机器学习与深度学习——使用paddle实现随机梯度下降算法SGD对波士顿房价数据进行线性回归和预测
机器学习与深度学习——使用paddle实现随机梯度下降算法SGD对波士顿房价数据进行线性回归和预测
随机梯度下降(SGD)也称为增量梯度下降,是一种迭代方法,用于优化可微分目标函数。该方法通过在小批量数据上计算损失函数的梯度而迭代地更新权重与偏置项。SGD在高度非凸的损失表面上远远超越了朴素梯度下降法,这种简单的爬山法技术已经主导了现代的非凸优化。
一、任务
使用Paddle实现随机梯度下降(SGD)算法对波士顿房价数据进行线性回归的训练,给出每次迭代的权重、损失和梯度,并进行房价预测值与真实房价值对比。
二、流程
1、导入必要的库和模块:PaddlePaddle深度学习框架、numpy、os等常用的包和库。
2、读取数据并进行预处理。将数据进行归一化处理,将训练集和测试集划分为7:3的比例。
3、定义线性回归模型。自定义类 Regressor 继承自 paddle.nn.Layer ,初始化函数中定义了一个全连接层。该全连接层的输入维度为13,输出维度为1。
4、构建模型并训练。调用 Regressor() 函数生成模型,使用随机梯度下降法进行训练。。
5、模型预测。运用之前训练好的模型进行前向计算得到预测结果。
6、反归一化处理。进行反归一化处理,得到原始的房价估计值。
输出结果。将得到的预测结果和真实标签值进行比较,并输出预测房价的结果和真实房价结果。
三、完整代码
使用Paddle实现随机梯度下降(SGD)算法对波士顿房价数据进行线性回归的训练,给出每次迭代的权重、损失和梯度,并进行房价预测值与真实房价值对比。
#导入必要的包和库
import paddle
from paddle.nn import Linear
import paddle.nn.functional as F
import numpy as np
import os
import random
def load_data():
# 从文件导入数据
datafile = './work/housing.data'
data = np.fromfile(datafile, sep=' ', dtype=np.float32)
# 每条数据包括14项,其中前面13项是影响因素,第14项是相应的房屋价格中位数
feature_names = ['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', \
'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV']
feature_num = len(feature_names)
# 将原始数据进行Reshape,变成[N, 14]这样的形状
data = data.reshape([data.shape[0] // feature_num, feature_num])
# 这里使用70%的数据做训练,30%的数据做测试
ratio = 0.7
offset = int(data.shape[0] * ratio)
training_data = data[:offset]
