K8S中的Pod到底是什么
01 概述
In earlier chapters we discussed how you might go about containerizing your application, but in real-world deployments of containerized applications you will often want to colocate multiple applications into a single atomic unit, scheduled onto a single machine.
在前面的章节中,我们讨论了如何对应用程序进行容器化,但在容器化应用程序的实际部署中,您通常希望将多个应用程序集中到一个原子单元中,并安排在一台机器上。
A canonical example of such a deployment is illustrated in Figure 5-1, which consists of a container serving web requests and a container synchronizing the filesystem with a remote Git repository.
图 5-1 是这种部署的典型示例,其中包括一个提供 Web 请求服务的容器和一个与远程 Git 仓库同步文件系统的容器。
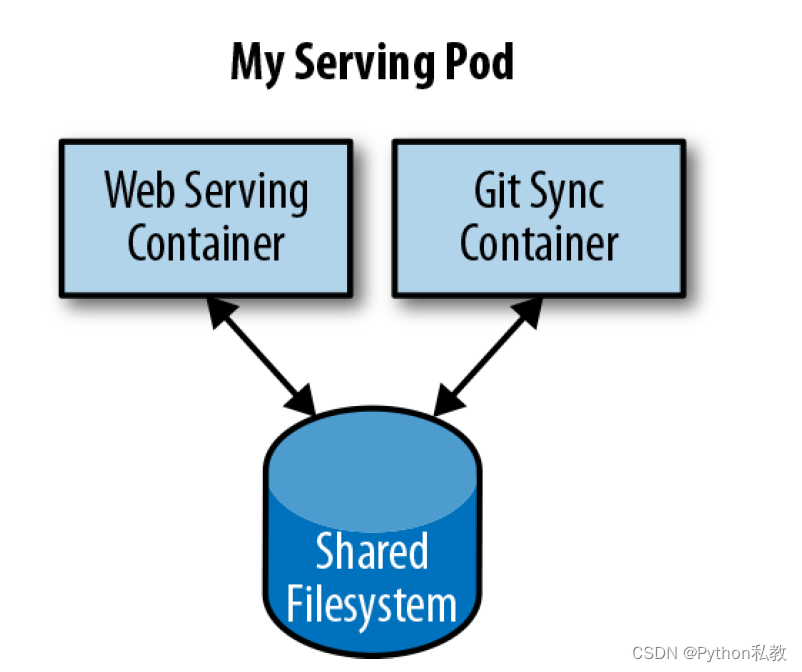
At first, it might seem tempting to wrap up both the web server and the Git synchronizer into a single container. After closer inspection, however, the reasons for the separation become clear. First, the two different containers have significantly different requirements in terms of resource usage. Take, for example, memory.
起初,将网络服务器和 Git 同步器打包到一个容器中似乎很诱人。但仔细观察后,分离的原因就一目了然了。首先,这两个不同的容器在资源使用方面有着明显不同的要求。以内存为例。
Because the web server is serving user requests, we want to ensure that it is always available and responsive. On the other hand, the Git synchronizer isn’t really user-facing and has a “best effort” quality of service.
由于网络服务器是为用户请求提供服务的,因此我们要确保它始终可用且响应迅速。另一方面,Git 同步器并不真正面向用户,它的服务质量是 “尽最大努力”。
Suppose that our Git synchronizer has a memory leak. We need to ensure that the Git synchronizer cannot use up memory that we want to use for our web server, since this can affect web server performance or even crash the server.
假设我们的 Git 同步器出现了内存泄漏。我们需要确保 Git 同步器不会占用我们希望用于网络服务器的内存,因为这会影响网络服务器的性能,甚至导致服务器崩溃。
This sort of resource isolation is exactly the sort of thing that containers are designed to accomplish. By separating the two applications into two separate containers, we can ensure reliable web server operation.
这种资源隔离正是容器的设计目标。通过将两个应用程序分离到两个独立的容器中,我们可以确保网络服务器的可靠运行。
Of course, the two containers are quite symbiotic; it makes no sense to schedule the web server on one machine and the Git synchronizer on another.
当然,这两个容器是共生的;在一台机器上调度网络服务器,而在另一台机器上调度 Git 同步器是毫无意义的。
Consequently, Kubernetes groups multiple containers into a single atomic unit called a Pod. (The name goes with the whale theme of Docker containers, since a Pod is also a group of whales.)
因此,Kubernetes 将多个容器组合成一个原子单元,称为 Pod。(这个名字与 Docker 容器的鲸鱼主题相吻合,因为 Pod 也是一组鲸鱼)。
Though the concept of such sidecars seemed controversial or confusing when it was first introduced in Kubernetes, it has subsequently been adopted by a variety of different applications to deploy their infrastructure. For example, several Service Mesh implementations use sidecars to inject network management into an application’s Pod.
尽管在 Kubernetes 中首次引入这种侧卡的概念时似乎存在争议或令人困惑,但后来它已被各种不同的应用所采用,用于部署它们的基础设施。例如,一些 Service Mesh 实现使用侧卡将网络管理注入到应用程序的 Pod 中。
Kubernetes 中的 Pod
A Pod represents a collection of application containers and volumes running in the same execution environment. Pods, not containers, are the smallest deployable artifact in a Kubernetes cluster. This means all of the containers in a Pod always land on the same machine.
Pod 代表在同一执行环境中运行的应用程序容器和卷的集合。Pod 是 Kubernetes 集群中最小的可部署工件,而不是容器。这意味着 Pod 中的所有容器始终位于同一台机器上。
Each container within a Pod runs in its own cgroup, but they share a number of Linux namespaces.
Pod 中的每个容器都在自己的 cgroup 中运行,但它们共享一些 Linux 命名空间。
Applications running in the same Pod share the same IP address and port space (network namespace), have the same hostname (UTS namespace), and can communicate using native interprocess communication channels over System V IPC or POSIX message queues (IPC namespace).
在同一 Pod 中运行的应用程序共享相同的 IP 地址和端口空间(网络命名空间),拥有相同的主机名(UTS 命名空间),并可通过 System V IPC 或 POSIX 消息队列(IPC 命名空间)使用本地进程间通信通道进行通信。
However, applications in different Pods are isolated from each other; they have different IP addresses, different hostnames, and more. Containers in different Pods running on the same node might as well be on different servers.
然而,不同 Pod 中的应用程序是相互隔离的;它们拥有不同的 IP 地址、不同的主机名等。在同一节点上运行的不同 Pod 中的容器,也可能在不同的服务器上运行。
关于Pods的思考
One of the most common questions that occurs in the adoption of Kubernetes is “What should I put in a Pod?”
在采用 Kubernetes 的过程中,最常见的问题之一是 "我应该在 Pod 中放置什么?
Sometimes people see Pods and think, “Aha! A WordPress container and a MySQL database container should be in the same Pod.”
