机器学习:自督导式学习模型
2023-12-17 12:28:56
outline
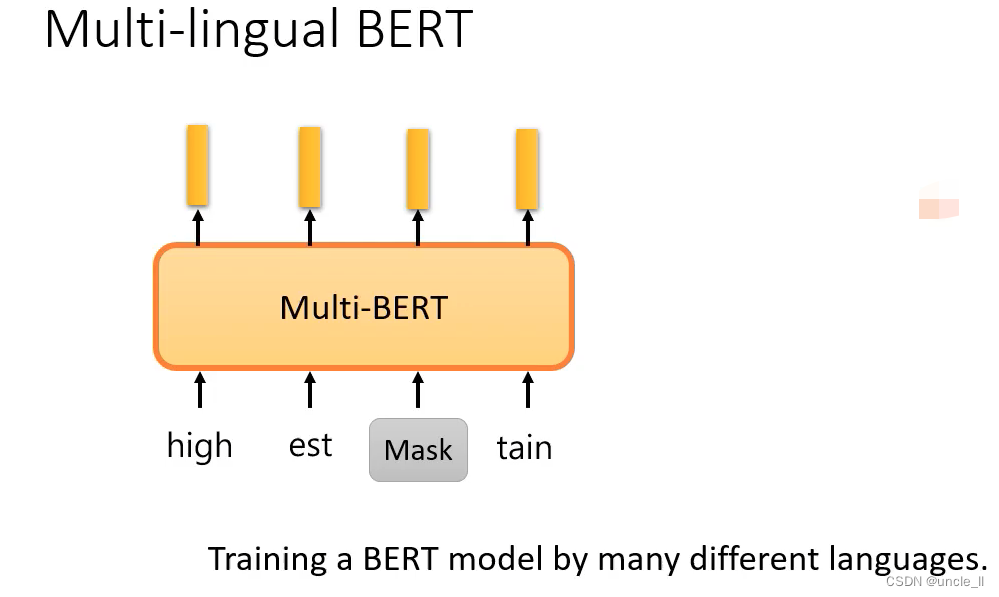
自督导式模型有跨语言的能力
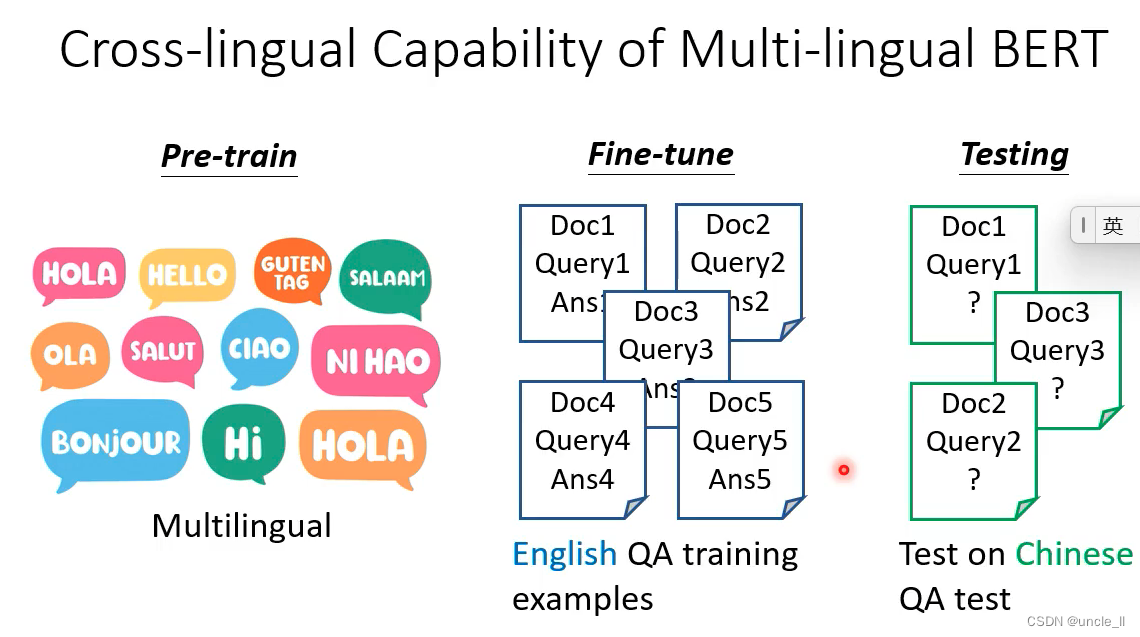

- 中文:DRCD的数据集
- 英文:SQuAD的数据集
在104种语言上进行学习,并在英文上进行微调,结果在中文上效果也比较好。
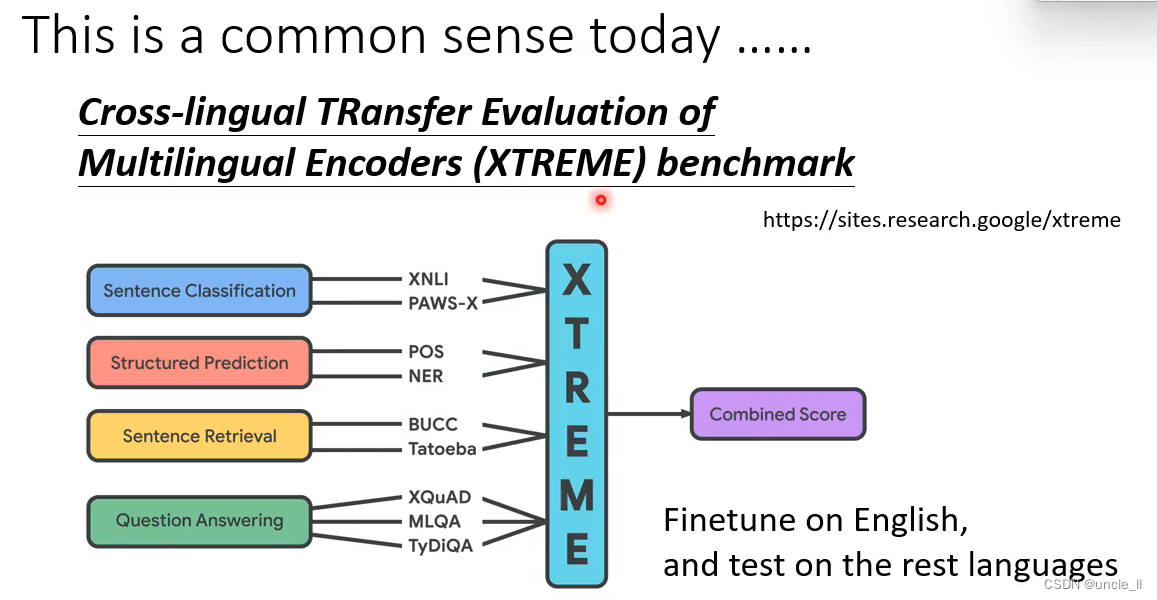