# 计算train数据集的最大值,最小值,平均值
maximums, minimums, avgs = training_data.max(axis=0), training_data.min(axis=0), \
training_data.sum(axis=0) / training_data.shape[0]
# 记录数据的归一化参数,在预测时对数据做归一化
global max_values
global min_values
global avg_values
max_values = maximums
min_values = minimums
avg_values = avgs
# 对数据进行归一化处理
for i in range(feature_num):
data[:, i] = (data[:, i] - avgs[i]) / (maximums[i] - minimums[i])
# 训练集和测试集的划分比例
training_data = data[:offset]
test_data = data[offset:]
return training_data, test_data
# 验证数据集读取程序的正确性
training_data, test_data = load_data()
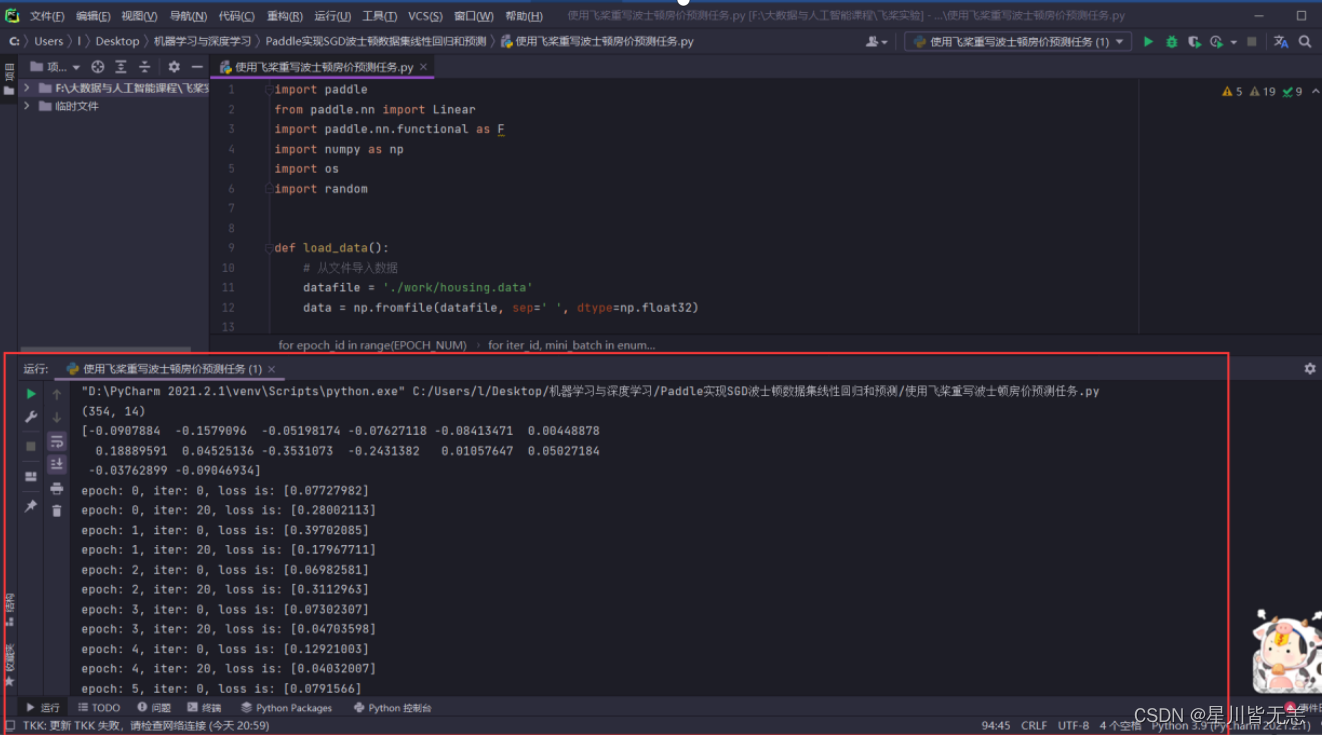
print(training_data.shape)
print(training_data[1,:])
class Regressor(paddle.nn.Layer):
# self代表类的实例自身
def __init__(self):
# 初始化父类中的一些参数
super(Regressor, self).__init__()
# 定义一层全连接层,输入维度是13,输出维度是1
self.fc = Linear(in_features=13, out_features=1)
# 网络的前向计算
def forward(self, inputs):
x = self.fc(inputs)
return x
# 声明定义好的线性回归模型
model = Regressor()
# 开启模型训练模式
model.train()
# 加载数据
training_data, test_data = load_data()
# 定义优化算法,使用随机梯度下降SGD
# 学习率设置为0.01
opt = paddle.optimizer.SGD(learning_rate=0.01, parameters=model.parameters())
EPOCH_NUM = 10 # 设置外层循环次数
BATCH_SIZE = 10 # 设置batch大小
# 定义外层循环
for epoch_id in range(EPOCH_NUM):
# 在每轮迭代开始之前,将训练数据的顺序随机的打乱
np.random.shuffle(training_data)
# 将训练数据进行拆分,每个batch包含10条数据
mini_batches = [training_data[k:k + BATCH_SIZE] for k in range(0, len(training_data), BATCH_SIZE)]
