《十堂课学习 Flink》第五章:Table API 以及 Flink SQL 入门
第四章中介绍了 DataStream API 以及 DataSet API 的入门案例,本章开始介绍 Table API 以及基于此的高层应用 Flink SQL 的基础。
5.1 Flink Table & SQL 基础知识
Flink 提供了两个关系API——Table API 和 SQL——用于统一的流和批处理。Table API 是一种针对Java、Scala和Python的语言集成查询API,它允许以非常直观的方式组合来自关系运算符(如选择、筛选和联接)的查询。Flink的SQL支持基于Apache Calcite,后者实现了SQL标准。无论输入是连续的(流式)还是有界的(批处理),在任一接口中指定的查询都具有相同的语义并指定相同的结果。
Table API和SQL接口与彼此以及Flink的DataStream API无缝集成。您可以轻松地在所有API和基于它们构建的库之间切换。
SQL是数据分析中使用最广泛的语言。Flink的Table API和SQL使用户能够用更少的时间和精力定义高效的流分析应用程序。此外,Flink Table API和SQL得到了有效的优化,它集成了大量的查询优化和优化的运算符实现。但并非所有优化都是默认启用的,因此对于某些工作负载,可以通过启用某些选项来提高性能。
5.2 DataStream / DataSet API & Table API & SQL 之间的关系
如下图所示,现在从下往上我们逐层介绍。
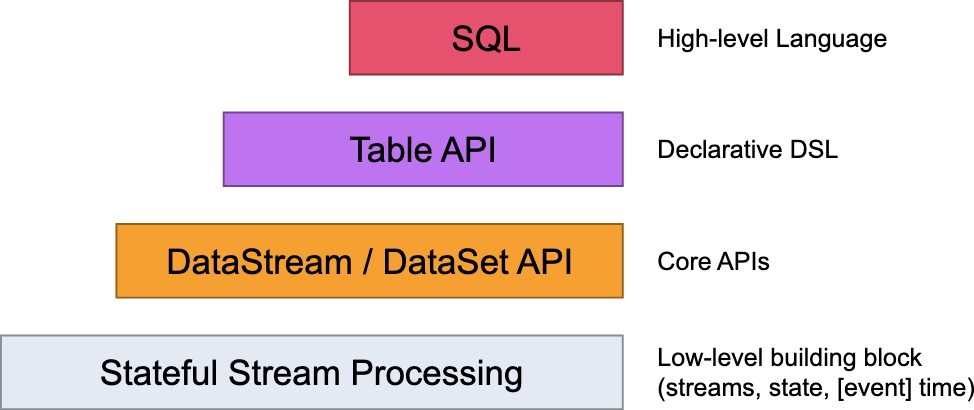
- 最低级别的抽象只是提供有状态和及时的流处理。它通过Process Function嵌入到DataStream API中。它允许用户自由处理来自一个或多个流的事件,并提供一致的容错状态。此外,用户可以注册事件时间和处理时间回调,使程序能够实现复杂的计算。
- 在实践中,许多应用程序不需要上面描述的低级抽象,而是可以根据核心API进行编程:DataStream API(有界/无界流)。这些流畅的API为数据处理提供了通用的构建块,如各种形式的用户指定的转换、联接、聚合、窗口、状态等。在这些API中处理的数据类型在各自的编程语言中表示为类。
低级别的Process Function与DataStream API集成在一起,从而可以按需使用低级别的抽象。数据集API在有界数据集上提供了额外的基元,如循环/迭代。 - Table API是一个以表为中心的声明性DSL,表可以是动态变化的表(当表示流时)。Table API遵循(扩展的)关系模型:表附加了一个模式(类似于关系数据库中的表),API提供了类似的操作,如选择、项目、联接、分组传递、聚合等。Table API程序以声明的方式定义了应该执行的逻辑操作,而不是确切地指定操作代码的外观。虽然Table API可以通过各种类型的用户定义函数进行扩展,但它的表达能力不如Core API,使用起来更简洁(编写的代码更少)。此外,Table API 程序还通过一个优化器,该优化器在执行之前应用优化规则。
可以在表和数据流/数据集之间无缝转换,允许程序将表API与数据流和数据集API混合。 - Flink提供的最高级别抽象是SQL。这种抽象在语义和表达上都类似于Table API,但将程序表示为SQL查询表达式。SQL抽象与Table API密切交互,SQL查询可以在Table API中定义的表上执行。
5.3 Flink Table API 添加依赖
在前面的例子中,我们已经添加了 flink-clients 核心依赖,现在使用Table API 时,需要额外添加两个依赖,如下所示:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
其中,${flink.version} 为 1.14.6 ,而 {scala.binary.version} 为 2.11。
5.4 Flink Table API / SQL 第一个例子 StreamSQLExample
这个例子大概可以理解为:总共两个订单,每个订单里包含三条记录,总共六条记录。形成一张表,然后根据订单中 product 字段进行 UNION 操作,并把最终结果打印。
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import java.util.Arrays;
/**
* 摘录自 flink 1.14.6 源码例子
* @author Smileyan
*/
public class StreamSQLExample {
public static void main(String[] args) throws Exception {
// set up the Java DataStream API
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// set up the Java Table API
final StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
final DataStream<Order> orderA =
env.fromCollection(
Arrays.asList(
new Order(1L, "beer", 3),
new Order(1L, "diaper", 4),
new Order(3L, "rubber", 2)));
final DataStream<Order> orderB =
env.fromCollection(
Arrays.asList(
new Order(2L, "pen", 3),
new Order(2L, "rubber", 3),
new Order(4L, "beer", 1)));
// convert the first DataStream to a Table object
// it will be used "inline" and is not registered in a catalog
final Table tableA = tableEnv.fromDataStream(orderA);
// convert the second DataStream and register it as a view
// it will be accessible under a name
tableEnv.createTemporaryView("TableB", orderB);
// union the two tables