XTREME Benchmark
只用英文进行微调,在其他剩下的语言中进行测试。
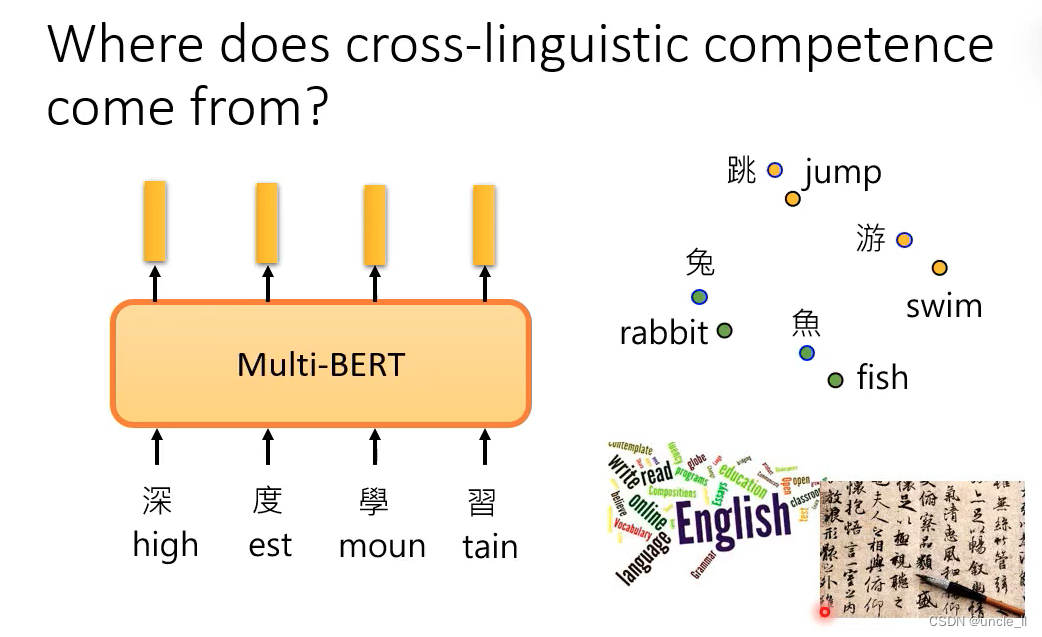
bert可以无视语言的表象,只了解符合背后代表的语义。

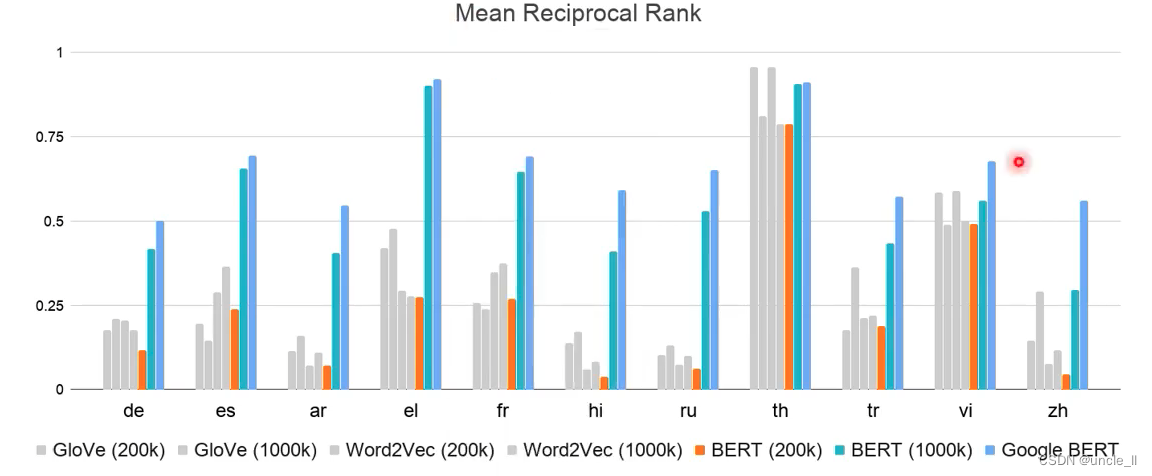
看看英文对中文相近的分数算出来,然后取平均值得到MRR,该值越大越好。
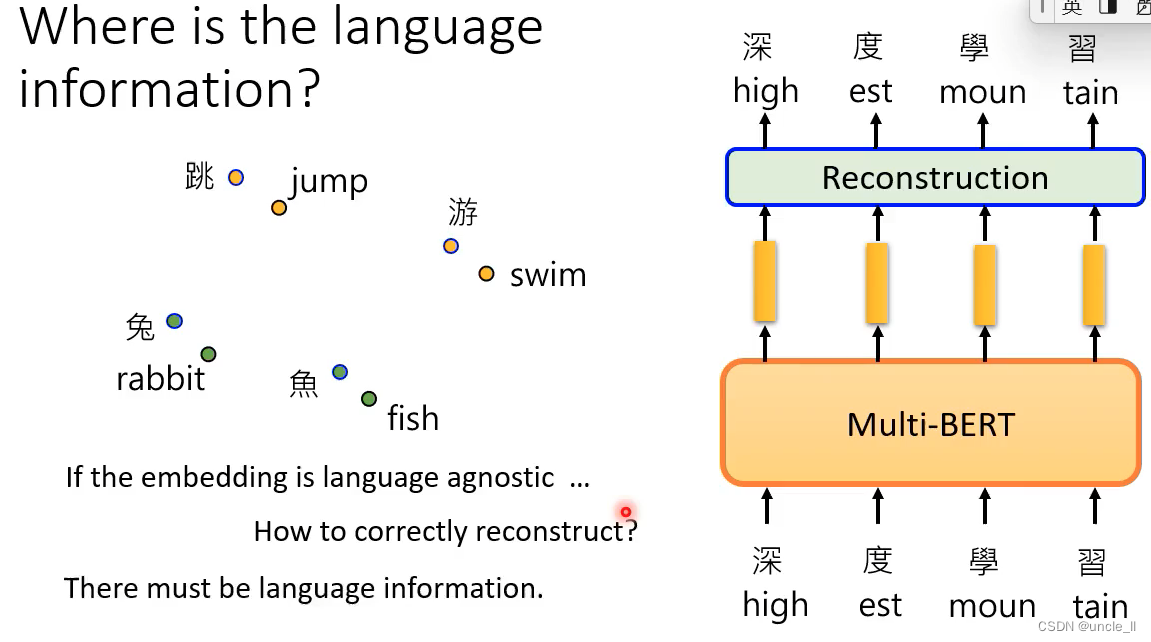
