机器学习——支持向量机(SVM)
今天由我来向大家介绍支持向量机及如何实现。
一、支持向量机
1.1定义
支持向量机(support vector machines,SVM)是一种二分类模型,它的目的是寻找一个超平面来对样本进行分割,分割的原则是间隔最大化。SVM的目标就是要找到这个超平面。
支持向量机思想直观,但细节复杂,涵盖凸优化,核函数,拉格朗日算子等理论。
1.2支持向量机类分类

1.3支持向量机的优缺点?
优点:
- 支持向量机算法可以解决小样本情况下的机器学习问题,简化了通常的分类和回归等问题。
- 由于采用核函数方法克服了维数灾难和非线性可分的问题,所以向高维空间映射时没有增加计算的复杂性。换句话说,由于支持向量计算法的最终决策函数只由少数的支持向量所确定,所以计算的复杂性取决于支持向量的数目,而不是样本空间的维数。
- 支持向量机算法利用松弛变量可以允许一些点到分类平面的距离不满足原先要求,从而避免这些点对模型学习的影响。
缺点:
- 支持向量机算法对大规模训练样本难以实施。这是因为支持向量机算法借助二次规划求解支持向量,这其中会涉及m阶矩阵的计算,所以矩阵阶数很大时将耗费大量的机器内存和运算时间。
- 经典的支持向量机算法只给出了二分类的算法,而在数据挖掘的实际应用中,一般要解决多分类问题,但支持向量机对于多分类问题解决效果并不理想。
- SVM算法效果与核函数的选择关系很大,往往需要尝试多种核函数,即使选择了效果比较好的高斯核函数,也要调参选择恰当的参数λ。另一方面就是现在常用的SVM理论都是使用固定惩罚系数C ,但正负样本的两种错误造成的损失是不一样的。