final Table result =
tableEnv.sqlQuery(
"SELECT * FROM "
+ tableA
+ " WHERE amount > 2 UNION ALL "
+ "SELECT * FROM TableB WHERE amount < 2");
// convert the Table back to an insert-only DataStream of type `Order`
tableEnv.toDataStream(result, Order.class).print();
// after the table program is converted to a DataStream program,
// we must use `env.execute()` to submit the job
env.execute();
}
// *************************************************************************
// USER DATA TYPES
// *************************************************************************
/** Simple POJO. */
public static class Order {
public Long user;
public String product;
public int amount;
// for POJO detection in DataStream API
public Order() {}
// for structured type detection in Table API
public Order(Long user, String product, int amount) {
this.user = user;
this.product = product;
this.amount = amount;
}
@Override
public String toString() {
return "Order{"
+ "user="
+ user
+ ", product='"
+ product
+ '\''
+ ", amount="
+ amount
+ '}';
}
}
}

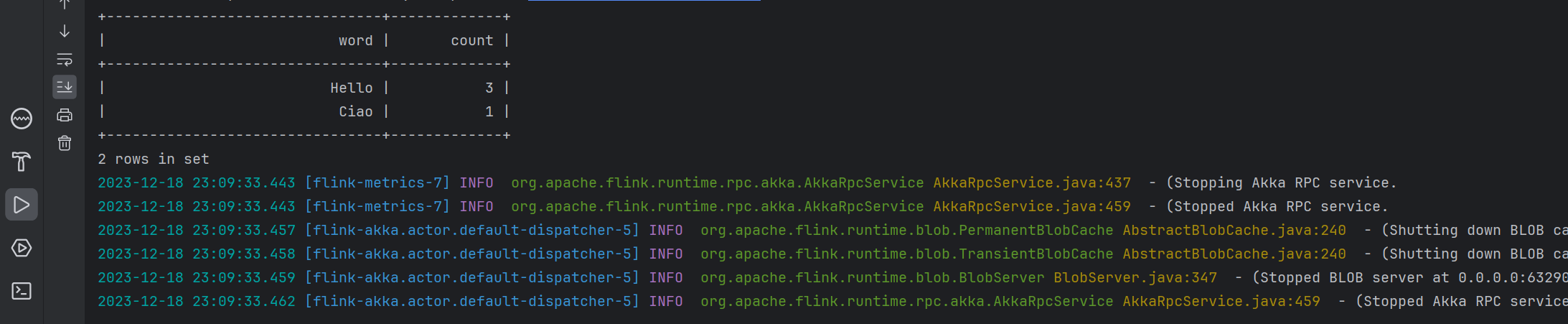
5.5 Flink Table API / SQL 第二个例子 WordCountSQLExample
这个例子更加简单,因为连 union 的操作都已经省去了,直接从一个表中进行SELECT。
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.TableEnvironment;
/**
*
* @author Smileyan
*/
public class WordCountSQLExample {
public static void main(String[] args) {
// set up the Table API
final EnvironmentSettings settings = EnvironmentSettings.newInstance().inBatchMode().build();
final TableEnvironment tableEnv = TableEnvironment.create(settings);
// execute a Flink SQL job and print the result locally
tableEnv.executeSql(
// define the aggregation
"SELECT word, SUM(frequency) AS `count`\n"
// read from an artificial fixed-size table with rows and columns
+ "FROM (\n"
+ " VALUES ('Hello', 1), ('Ciao', 1), ('Hello', 2)\n"
+ ")\n"
// name the table and its columns
+ "AS WordTable(word, frequency)\n"
// group for aggregation
+ "GROUP BY word")
.print();
}
}
5.6 参考资料
https://github.com/apache/flink/tree/release-1.14.6
https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/concepts/overview/
5.7 总结
第四章介绍了DataStream API和DataSet API的入门案例,而第五章则开始介绍了Table API以及基于其上的高层应用Flink SQL的基础知识。
在5.1中,阐述了Flink提供的两个关系API——Table API和SQL,用于统一流和批处理。无论是处理连续的流数据还是有界的批处理数据,在这两个接口中指定的查询具有相同的语义和结果。Table API和SQL接口与DataStream API无缝集成,用户可以轻松在它们之间切换。
5.2详细描述了DataStream、DataSet、Table API以及SQL之间的关系。从最低级别的抽象开始,介绍了DataStream API的Process Function,然后是DataStream API和DataSet API的一般构建块,最后到以表为中心的声明性DSL——Table API。最高级别的抽象是SQL,与Table API密切交互,允许通过SQL查询表达式执行操作。
在5.3中,介绍了Flink Table API的添加依赖,以及相应的Maven配置。
最后,在5.4和5.5中给出了两个Flink Table API / SQL的例子。StreamSQLExample展示了使用Table API和SQL进行流处理的例子,而WordCountSQLExample则展示了一个简单的批处理Flink SQL作业。
总体而言,本章深入介绍了Flink的Table API和SQL,以及它们与DataStream和DataSet API的关系,为使用Flink进行流和批处理提供了全面的基础知识。
Smileyan
2023.12.18 23:14
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!