语言的信息藏在哪里呢?通过embedding展示,相近的词更接近
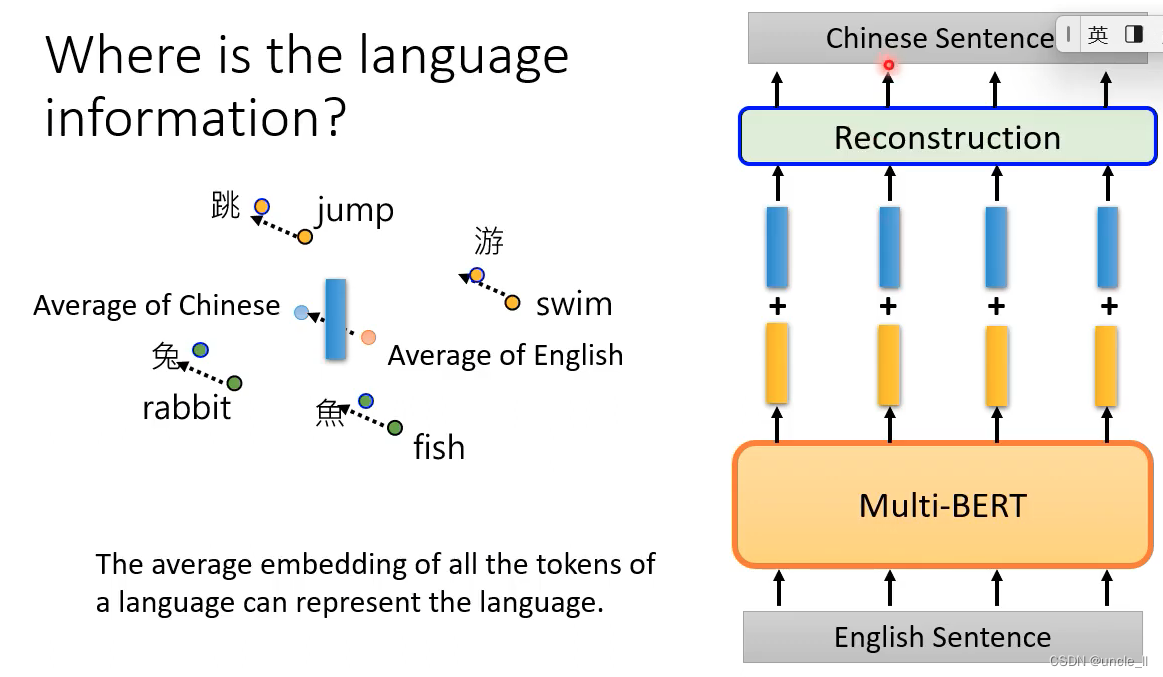
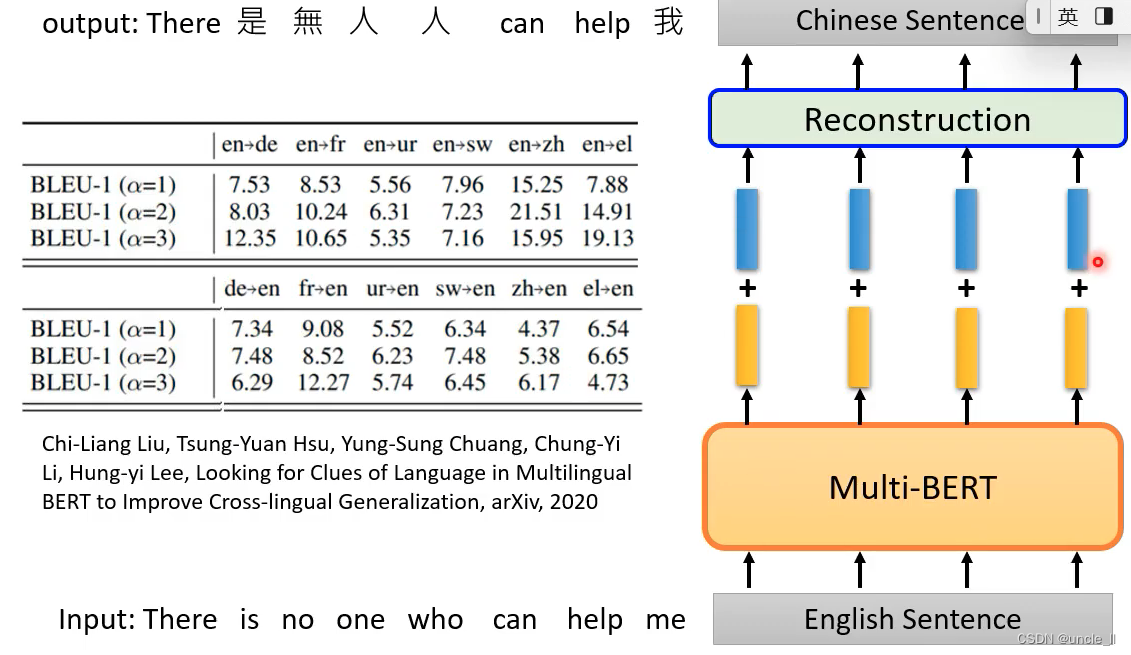
英文转化成向量后,并对其进行偏移向量后,能够重构为中文。
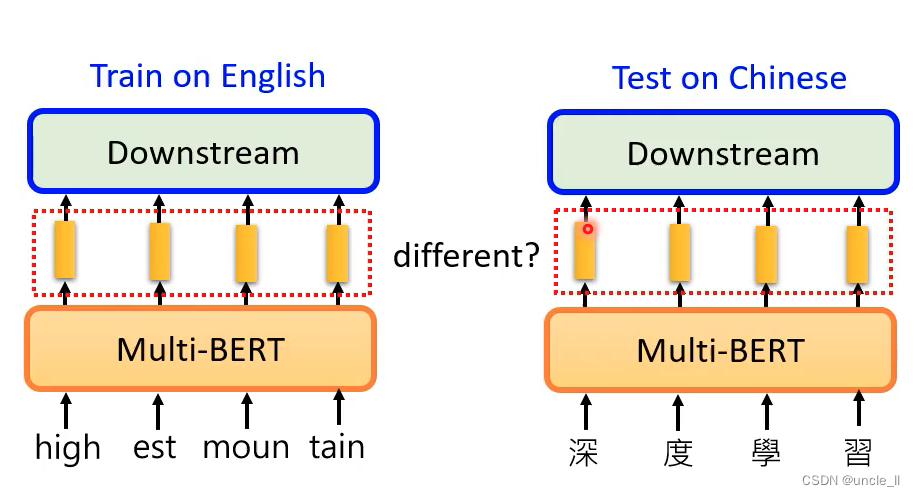
可以在英文上测试,并在中文上进行测试。中英文上的embedding是有点差距的。