二、基本概念?
 ?
?
2.1线性可分
对于一个数据集合可以画一条直线将两组数据点分开,这样的数据称为线性可分(linearly separable)。如下图所示:
 ?
?
2.2分割超平面
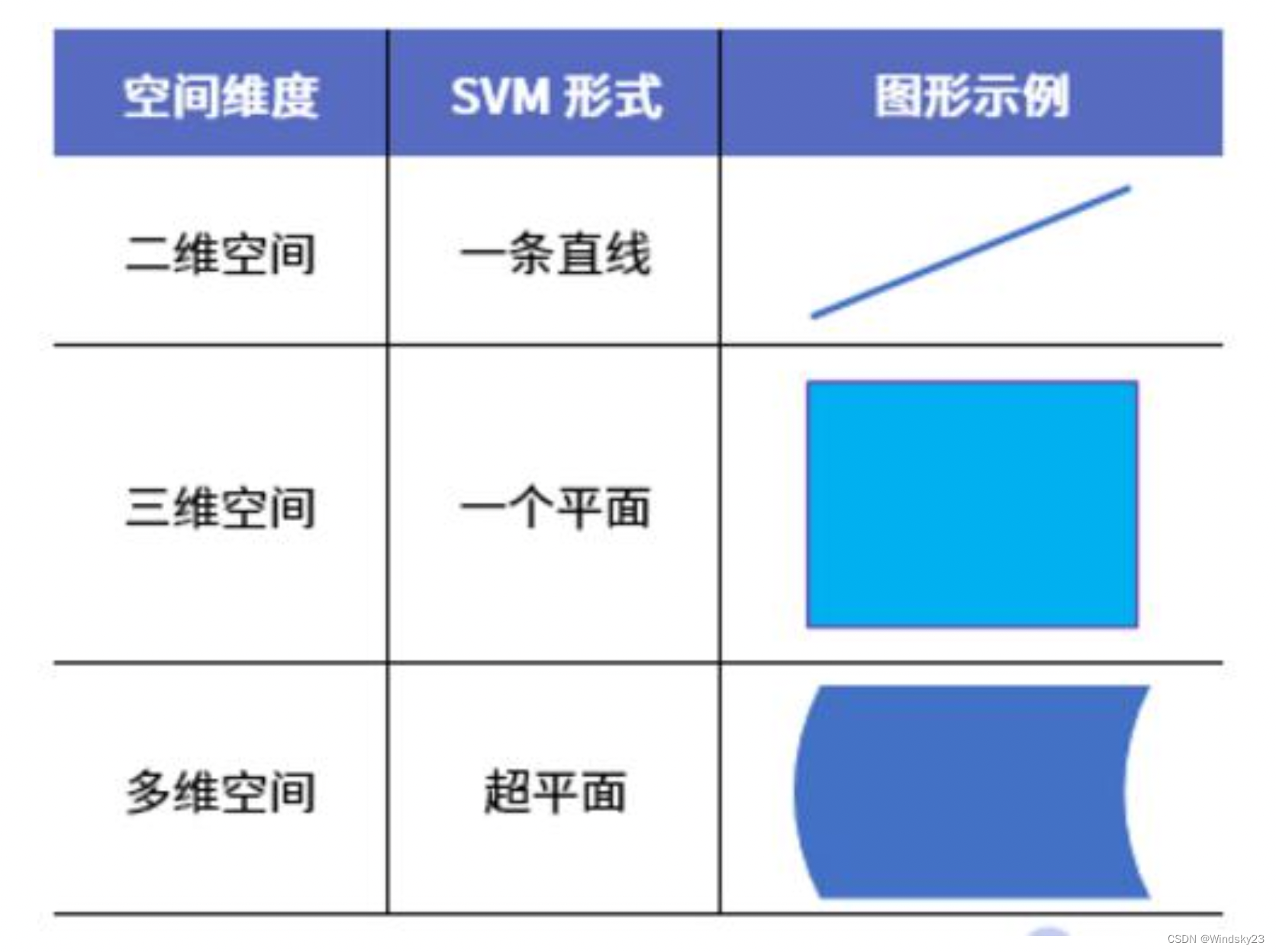
将上述数据集分隔开来的直线成为分隔超平面。对于二维平面来说,分隔超平面就是一条直线。?
2.3超平面
对于三维及三维以上的数据来说,分隔数据的是个平面,称为超平面,也就是分类的决策边界。?
2.4点相对于分割面的间隔
点到分割面的距离,称为点相对于分割面的间隔。
2.5间隔
数据集所有点到分隔面的最小间隔的2倍,称为分类器或数据集的间隔。论文中提到的间隔多指这个间隔。SVM分类器就是要找最大的数据集间隔。?
2.6支持向量
?离分隔超平面最近的那些点。
三、最大间隔?
最大间隔是支持向量机的核心思想,因此我们首先来了解如何寻找最大间隔。
3.1分隔超平面
二维空间一条直线的方程为,y=ax+b,推广到n维空间,就变成了超平面方程,即,其中w是权重,b是截距,训练数据就是训练得到权重和截距。
3.2?如何决定最好的参数

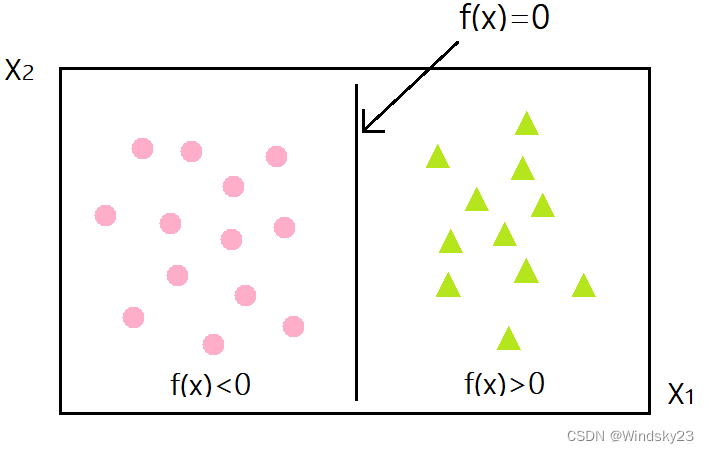
支持向量机的核心思想: 最大间隔化, 最不受到噪声的干扰。如上图所示,分类器A比分类器B的间隔(蓝色阴影)大。

SVM划分的超平面:f(x) = 0,w为法向量,决定超平面方向,
假设超平面将样本正确划分
f(x) ≥ 1,y = +1
f(x) ≤ ?1,y = ?1
间隔:d=2/|w|?