# 定义内层循环
for iter_id, mini_batch in enumerate(mini_batches):
x = np.array(mini_batch[:, :-1]) # 获得当前批次训练数据
y = np.array(mini_batch[:, -1:]) # 获得当前批次训练标签(真实房价)
# 将numpy数据转为飞桨动态图tensor的格式
house_features = paddle.to_tensor(x)
prices = paddle.to_tensor(y)
# 前向计算
predicts = model(house_features)
# 计算损失
loss = F.square_error_cost(predicts, label=prices)
avg_loss = paddle.mean(loss)
if iter_id % 20 == 0:
print("epoch: {}, iter: {}, loss is: {}".format(epoch_id, iter_id, avg_loss.numpy()))
# 反向传播,计算每层参数的梯度值
avg_loss.backward()
# 更新参数,根据设置好的学习率迭代一步
opt.step()
# 清空梯度变量,以备下一轮计算
opt.clear_grad()
# 保存模型参数,文件名为LR_model.pdparams
paddle.save(model.state_dict(), 'LR_model.pdparams')
print("模型保存成功,模型参数保存在LR_model.pdparams中")
def load_one_example():
# 从上边已加载的测试集中,随机选择一条作为测试数据
idx = np.random.randint(0, test_data.shape[0])
idx = -10
one_data, label = test_data[idx, :-1], test_data[idx, -1]
# 修改该条数据shape为[1,13]
one_data = one_data.reshape([1, -1])
return one_data, label
# 参数为保存模型参数的文件地址
model_dict = paddle.load('LR_model.pdparams')
model.load_dict(model_dict)
model.eval()
# 参数为数据集的文件地址
one_data, label = load_one_example()
# 将数据转为动态图的variable格式
one_data = paddle.to_tensor(one_data)
predict = model(one_data)
# 对结果做反归一化处理
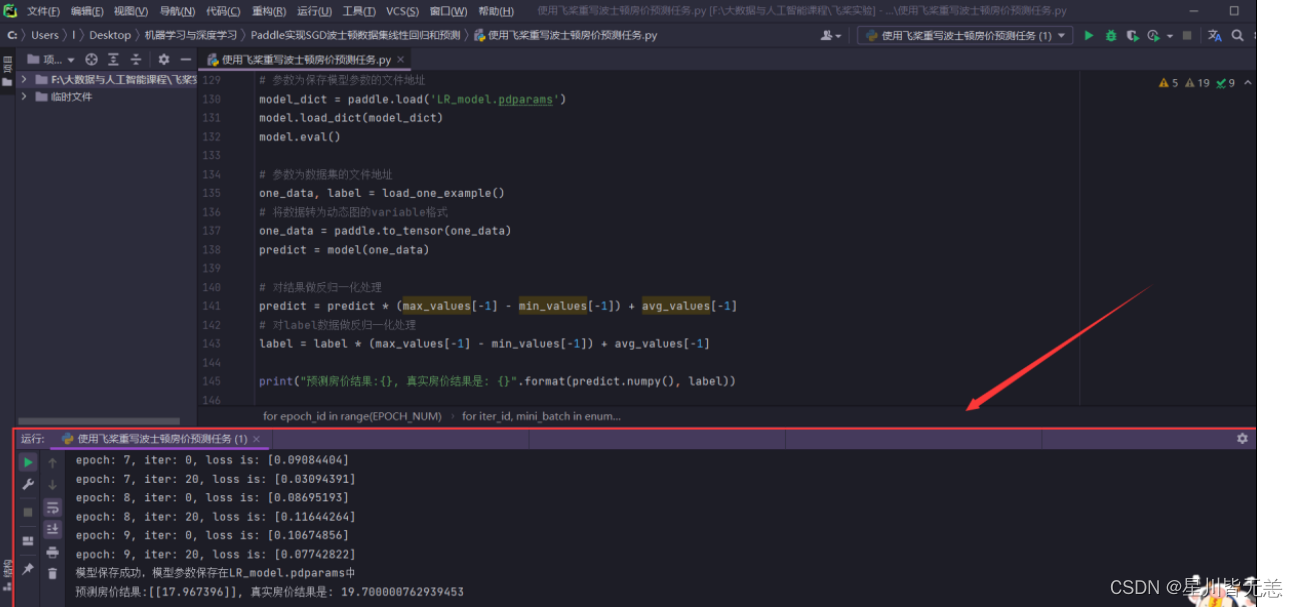
predict = predict * (max_values[-1] - min_values[-1]) + avg_values[-1]
