LLaVA-v1.5-7B:实现先进多模态学习的开源AI
引言
LLaVA-v1.5-7B是一个开源大型多模态模型(LMM),它通过结合视觉指令调整(Visual Instruction Tuning)技术,展示了在多模态理解和生成任务上的卓越性能。该模型特别注重简洁性和数据效率,利用CLIP-ViT-L-336px与多层感知器(MLP)投影以及包含学术任务导向的视觉问答(VQA)数据,来建立更强的基准。
-
Huggingface模型下载:https://huggingface.co/llava-hf/llava-1.5-7b-hf
-
AI快站模型免费加速下载:https://aifasthub.com/models/llava-hf
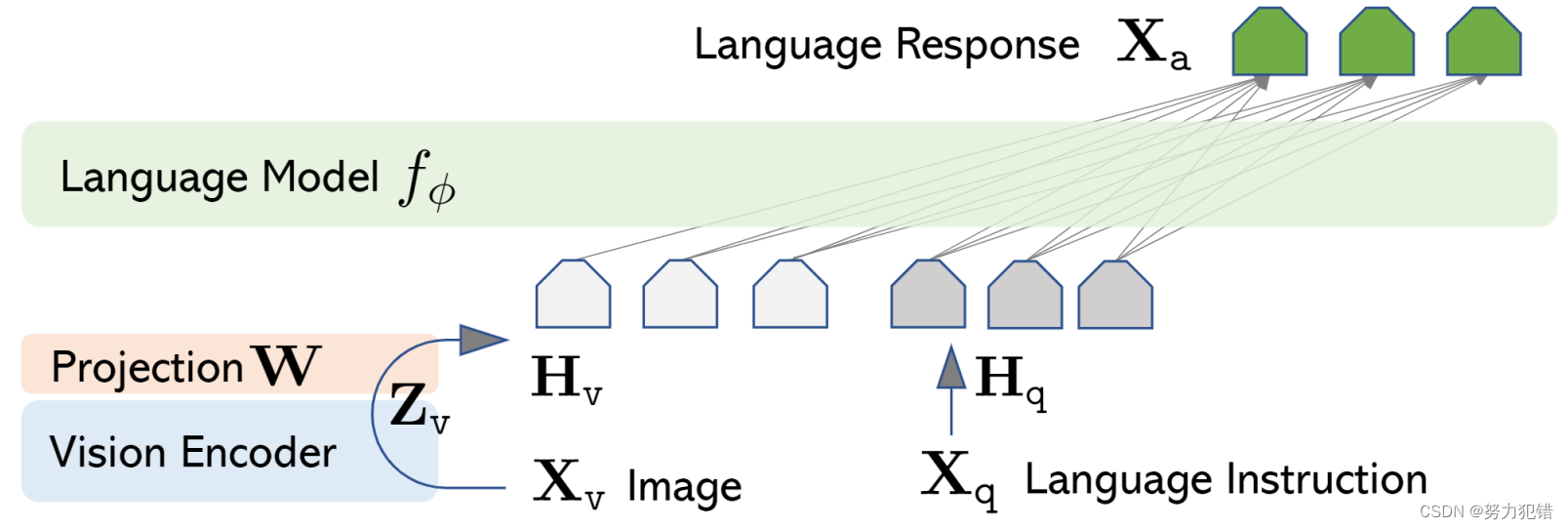
技术特点
LLaVA-v1.5-7B的最终13B检查点仅使用了1.2M公开可用的数据,并在单个8-A100节点上仅用约1天完成全部训练,这彰显了其出色的训练效率和轻量级架构。模型通过对CLIP-ViT-L-336px和MLP投影层的简单修改,以及对特定学术任务导向的VQA数据的添加,取得了11个基准测试中的最佳性能。
多模态学习能力
LLaVA-v1.5-7B在多模态学习领域展示了强大的能力。它能够处理包括对话风格的问答、详细描述和复杂推理在内的多种类型的视觉指令。此外,该模型利用多种不同来源的数据,包括lmsys-chat-1M、ShareGPT和Antropic/hh-rlhf等,通过综合这些数据,模型能够理解和生成针对广泛话题的响应。