自督导式模型有跨领域的能力
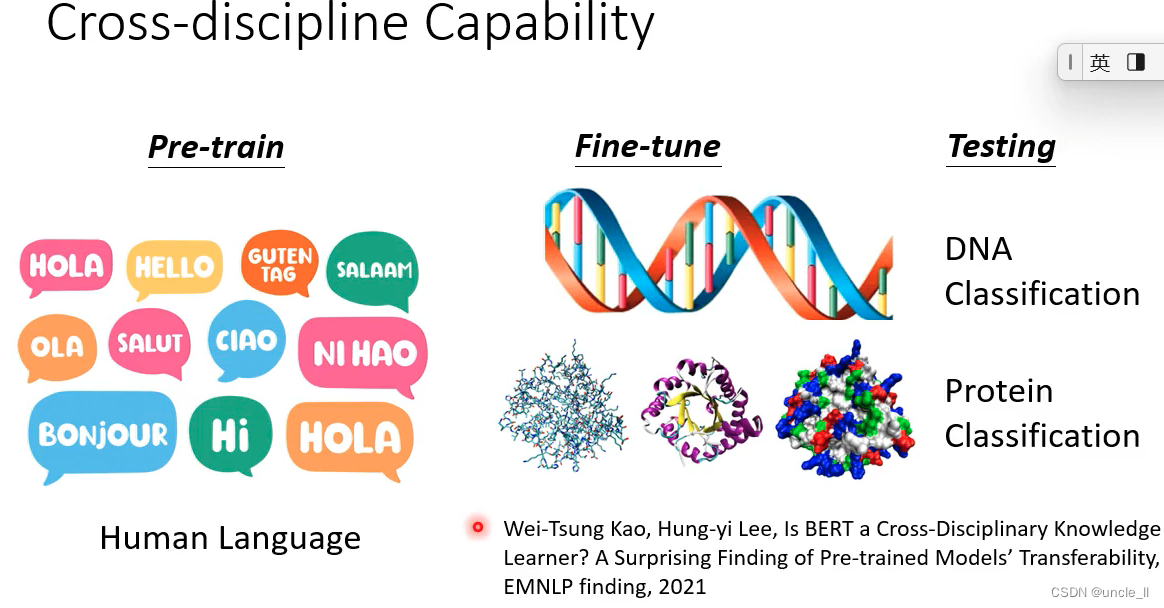
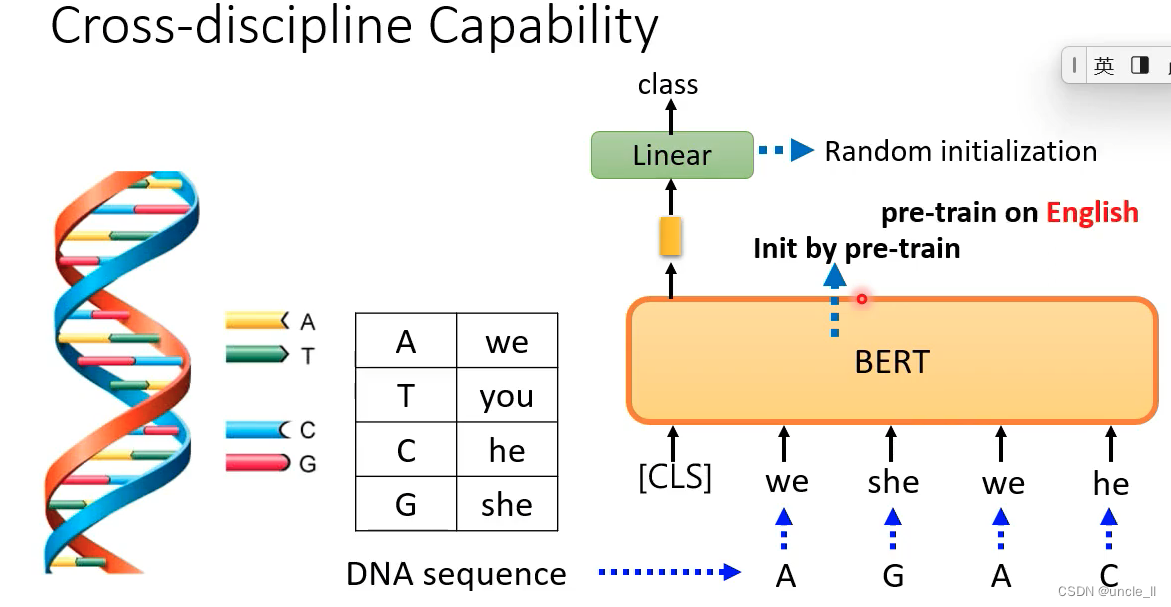
把DNA的组成替换成字符型的表示形式进行学习
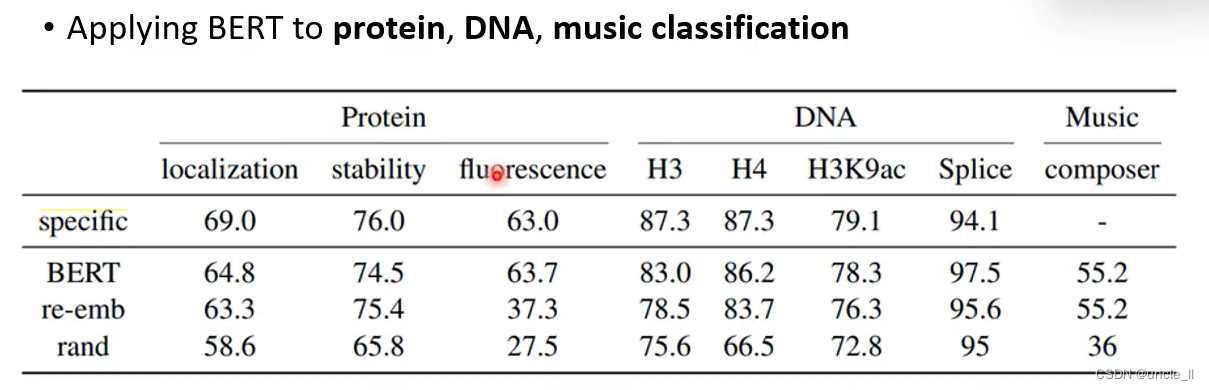
用bert有明显的提升。不仅学到了语义信息,也学到了一些通用的能力,在其他领域也能有较好的性能,
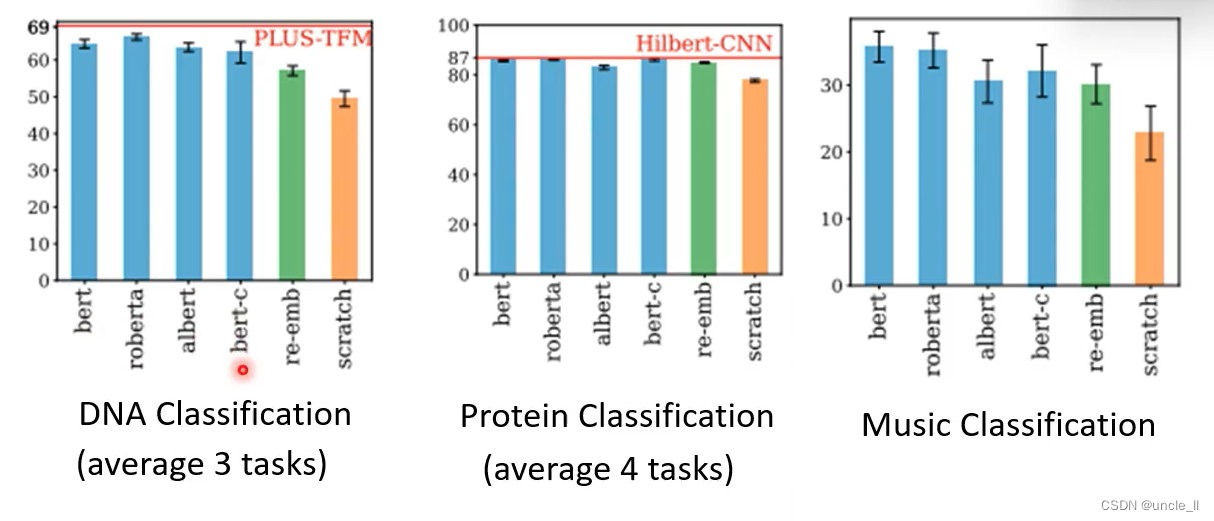