# 对label数据做反归一化处理
label = label * (max_values[-1] - min_values[-1]) + avg_values[-1]
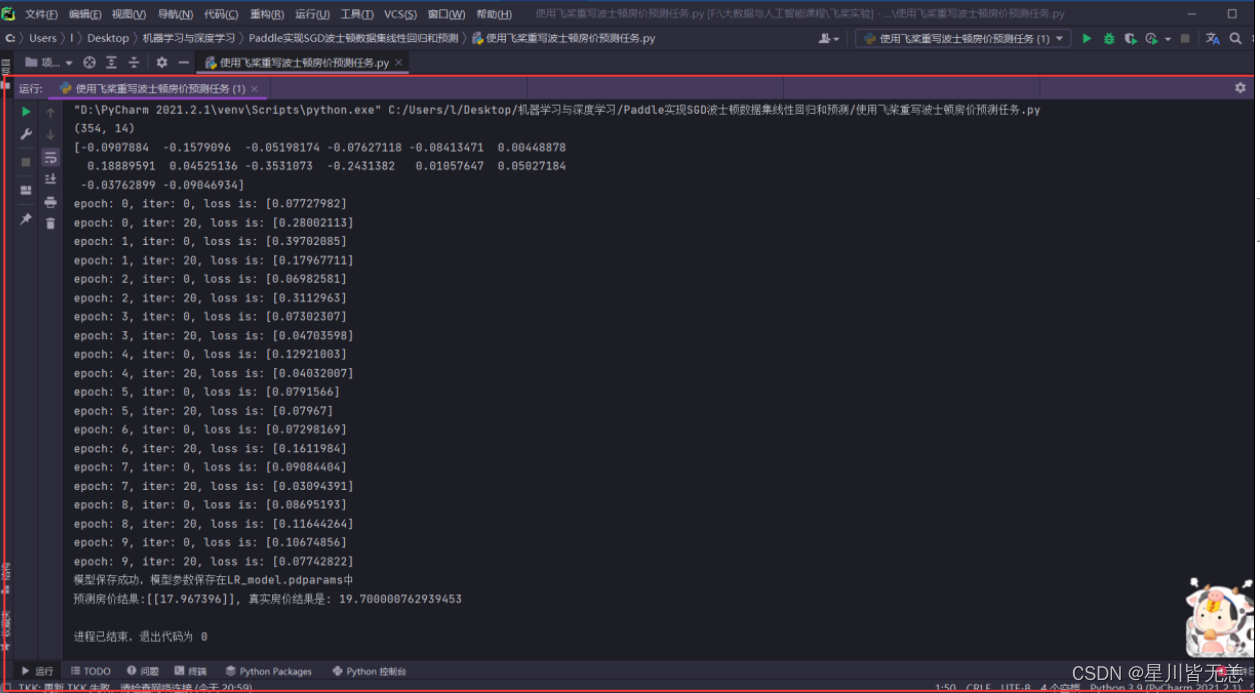
print("预测房价结果:{}, 真实房价结果是: {}".format(predict.numpy(), label))
四、代码解析
-
外层循环(Epoch循环):
pythonfor epoch_id in range(EPOCH_NUM):模型训练的外层循环,会遍历指定次数(
EPOCH_NUM)的数据集。 -
训练数据的打乱和拆分:
pythonnp.random.shuffle(training_data) mini_batches = [training_data[k:k + BATCH_SIZE] for k in range(0, len(training_data), BATCH_SIZE)]在每个 epoch 开始之前,随机打乱训练数据集。然后将数据集划分为小批次(mini-batches),每个批次包含
BATCH_SIZE条数据。 -
内层循环(Batch循环):
pythonfor iter_id, mini_batch in enumerate(mini_batches):每个 epoch 内部的循环,遍历每个小批次的数据。
-
数据处理:
pythonx = np.array(mini_batch[:, :-1]) # 获得当前批次训练数据 y = np.array(mini_batch[:, -1:]) # 获得当前批次训练标签(真实房价) house_features = paddle.to_tensor(x) prices = paddle.to_tensor(y)从当前小批次中分离出输入特征
x和对应的标签y,然后将它们转换为飞桨动态图的张量格式。 -
前向计算和损失计算:
pythonpredicts = model(house_features) loss = F.square_error_cost(predicts, label=prices) avg_loss = paddle.mean(loss)通过模型进行前向计算,然后计算预测值与真实标签的均方误差损失。
-
打印损失信息:
pythonif iter_id % 20 == 0: print("epoch: {}, iter: {}, loss is: {}".format(epoch_id, iter_id, avg_loss.numpy()))每隔一定步数打印当前的损失值,以便观察训练过程。
-
反向传播和参数更新:
pythonavg_loss.backward() opt.step() opt.clear_grad()通过反向传播计算梯度,然后使用优化器(
opt)更新模型参数 -
模型保存:
pythonpaddle.save(model.state_dict(), 'LR_model.pdparams')在训练结束后,保存训练好的模型参数到文件中。
-
加载测试数据的函数:
