KANDINSKY 3.0 TECHNICAL REPORT
Paper name
KANDINSKY 3.0 TECHNICAL REPORT
Paper Reading Note
Paper URL: https://arxiv.org/pdf/2312.03511.pdf
Project URL: https://ai-forever.github.io/Kandinsky-3/
Code URL: https://github.com/ai-forever/Kandinsky-3
TL;DR
- 2023 年 Sber AI(俄罗斯最大的银行和金融服务公司 Сбер 银行 Sberbank的人工智能部门)和 AIRI 出品的文章,提出了 Kandinsky 3.0,这是一种基于潜在扩散的新型文本到图像生成模型,专注于改善对文本的理解、图像质量。同时开源了相关模型和代码,相关模型在 https://fusionbrain.ai/en/editor 网页上可免费玩
Introduction
背景
- 文本到图像生成模型的质量显著提高,这得益于扩散概率模型的发明
- 尽管如此,文本到图像生成的任务仍然对研究人员提出严重挑战。在商业和设计中实际应用的不断增加导致了与复杂文本描述相一致的难度逐渐提升
本文方案
-
本文介绍了 Kandinsky 3.0,这是一种基于潜在扩散的新型文本到图像生成模型。Kandinsky家族的早期模型(Kandinsky 1.0)架构基于在图像和文本的潜在向量空间之间使用扩散映射的两阶段 pipeline,然后进行解码。在 Kandinsky 3.0 模型中,专注于改善对文本的理解、图像质量,并通过提供单阶段 pipeline 来简化架构,在该 pipeline 中,生成直接使用文本嵌入,无需任何额外的先验知识。