解释一下这个间隔的由来:上图中的X对应的点x1代入得到式1:,
对应的点x2代入得到式2:
,将式1-式2得到:
,根据向量相乘的性质
,由上图可以看处
,即
,所以
最大化间隔也就是寻找参数w和b , 使得下述公式最大

?上式就是求解最大间隔超平面的表达式。?
四、对偶问题?
4.1不等式约束的KKT条件
给定一个目标函数 f : Rn→R,希望找到x∈Rn ,在满足约束条件g(x)=0的前提下,使得f(x)有最小值。该约束优化问题记为:?
minf(x)
??g(x)=0
可建立拉格朗日函数:L(x,λ)=f(x)+λg(x)
?
其中 λ 称为拉格朗日乘数。因此,可将原本的约束优化问题转换成等价的无约束优化问题:
?分别对待求解参数求偏导,可得:
一般联立方程组可以得到相应的解。
将约束等式 g(x)=0 推广为不等式 g(x)≤0。这个约束优化问题可改为:
minf(x)
??g(x)≤0
同理,其拉格朗日函数为:
L(x,λ)=f(x)+λg(x)
拉格朗日乘子法的几何意义即在等式g(x)=0或在不等式约束g(x)≤0下最小化目标函数f(x),如下图:
?
其约束范围为不等式,因此可等价转换为Karush-Kuhn-Tucker (KKT)条件
▽xL=▽f+λ▽g=0
g(x)≤0
λ≥0
λg(x)=0
?
在此基础上,通过优化方式(如二次规划或SMO)求解其最优解。
4.2拉格朗日乘法
?我们先看一下支持向量机的目标函数与约束函数:
第一步:引入拉格朗日乘子≥0得到拉格朗日函数
第二步:令L(w,b,α)
,
第三步:w,b回代到第一步
![]()
第四步:转换为对偶形式
第五步:最终模型
,其中未知数为
五、SMO算法
5.1Platt的SMO算法?
1996年,John Platt发布了一个称为SMO的强大算法,用于训练SVM。
SMO表示序列最小化(Sequential Minimal Optimizaion)。Platt的SMO算法是将大优化问题分解为多个小优化问题来求解的。这些小优化问题往往很容易求解,并且对它们进行顺序求解的结果与将它们作为整体来求解的结果完全一致的。在结果完全相同的同时,SMO算法的求解时间短很多。
SMO算法的目标是求出一系列alpha和b,一旦求出了这些alpha,就很容易计算出权重向量w并得到分隔超平面。
SMO算法的工作原理是:每次循环中选择两个alpha进行优化处理。一旦找到了一对合适的alpha,那么就增大其中一个同时减小另一个。
这里所谓的"合适"就是指两个alpha必须符合以下两个条件,条件之一就是两个alpha必须要在间隔边界之外,而且第二个条件则是这两个alpha还没有进进行过区间化处理或者不在边界上。
5.2SMO算法的基本思路
1.如果所有的变量的解都满足最优化问题的KKT条件 那么这个最优化问题的解就得到了
2.否则选择两个变量 固定其他变量(任意选择两个拉格朗日乘子) 针对这两个变量构建一个二次规划问题
这个二次规划问题关于这两个变量的解应该更加接近二次规划问题的解 使得二次规划问题的目标函数值变得更小
3.此时: 子问题有两个变量 一个是违反KKT条件最严重的一个 一个是由约束条件自动确定的
注意: 选择两个变量实质上只有一个自由变量
因为等式约束:
重点:SMO算法实质上包含两个部分
1. 求解两个变量二次规划的解析方法
2.选择变量的启发式方法
5.3应用简化版SMO算法处理小规模数据集
数据集

?
