LLM的评价指标
目录
LLM 大语言模型的评价指标
1. 性能和准确性
大型语言模型通常通过多项基准测试(benchmarks)来评价其性能和准确性。这些基准测试可能包括各种自然语言处理任务,如文本分类、情感分析、问答系统、摘要生成、机器翻译等。模型的准确性是通过比较模型的预测结果和实际结果来衡量的,通常使用精确度(precision)、召回率(recall)、F1分数等指标。
2. 泛化能力
泛化能力是衡量模型在未见数据上表现的能力。一个好的语言模型应该能够处理不同领域、不同风格的语言,而不仅仅是在训练数据上表现良好。这通常需要通过跨领域的测试集来评估。
3. 可解释性和透明度
随着模型变得越来越大,其决策过程的可解释性也变得越来越重要。评价一个模型的可解释性涉及到理解模型的决策是如何做出的,以及模型的预测是否为人类所能理解和接受。
4. 偏见和公平性
评价大型语言模型还需要考虑模型是否存在偏见,以及其表现是否公平。这包括检查模型是否在性别、种族、年龄等方面有不公正的倾向,并采取措施来减少这些偏见。
5. 资源效率
大型模型通常需要大量的计算资源来训练和运行。资源效率涵盖了模型的能耗、训练和推理时间、以及模型大小等方面。在实际应用中,资源效率是一个重要的考虑因素。
6. 安全性和隐私
评价大型语言模型时还需考虑其安全性,包括模型是否容易受到对抗性攻击,以及是否能够保护用户数据的隐私。
7. 持续学习能力
评价模型的另一个维度是其持续学习的能力,即模型是否能够在不断接触新数据时保持或提高其性能,而不会忘记先前学到的知识。
8. 用户体验
对于商业应用来说,大型语言模型的用户体验也是一个重要的评价指标。这包括用户界面的友好程度、响应速度、以及用户满意度。
9. 遵守法律法规
大型语言模型必须遵守相关的法律法规,如数据保护法规、版权法等,这也是评价模型的一个重要方面。
10. 伦理和社会影响
最后,大型语言模型的评价还应包括其伦理和社会影响,如模型的使用是否可能造成社会分裂、增加误导信息的传播等。
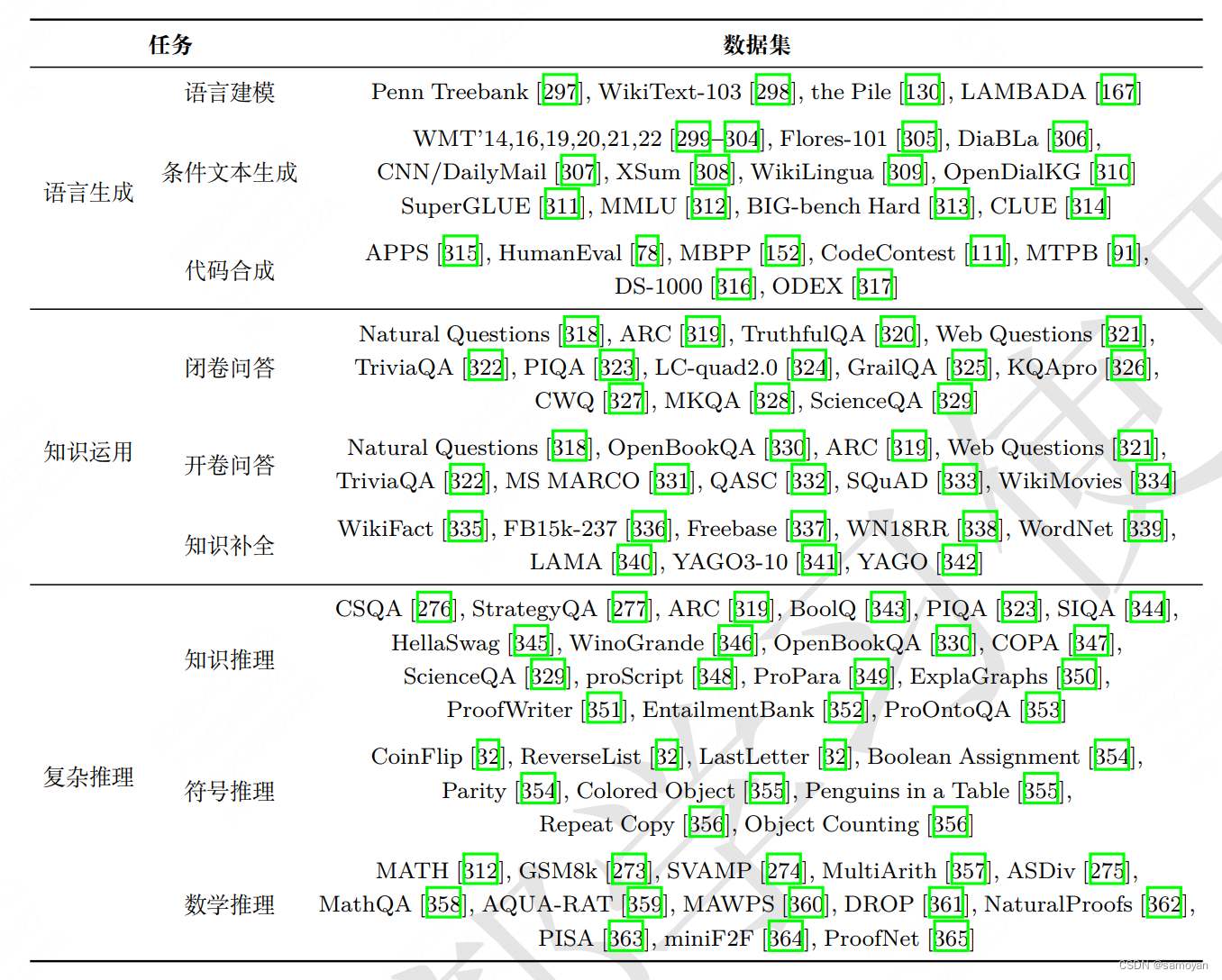
LLM(大型语言模型)评价的常用测试集
1. GLUE Benchmark
GLUE(General Language Understanding Evaluation)是一个用于评估和比较自然语言理解系统的工具集,它包括一系列不同的任务,如文本蕴含、情感分析、句子相似性等。GLUE旨在测试模型在理解英语文本方面的能力。