整个 pipeline 包含 119 亿(11.9B)个参数,几乎是 Kandinsky 家族先前模型中最大的模型的三倍。此外,作者将 Kandinsky 3.0 集成到用户友好的交互系统中。完全公开了模型,以促进新技术的发展并在科学界推动开放性。
-
这份技术报告的结构如下:
- 首先,描述用户交互演示系统;
- 其次,详细介绍 Kandinsky 3.0 模型的关键组成部分、数据集使用策略、训练技术以及各种应用;
- 最后,报告基于人类偏好的并列比较结果,并讨论模型的局限性。
Methods
Demo System
-
demo system 地址:https://fusionbrain.ai/en/editor/ (注册后可免费玩,页面如下,注意一开始登录进去是俄文显示,点左下角的按钮后切换为英文)
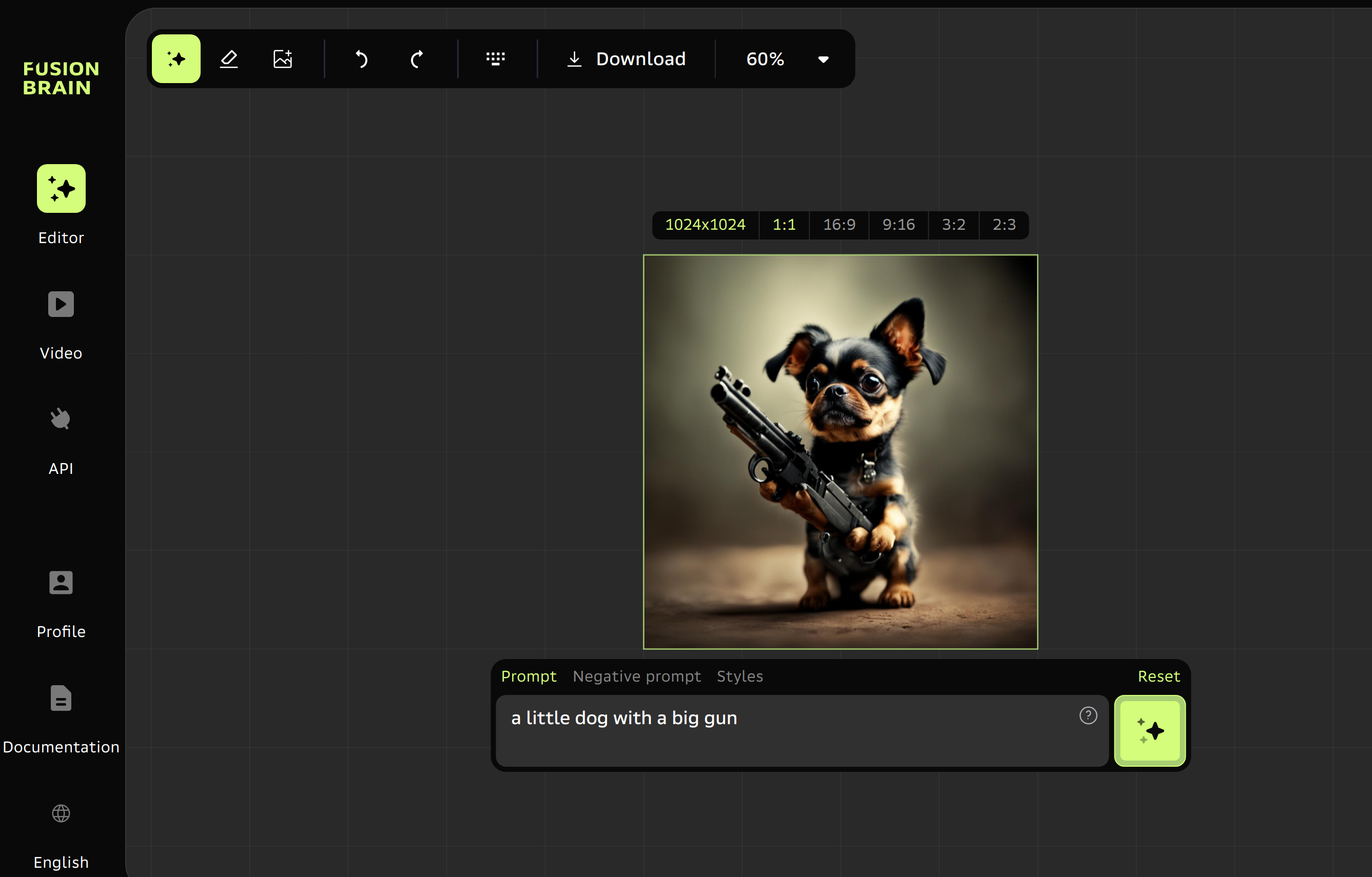
-
该系统可以接受俄语、英语和其他语言的文本提示。还允许在文本描述中使用表情符号。文本的最大长度为1000个字符;
-
在“Negative prompt”字段中,用户可以指定模型在生成过程中不应使用的信息(例如颜色);
-
最大分辨率为1024 × 1024;
-
选择边缘比例:1:1,16:9,9:16,2:3或3:2;
-
选择生成样式以加速推理:数字图像,像素艺术,卡通,肖像照片,工作室照片,赛博朋克,3D渲染,古典主义,动漫,油画,铅笔画,霍赫洛马绘画风格,以及著名艺术家如艾瓦佐夫斯基,康定斯基,马列维奇和毕加索的风格;
-
放大/缩小;
-
使用橡皮擦突出显示可以用新的文本描述进行填充的区域(修补技术);
-
使用滑动窗口扩展生成图像的边界,并使用新边界进行进一步生成(扩展技术);
-