from numpy import *
import matplotlib.pyplot as plt
# 读取数据
def loadDataSet(fileName):
dataMat = [] # 数据矩阵
labelMat = [] # 数据标签
fr = open(fileName) # 打开文件
for line in fr.readlines(): # 遍历,逐行读取
lineArr = line.strip().split() # 去除空格
dataMat.append([float(lineArr[0]), float(lineArr[1])]) # 数据矩阵中添加数据
labelMat.append(float(lineArr[2])) # 数据标签中添加标签
return dataMat, labelMat
# 绘制数据集
def showData():
dataMat, labelMat = loadDataSet('testSet.txt') # 加载数据集,标签
dataArr = array(dataMat) # 转换成numPy的数组
n = shape(dataArr)[0] # 获取数据总数
xcord1 = []; ycord1 = [] # 存放正样本
xcord2 = []; ycord2 = [] # 存放负样本
for i in range(n): # 依据数据集的标签来对数据进行分类
if int(labelMat[i]) == 1: # 数据的标签为1,表示为正样本
xcord1.append(dataArr[i, 0]); ycord1.append(dataArr[i, 1])
else: # 否则,若数据的标签不为1,表示为负样本
xcord2.append(dataArr[i, 0]); ycord2.append(dataArr[i, 1])
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(xcord1, ycord1, s=15, c='blue') # 绘制正样本
ax.scatter(xcord2, ycord2, s=15, c='red', marker='s') # 绘制负样本
plt.title('DateSet') # 标题
plt.xlabel('X1'); plt.ylabel('X2') # x,y轴的标签
plt.show()
showData()
?运行结果

这就是我们使用的二维数据集,显然线性可分。现在我们使用简化版的SMO算法进行求解。
from numpy import *
import matplotlib.pyplot as plt
# 读取数据
def loadDataSet(fileName):
dataMat = [] # 数据矩阵
labelMat = [] # 数据标签
fr = open(fileName) # 打开文件
for line in fr.readlines(): # 遍历,逐行读取
lineArr = line.strip().split() # 去除空格
dataMat.append([float(lineArr[0]), float(lineArr[1])]) # 数据矩阵中添加数据
labelMat.append(float(lineArr[2])) # 数据标签中添加标签
return dataMat, labelMat
# 随机选择alpha
def selectJrand(i, m):
j = i # 选择一个不等于i的j
while (j == i): # 只要函数值不等于输入值i,函数就会进行随机选择
j = int(random.uniform(0, m))
return j
# 修剪alpha
def clipAlpha(aj, H, L): # 用于调整大于H或小于L的alpha值
if aj > H:
aj = H
if L > aj:
aj = L
return aj
# 简化版SMO算法
def smoSimple(dataMatIn, classLabels, C, toler, maxIter):
dataMatrix = mat(dataMatIn) # 数据矩阵dataMatIn转换为numpy的mat存储
labelMat = mat(classLabels).transpose() # 数据标签classLabels转换为numpy的mat存储
b = 0; m, n = shape(dataMatrix) # 初始化b参数,统计dataMatrix的维度m*n
alphas = mat(zeros((m, 1))) # 初始化alpha参数为0
iter = 0 # 初始化迭代次数0
while (iter < maxIter): # matIter表示最多迭代次数,iter变量达到输入值maxIter时,函数结束运行并退出
alphaPairsChanged = 0 # 变量alphaPairsChanged用于记录alpha是否已经进行优化
for i in range(m):
# 步骤1:计算误差Ei
fXi = float(multiply(alphas, labelMat).T * (dataMatrix * dataMatrix[i, :].T)) + b
Ei = fXi - float(labelMat[i])
# 优化alpha,同时设定容错率
if ((labelMat[i] * Ei < -toler) and (alphas[i] < C)) or ((labelMat[i] * Ei > toler) and (alphas[i] > 0)):
j = selectJrand(i, m) # 随机选择另一个与alpha_i成对优化的alpha_j
# 步骤1:计算误差Ej
fXj = float(multiply(alphas, labelMat).T * (dataMatrix * dataMatrix[j, :].T)) + b
Ej = fXj - float(labelMat[j])
# 保存更新前的aplpha值,使用拷贝
alphaIold = alphas[i].copy(); alphaJold = alphas[j].copy()
# 步骤2:计算上下界L和H
if (labelMat[i] != labelMat[j]):