2. SuperGLUE Benchmark
SuperGLUE是继GLUE之后的一个更为复杂和挑战性的基准测试,它引入了更难的任务和更复杂的数据集,用以推动语言理解模型的发展。SuperGLUE包括问答、因果推理和多项选择等任务。
3. SQuAD
SQuAD(Stanford Question Answering Dataset)是一个阅读理解数据集,包含一系列的问题和基于Wikipedia文章的答案。模型的任务是阅读段落并回答关于段落内容的问题。
4. LAMBADA
LAMBADA评估模型在给定文本上下文的情况下预测句子最后一个单词的能力。它特别设计来测试模型在长距离依赖方面的表现。
5. Winograd Schema Challenge
Winograd Schema Challenge是一个旨在测试常识推理和语言理解能力的挑战。它包含一系列的句子,其中包含歧义,模型必须使用常识来解决这些歧义。
6. CoQA
CoQA(Conversational Question Answering Challenge)是一个对话式问题回答数据集,它要求模型能够理解一系列连贯的问题和答案。
7. Common Sense Reasoning Benchmarks
包括COPA(Choice of Plausible Alternatives)和SWAG(Situations With Adversarial Generations)等测试集,旨在评估模型在常识推理方面的能力。
8. MultiNLI
MultiNLI(Multi-Genre Natural Language Inference)是一个自然语言推理数据集,包含多种文本风格和话题,用于评估模型在不同类型文本上的推理能力。
9. The Pile
The Pile是一个大型的文本数据集,用于训练和评估语言模型,它包含各种来源的文本,如书籍、网站和科学论文。
10. Hugging Face's Datasets
Hugging Face提供了一个广泛的数据集库,覆盖多种语言、任务和域,这些数据集可以用于评估语言模型在多样化任务上的性能。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!