我们还实现了我们开发的内容过滤器,以处理不正确的请求。
-
该网站还支持具有以下特征的图像到视频生成:
- 分辨率:640 × 640,480 × 854和854 × 480;
- 用户可以通过使用文本提示描述每个场景来设置最多4个场景。每个场景持续4秒,包括过渡到下一个场景;
- 对于每个场景,可以选择相机运动的方向:向上、向下、向右、向左、逆时针或顺时针旋转、缩小、放大以及围绕对象的不同飞行类型;
- 平均生成时间范围从一个场景的1.5分钟到四个场景的6分钟不等;
- 生成的视频可以以mp4格式下载
Kandinsky 3.0 Architecture
- Kandinsky 3.0是一种潜在扩散模型,其整个 pipeline 包括用于处理用户提示的文本编码器,用于在去噪(反向)过程中预测噪声的U-Net,以及用于从生成的 latent 中进行图像重建的解码器

各模块的参数量如下,总共的参数量为 11.9B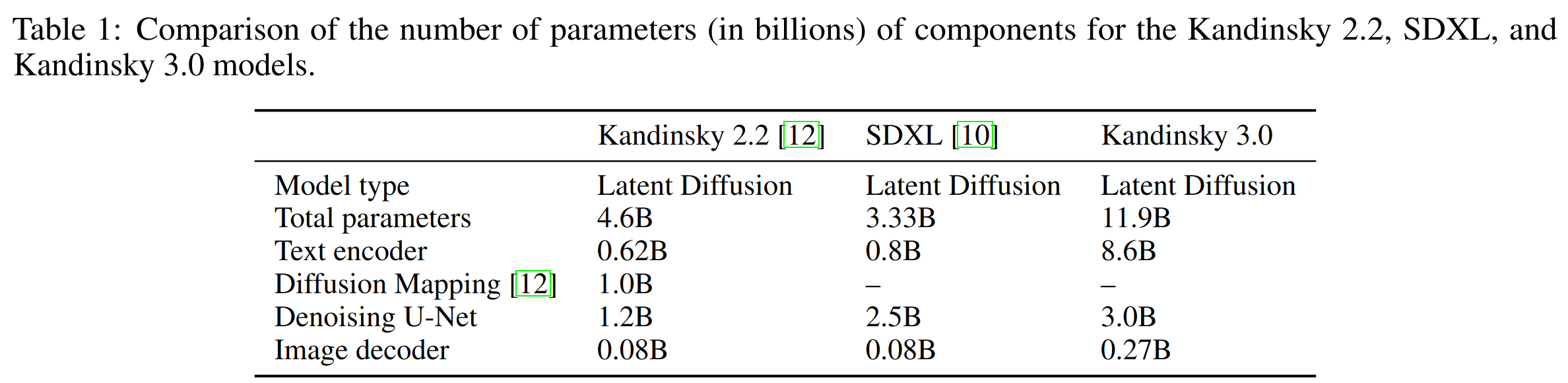
UNet 架构
-
做了 500 次左右的模型架构实验,探索要将主要的参数放在 CNN 上还是 transformer 上
- 提升网络的层数,同时降低总参数量可以获得更好的训练效果
- 在初始阶段,仅使用卷积块处理高分辨率图像,而更压缩的特征才送到 transformer 层。这确保了图像元素的全局交互
- 作者尝试了基于全 transformer 搭建的 magvit 架构,通过减少自注意力的平方复杂度适应图像处理。在分类任务中,与上述模型相比,该架构显示出最佳结果。尽管如此,在实验中,发现该架构在生成任务中表现不佳
-
