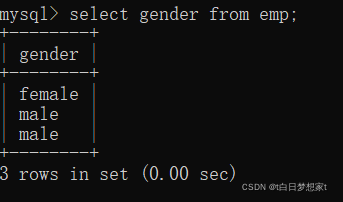
显示了重复性别,那么我们怎么去掉重复记录呢?
用到:?DISTINCT关键字:
SELECT DISTINCT?列名?FROM?表名;
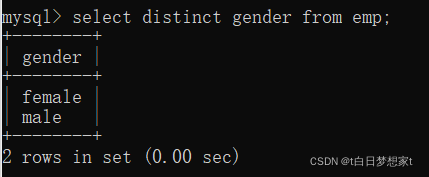
?这样就去除了重复记录。
2、查询列的和
?SELECT?列名+列名?FROM?表名;(注意:必须是可以相加的列才行,否则会出错)
这里用下面这个表给大家做演示:
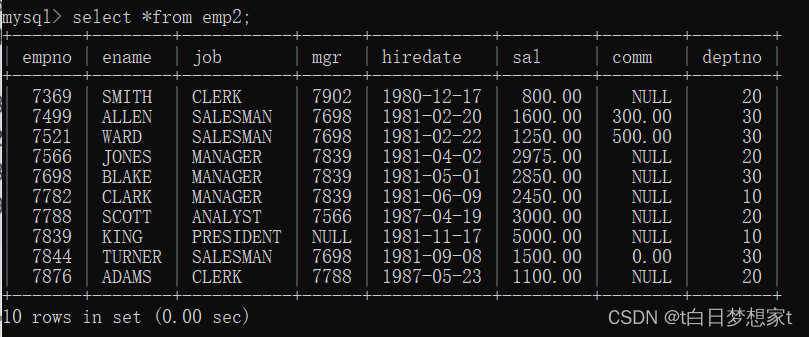
?eg:查看雇员的月薪与佣金之和
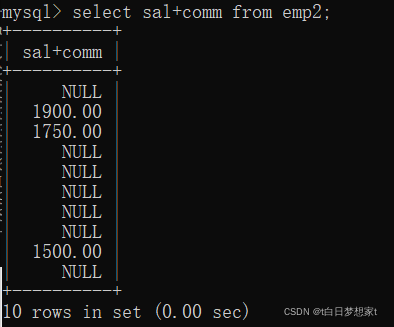
?这里我们注意,emp2表中的一些数字加上null变成了null。例如第一行的sal为800.00但comm为null,加完后的结果不是800而是null。这种情况怎么办呢?
把null转为数字0?
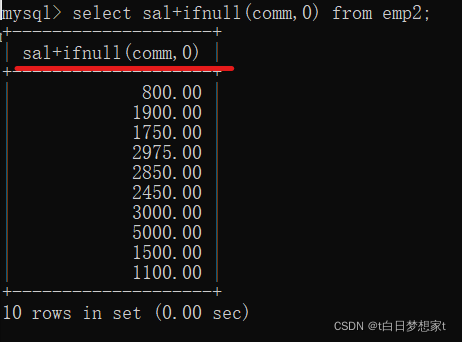
把NULL转换成数值0的函数IFNULL?:
SELECT?列名+IFNULL(要转换的列名,0) FROM emp;(这样就是把要转换的列名中的null都转换成0)?
?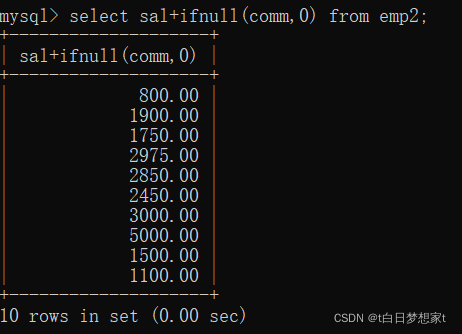
这样就相加正确。?