L = max(0, alphas[j] - alphas[i])
H = min(C, C + alphas[j] - alphas[i])
else:
L = max(0, alphas[j] + alphas[i] - C)
H = min(C, alphas[j] + alphas[i])
if L == H:
print("L==H")
continue
# 步骤3:计算eta
eta = 2.0 * dataMatrix[i, :] * dataMatrix[j, :].T - dataMatrix[i, :] * dataMatrix[i, :].T - dataMatrix[j,:] * dataMatrix[j, :].T
if eta >= 0:
print("eta>=0")
continue
# 步骤4:更新alpha_j
alphas[j] -= labelMat[j] * (Ei - Ej) / eta
# 步骤5:修剪alpha_j
alphas[j] = clipAlpha(alphas[j], H, L)
if (abs(alphas[j] - alphaJold) < 0.00001):
print("j not moving enough")
continue
# 步骤6:更新alpha_i
alphas[i] += labelMat[j] * labelMat[i] * (alphaJold - alphas[j]) # 按与alpha_j相同的方法更新alpha_i
# 步骤7:更新b_1和b_2,更新方向相反
b1 = b - Ei - labelMat[i] * (alphas[i] - alphaIold) * dataMatrix[i, :] * dataMatrix[i, :].T - labelMat[j] * (alphas[j] - alphaJold) * dataMatrix[i, :] * dataMatrix[j, :].T
b2 = b - Ej - labelMat[i] * (alphas[i] - alphaIold) * dataMatrix[i, :] * dataMatrix[j, :].T - labelMat[j] * (alphas[j] - alphaJold) * dataMatrix[j, :] * dataMatrix[j, :].T
# 步骤8:根据b_1和b_2更新b
if (0 < alphas[i]) and (C > alphas[i]):
b = b1
elif (0 < alphas[j]) and (C > alphas[j]):
b = b2
else:
b = (b1 + b2) / 2.0
# 统计优化次数
alphaPairsChanged += 1
print("第%d次迭代 样本:%d, alpha优化次数:%d" % (iter, i, alphaPairsChanged))
# 更新迭代次数
if (alphaPairsChanged == 0):
iter += 1
else:
iter = 0
print("迭代次数: %d" % iter)
return b, alphas
# 计算w值
def calcWs(alphas, dataArr, classLabels):
X = mat(dataArr);
labelMat = mat(classLabels).transpose()
m, n = shape(X)
w = zeros((n, 1))
for i in range(m):
w += multiply(alphas[i] * labelMat[i], X[i, :].T)
return w
# 绘制数据集以及划分直线
def showDataLine(w, b):
x, y = loadDataSet('testSet.txt')
xarr = array(x)
n = shape(x)[0]
x1 = []; y1 = []
x2 = []; y2 = []
for i in arange(n):
if int(y[i]) == 1:
x1.append(xarr[i, 0]);
y1.append(xarr[i, 1])
else:
x2.append(xarr[i, 0]);
y2.append(xarr[i, 1])
plt.scatter(x1, y1, s=30, c='r', marker='s')
plt.scatter(x2, y2, s=30, c='g')
# 画出 SVM 分类直线
xx = arange(0, 10, 0.1)
# 由分类直线 weights[0] * xx + weights[1] * yy1 + b = 0 易得下式
yy1 = (-w[0] * xx - b) / w[1]
# 由分类直线 weights[0] * xx + weights[1] * yy2 + b + 1 = 0 易得下式
yy2 = (-w[0] * xx - b - 1) / w[1]
# 由分类直线 weights[0] * xx + weights[1] * yy3 + b - 1 = 0 易得下式
yy3 = (-w[0] * xx - b + 1) / w[1]
plt.plot(xx, yy1.T)
plt.plot(xx, yy2.T)
plt.plot(xx, yy3.T)
# 画出支持向量点
for i in range(n):
if alphas[i] > 0.0:
plt.scatter(xarr[i, 0], xarr[i, 1], s=150, c='none', alpha=0.7, linewidth=1.5, edgecolor='red')
plt.xlim((-2, 12))
plt.ylim((-8, 6))
plt.show()
# 主函数
if __name__ == '__main__':
dataMat, labelMat = loadDataSet('testSet.txt')
b, alphas = smoSimple(dataMat, labelMat, 0.6, 0.001, 40)
w = calcWs(alphas, array(dataMat), labelMat)
showDataLine(w, b)运行结果


中间的蓝线为求出来的分类器,用红圈和橙圈圈出的点为支持向量点。?