在探讨了以上所有架构之后,我们选择了 ResNet-50 block 作为我们去噪U-Net的主要模块。因此,我们的架构的输入和输出的残差块包含具有1×1核的卷积层,相应地减少和增加通道数。我们还通过一个具有 3×3 核的额外卷积层扩展了它,就像 BigGAN-deep 残差块架构一样。在残差块中使用瓶颈使得我们能够加倍卷积层的数量,同时保持几乎相同数量的参数。与Kandinsky 2.x 模型的先前版本相比,我们新架构的深度增加了 1.5 倍。在放大和缩小的更高级别的部分,我们仅放置了我们实现的卷积残差 BigGAN-deep 块。同时,在较低分辨率处,架构包括自注意和交叉注意层。我们的 U-Net 架构、残差 BigGAN-deep 块和交叉注意块的完整方案如下图所示:
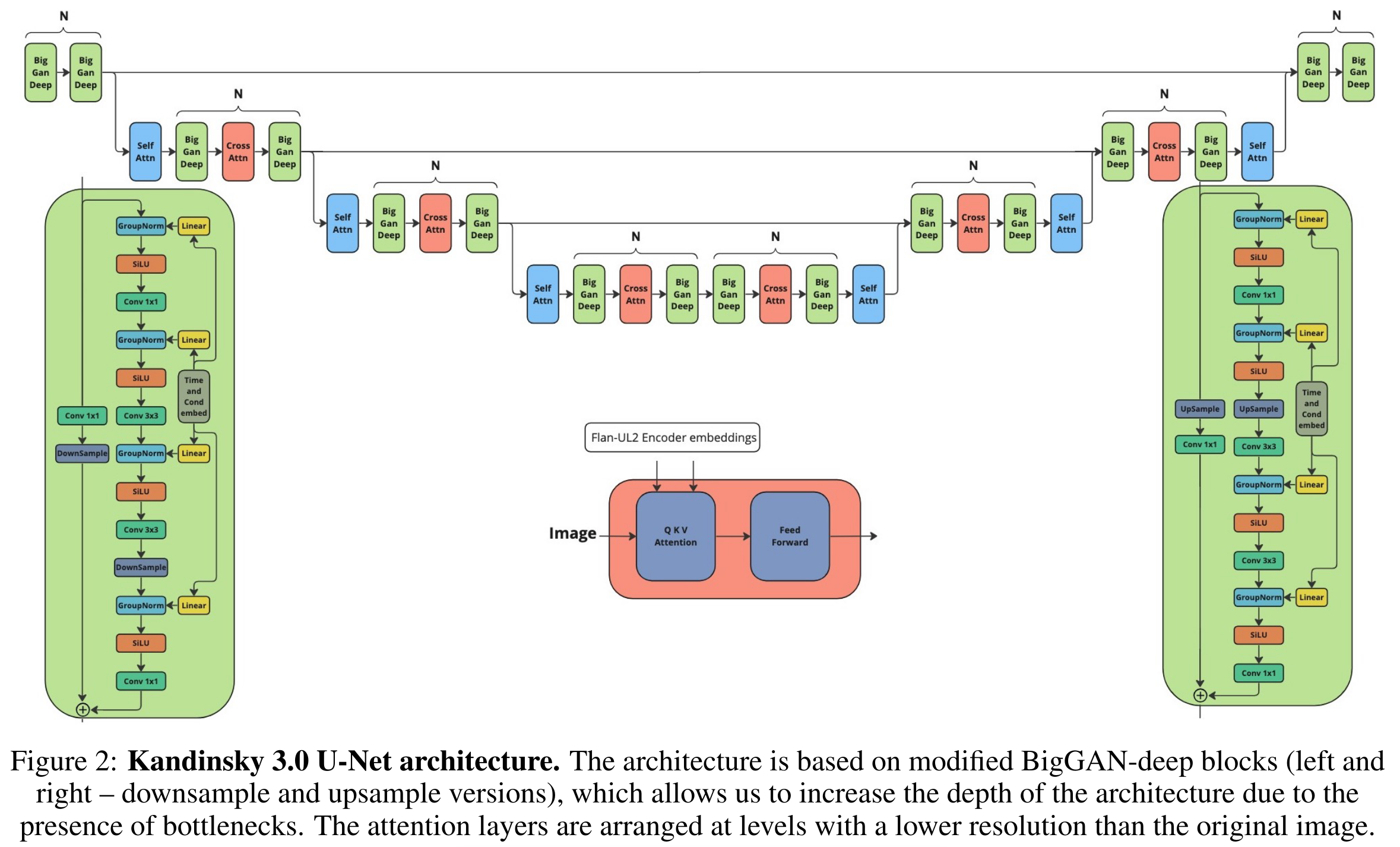
-
我们的BigGAN-deep残差块版本与 BigGANs 中提出的版本有以下不同之处:
- 我们使用 GN 而不是 BN;
- 我们使用 SiLU 而不是ReLU;
- 作为跳跃连接,我们在标准的 BigGAN 残差块中实现它们。例如,在U-Net的放大部分,我们不会丢弃通道,而是进行上采样并应用1×1核的卷积。
text encoder
- 文本编码器使用目前最强大的编码器解码器开源模型之一,即 Flan-UL2 20B 模型的 8.6B 编码器。该模型基于预训练的 UL2 20B模型,目前是开源的最强大的编码器解码器模型。除了在大量文本语料库上进行预训练外,Flan-UL2 还使用Flan Prompting 进行了许多语言任务的监督微调。我们的实验证明,这样的微调也显著改善了图像生成效果。
Sber-MoVQGAN
-
为在文本和人脸等复杂领域实现高质量的图像重建,我们开发了 Sber-MoVQGAN 自编码器,在 Kandinsky 2.2 中取得了良好的结果。