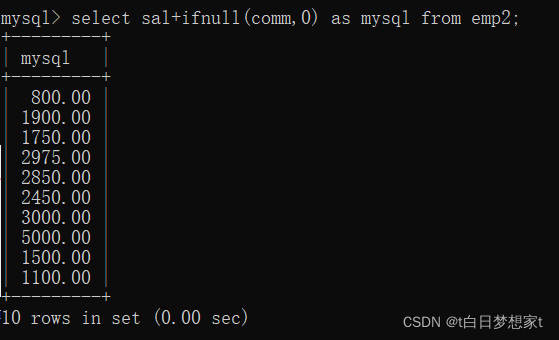
3、给列起别名
像这种,如果虚拟表的列名太长,不好记。我们也可以给它取个别名?
?语法1:select?要改的列名?as?新列名?from?表名;
?
?语法2:将语法1的as去掉?换成空格;
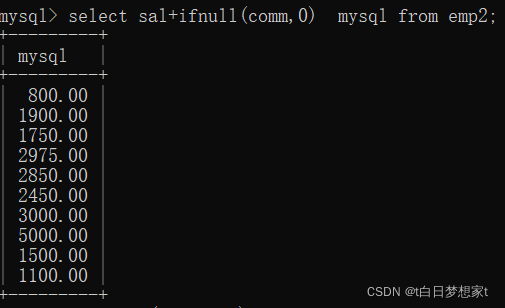
?排序
对表进行升序排列或者降序排列
order by 列名 asc/desc
asc 升序 desc 降序 默认不写的话是升序
用到的表:?
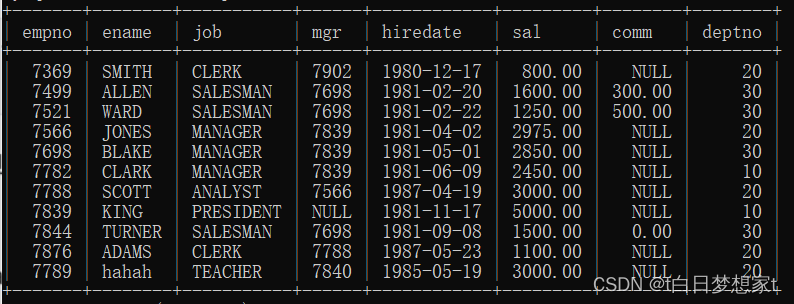
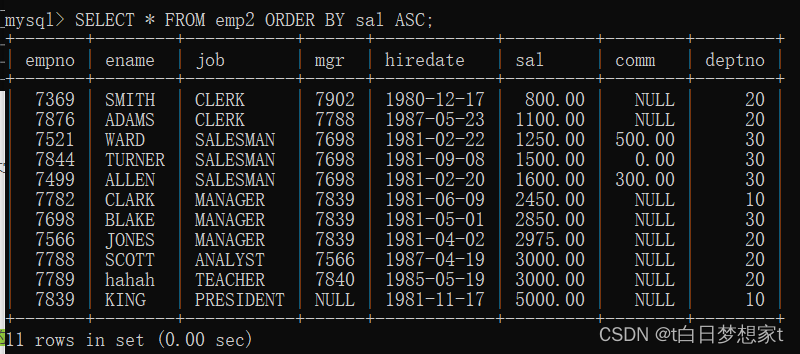
??查询所有记录,按薪水的升序排列:
SELECT * FROM?emp2?ORDER BY sal?ASC;??(默认不写asc也是升序)
???降序就是?将asc改为desc就不在演示。
多列排序:当前面的列的值相同的时候,才会按照后面的列值进行排序
SELECT * FROM?表名?ORDER BY?列名?排序方法,列名2? 排序方法;?