运行结果看起来并不算很差,但这只是一个仅有100个点的小规模数据集。在更大的数据集上,收敛时间会变得更长。接下来,我们通过构建完整SMO算法来加快其运行速度。
5.4利用完整Platt SMO算法加速优化
# 读取数据
def loadDataSet(fileName):
dataMat = [] # 数据矩阵
labelMat = [] # 数据标签
fr = open(fileName) # 打开文件
for line in fr.readlines(): # 遍历,逐行读取
lineArr = line.strip().split() # 去除空格
dataMat.append([float(lineArr[0]), float(lineArr[1])]) # 数据矩阵中添加数据
labelMat.append(float(lineArr[2])) # 数据标签中添加标签
return dataMat, labelMat
# 随机选择alpha
def selectJrand(i, m):
j = i # 选择一个不等于i的j
while (j == i): # 只要函数值不等于输入值i,函数就会进行随机选择
j = int(random.uniform(0, m))
return j
# 修剪alpha
def clipAlpha(aj, H, L): # 用于调整大于H或小于L的alpha值
if aj > H:
aj = H
if L > aj:
aj = L
return aj
# 类
class optStruct:
def __init__(self, dataMatIn, classLabels, C, toler, kTup): # 使用参数初始化结构
self.X = dataMatIn # 数据矩阵
self.labelMat = classLabels # 数据标签
self.C = C # 松弛变量
self.tol = toler # 容错率
self.m = shape(dataMatIn)[0] # 数据矩阵行数m
self.alphas = mat(zeros((self.m, 1))) # 根据矩阵行数初始化alpha参数为0
self.b = 0 # 初始化b参数为0
self.eCache = mat(zeros((self.m, 2)))
# 计算误差
def calcEk(oS, k):
fXk = float(multiply(oS.alphas, oS.labelMat).T * (oS.X*oS.X[k,:].T)) + oS.b
Ek = fXk - float(oS.labelMat[k])
return Ek
# 内循环启发方式
def selectJ(i, oS, Ei):
maxK = -1; maxDeltaE = 0; Ej = 0 # 初始化
oS.eCache[i] = [1, Ei] # 选择给出最大增量E的alpha
validEcacheList = nonzero(oS.eCache[:, 0].A)[0]
if (len(validEcacheList)) > 1:
for k in validEcacheList: # 循环使用有效的Ecache值并找到使delta E最大化的值
if k == i: continue # 如果k对于i,不计算i
Ek = calcEk(oS, k) # 计算Ek的值
deltaE = abs(Ei - Ek) # 计算|Ei-Ek|
if (deltaE > maxDeltaE): # 找到maxDeltaE
maxK = k; maxDeltaE = deltaE; Ej = Ek
return maxK, Ej
else: # 在这种情况下(第一次),没有任何有效的eCache值
j = selectJrand(i, oS.m) # 随机选择alpha_j的索引值
Ej = calcEk(oS, j)
return j, Ej
# 计算Ek并更新误差缓存
def updateEk(oS, k): # 任何alpha更改后,更新缓存中的新值
Ek = calcEk(oS, k)
oS.eCache[k] = [1, Ek]
# 优化的SMO算法
def innerL(i, oS):
Ei = calcEk(oS, i) # 计算误差Ei
if ((oS.labelMat[i]*Ei < -oS.tol) and (oS.alphas[i] < oS.C)) or ((oS.labelMat[i]*Ei > oS.tol) and (oS.alphas[i] > 0)):
# 使用内循环启发方式选择alpha_j并计算Ej
j,Ej = selectJ(i, oS, Ei)
# 保存更新前的aplpha值,拷贝
alphaIold = oS.alphas[i].copy(); alphaJold = oS.alphas[j].copy()
# 步骤2:计算上下界L和H
if (oS.labelMat[i] != oS.labelMat[j]):
L = max(0, oS.alphas[j] - oS.alphas[i])
H = min(oS.C, oS.C + oS.alphas[j] - oS.alphas[i])
else:
L = max(0, oS.alphas[j] + oS.alphas[i] - oS.C)
H = min(oS.C, oS.alphas[j] + oS.alphas[i])
if L==H: print("L==H"); return 0
# 步骤3:计算eta
eta = 2.0 * oS.X[i,:]*oS.X[j,:].T - oS.X[i,:]*oS.X[i,:].T - oS.X[j,:]*oS.X[j,:].T
if eta >= 0: print("eta>=0"); return 0
# 步骤4:更新alpha_j
oS.alphas[j] -= oS.labelMat[j]*(Ei - Ej)/eta