有时,人们看到 Pod 会想:"啊哈!WordPress 容器和 MySQL 数据库容器应该放在同一个 Pod 中。
However, this kind of Pod is actually an example of an anti-pattern for Pod construction. There are two reasons for this. First, WordPress and its database are not truly symbiotic. If the WordPress container and the database container land on different machines, they still can work together quite effectively, since they communicate over a network connection. Secondly, you don’t necessarily want to scale WordPress and the database as a unit. WordPress itself is mostly stateless, and thus you may want to scale your WordPress frontends in response to frontend load by creating more WordPress Pods.
然而,这种 Pod 实际上是 Pod 结构的反模式范例。原因有二。首先,WordPress 及其数据库并非真正的共生关系。如果 WordPress 容器和数据库容器位于不同的机器上,它们仍然可以非常有效地协同工作,因为它们通过网络连接进行通信。其次,你并不一定要把WordPress和数据库作为一个单元来扩展。WordPress 本身大多是无状态的,因此您可能希望通过创建更多的 WordPress Pod 来扩展 WordPress 前端,以应对前端负载。
Scaling a MySQL database is much trickier, and you would be much more likely to increase the resources dedicated to a single MySQL Pod. If you group the WordPress and MySQL containers together in a single Pod, you are forced to use the same scaling strategy for both containers, which doesn’t fit well.
扩展 MySQL 数据库要棘手得多,你更有可能增加专用于单个 MySQL Pod 的资源。如果将 WordPress 和 MySQL 容器组合在一个 Pod 中,就不得不对两个容器使用相同的扩展策略,这并不合适。
In general, the right question to ask yourself when designing Pods is, “Will these containers work correctly if they land on different machines?” If the answer is “no,” a Pod is the correct grouping for the containers. If the answer is “yes,” multiple Pods is probably the correct solution. In the example at the beginning of this chapter, the two containers interact via a local filesystem. It would be impossible for them to operate correctly if the containers were scheduled on different machines.
一般来说,设计 Pod 时要问自己的正确问题是:"如果这些容器放在不同的机器上,它们能正常工作吗?如果答案是 “否”,那么 Pod 就是容器的正确分组。如果答案是 “是”,那么多个 Pod 可能是正确的解决方案。在本章开头的示例中,两个容器通过本地文件系统进行交互。如果容器被安排在不同的机器上,它们就不可能正常运行。
In the remaining sections of this chapter, we will describe how to create, introspect, manage, and delete Pods in Kubernetes.
在本章的其余章节中,我们将介绍如何在 Kubernetes 中创建、反省、管理和删除 Pod。
Pod的资源清单
概述
Pods are described in a Pod manifest. The Pod manifest is just a textfile representation of the Kubernetes API object. Kubernetes strongly believes in declarative configuration. Declarative configuration means that you write down the desired state of the world in a configuration and then submit that configuration to a service that takes actions to ensure the desired state becomes the actual state.
Pod 清单中描述了 Pod。Pod 清单只是 Kubernetes API 对象的文本文件表示。Kubernetes 坚信声明式配置。声明式配置是指在配置中写下世界的理想状态,然后将配置提交给服务,服务会采取行动确保理想状态成为实际状态。
Declarative configuration is different from imperative configuration, where you simply take a series of actions (e.g., apt-get install foo) to modify the world. Years of production experience have taught us that maintaining a written record of the system’s desired state leads to a more manageable, reliable system.
声明式配置不同于命令式配置,在命令式配置中,你只需执行一系列操作(例如,apt-get install foo)即可修改世界。多年的生产经验告诉我们,对系统所需的状态进行书面记录,能让系统更易于管理、更可靠。
Declarative configuration enables numerous advantages, including code review for configurations as well as documenting the current state of the world for distributed teams. Additionally, it is the basis for all of the self-healing behaviors in Kubernetes that keep applications running without user action.
声明式配置具有众多优势,包括对配置进行代码审查,以及为分布式团队记录当前状态。此外,它还是 Kubernetes 中所有自愈行为的基础,无需用户操作即可保持应用运行。
The Kubernetes API server accepts and processes Pod manifests before storing them in persistent storage (etcd). The scheduler also uses the Kubernetes API to find Pods that haven’t been scheduled to a node. The scheduler then places the Pods onto nodes depending on the resources and other constraints expressed in the Pod manifests.
Kubernetes API 服务器接受并处理 Pod 清单,然后将其存储到持久存储(etcd)中。调度器还使用 Kubernetes API 查找尚未调度到节点的 Pod。然后,调度程序会根据 Pod 清单中表达的资源和其他限制,将 Pod 放置到节点上。
Multiple Pods can be placed on the same machine as long as there are sufficient resources. However, scheduling multiple replicas of the same application onto the same machine is worse for reliability, since the machine is a single failure domain. Consequently, the Kubernetes scheduler tries to ensure that Pods from the same application are distributed onto different machines for reliability in the presence of such failures. Once scheduled to a node, Pods don’t move and must be explicitly destroyed and rescheduled.
只要有足够的资源,就可以在同一台机器上部署多个 Pod。但是,将同一应用程序的多个副本调度到同一台机器上会降低可靠性,因为机器是单一故障域。因此,Kubernetes 调度器试图确保同一应用程序的 Pod 被分配到不同的机器上,以确保在出现此类故障时的可靠性。一旦调度到某个节点,Pod 就不会移动,必须明确销毁并重新调度。
Multiple instances of a Pod can be deployed by repeating the workflow described here. However, ReplicaSets (Chapter 9) are better suited for running multiple instances of a Pod. (It turns out they’re also better at running a single Pod, but we’ll get into that later.)
通过重复此处描述的工作流程,可以部署 Pod 的多个实例。不过,ReplicaSets(第 9 章)更适合运行 Pod 的多个实例。(事实证明,它们也更适合运行单个 Pod,但我们稍后会讨论这个问题)。
创建Pod
The simplest way to create a Pod is via the imperative kubectl run command.
创建 Pod 的最简单方法是使用命令式 kubectl run 命令。
For example, to run our same kuard server, use:
例如,要运行同一个 kuard 服务器,请使用:
kubectl run kuard --generator=run-pod/v1 --image=gcr.io/kuar-demo/kuard-amd64:blue
You can see the status of this Pod by running:
您可以通过运行:
kubectl get pods
You may initially see the container as Pending, but eventually you will see it transition to Running, which means that the Pod and its containers have been successfully created.
容器最初可能显示为 “待定”,但最终会显示为 “运行”,这意味着 Pod 及其容器已成功创建。
For now, you can delete this Pod by running:
现在,您可以通过运行:
kubectl delete pods/kuard
We will now move on to writing a complete Pod manifest by hand.
现在,我们将开始手工编写完整的 Pod 清单。
创建Pod资源清单
Pod manifests can be written using YAML or JSON, but YAML is generally preferred because it is slightly more human-editable and has the ability to add comments. Pod manifests (and other Kubernetes API objects) should really be treated in the same way as source code, and things like comments help explain the Pod to new team members who are looking at them for the first time.