eg:查询所有雇员,按月薪降序排序,如果月薪相同时,按编号降序排序?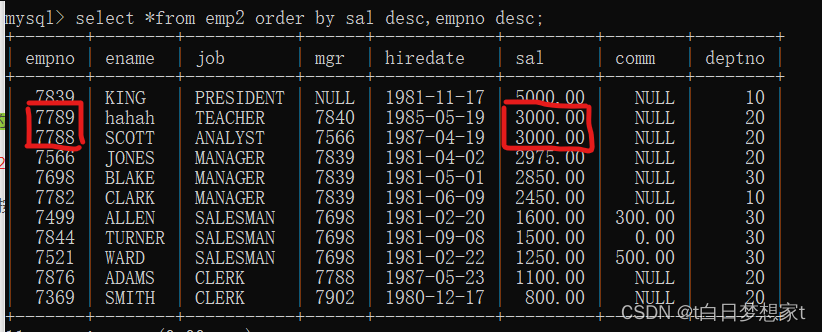
?我们可以看出sal相同的两行,按照empno的降序排列。
聚合函数
聚合函数是用来做纵向运算的函数?
?COUNT(列名):统计指定列不为NULL的记录行数;
MAX(列名):计算指定列的最大值,如果指定列是字符串类型,那么使用字符串排序运算;
MIN(列名):计算指定列的最小值,如果指定列是字符串类型,那么使用字符串排序运算;
SUM(列名):计算指定列的数值和,如果指定列类型不是数值类型,那么计算结果为0;
AVG(列名):计算指定列的平均值,如果指定列类型不是数值类型,那么计算结果为0;
?还是用上面的emp2来给大家一一演示
一、count
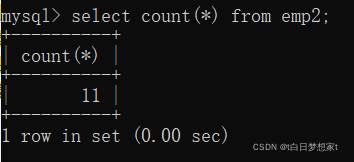
1、查询表中的所有行数:
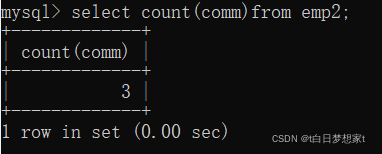
2、查询表中有佣金(comm)的所有行数?
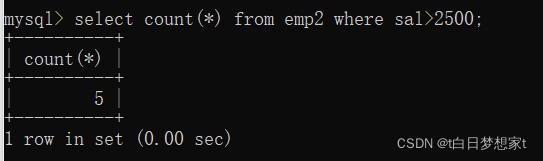
?3、查询表中月薪(sal)大于2500的行数;
?4、统计月薪和佣金之和大于2500
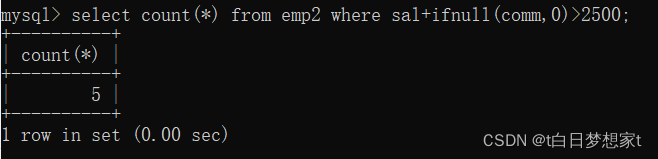
?5、查询有佣金(comm)并且是领导(有mgr)的人数
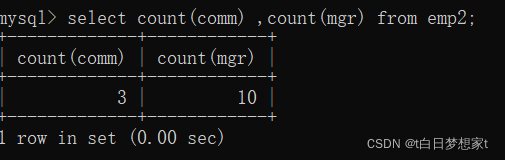
?二、sum和avg
1、查询所有雇员月薪和
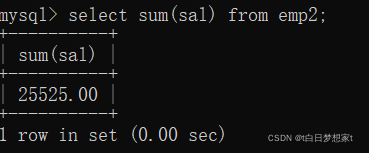
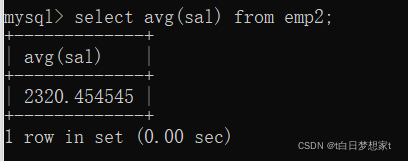
2、统计所有员工薪资(comm)的平均值
?