-
Sber-MoVQGAN 架构基于 VQGAN 架构,并添加了 MoVQ 的空间条件归一化。空间条件归一化的实现方式类似于 StyleGAN 架构中使用的自适应实例归一化(AdaIN)层,其计算公式为:
F i = ? γ ( z q ) F i ? 1 ? μ ( F i ? 1 ) σ ( F i ? 1 ) + ? β ( z q ) F_i = \phi_\gamma(z_q)\frac{F_{i-1} - \mu(F_{i-1})}{\sigma(F_{i-1})} + \phi_\beta(z_q) \quad Fi?=?γ?(zq?)σ(Fi?1?)Fi?1??μ(Fi?1?)?+?β?(zq?)
其中, F i ? 1 F_{i-1} Fi?1? 是中间特征图, z q z_q zq? 是 encoder 输出的量化后的 latent 特征, μ \mu μ 和 σ \sigma σ 是激活的均值和标准差计算函数, ? γ \phi_\gamma ?γ? 和 ? β \phi_\beta ?β? 是可训练的仿射变换,将 z q z_q zq? 转换为缩放和偏置值。我们的实现的其他重要特征包括在训练阶段使用了 EMA(指数移动平均)权重和修改的来自 ViT-VQGAN 的损失函数。 -
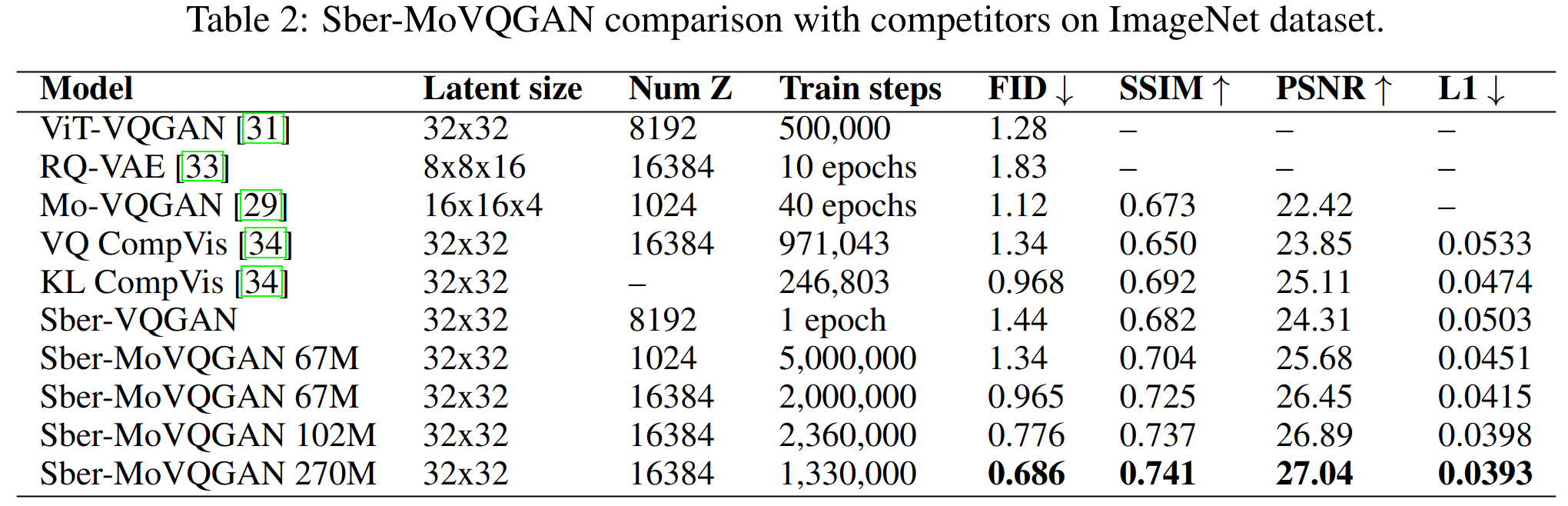
我们训练了 Sber-MoVQGAN 的三个版本 – 67M、102M 和 270M。67M版本与标准 VQGAN 的大小相同。102M 模型相较于 67M 使用了两倍数量的残差块,而270M模型则使用了两倍原始通道数。Kandinsky 3.0使用270M模型作为图像解码器。我们在 LAION HighRes 数据集上训练了 Sber-MoVQGAN,获得了在图像重建方面的 SOTA 结果。我们在下表中对我们的自编码器与竞争对手以及 Sber-VQGAN 进行了比较。我们在开源许可下发布了这些模型的权重和代码。