Pod 清单可以使用 YAML 或 JSON 编写,但一般更倾向于使用 YAML,因为它更便于人工编辑,而且可以添加注释。Pod 清单(以及其他 Kubernetes API 对象)应与源代码同等对待,注释之类的东西有助于向第一次查看 Pod 清单的新团队成员解释 Pod。
Pod manifests include a couple of key fields and attributes: namely a metadata section for describing the Pod and its labels, a spec section for describing volumes, and a list of containers that will run in the Pod.
Pod 清单包括几个关键字段和属性:即用于描述 Pod 及其标签的元数据部分、用于描述卷的规格部分,以及将在 Pod 中运行的容器列表。
In Chapter 2 we deployed kuard using the following Docker command:
在第 2 章中,我们使用以下 Docker 命令部署了 kuard:
docker run -d --name kuard --publish 8080:8080 gcr.io/kuar-demo/kuard-amd64:blue
A similar result can be achieved by instead writing Example 5-1 to a file named kuard-pod.yaml and then using kubectl commands to load that manifest to Kubernetes.
将例 5-1 写入名为 kuard-pod.yaml 的文件,然后使用 kubectl 命令将该清单加载到 Kubernetes,也能达到类似的效果。
kuard-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: kuard
spec:
containers:
- image: gcr.io/kuar-demo/kuard-amd64:1
name: kuard
ports:
- containerPort: 8080
name: http
protocol: TCP
运行Pod
概述
In the previous section we created a Pod manifest that can be used to start a Pod running kuard. Use the kubectl apply command to launch a single instance of kuard:
kubectl apply -f kuard-pod.yaml
The Pod manifest will be submitted to the Kubernetes API server. The Kubernetes system will then schedule that Pod to run on a healthy node in the cluster, where it will be monitored by the kubelet daemon process. Don’t worry if you don’t understand all the moving parts of Kubernetes right now; we’ll get into more details throughout the book.
Pod 清单将提交给 Kubernetes API 服务器。然后,Kubernetes 系统会安排 Pod 在集群中一个健康的节点上运行,并由 kubelet 守护进程进行监控。如果你现在还不了解 Kubernetes 的所有活动部分,也不用担心;我们将在本书中详细介绍。
获取Pod列表
Now that we have a Pod running, let’s go find out some more about it. Using the kubectl command-line tool, we can list all Pods running in the cluster. For now, this should only be the single Pod that we created in the previous step:
现在我们有了一个正在运行的 Pod,让我们进一步了解一下它。使用 kubectl 命令行工具,我们可以列出集群中运行的所有 Pod。目前,这应该只是我们在上一步中创建的单个 Pod:
kubectl get pods
You can see the name of the Pod (kuard) that we gave it in the previous YAML file. In addition to the number of ready containers (1/1), the output also shows the status, the number of times the Pod was restarted, as well as the age of the Pod.
你可以看到我们在之前的 YAML 文件中给 Pod 起的名字(kuard)。除了已就绪容器的数量(1/1),输出结果还显示了 Pod 的状态、重启次数以及 Pod 的年龄。
If you ran this command immediately after the Pod was created, you might see:
如果在 Pod 创建后立即运行此命令,您可能会看到:
NAME READY STATUS RESTARTS AGE
kuard 0/1 Pending 0 1s
The Pending state indicates that the Pod has been submitted but hasn’t been scheduled yet.
待定状态表示 Pod 已提交,但尚未排定。
If a more significant error occurs (e.g., an attempt to create a Pod with a container image that doesn’t exist), it will also be listed in the status field.
如果出现更严重的错误(例如,尝试使用不存在的容器映像创建 Pod),也会在状态字段中列出。
By default, the kubectl command-line tool tries to be concise in the information it reports, but you can get more information via command-line flags. Adding -o wide to any kubectl command will print out slightly more information (while still trying to keep the information to a single line).
默认情况下,kubectl 命令行工具会尽量简洁地报告信息,但你可以通过命令行标志获得更多信息。在任何 kubectl 命令中添加 -o wide,就能打印出更多信息(同时仍尽量将信息控制在一行内)。
Adding -o json or -o yaml will print out the complete objects in JSON or YAML, respectively.
添加 -o json 或 -o yaml 后,将分别以 JSON 或 YAML 格式打印出完整的对象。
获取Pod详情
Sometimes, the single-line view is insufficient because it is too terse.
有时,单行视图因过于简洁而不够充分。
Additionally, Kubernetes maintains numerous events about Pods that are present in the event stream, not attached to the Pod object.
此外,Kubernetes 还会维护大量有关 Pod 的事件,这些事件存在于事件流中,而不是附加到 Pod 对象上。
To find out more information about a Pod (or any Kubernetes object) you can use the kubectl describe command. For example, to describe the Pod we previously created, you can run:
要了解 Pod(或任何 Kubernetes 对象)的更多信息,可以使用 kubectl describe 命令。例如,要描述我们之前创建的 Pod,可以运行:
kubectl describe pods kuard
This outputs a bunch of information about the Pod in different sections. At the top is basic information about the Pod:
这将在不同部分输出有关 Pod 的大量信息。顶部是 Pod 的基本信息:
Name: kuard
Namespace: default
Node: node1/10.0.15.185
Start Time: Sun, 02 Jul 2017 15:00:38 -0700
Labels: <none>
Annotations: <none>
Status: Running
IP: 192.168.199.238
Controllers: <none>
Then there is information about the containers running in the Pod:
然后是有关 Pod 中运行的容器的信息:
Containers:
kuard:
Container ID: docker://055095…
Image: gcr.io/kuar-demo/kuard-amd64:blue
Image ID: docker-pullable://gcr.io/kuardemo/kuard-amd64@sha256:a580…
Port: 8080/TCP
State: Running
Started: Sun, 02 Jul 2017 15:00:41 -0700
Ready: True
Restart Count: 0
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount
Finally, there are events related to the Pod, such as when it was scheduled, when its image was pulled, and if/when it had to be restarted because of failing health checks:
最后,还有与 Pod 相关的事件,如何时计划、何时提取映像,以及是否/何时因健康检查失败而必须重启 Pod:
Events:
Seen From SubObjectPath Type
Reason Message
---- ---- ------------- ------
-- ------ -------
50s default-scheduler Normal
Scheduled Success…
49s kubelet, node1 spec.containers{kuard} Normal
Pulling pulling…
47s kubelet, node1 spec.containers{kuard} Normal
Pulled Success…
47s kubelet, node1 spec.containers{kuard} Normal
Created Created…
47s kubelet, node1 spec.containers{kuard} Normal
Started Started…
删除一个Pod
When it is time to delete a Pod, you can delete it either by name:
要删除 Pod 时,您可以按名称删除:
kubectl delete pods/kuard
or using the same file that you used to create it:
或使用与创建时相同的文件:
kubectl delete -f kuard-pod.yaml
When a Pod is deleted, it is not immediately killed. Instead, if you run kubectl get pods you will see that the Pod is in the Terminating state. All Pods have a termination grace period. By default, this is 30 seconds. When a Pod is transitioned to Terminating it no longer receives new requests. In a serving scenario, the grace period is important for reliability because it allows the Pod to finish any active requests that it may be in the middle of processing before it is terminated.