3、得到所有员工的薪资的最大值和最小值
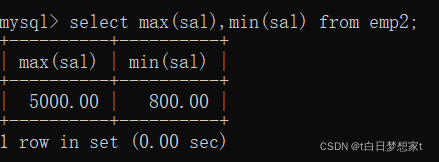
?分组查询
上面我们查找工资之类的都是所有的员工,那么如果我们只想查找一个部门的呢?
关键字:GROUP BY
注意:如果查询语句中有分组操作,则select后面能添加的只能是聚合函数和被分组的列名
查询每个部门的部门编号和每个部门的工资和:
?1、查询各部门工资总和:
select? 方法(列名)from?表名?group?by? 要分类的列名。
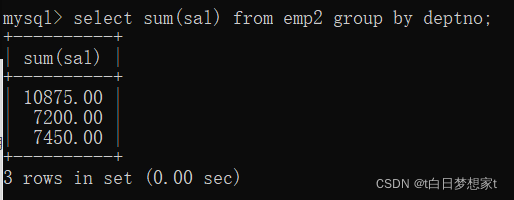
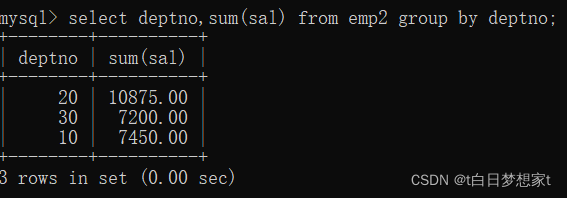
此时,我们发现,将部门通过编号分成了三类,但是我们并不知道,哪一个总和对应哪一个部门,这时就要用到语句:select?部门,方法(列名)from?表名?group?by? 要分类的列名。
?
2、查询每个部门的部门编号以及每个部门工资大于1500的人数?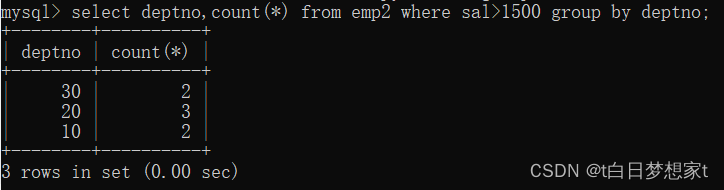
?HAVING子句
我们看上面的第二题:查询每个部门的部门编号以及每个部门工资大于1500的人数?,是先有条件:工资大于1500,再分组,部门
而having关键字用于:先分部门,再有条件。
eg:查询工资总和大于9000的部门编号以及工资和:?

?注:having与where的区别:
1.having是在分组后对数据进行过滤,where是在分组前对数据进行过滤
2.having后面可以使用分组函数(统计函数)
where后面不可以使用分组函数。
WHERE是对分组前记录的条件,如果某行记录没有满足WHERE子句的条件,那么这行记录不会参加分
组;而HAVING是对分组后数据的约束。
补充: 多列分组,分组的第一列出现相同的情况下,用第二列的值来分组
select?列名1,列名2?,方法名(列名) ,from?表名 group by?列名1,列名2.