在DNA 蛋白质 音乐上都有所帮助。
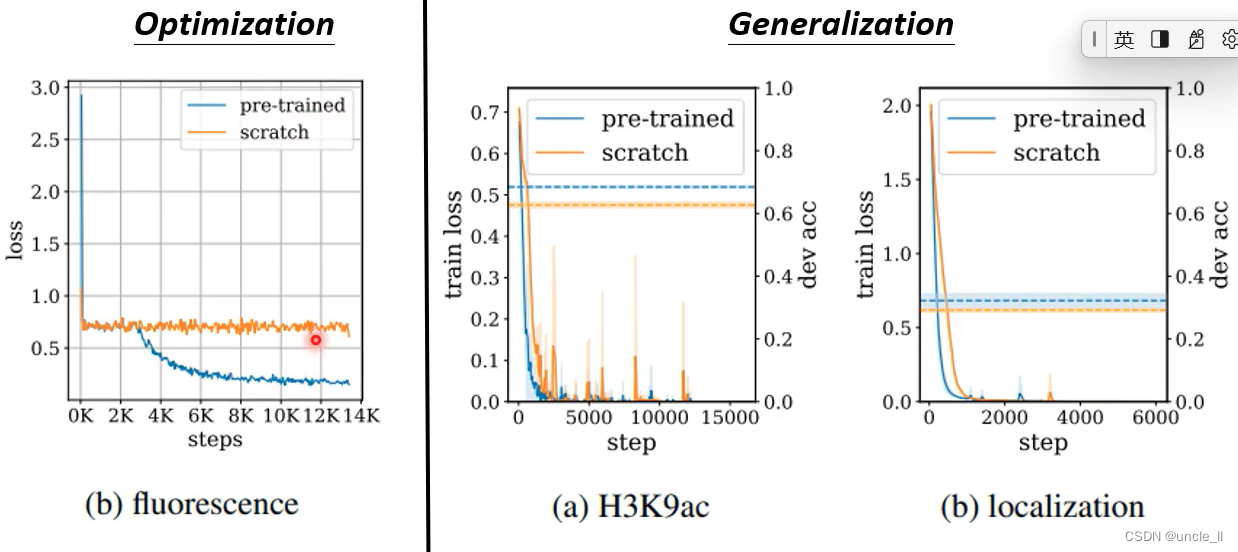
pre-trained模型有强化模型的能力

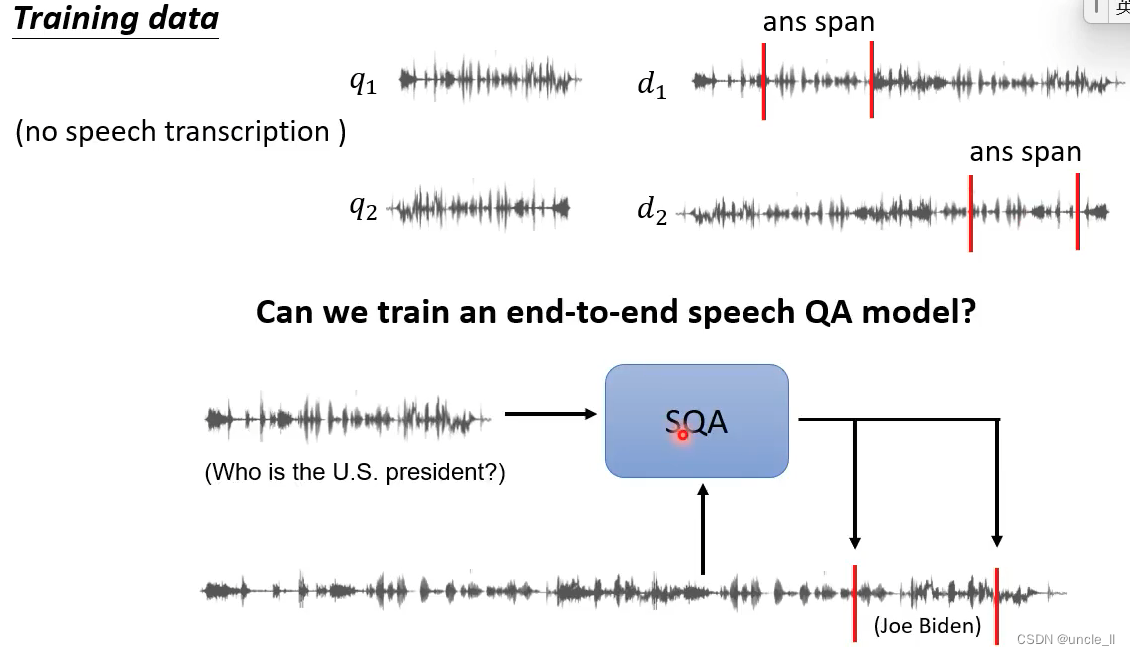
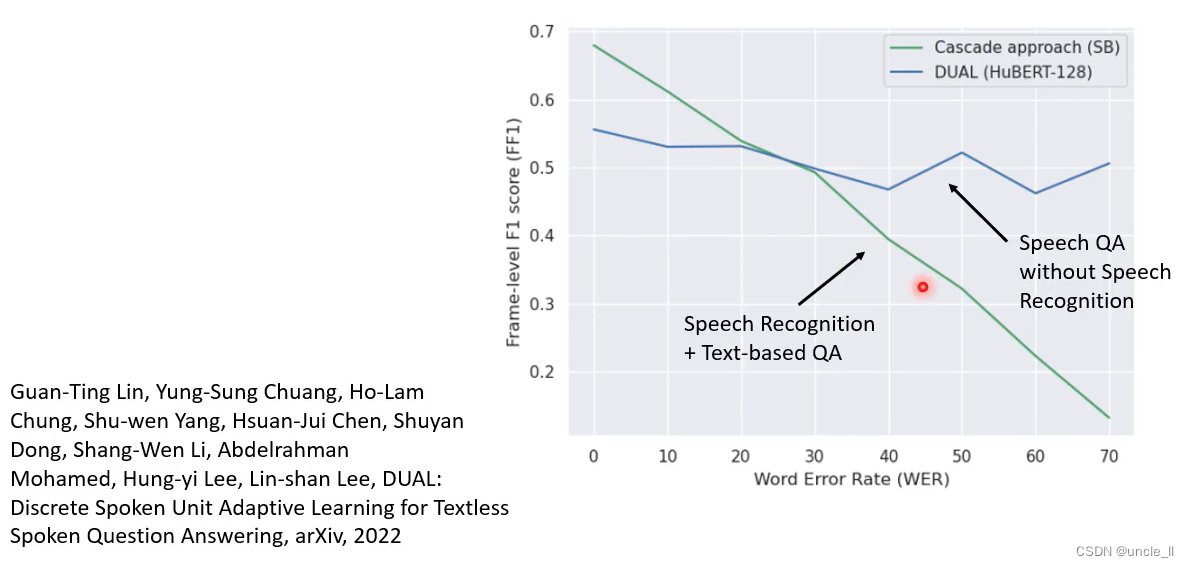
跨语言学习的能力用在语音回答系统。
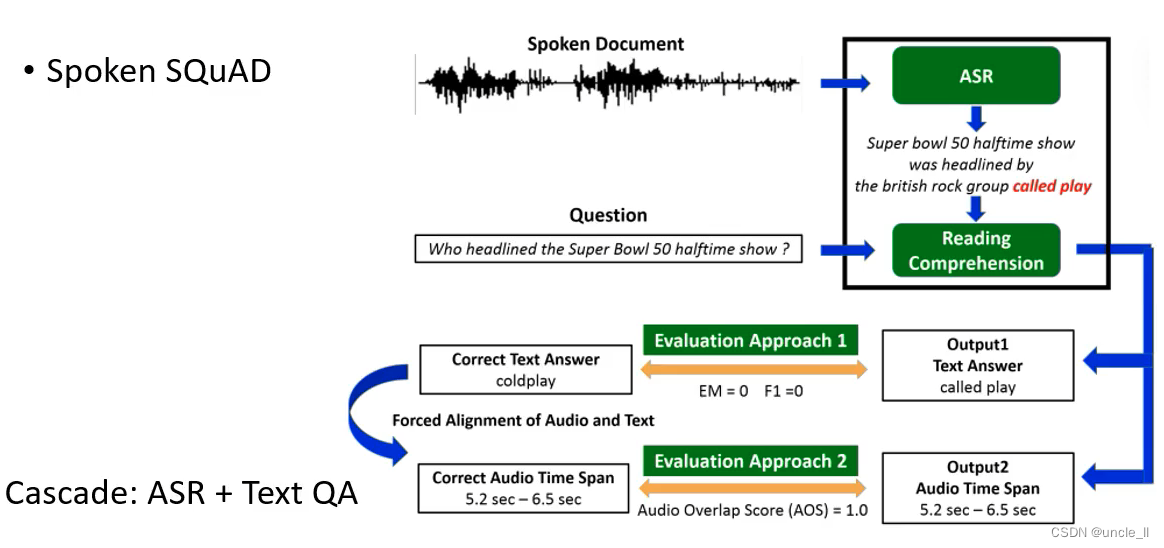