# 步骤5:修剪alpha_j
oS.alphas[j] = clipAlpha(oS.alphas[j],H,L)
# 更新Ej至误差缓存
updateEk(oS, j)
if (abs(oS.alphas[j] - alphaJold) < 0.00001): print("j not moving enough"); return 0
# 步骤6:更新alpha_i
oS.alphas[i] += oS.labelMat[j]*oS.labelMat[i]*(alphaJold - oS.alphas[j])
# 更新Ei至误差缓存
updateEk(oS, i)
# 步骤7:更新b_1和b_2
b1 = oS.b - Ei - oS.labelMat[i]*(oS.alphas[i]-alphaIold)*oS.X[i,:]*oS.X[i,:].T - oS.labelMat[j]*(oS.alphas[j]-alphaJold)*oS.X[i,:]*oS.X[j,:].T
b2 = oS.b - Ej - oS.labelMat[i]*(oS.alphas[i]-alphaIold)*oS.X[i,:]*oS.X[j,:].T - oS.labelMat[j]*(oS.alphas[j]-alphaJold)*oS.X[j,:]*oS.X[j,:].T
# 步骤8:根据b_1和b_2更新b
if (0 < oS.alphas[i]) and (oS.C > oS.alphas[i]):
oS.b = b1
elif (0 < oS.alphas[j]) and (oS.C > oS.alphas[j]):
oS.b = b2
else:
oS.b = (b1 + b2)/2.0
return 1
else:
return 0
# 完整的线性SMO算法
def smoP(dataMatIn, classLabels, C, toler, maxIter,kTup=('lin', 0)):
oS = optStruct(mat(dataMatIn),mat(classLabels).transpose(), C, toler, kTup)# 初始化
iter = 0 # 初始化迭代次数为0
entireSet = True; alphaPairsChanged = 0
while (iter < maxIter) and ((alphaPairsChanged > 0) or (entireSet)): # 超过最大迭代次数或者遍历整个数据集都alpha也没有更新,则退出循环
alphaPairsChanged = 0
if entireSet:
for i in range(oS.m): # 遍历整个数据集
alphaPairsChanged += innerL(i, oS) # 使用优化的SMO算法
print("全样本遍历,第%d次迭代 样本:%d, alpha优化次数:%d" % (iter, i, alphaPairsChanged))
iter += 1
else: # 遍历非边界值
nonBoundIs = nonzero((oS.alphas.A > 0) * (oS.alphas.A < C))[0] # 遍历不在边界0和C的alpha
for i in nonBoundIs:
alphaPairsChanged += innerL(i, oS)
print("非边界遍历,第%d次迭代 样本:%d, alpha优化次数:%d" % (iter, i, alphaPairsChanged))
iter += 1
if entireSet:
entireSet = False # 切换整个集合循环
elif (alphaPairsChanged == 0):
entireSet = True
print("迭代次数: %d" % iter)
return oS.b, oS.alphas
# 计算w
def calcWs(alphas, dataArr, classLabels):
X = mat(dataArr);
labelMat = mat(classLabels).transpose()
m, n = shape(X)
w = zeros((n, 1))
for i in range(m):
w += multiply(alphas[i] * labelMat[i], X[i, :].T)
return w
# 绘制数据集以及划分直线
def showData(w, b):
x, y = loadDataSet('testSet.txt')
xarr = array(x)
n = shape(x)[0]
x1 = []; y1 = []
x2 = []; y2 = []
for i in arange(n):
if int(y[i]) == 1:
x1.append(xarr[i, 0]);
y1.append(xarr[i, 1])
else:
x2.append(xarr[i, 0]);
y2.append(xarr[i, 1])
plt.scatter(x1, y1, s=30, c='r', marker='s')
plt.scatter(x2, y2, s=30, c='g')
# 画出 SVM 分类直线
xx = arange(0, 10, 0.1)
# 由分类直线 weights[0] * xx + weights[1] * yy1 + b = 0 易得下式
yy1 = (-w[0] * xx - b) / w[1]
# 由分类直线 weights[0] * xx + weights[1] * yy2 + b + 1 = 0 易得下式
yy2 = (-w[0] * xx - b - 1) / w[1]
# 由分类直线 weights[0] * xx + weights[1] * yy3 + b - 1 = 0 易得下式
yy3 = (-w[0] * xx - b + 1) / w[1]