训练方法
LLaVA-v1.5-7B的训练涉及到从监督微调(SFT)到强化学习的结合。模型首先在视觉语言对齐预训练阶段,利用图像-文本对来对齐视觉特征和语言模型的词嵌入空间。其次,在视觉指令调整阶段,模型通过对视觉指令的微调,使其能够更好地理解用户的多样化请求。
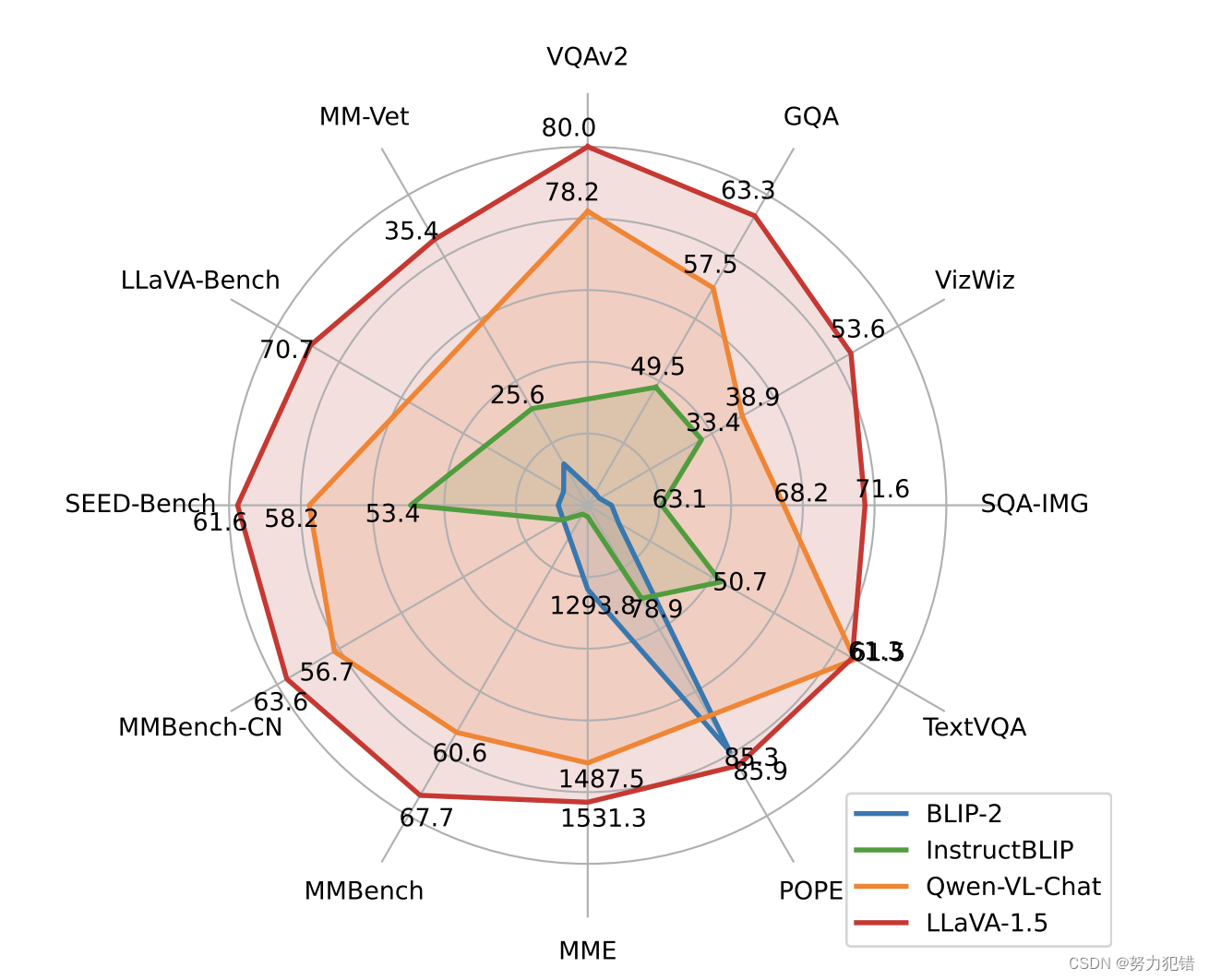
性能基准
LLaVA-v1.5-7B在多个学术视觉问答基准测试中取得了最优性能,包括在11个共12个基准测试中排名第一。此外,模型在多模态指令遵循能力方面也表现出色,即使没有特别针对多语言多模态指令遵循进行微调,也能够理解多种语言的指令。

局限性
尽管LLaVA-v1.5-7B在多个领域显示出强大的性能,但它在处理涉及推理或数学的任务时仍有局限。此外,该模型也容易受到提示注入的影响,尤其是在未经显式针对这些场景训练的情况下。
结论
LLaVA-v1.5-7B不仅作为一个技术上的选择,更代表了开源、透明和伦理的人工智能开发的愿景。随着数据的多样性、训练方法的精细化以及更广泛的社区参与,我们期待LLaVA-v1.5-7B在未来的AI世界中扮演更加重要的角色。
模型下载
Huggingface模型下载
https://huggingface.co/llava-hf/llava-1.5-7b-hf
AI快站模型免费加速下载
https://aifasthub.com/models/llava-hf
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!