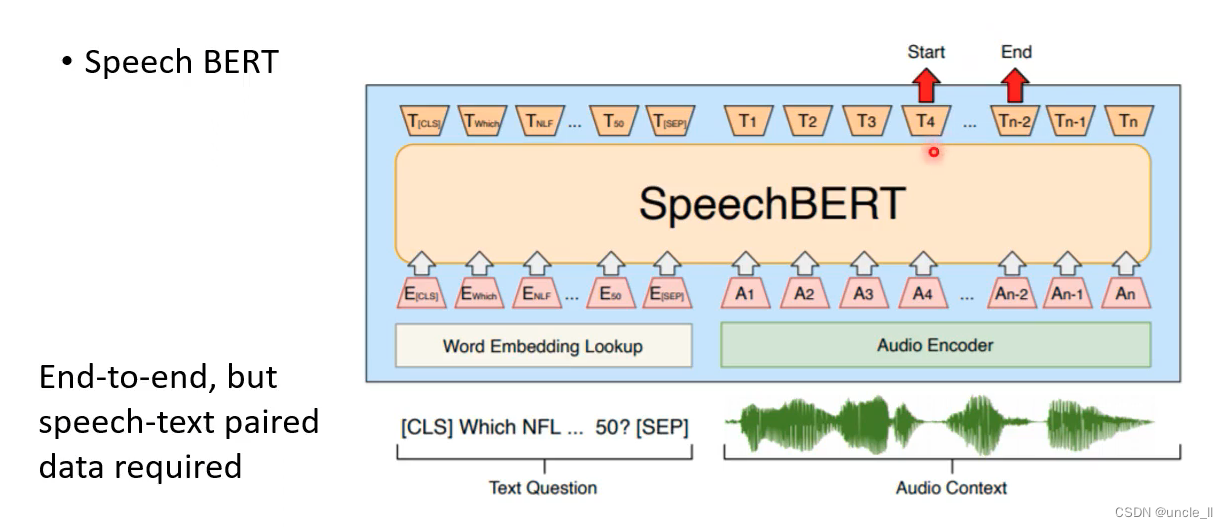
终极状态:输入是语音,输出也是语音。
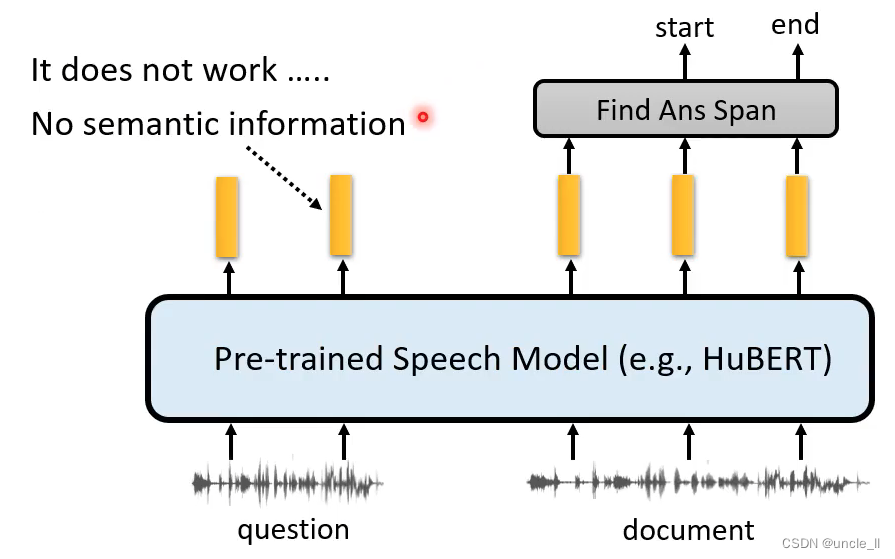
光用hubert是不行的,可以通过中间层后再加几层网络:
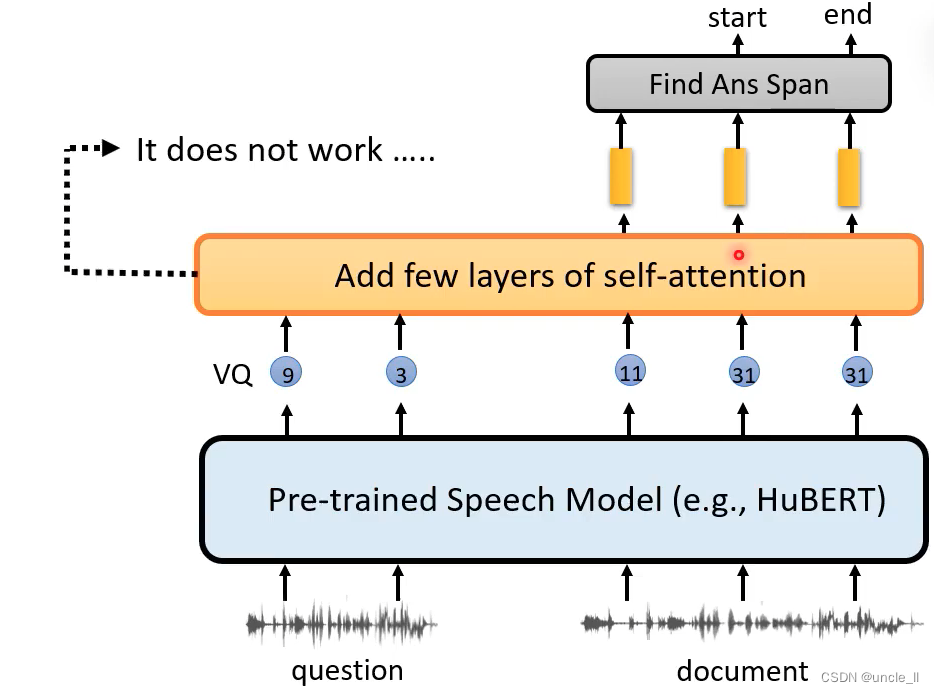
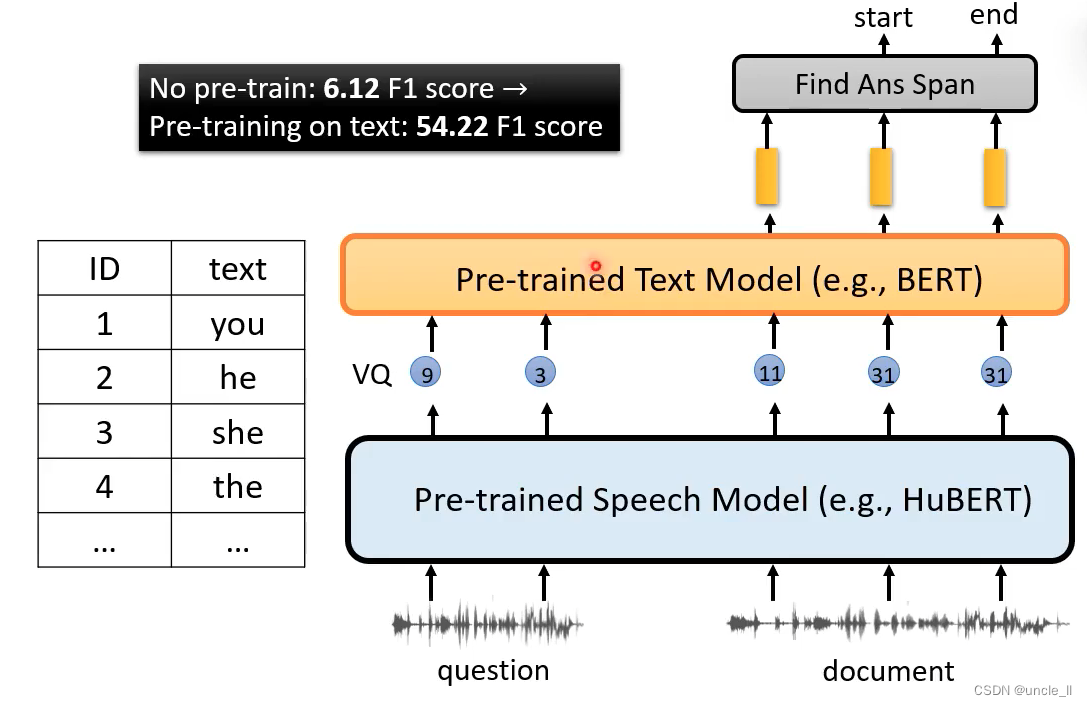
可以把Hubert的输出 丢给文字的预训练Bert