数据
- 在训练过程中,我们使用了一个大型的线上收集的文本图像对数据集。训练数据集包括流行的开源数据集以及我们内部的约 1.5 亿个文本图像对。
- 为提高数据质量,我们通过了几个过滤器:图像的审美质量、水印检测、图像与文本的 CLIP 相似性以及感知哈希检测重复。
- 我们发现从Common Crawl 收集的数据几乎不包含与俄罗斯文化相关的图像。为解决这个问题,我们收集并标注了一个包含 20 万个苏联和俄罗斯卡通、名人和地点文本图像对的数据集。该数据集有助于提高模型在生成与俄罗斯相关的图像时的质量和文本对齐。
- 我们还将所有数据分为两类。我们在低分辨率预训练的初始阶段使用第一类数据,而在最后阶段使用混合和高分辨率微调时使用第二类数据。
- 第一类包括像 LAION-5B 和 COYO-700M 这样的开源大型文本图像数据集以及我们从互联网收集的“脏”数据
- 第二类包含相同的数据集,但使用更严格的过滤器,尤其是图像审美质量
训练
我们将训练过程分为以下几个阶段,以使用更多的数据并训练模型在广泛的分辨率范围内生成图像:
- 256 × 256 分辨率:11亿文本图像对,批量大小 = 20,训练步数为60万,使用104台NVIDIA Tesla A100;
- 384 × 384 分辨率:7.68亿文本图像对,批量大小 = 10,训练步数为50万,使用104台NVIDIA Tesla A100;
- 512 × 512 分辨率:4.5亿文本图像对,批量大小 = 10,训练步数为40万,使用104台NVIDIA Tesla A100;