删除 Pod 时,它不会立即被杀死。相反,如果运行 kubectl get pods,你会看到 Pod 处于终止状态。所有 Pod 都有一个终止宽限期。默认情况下,宽限期为 30 秒。当 Pod 过渡到终止状态时,它将不再接收新请求。在服务场景中,宽限期对可靠性非常重要,因为它允许 Pod 在终止前完成正在处理的任何活动请求。
It’s important to note that when you delete a Pod, any data stored in the containers associated with that Pod will be deleted as well. If you want to persist data across multiple instances of a Pod, you need to use PersistentVolumes, described at the end of this chapter.
值得注意的是,删除 Pod 时,存储在与 Pod 相关联的容器中的任何数据也将被删除。如果想在 Pod 的多个实例中持久保存数据,则需要使用 PersistentVolumes(本章末尾将介绍)。
访问您的 Pod
概述
Now that your Pod is running, you’re going to want to access it for a variety of reasons. You may want to load the web service that is running in the Pod. You may want to view its logs to debug a problem that you are seeing, or even execute other commands in the context of the Pod to help debug. The following sections detail various ways that you can interact with the code and data running inside your Pod.
现在,您的 Pod 已经运行,出于各种原因,您可能想要访问它。您可能想加载正在 Pod 中运行的网络服务。您可能想查看日志来调试您看到的问题,甚至在 Pod 的上下文中执行其他命令来帮助调试。以下章节详细介绍了与 Pod 内运行的代码和数据交互的各种方式。
使用端口转发
Later in the book, we’ll show how to expose a service to the world or other containers using load balancers?—but oftentimes you simply want to access a specific Pod, even if it’s not serving traffic on the internet.
在本书的后面部分,我们将介绍如何使用负载平衡器向全世界或其他容器公开服务,但很多时候,你只是想访问一个特定的 Pod,即使它没有在互联网上提供流量。
To achieve this, you can use the port-forwarding support built into the Kubernetes API and command-line tools.
为此,您可以使用 Kubernetes API 和命令行工具内置的端口转发支持。
When you run:
当你运行:
kubectl port-forward kuard 8080:8080
a secure tunnel is created from your local machine, through the Kubernetes master, to the instance of the Pod running on one of the worker nodes.
从您的本地机器通过 Kubernetes 主站,到运行在其中一个工作节点上的 Pod 实例,会创建一个安全隧道。
As long as the port-forward command is still running, you can access the Pod (in this case the kuard web interface) at http://localhost:8080.
只要端口转发命令仍在运行,您就可以通过 http://localhost:8080 访问 Pod(此处为 kuard 网络界面)。
通过日志获取更多信息
When your application needs debugging, it’s helpful to be able to dig deeper than describe to understand what the application is doing. Kubernetes provides two commands for debugging running containers. The kubectl logs command downloads the current logs from the running instance:
当你的应用程序需要调试时,能比描述更深入地了解应用程序正在做什么会很有帮助。Kubernetes 提供了两种调试正在运行的容器的命令。kubectl logs 命令会从正在运行的实例中下载当前日志:
kubectl logs kuard
Adding the -f flag will cause you to continuously stream logs.
添加 -f 标志将使日志流持续不断。
The kubectl logs command always tries to get logs from the currently running container. Adding the --previous flag will get logs from a previous instance of the container. This is useful, for example, if your containers are continuously restarting due to a problem at container startup.
kubectl logs 命令总是尝试从当前运行的容器中获取日志。添加 --previous 标志将从容器的前一个实例中获取日志。例如,如果由于容器启动时出现问题而导致容器不断重启,这将非常有用。
While using kubectl logs is useful for one-off debugging of containers in production environments, it’s generally useful to use a log aggregation service. There are several open source log aggregation tools, like fluentd and elasticsearch, as well as numerous cloud logging providers. Log aggregation services provide greater capacity for storing a longer duration of logs, as well as rich log searching and filtering capabilities. Finally, they often provide the ability to aggregate logs from multiple Pods into a single view.
虽然使用 kubectl 日志对生产环境中容器的一次性调试很有用,但使用日志聚合服务通常也很有用。有几种开源日志聚合工具,如 fluentd 和 elasticsearch,以及许多云日志提供商。日志聚合服务的容量更大,可存储更长时间的日志,并具有丰富的日志搜索和过滤功能。最后,它们通常还能将多个 Pod 的日志聚合到一个视图中。
使用 exec 在容器中运行命令
Sometimes logs are insufficient, and to truly determine what’s going on you need to execute commands in the context of the container itself. To do this you can use:
有时日志并不足够,要真正确定发生了什么,需要在容器本身的上下文中执行命令。为此,您可以使用:
kubectl exec kuard date
You can also get an interactive session by adding the -it flags:
您还可以通过添加 -it 标记来获得交互式会话:
kubectl exec -it kuard ash
将文件复制到容器或从容器中复制文件
At times you may need to copy files from a remote container to a local machine for more in-depth exploration. For example, you can use a tool like Wireshark to visualize tcpdump packet captures. Suppose you had a file called /captures/capture3.txt inside a container in your Pod. You could securely copy that file to your local machine by running:
有时,您可能需要将文件从远程容器复制到本地计算机,以便进行更深入的探索。例如,你可以使用 Wireshark 等工具来可视化 tcpdump 数据包捕获。假设在 Pod 的容器中有一个名为 /captures/capture3.txt 的文件。您可以通过运行以下命令将该文件安全地复制到本地计算机上:
kubectl cp <pod-name>:/captures/capture3.txt ./capture3.txt
Other times you may need to copy files from your local machine into a container. Let’s say you want to copy $HOME/config.txt to a remote container. In this case, you can run:
其他时候,你可能需要将文件从本地机器复制到容器中。比方说,你想把 $HOME/config.txt 复制到远程容器中。在这种情况下,你可以运行:
kubectl cp $HOME/config.txt <pod-name>:/config.txt
Generally speaking, copying files into a container is an anti-pattern.
一般来说,将文件复制到容器中是一种反模式。
You really should treat the contents of a container as immutable. But occasionally it’s the most immediate way to stop the bleeding and restore your service to health, since it is quicker than building, pushing, and rolling out a new image. Once the bleeding is stopped, however, it is critically important that you immediately go and do the image build and rollout, or you are guaranteed to forget the local change that you made to your container and overwrite it in the subsequent regularly scheduled rollout.
你确实应该将容器中的内容视为不可变的。但偶尔这也是止血和恢复服务的最直接方法,因为它比构建、推送和推出新映像更快。不过,一旦止血成功,最重要的是立即进行镜像构建和推出,否则你肯定会忘记对容器所做的本地更改,并在随后的定期推出中覆盖它。
健康检查
概述
When you run your application as a container in Kubernetes, it is automatically kept alive for you using a process health check. This health check simply ensures that the main process of your application is always running. If it isn’t, Kubernetes restarts it.