plt.plot(xx, yy1.T)
plt.plot(xx, yy2.T)
plt.plot(xx, yy3.T)
# 画出支持向量点
for i in range(n):
if alphas[i] > 0.0:
plt.scatter(xarr[i, 0], xarr[i, 1], s=150, c='none', alpha=0.7, linewidth=1.5, edgecolor='red')
plt.xlim((-2, 12))
plt.ylim((-8, 6))
plt.show()
if __name__ == '__main__':
dataMat, labelMat = loadDataSet('testSet.txt')
b, alphas = smoP(dataMat, labelMat, 0.6, 0.001, 40)
w = calcWs(alphas, array(dataMat), labelMat)
showData(w, b)运行结果


六、实例:用svm进行垃圾邮件分类
6.1 邮件预处理
首先导入库
import numpy as np
import scipy.io as sio
import matplotlib.pyplot as plt
from sklearn.svm import SVC # 导入sklearn.svm的库
导入训练集数据和测试集数据,打印表头
?# Training data
data1 = sio.loadmat('spamTrain.mat')
print('data1.keys():', data1.keys())
# Testing data
data2 = sio.loadmat('spamTest.mat')
print('data2.keys():', data2.keys())?
获取X,y,Xtest, ytest ;并打印X, y的shape以及X,y
X, y = data1['X'], data1['y']
Xtest, ytest = data2['Xtest'], data2['ytest']
print('X.shape, y.shape:', X.shape, y.shape)
print('X:', X)
print('y:', y)
 ?
?
X由1899种特征来表示,这些特征由0和1组成,0表示语义库不能找到该单词,1表示语义库可以找到该单词。y只有0和1两种形式,1表示当前邮件为垃圾邮件,0表示不是垃圾邮件?。
调用SVC进行邮件分类, 打印出最好的分数结果best_score与其对应的参数best_param
Cvalues = [3, 10, 30, 100, 0.01, 0.03, 0.1, 0.3, 1] # 设置9个误差惩罚系数的候选值C
best_score = 0 # 设置初始得分(即预测准确率)
best_param = 0 # 设置初始参数
for c in Cvalues: # 遍历Cvalues中的候选值
svc = SVC(C=c, kernel='linear') # 将候选值一个一个代入SVC中,kernel采用线性分类linear
svc.fit(X, y.flatten())
score = svc.score(Xtest, ytest.flatten()) # 将svc后的结果代入验证集中,对Xval,yval进行验证,显示预测准确率,
if score > best_score: # 如果当前的分数score大于之前的历史最好分数best_score
best_score = score # 就将当前的分数score赋值成历史最好分数best_score
best_param = c # 并且把当前的参数c和gamma赋值成历史最好参数best_params
print('best_score, best_param:', best_score, best_param)
 ?
?
6.2训练SVM进行垃圾邮件分类
将最优的参数best_param分别带入训练集和测试集,得到在各自数据下的最好分数(预测准确率)
svc = SVC(C= best_param, kernel='linear')
svc.fit(X, y.flatten())
score_train = svc.score(X, y.flatten())
score_test = svc.score(Xtest, ytest.flatten())
print('score_train, score_test:', best_score, best_param)
 ?
?
分别输出代入最优参数best_param=0.03时,在测试集和验证集上得到的最优的分数结果,
在训练集上的预测准确率为0.99,在验证集上的预测准确率也为0.99。?
七、问题及总结?
问题
运行时报错
ValueError:setting an array element with a sequence. The requested array has an?inhomogeneous shape after 1 dimensions. The detected shape was (2,) + inhomogeneous part.
解决方法:降低numpy版本后成功运行。
总结
在分类问题中,SVM是一种很优秀的机器学习算法。SVM可以有效的分离高维度的数据,更节省内存空间,因为只需要用向量来创建最佳超平面,是针对于可分离数据集的最佳方法。但是当数据量级较大的时候,分类效果不好,针对于不可分类的数据集,效果有些不太好。这次实验让我对支持向量机有了一定的了解和认识,能运用其解决实际问题,但还不能熟练使用,要继续加强对机器学习相关知识的学习。总的来说是一次收获满满的实验。
?
?
?
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!