- 768 × 768 分辨率:2.24亿文本图像对,批量大小 = 4,训练步数为25万,使用416台NVIDIA Tesla A100;
- 混合分辨率:7682 ≤ W × H ≤ 10242,2.8亿文本图像对,批量大小 = 1,训练步数为35万,使用416台NVIDIA Tesla A100。
应用
Inpainting and Outpainting
- 实现与 GLIDE 相同,从基础 Kandinsky 模型权重初始化 inpainting 模型
- 修改 U-Net 的输入卷积层,以便输入还能接受图像 latent 和掩码。因此,U-Net 的输入通道增至 9 个:4 个用于原始 latent,4 个用于图像 latent,以及一个额外的通道用于掩码。我们将额外的权重置零,因此训练始于基础模型。
- 在训练过程中,我们生成以下形式的随机掩码:矩形、圆形、笔画和任意形状。对于每个图像样本,我们使用最多 3 个掩码,并为每个图像使用唯一的掩码。我们使用与基础模型训练相同的数据集,其中包括生成的掩码。我们使用 Lion 进行训练,lr=1e-5,并在前 1 万步训练应用线性 warmup。总共训练 250 万步。

Image-to-Video Generation
- 图像到视频生成涉及一系列迭代步骤,包括下图中所示的四个阶段。我们的动画 pipeline 基于 Deforum 技术
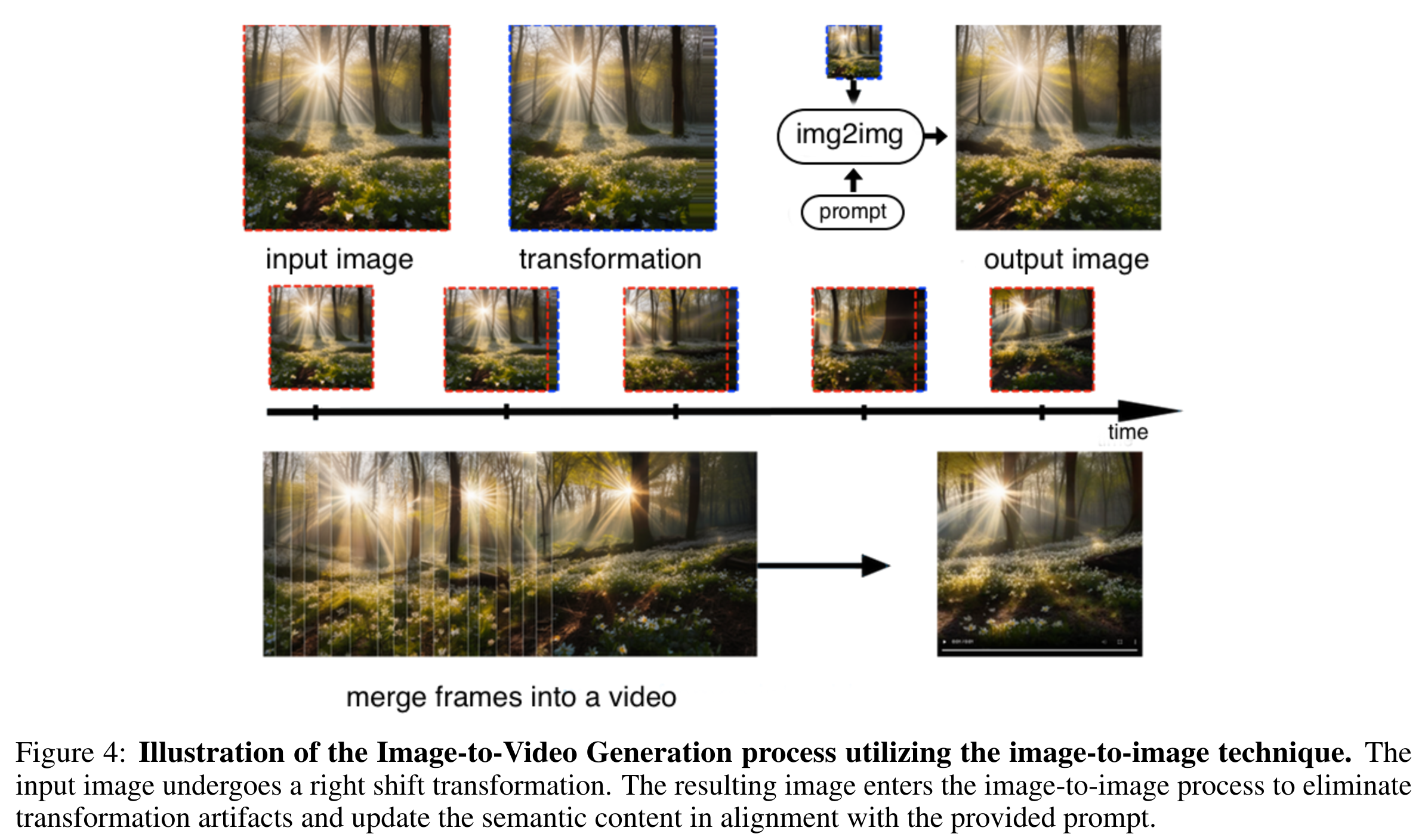
- 包括一系列应用于场景的变换
- 将图像转换为具有深度图的三维表示;
- 对结果场景应用空间变换以产生动画效果;
- 将2.5D场景投影回2D图像;
- 通过图像到图像转换技术消除变换缺陷并更新语义。