当您在 Kubernetes 中以容器形式运行应用程序时,它会通过进程健康检查自动为您保持活力。这种健康检查只需确保应用程序的主进程始终在运行。如果没有,Kubernetes 会重新启动它。
However, in most cases, a simple process check is insufficient. For example, if your process has deadlocked and is unable to serve requests, a process health check will still believe that your application is healthy since its process is still running.
不过,在大多数情况下,简单的进程检查是不够的。例如,如果您的进程出现死锁,无法为请求提供服务,进程健康检查仍会认为您的应用程序是健康的,因为其进程仍在运行。
To address this, Kubernetes introduced health checks for application liveness. Liveness health checks run application-specific logic (e.g., loading a web page) to verify that the application is not just still running, but is functioning properly. Since these liveness health checks are application-specific, you have to define them in your Pod manifest.
为了解决这个问题,Kubernetes 引入了应用程序有效性健康检查。有效性健康检查运行特定于应用程序的逻辑(如加载网页),以验证应用程序不仅仍在运行,而且运行正常。由于这些有效性健康检查是针对特定应用的,因此必须在 Pod 清单中加以定义。
有效性探测器
Once the kuard process is up and running, we need a way to confirm that it is actually healthy and shouldn’t be restarted. Liveness probes are defined per container, which means each container inside a Pod is health-checked separately. In Example 5-2, we add a liveness probe to our kuard container, which runs an HTTP request against the /healthy path on our container.
一旦 kuard 进程启动并运行,我们需要一种方法来确认它是否真的健康,并且不应该重新启动。生命探测是按容器定义的,这意味着 Pod 中的每个容器都要分别进行健康检查。在例 5-2 中,我们为 kuard 容器添加了一个有效性探针,它针对容器上的 /healthy 路径运行 HTTP 请求。
kuard-pod-health.yaml
apiVersion: v1
kind: Pod
metadata:
name: kuard
spec:
containers:
- image: gcr.io/kuar-demo/kuard-amd64:blue
name: kuard
livenessProbe:
httpGet:
path: /healthy
port: 8080
initialDelaySeconds: 5
timeoutSeconds: 1
periodSeconds: 10
failureThreshold: 3
ports:
- containerPort: 8080
name: http
protocol: TCP
The preceding Pod manifest uses an httpGet probe to perform an HTTP GET request against the /healthy endpoint on port 8080 of the kuard container.
前面的 Pod 清单使用 httpGet 探测器对 kuard 容器 8080 端口上的 /healthy 端点执行 HTTP GET 请求。
The probe sets an initialDelaySeconds of 5, and thus will not be called until 5 seconds after all the containers in the Pod are created. The probe must respond within the 1-second timeout, and the HTTP status code must be equal to or greater than 200 and less than 400 to be considered successful.
探针设置的 initialDelaySeconds(初始延迟秒数)为 5,因此在 Pod 中的所有容器创建完成 5 秒后才会被调用。探针必须在 1 秒超时时间内做出响应,HTTP 状态代码必须等于或大于 200 且小于 400 才算成功。
Kubernetes will call the probe every 10 seconds. If more than three consecutive probes fail, the container will fail and restart.
Kubernetes 将每隔 10 秒调用一次探测器。如果连续三次以上探测失败,容器就会失败并重新启动。
You can see this in action by looking at the kuard status page.
您可以查看 kuard 状态页面,了解其运行情况。
Create a Pod using this manifest and then port-forward to that Pod:
使用此清单创建 Pod,然后将端口转发到该 Pod:
kubectl apply -f kuard-pod-health.yaml
kubectl port-forward kuard 8080:8080
Point your browser to http://localhost:8080.
将浏览器指向 http://localhost:8080。
Click the “Liveness Probe” tab. You should see a table that lists all of the probes that this instance of kuard has received. If you click the “Fail” link on that page, kuard will start to fail health checks.
单击 "Liveness Probe(有效性探针)"选项卡。您会看到一个表格,其中列出了此 kuard 实例收到的所有探针。如果单击该页面上的 "Fail(失败)"链接,kuard 将开始无法进行健康检查。
Wait long enough and Kubernetes will restart the container. At that point the display will reset and start over again. Details of the restart can be found with kubectl describe pods kuard. The “Events” section will have text similar to the following:
等待足够长的时间,Kubernetes 就会重新启动容器。此时,显示将重置并重新开始。重启的详情可通过 kubectl describe pods kuard 找到。事件 "部分将显示类似下面的文本:
Killing container with id docker://2ac946...:pod "kuard_default(9ee84...)"
container "kuard" is unhealthy, it will be killed and re-created.
While the default response to a failed liveness check is to restart the Pod, the actual behavior is governed by the Pod’s restartPolicy.
虽然对有效性检查失败的默认响应是重启 Pod,但实际行为受 Pod 的重启策略(restartPolicy)控制。
There are three options for the restart policy: Always (the default), OnFailure (restart only on liveness failure or nonzero process exit code), or Never.
重启策略有三个选项: 始终(默认)、OnFailure(仅在运行失败或非零进程退出代码时重启)或 Never(永不)。
准备状态探测器
Of course, liveness isn’t the only kind of health check we want to perform.
当然,有效性并不是我们要进行的唯一一种健康检查。
Kubernetes makes a distinction between liveness and readiness. Liveness determines if an application is running properly.
Kubernetes 区分了有效性和就绪性。有效性决定了应用程序是否正常运行。
Containers that fail liveness checks are restarted. Readiness describes when a container is ready to serve user requests. Containers that fail readiness checks are removed from service load balancers.
未通过有效性检查的容器会被重新启动。就绪状态描述了容器何时可以为用户请求提供服务。未通过就绪检查的容器会从服务负载平衡器中移除。
Readiness probes are configured similarly to liveness probes. We explore Kubernetes services in detail in Chapter 7.
准备状态探针的配置与有效性探针类似。我们将在第 7 章详细探讨 Kubernetes 服务。
Combining the readiness and liveness probes helps ensure only healthy containers are running within the cluster.
将就绪性探针和有效性探针结合起来,有助于确保只有健康的容器在集群中运行。
健康检查的类型
In addition to HTTP checks, Kubernetes also supports tcpSocket health checks that open a TCP socket; if the connection is successful, the probe succeeds.
除了 HTTP 检查,Kubernetes 还支持打开 TCP 套接字的 tcpSocket 健康检查;如果连接成功,则探测成功。
This style of probe is useful for non-HTTP applications; for example, databases or other non–HTTP-based APIs.
这种探针适用于非 HTP 应用程序,例如数据库或其他非基于 HTP 的应用程序接口。
Finally, Kubernetes allows exec probes. These execute a script or program in the context of the container. Following typical convention, if this script returns a zero exit code, the probe succeeds; otherwise, it fails. exec scripts are often useful for custom application validation logic that doesn’t fit neatly into an HTTP call.