在人造的资料上训练Bert
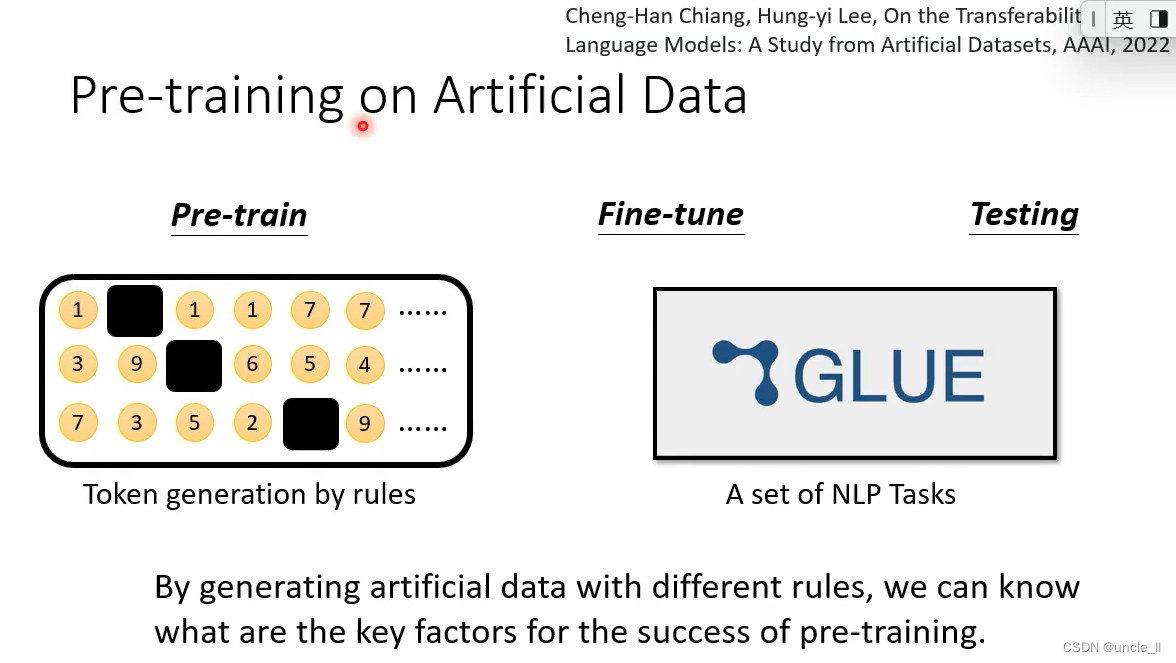
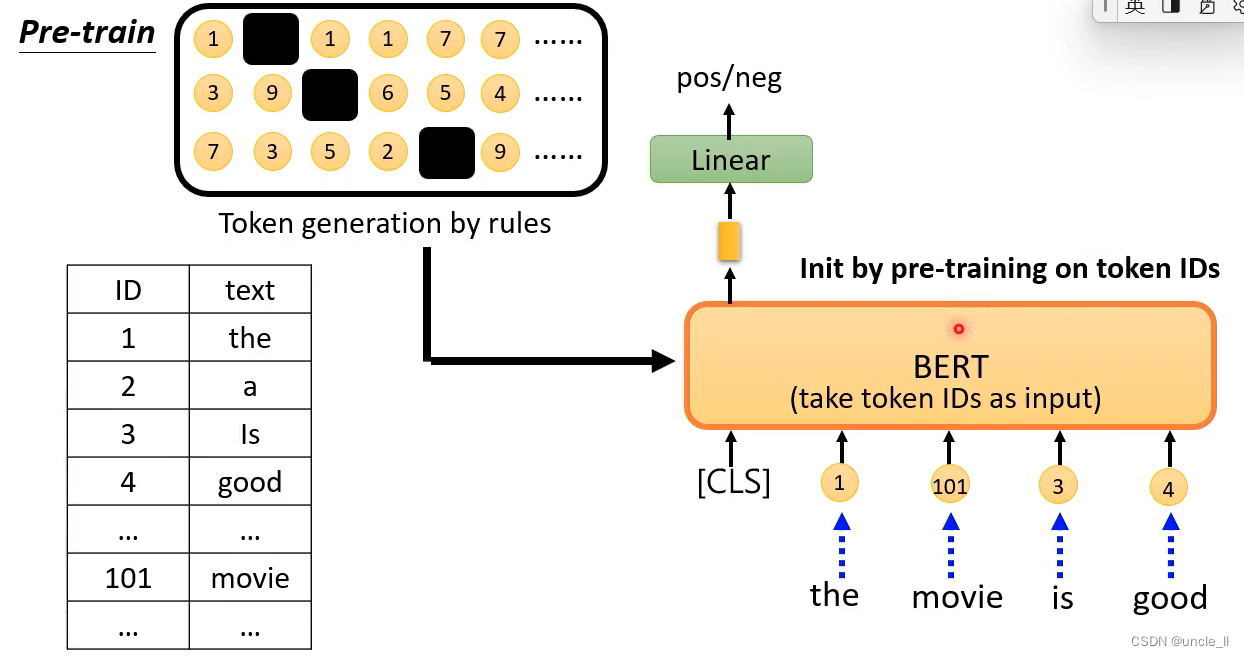
通过规则生成一些tokens,并将tokens进行映射,之后再送到网络中进行学习。

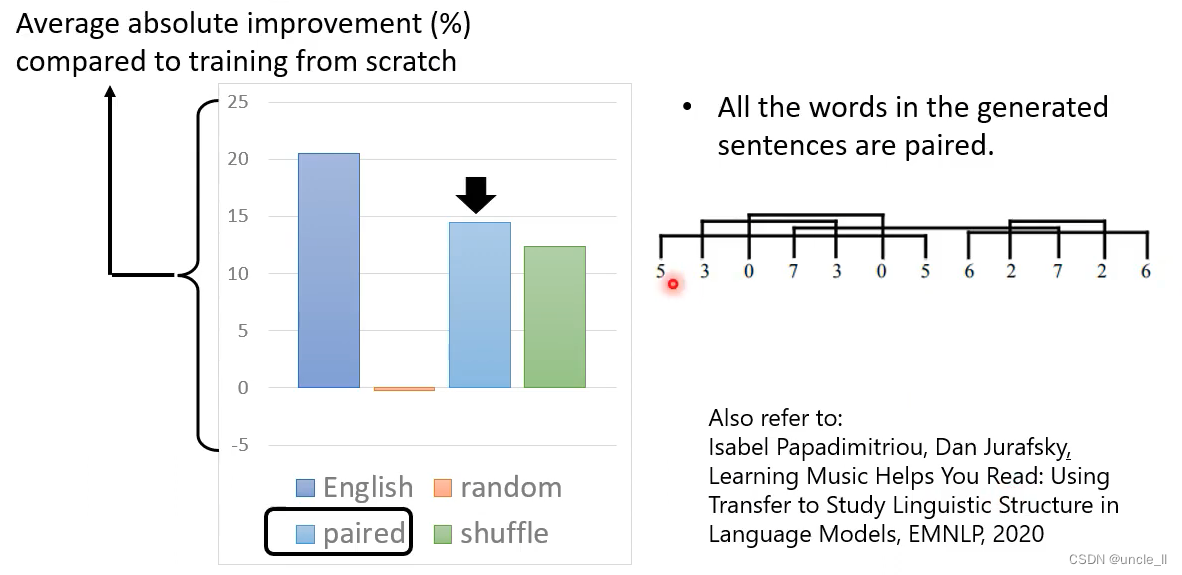
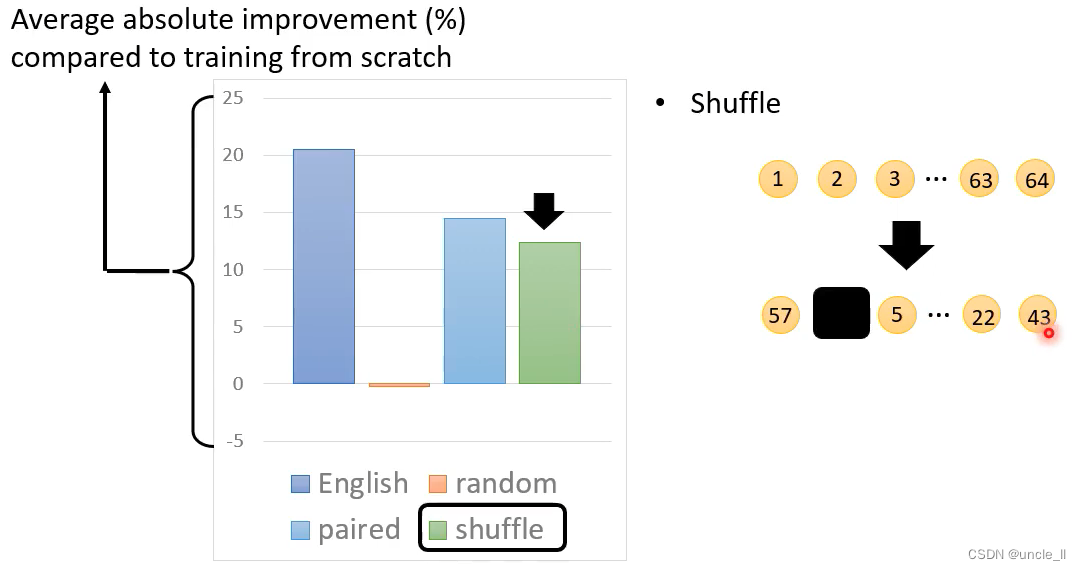