用到的表:
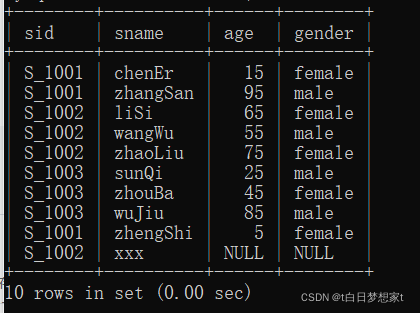
??-- 统计出stu表中每个班级的男女生各多少人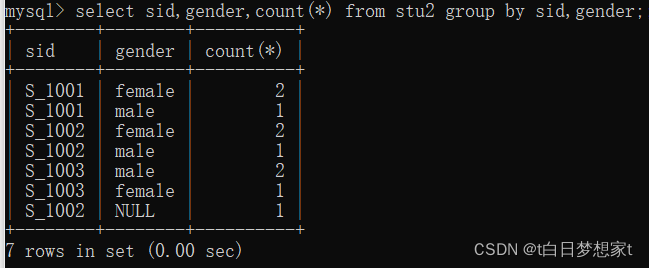
limit关键字和分页查询
limit用来限定查询结果的起始行,以及总行数(起到一个分页的效果,显示几行)
1、limit?开始下标,显示条数;//开始下标从0开始。
2、limit?显示条数;//表示默认从0开始获取数据
?用此表来展示: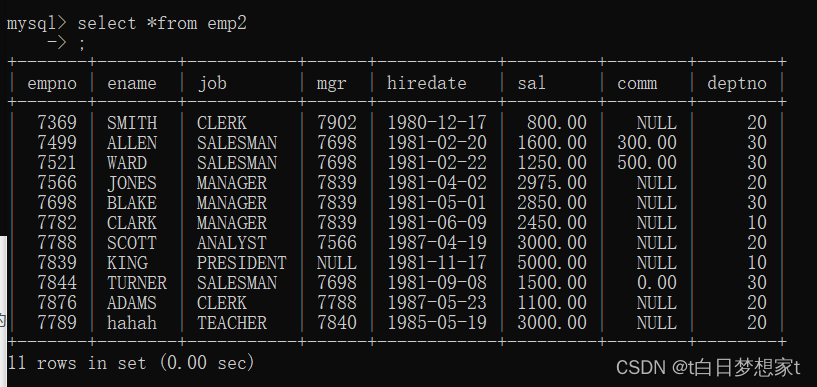
?1.查询5行记录,起始行从0开始
SELECT * FROM emp LIMIT 0, 5;
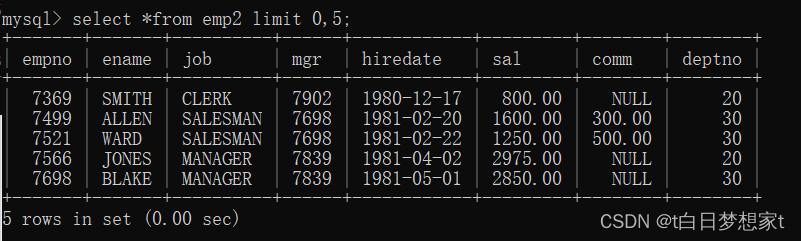
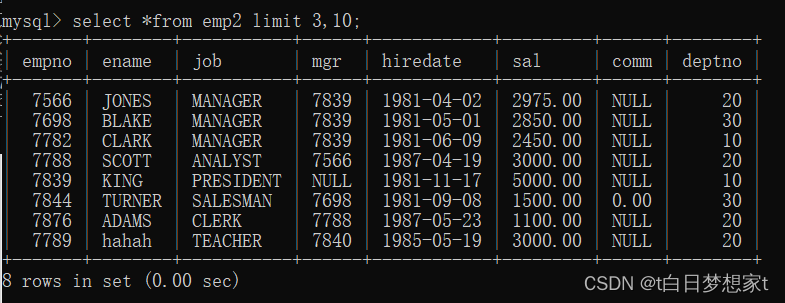
2.查询10行记录,起始行从3开始?
SELECT* FROM emp LIMIT 3, 10;(因为数据没有那么多,所以只展示了符合要求的8行)
?分页查询
我们在实际开发中一般limit应用于分页查询这个功能上。
比如,我们现要将一个数据表分开,一页10条,分为n页,该怎么查呢?
解:第一页:limit 0,9;
????????第二页:limit 10,19;
? ? ? ?。。。。
这样显然太麻烦。
此时,我们应设置变量,改变变量即可。eg:pageIndex 页码值 pageSize 每页显示条数
于是,用一条语句就可以代替上面的n条:
limit (pageindex-1)*pagesize,pagesize;
数据库的基础内容就这些。上面的所有都需要熟练掌握,逐一实现。?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!