最后,Kubernetes 允许执行探针。它们在容器上下文中执行脚本或程序。按照通常的惯例,如果该脚本返回的退出代码为零,则探测成功;否则,探测失败。执行脚本通常适用于无法整齐纳入 HTTP 调用的自定义应用验证逻辑。
资源管理
概述
Most people move into containers and orchestrators like Kubernetes because of the radical improvements in image packaging and reliable deployment they provide.
大多数人开始使用 Kubernetes 等容器和编排器,是因为它们在镜像打包和可靠部署方面有了重大改进。
In addition to application-oriented primitives that simplify distributed system development, equally important is the ability to increase the overall utilization of the compute nodes that make up the cluster.
除了简化分布式系统开发的面向应用的基本原理外,同样重要的是能够提高组成集群的计算节点的整体利用率。
The basic cost of operating a machine, either virtual or physical, is basically constant regardless of whether it is idle or fully loaded. Consequently, ensuring that these machines are maximally active increases the efficiency of every dollar spent on infrastructure.
无论是虚拟机还是物理机,无论其处于闲置还是满载状态,其基本运行成本基本不变。因此,确保这些机器最大限度地处于活跃状态,就能提高基础设施每一分钱的使用效率。
Generally speaking, we measure this efficiency with the utilization metric.
一般来说,我们用利用率指标来衡量这种效率。
Utilization is defined as the amount of a resource actively being used divided by the amount of a resource that has been purchased. For example, if you purchase a one-core machine, and your application uses one-tenth of a core, then your utilization is 10%.
利用率的定义是正在使用的资源量除以已购买的资源量。例如,如果您购买了一台单核机器,而您的应用程序使用了十分之一的核心,那么您的利用率就是 10%。
With scheduling systems like Kubernetes managing resource packing, you can drive your utilization to greater than 50%.
利用 Kubernetes 等调度系统管理资源打包,可以将利用率提高到 50% 以上。
To achieve this, you have to tell Kubernetes about the resources your application requires, so that Kubernetes can find the optimal packing of containers onto purchased machines.
要做到这一点,你必须告诉 Kubernetes 你的应用程序所需的资源,这样 Kubernetes 就能在购买的机器上找到最佳的容器包装。
Kubernetes allows users to specify two different resource metrics.
Kubernetes 允许用户指定两种不同的资源指标。
Resource requests specify the minimum amount of a resource required to run the application. Resource limits specify the maximum amount of a resource that an application can consume.
资源请求指定运行应用程序所需的最少资源量。资源限制规定了应用程序可消耗的最大资源量。
Both of these resource definitions are described in greater detail in the following sections.
这两种资源定义将在以下章节中详细介绍。
资源申请: 最低所需资源
With Kubernetes, a Pod requests the resources required to run its containers. Kubernetes guarantees that these resources are available to the Pod. The most commonly requested resources are CPU and memory, but Kubernetes has support for other resource types as well, such as GPUs and more.
在 Kubernetes 中,Pod 请求运行其容器所需的资源。Kubernetes 保证 Pod 可以使用这些资源。最常请求的资源是 CPU 和内存,但 Kubernetes 也支持其他资源类型,如 GPU 等。
For example, to request that the kuard container lands on a machine with half a CPU free and gets 128 MB of memory allocated to it, we define the Pod as shown in Example 5-3.
例如,要请求将 kuard 容器安装在有一半空闲 CPU 的机器上,并为其分配 128 MB 内存,我们可以按例 5-3 所示定义 Pod。
kuard-pod-resreq.yaml
apiVersion: v1
kind: Pod
metadata:
name: kuard
spec:
containers:
- image: gcr.io/kuar-demo/kuard-amd64:1
name: kuard
resources:
requests:
cpu: "500m"
memory: "128Mi"
ports:
- containerPort: 8080
name: http
protocol: TCP
Resources are requested per container, not per Pod. The total resources requested by the Pod is the sum of all resources requested by all containers in the Pod.
资源是按容器申请的,而不是按 Pod 申请的。Pod 申请的总资源是 Pod 中所有容器申请的所有资源的总和。
The reason for this is that in many cases the different containers have very different CPU requirements. For example, in the web server and data synchronizer Pod, the web server is user-facing and likely needs a great deal of CPU, while the data synchronizer can make do with very little.
原因是在许多情况下,不同的容器对 CPU 的要求大不相同。例如,在网络服务器和数据同步器 Pod 中,网络服务器面向用户,可能需要大量 CPU,而数据同步器只需要很少的 CPU。
申请限额详情
Requests are used when scheduling Pods to nodes.
请求用于将 Pod 调度到节点。
The Kubernetes scheduler will ensure that the sum of all requests of all Pods on a node does not exceed the capacity of the node.
Kubernetes 调度器将确保一个节点上所有 Pod 的所有请求总和不超过该节点的容量。
Therefore, a Pod is guaranteed to have at least the requested resources when running on the node. Importantly, “request” specifies a minimum.
因此,当 Pod 在节点上运行时,保证至少拥有所请求的资源。重要的是,"请求 "指定了最低限度。
It does not specify a maximum cap on the resources a Pod may use.
它没有规定 Pod 可使用资源的最大上限。
To explore what this means, let’s look at an example.
为了探究这意味着什么,让我们来看一个例子。
Imagine that we have container whose code attempts to use all available CPU cores.
想象一下,我们有一个容器,其代码试图使用所有可用的 CPU 内核。
Suppose that we create a Pod with this container that requests 0.5 CPU. Kubernetes schedules this Pod onto a machine with a total of 2 CPU cores.
假设我们用这个容器创建了一个 Pod,要求使用 0.5 个 CPU。Kubernetes 将这个 Pod 调度到一台总共有 2 个 CPU 内核的机器上。
As long as it is the only Pod on the machine, it will consume all 2.0 of the available cores, despite only requesting 0.5 CPU.
只要它是机器上唯一的 Pod,就会占用全部 2.0 个可用内核,尽管只需要 0.5 个 CPU。
If a second Pod with the same container and the same request of 0.5 CPU lands on the machine, then each Pod will receive 1.0 cores.
如果第二个装有相同容器的 Pod 出现在机器上,并要求使用 0.5 个 CPU,那么每个 Pod 将获得 1.0 个内核。
If a third identical Pod is scheduled, each Pod will receive 0.66 cores. Finally, if a fourth identical Pod is scheduled, each Pod will receive the 0.5 core it requested, and the node will be at capacity.
如果第三个相同的 Pod 被调度,每个 Pod 将获得 0.66 个内核。最后,如果第四个相同的 Pod 被调度,每个 Pod 将获得它所请求的 0.5 个内核,节点将达到容量。
CPU requests are implemented using the cpu-shares functionality in the Linux kernel.