- random产生的资料的效果不好
- pair产生资料的效果还是非常明显的
- shuffle产生的资料效果还是可以的
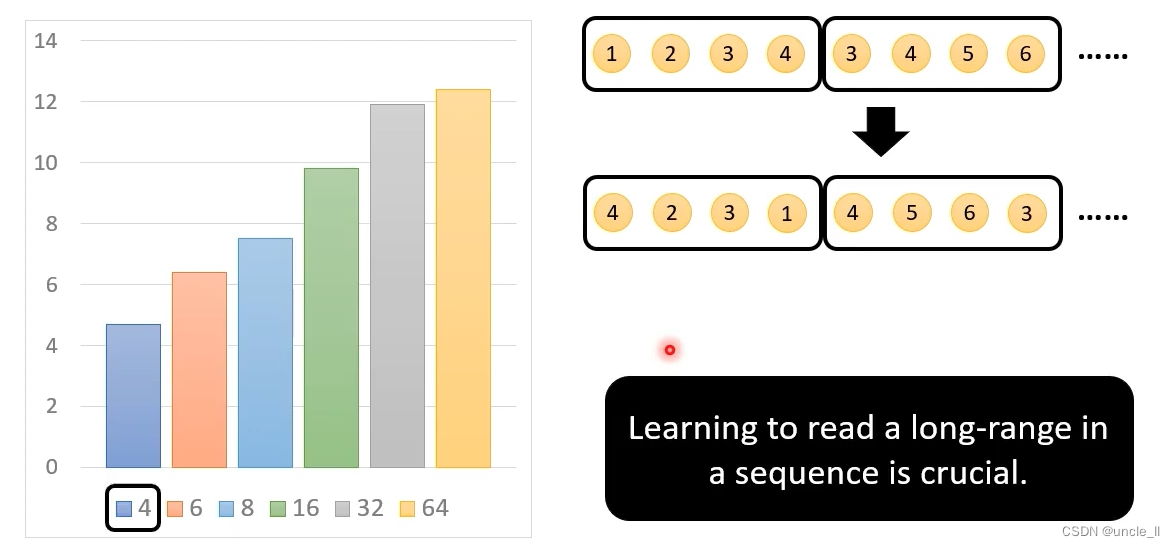
token的序列长度是非常重要的。
文章来源:https://blog.csdn.net/uncle_ll/article/details/135036562
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!