- 包括一系列应用于场景的变换
Text-to-Video
- 基于Kandinsky 3.0模型,我们还创建了文本到视频生成流程 Kandinsky Video,除了包含文本编码器和图像解码器外,还包括两个模型——用于关键帧生成和在它们之间插值的模型。这两个模型都使用 Kandinsky 3.0 的预训练权重作为骨干。
Experiments
人工评测
- 每个人根据两个标准选择最佳图像:1. 图像内容与提示的对齐度(文本理解);2. 图像的视觉质量。我们总体比较了所有类别的视觉质量和文本理解,以及每个类别的独立比较
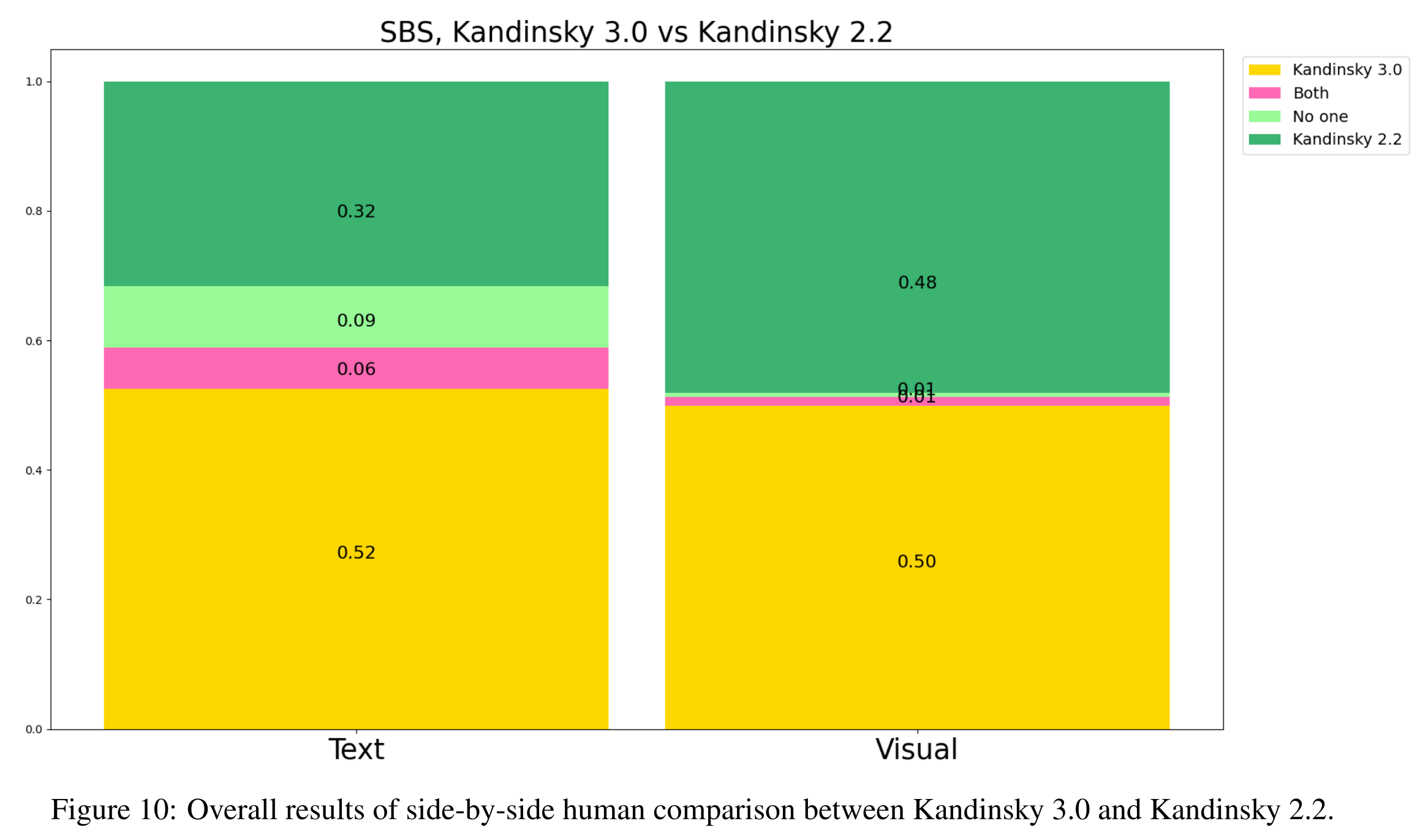
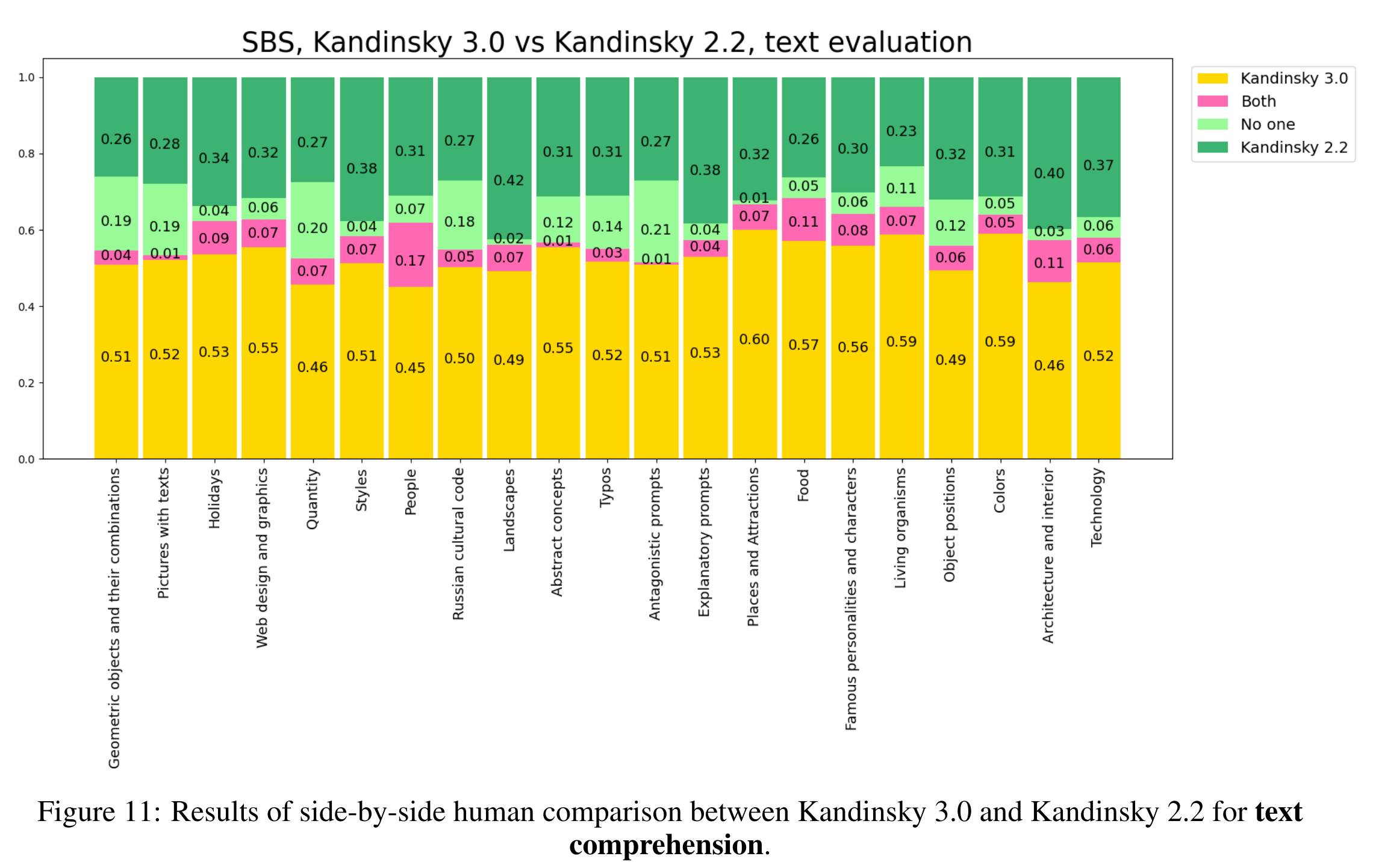
与上一代模型对比
- 有明显提升(黄色比例更大)

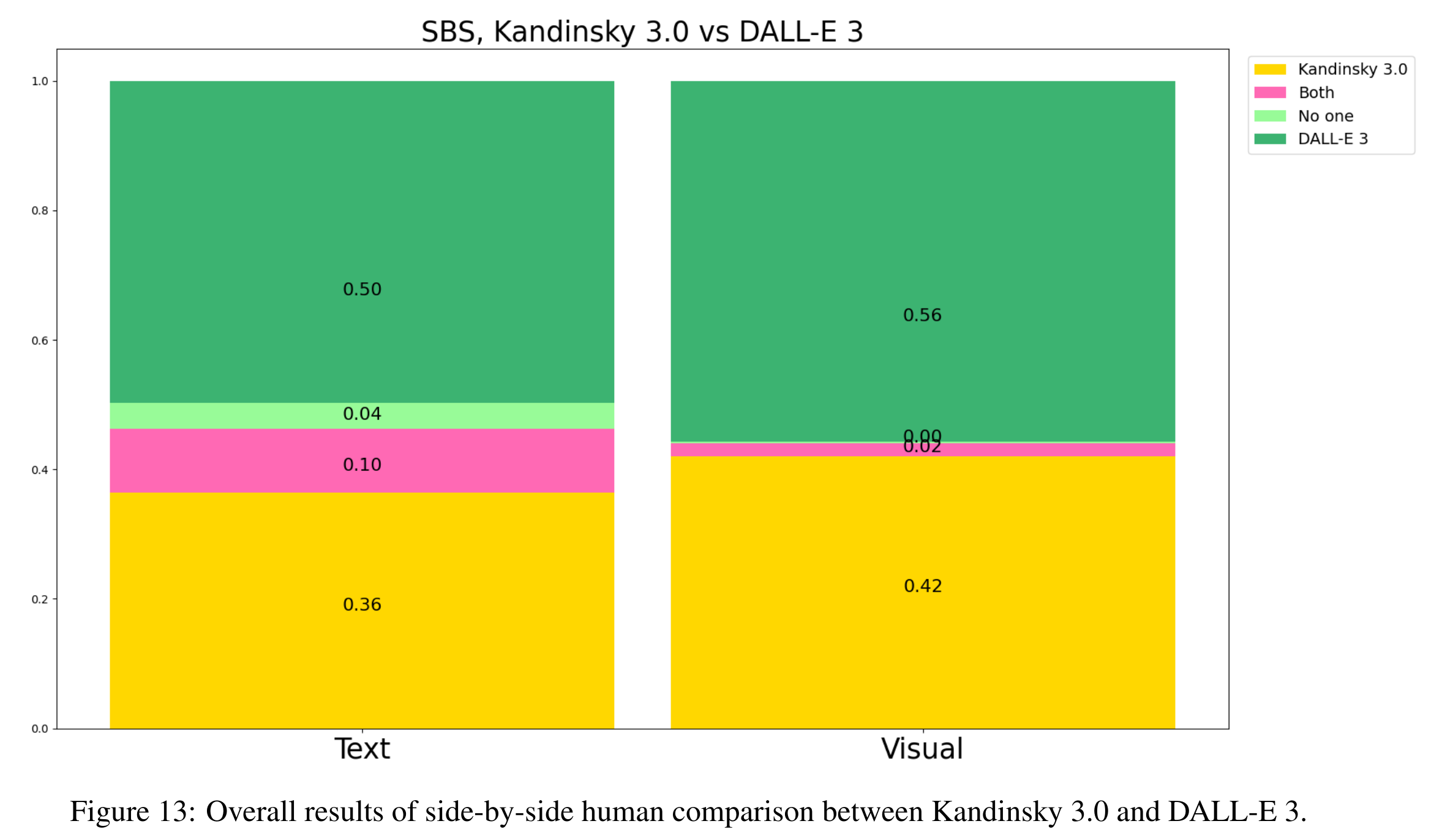
与 DALLE 比较
- 不如 DALLE
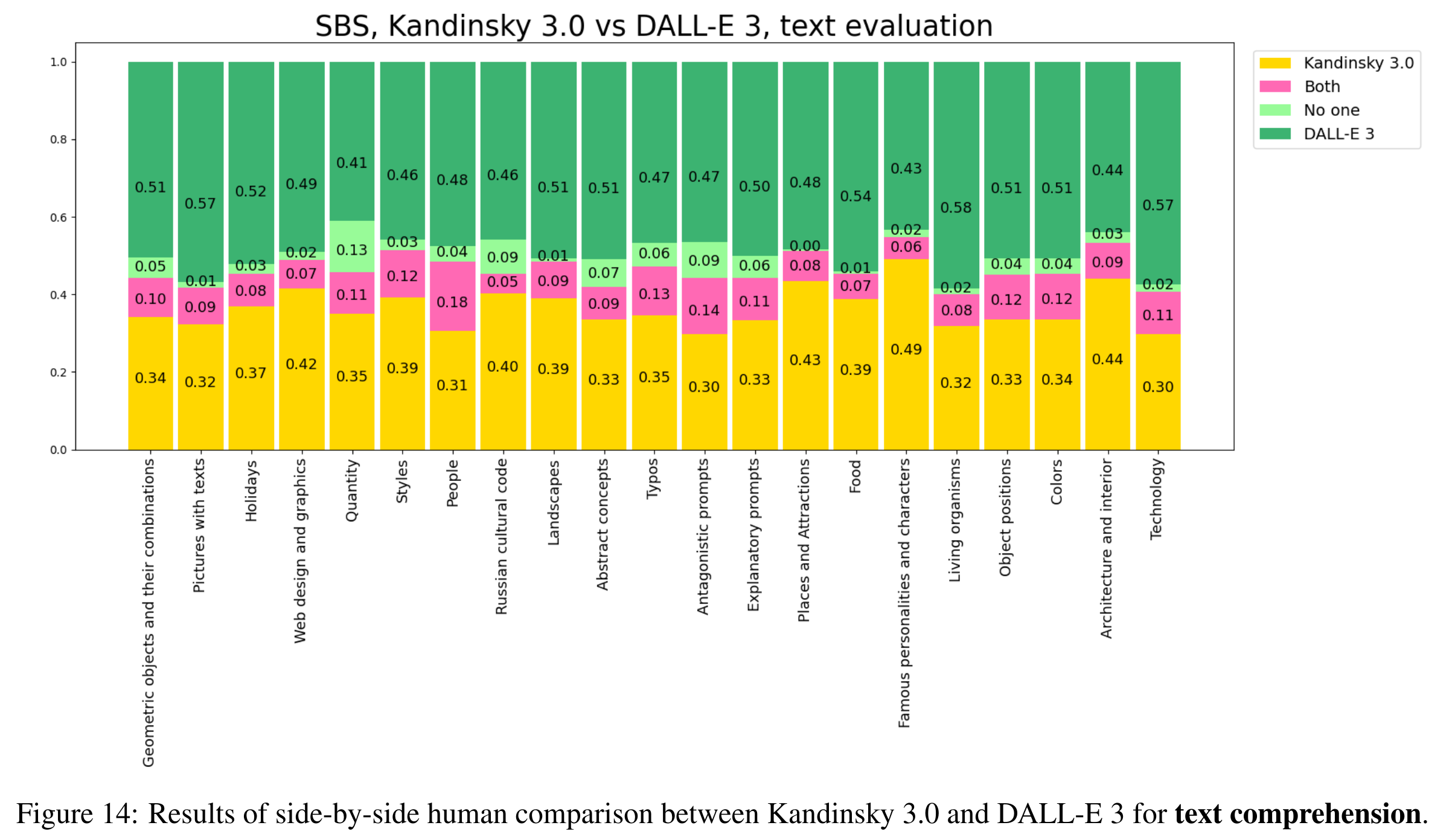
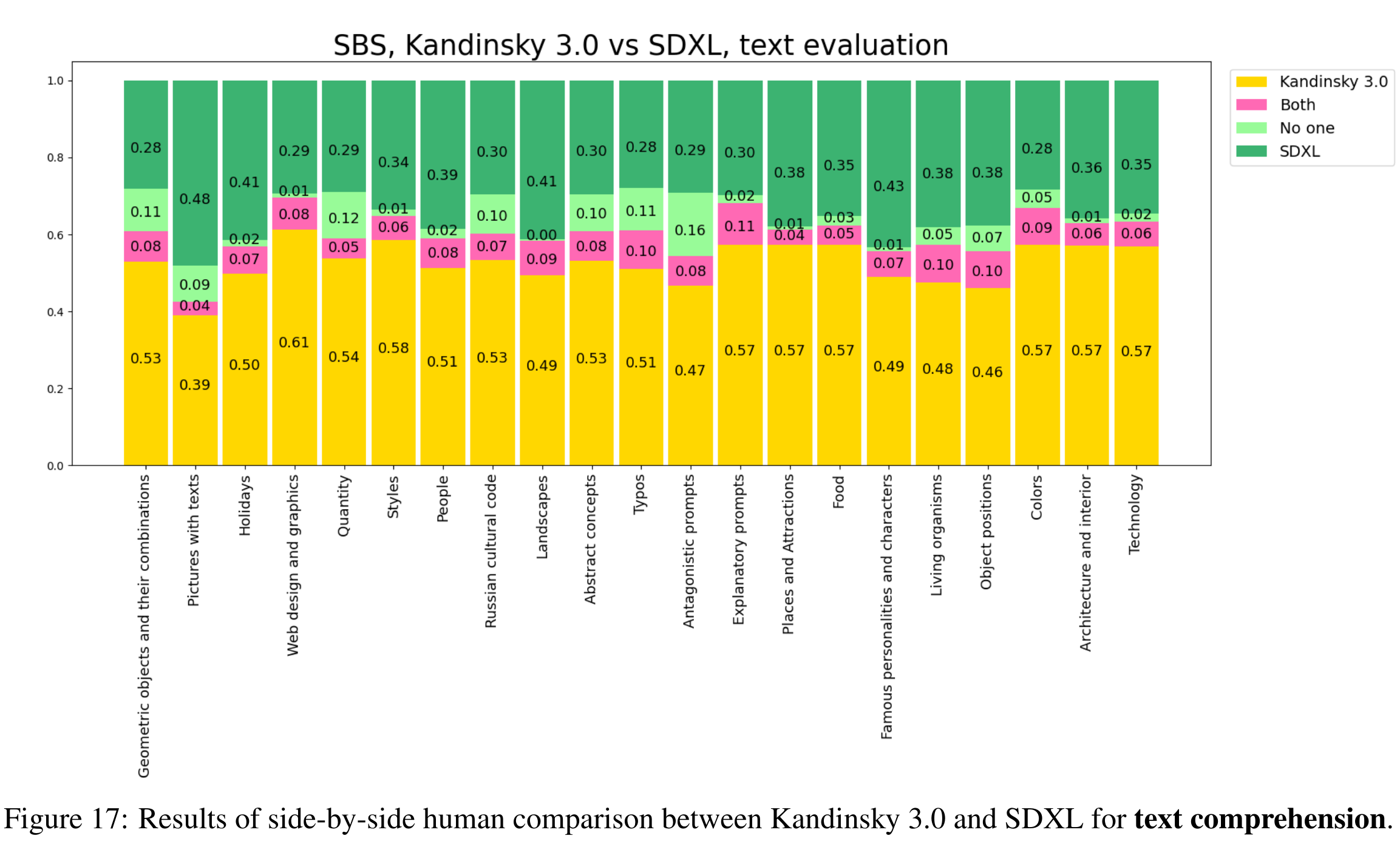
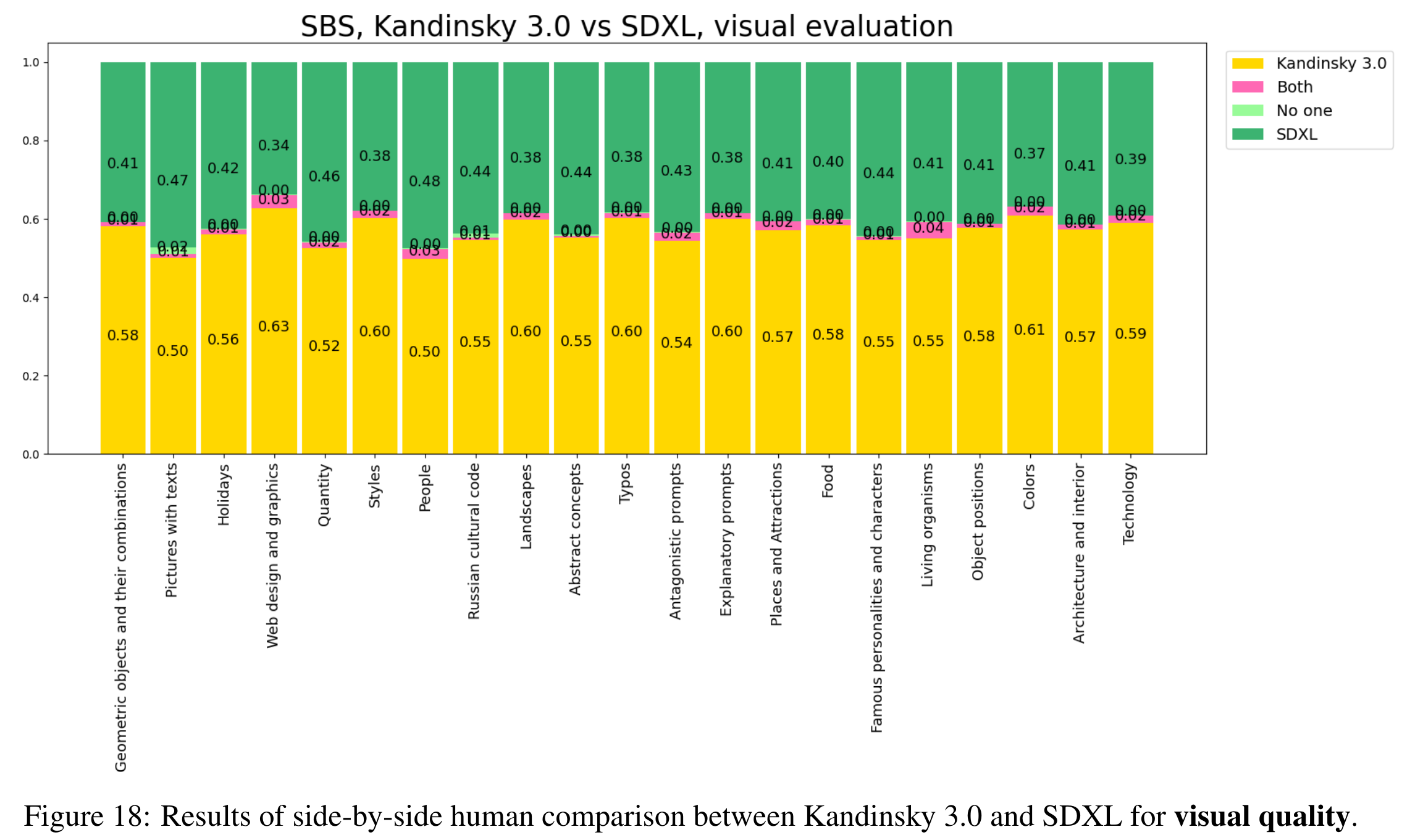
与 SDXL 比较
- 整体效果优于 SDXL,不过 pictures with texts 这一项还是明显不如 SDXL
Thoughts
- 开源诚意很好的工作,不过实验部分对比不够充分
- 通过加大模型参数量的方式在 autoencoder 层面上达到了 SOTA
- 针对俄罗斯做了一些体验优化,优化方式主要在数据层面
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!