CPU 请求使用 Linux 内核中的 cpu-shares 功能实现。
Memory requests are handled similarly to CPU, but there is an important difference. If a container is over its memory request, the OS can’t just remove memory from the process, because it’s been allocated. Consequently, when the system runs out of memory, the kubelet terminates containers whose memory usage is greater than their requested memory. These containers are automatically restarted, but with less available memory on the machine for the container to consume.
内存请求的处理方式与 CPU 类似,但有一个重要区别。如果容器超出了内存请求,操作系统就无法从进程中移除内存,因为内存已经分配完毕。因此,当系统内存耗尽时,kubelet 会终止内存使用量大于其内存请求的容器。这些容器会自动重新启动,但容器消耗的可用内存会减少。
Since resource requests guarantee resource availability to a Pod, they are critical to ensuring that containers have sufficient resources in high-load situations.
由于资源请求能保证 Pod 的资源可用性,因此对于确保容器在高负载情况下有足够的资源至关重要。
限制资源使用量
In addition to setting the resources required by a Pod, which establishes the minimum resources available to the Pod, you can also set a maximum on a Pod’s resource usage via resource limits.
除了设置 Pod 所需的资源(即 Pod 可用的最小资源)外,您还可以通过资源限制设置 Pod 资源使用的最大值。
In our previous example we created a kuard Pod that requested a minimum of 0.5 of a core and 128 MB of memory. In the Pod manifest in Example 5-4, we extend this configuration to add a limit of 1.0 CPU and 256 MB of memory.
在上一个例子中,我们创建了一个 kuard Pod,要求至少有 0.5 个内核和 128 MB 内存。在例 5-4 中的 Pod 清单中,我们扩展了这一配置,增加了 1.0 CPU 和 256 MB 内存的限制。
kuard-pod-reslim.yaml
apiVersion: v1
kind: Pod
metadata:
name: kuard
spec:
containers:
- image: gcr.io/kuar-demo/kuard-amd64:1
name: kuard
resources:
requests:
cpu: "500m"
memory: "128Mi"
limits:
cpu: "1000m"
memory: "256Mi"
ports:
- containerPort: 8080
name: http
protocol: TCP
When you establish limits on a container, the kernel is configured to ensure that consumption cannot exceed these limits. A container with a CPU limit of 0.5 cores will only ever get 0.5 cores, even if the CPU is otherwise idle. A container with a memory limit of 256 MB will not be allowed additional memory (e.g., malloc ill fail) if its memory usage exceeds 256 MB.
为容器设置限制时,内核的配置会确保消耗量不会超过这些限制。一个 CPU 限制为 0.5 个内核的容器,即使 CPU 闲置,也只能获得 0.5 个内核。内存限制为 256 MB 的容器,如果内存使用量超过 256 MB,将不允许增加内存(例如,malloc ill 失败)。
使用卷持久化数据
概述
When a Pod is deleted or a container restarts, any and all data in the container’s filesystem is also deleted. This is often a good thing, since you don’t want to leave around cruft that happened to be written by your stateless web application. In other cases, having access to persistent disk storage is an important part of a healthy application.
删除 Pod 或重启容器时,容器文件系统中的所有数据也会被删除。这通常是件好事,因为你不想留下无状态网络应用程序写入的残渣。在其他情况下,访问持久磁盘存储是健康应用的重要组成部分。
Kubernetes models such persistent storage.
Kubernetes 就是这种持久存储的典范。
将卷与 Pod 一起使用
To add a volume to a Pod manifest, there are two new stanzas to add to our configuration. The first is a new spec.volumes section.
要在 Pod 清单中添加卷,有两个新的章节需要添加到我们的配置中。第一个是新的 spec.volumes 部分。
This array defines all of the volumes that may be accessed by containers in the Pod manifest. It’s important to note that not all containers are required to mount all volumes defined in the Pod.
该数组定义了 Pod 清单中容器可以访问的所有卷。值得注意的是,并非所有容器都需要挂载 Pod 中定义的所有卷。
The second addition is the volumeMounts array in the container definition. This array defines the volumes that are mounted into a particular container, and the path where each volume should be mounted. Note that two different containers in a Pod can mount the same volume at different mount paths.
第二个新增内容是容器定义中的 volumeMounts 数组。该数组定义了挂载到特定容器中的卷,以及每个卷的挂载路径。请注意,一个 Pod 中的两个不同容器可以在不同的挂载路径上挂载同一个卷。
The manifest in Example 5-5 defines a single new volume named kuard-data, which the kuard container mounts to the /data path.
例 5-5 中的清单定义了一个名为 kuard-data 的新卷,kuard 容器会将其挂载到 /data 路径。
kuard-pod-vol.yaml
apiVersion: v1
kind: Pod
metadata:
name: kuard
spec:
volumes:
- name: "kuard-data"
hostPath:
path: "/var/lib/kuard"
containers:
- image: gcr.io/kuar-demo/kuard-amd64:1
name: kuard
volumeMounts:
- mountPath: "/data"
name: "kuard-data"
ports:
- containerPort: 8080
name: http
protocol: TCP
利用 Pod 使用卷的不同方法
There are a variety of ways you can use data in your application. The following are a few, and the recommended patterns for Kubernetes.
在应用程序中使用数据有多种方式。以下是几种以及 Kubernetes 推荐的模式。
通信/同步
In the first example of a Pod, we saw how two containers used a shared volume to serve a site while keeping it synchronized to a remote Git location. To achieve this, the Pod uses an emptyDir volume.
在 Pod 的第一个示例中,我们看到两个容器如何使用共享卷为一个站点提供服务,同时保持与远程 Git 位置同步。为此,Pod 使用了 emptyDir 卷。
Such a volume is scoped to the Pod’s lifespan, but it can be shared between two containers, forming the basis for communication between our Git sync and web serving containers.
这种卷在 Pod 的生命周期内有效,但可以在两个容器之间共享,为 Git 同步和网络服务容器之间的通信奠定基础。
缓存
An application may use a volume that is valuable for performance, but not required for correct operation of the application.
应用程序可能会使用对性能有价值的卷,但应用程序的正确运行并不需要该卷。
For example, perhaps the application keeps prerendered thumbnails of larger images.
例如,应用程序可能会保留较大图像的预渲染缩略图。
Of course, they can be reconstructed from the original images, but that makes serving the thumbnails more expensive.
当然,也可以根据原始图像重建缩略图,但这样做会增加提供缩略图的成本。
You want such a cache to survive a container restart due to a health-check failure, and thus emptyDir works well for the cache use case as well.
您希望这样的缓存在容器因健康检查失败而重启后仍能存活,因此 emptyDir 也能很好地用于缓存用例。
持久数据
Sometimes you will use a volume for truly persistent data—data that is independent of the lifespan of a particular Pod, and should move between nodes in the cluster if a node fails or a Pod moves to a different machine for some reason.
有时,您会使用卷来存储真正的持久性数据–与特定 Pod 的生命周期无关的数据,如果某个节点发生故障或某个 Pod 因某种原因移动到不同的机器上,这些数据应在群集的不同节点之间移动。
To achieve this, Kubernetes supports a wide variety of remote network storage volumes, including widely supported protocols like NFS and iSCSI as well as cloud provider network storage like Amazon’s Elastic Block Store, Azure’s Files and Disk Storage, as well as Google’s Persistent Disk.
为此,Kubernetes 支持各种远程网络存储卷,包括广泛支持的协议(如 NFS 和 iSCSI)以及云提供商的网络存储,如亚马逊的弹性块存储、Azure 的文件和磁盘存储以及谷歌的持久磁盘。
挂载主机文件系统
Other applications don’t actually need a persistent volume, but they do need some access to the underlying host filesystem.
其他应用程序实际上并不需要持久卷,但它们确实需要访问底层主机文件系统。
For example, they may need access to the /dev filesystem in order to perform raw block-level access to a device on the system. For these cases, Kubernetes supports the hostPath volume, which can mount arbitrary locations on the worker node into the container.
例如,它们可能需要访问 /dev 文件系统,以便对系统上的设备执行原始块级访问。对于这些情况,Kubernetes 支持 hostPath 卷,它可以将工作节点上的任意位置挂载到容器中。
The previous example uses the hostPath volume type. The volume created is /var/lib/kuard on the host.
上例使用了 hostPath 卷类型。创建的卷是主机上的 /var/lib/kuard。
使用远程磁盘持久化数据
Oftentimes, you want the data a Pod is using to stay with the Pod, even if it is restarted on a different host machine.
通常,您希望 Pod 使用的数据与 Pod 保持一致,即使在不同的主机上重新启动也是如此。
To achieve this, you can mount a remote network storage volume into your Pod. When using network-based storage, Kubernetes automatically mounts and unmounts the appropriate storage whenever a Pod using that volume is scheduled onto a particular machine.
为此,您可以将远程网络存储卷挂载到 Pod 中。使用基于网络的存储时,每当使用该卷的 Pod 被调度到特定机器上时,Kubernetes 就会自动挂载和卸载相应的存储。
There are numerous methods for mounting volumes over the network.
通过网络挂载卷的方法有很多。
Kubernetes includes support for standard protocols such as NFS and iSCSI as well as cloud provider–based storage APIs for the major cloud providers (both public and private). In many cases, the cloud providers will also create the disk for you if it doesn’t already exist.
Kubernetes 支持 NFS 和 iSCSI 等标准协议,以及主要云提供商(包括公共云和私有云)基于云提供商的存储 API。在很多情况下,如果磁盘还不存在,云提供商也会为您创建磁盘。
Here is an example of using an NFS server:
下面是一个使用 NFS 服务器的示例:
...
# Rest of pod definition above here
volumes:
- name: "kuard-data"
nfs:
server: my.nfs.server.local
path: "/exports"
Persistent volumes are a deep topic that has many different details: in particular, the manner in which persistent volumes, persistent volume claims, and dynamic volume provisioning work together.
持久卷是一个深奥的话题,有许多不同的细节:特别是持久卷、持久卷索赔和动态卷供应的协同工作方式。
There is a more in-depth examination of the subject in Chapter 15.
第 15 章对这一主题进行了更深入的探讨。
将所有内容整合在一起
Many applications are stateful, and as such we must preserve any data and ensure access to the underlying storage volume regardless of what machine the application runs on.
许多应用程序都是有状态的,因此无论应用程序在哪台机器上运行,我们都必须保留任何数据并确保对底层存储卷的访问。
As we saw earlier, this can be achieved using a persistent volume backed by network-attached storage.
如前所述,这可以通过网络附加存储支持的持久卷来实现。
We also want to ensure that a healthy instance of the application is running at all times, which means we want to make sure the container running kuard is ready before we expose it to clients.
我们还希望确保应用程序的健康实例始终处于运行状态,这意味着我们要确保运行 kuard 的容器已准备就绪,然后再将其暴露给客户。
Through a combination of persistent volumes, readiness and liveness probes, and resource restrictions, Kubernetes provides everything needed to run stateful applications reliably. Example 5-6 pulls this all together into one manifest.
通过持久卷、就绪性和有效性探针以及资源限制的组合,Kubernetes 提供了可靠运行有状态应用程序所需的一切。示例 5-6 将这一切整合到一个清单中。
kuard-pod-full.yaml
apiVersion: v1
kind: Pod
metadata:
name: kuard
spec:
volumes:
- name: "kuard-data"
nfs:
server: my.nfs.server.local
path: "/exports"
containers:
- image: gcr.io/kuar-demo/kuard-amd64:1
name: kuard
ports:
- containerPort: 8080
name: http
protocol: TCP
resources:
requests:
cpu: "500m"
memory: "128Mi"
limits:
cpu: "1000m"
memory: "256Mi"
volumeMounts:
- mountPath: "/data"
name: "kuard-data"
livenessProbe:
httpGet:
path: /healthy
port: 8080
initialDelaySeconds: 5
timeoutSeconds: 1
periodSeconds: 10
failureThreshold: 3
readinessProbe:
httpGet:
path: /ready
port: 8080
initialDelaySeconds: 30
timeoutSeconds: 1
periodSeconds: 10
failureThreshold: 3
总结
Pods represent the atomic unit of work in a Kubernetes cluster.
Pod 代表 Kubernetes 集群中的原子工作单元。
Pods are comprised of one or more containers working together symbiotically. To create a Pod, you write a Pod manifest and submit it to the Kubernetes API server by using the command-line tool or (less frequently) by making HTTP and JSON calls to the server directly.
Pod 由一个或多个容器组成,它们共生工作。要创建 Pod,你需要编写一份 Pod 清单,并通过使用命令行工具或(较少使用)直接向服务器进行 HTTP 和 JSON 调用,将其提交给 Kubernetes API 服务器。
Once you’ve submitted the manifest to the API server, the Kubernetes scheduler finds a machine where the Pod can fit and schedules the Pod to that machine.
向 API 服务器提交清单后,Kubernetes 调度器就会找到适合 Pod 的机器,并将 Pod 调度到该机器上。
Once scheduled, the kubelet daemon on that machine is responsible for creating the containers that correspond to the Pod, as well as performing any health checks defined in the Pod manifest.
一旦计划好,该机器上的 kubelet 守护进程就会负责创建与 Pod 相对应的容器,并执行 Pod 清单中定义的任何健康检查。
Once a Pod is scheduled to a node, no rescheduling occurs if that node fails.
一旦 Pod 被调度到某个节点,即使该节点发生故障,也不会重新调度。
Additionally, to create multiple replicas of the same Pod you have to create and name them manually.
此外,要创建同一 Pod 的多个副本,必须手动创建和命名它们。
In a later chapter we introduce the ReplicaSet object and show how you can automate the creation of multiple identical Pods and ensure that they are recreated in the event of a node machine failure.
在后面的章节中,我们将介绍 ReplicaSet 对象,并展示如何自动创建多个相同的 Pod,并确保在节点机发生故障时重新创建它们。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!