def load_one_example(): # 从上边已加载的测试集中,随机选择一条作为测试数据 idx = np.random.randint(0, test_data.shape[0]) idx = -10 one_data, label = test_data[idx, :-1], test_data[idx, -1] # 修改该条数据shape为[1,13] one_data = one_data.reshape([1, -1]) return one_data, label用于从测试集中随机选择一条数据作为测试样本,并返回该样本的特征和标签。
# 参数为保存模型参数的文件地址
model_dict = paddle.load('LR_model.pdparams')
model.load_dict(model_dict)
model.eval()
# 参数为数据集的文件地址
one_data, label = load_one_example()
# 将数据转为动态图的variable格式
one_data = paddle.to_tensor(one_data)
predict = model(one_data)
# 对结果做反归一化处理
predict = predict * (max_values[-1] - min_values[-1]) + avg_values[-1]
# 对label数据做反归一化处理
label = label * (max_values[-1] - min_values[-1]) + avg_values[-1]
print("预测房价结果:{}, 真实房价结果是: {}".format(predict.numpy(), label))
model_dict = paddle.load(‘LR_model.pdparams’): 从文件 ‘LR_model.pdparams’ 中加载保存的模型参数。
model.load_dict(model_dict): 将加载的模型参数字典加载到模型中。这个步骤将预训练好的参数应用到模型中。
model.eval(): 将模型设置为评估模式,这通常用于测试或推断阶段。
one_data, label = load_one_example(): 加载一个样本和其对应的标签。
one_data = paddle.to_tensor(one_data): 将输入数据 one_data 转换为 PaddlePaddle 动态图的 Variable 格式。。
predict = model(one_data): 使用加载的模型进行推断,得到预测结果 predict。
predict = predict * (max_values[-1] - min_values[-1]) + avg_values[-1]: 对模型的预测结果进行反归一化处理。
label = label * (max_values[-1] - min_values[-1]) + avg_values[-1]: 对标签数据进行相同的反归一化处理,以便比较预测结果和真实标签。
最后,打印出预测结果和真实标签:print(“预测房价结果:{}, 真实房价结果是: {}”.format(predict.numpy(), label))。这里使用 numpy() 方法将 PaddlePaddle 的 Tensor 转换为 NumPy 数组,以便更方便地打印结果。
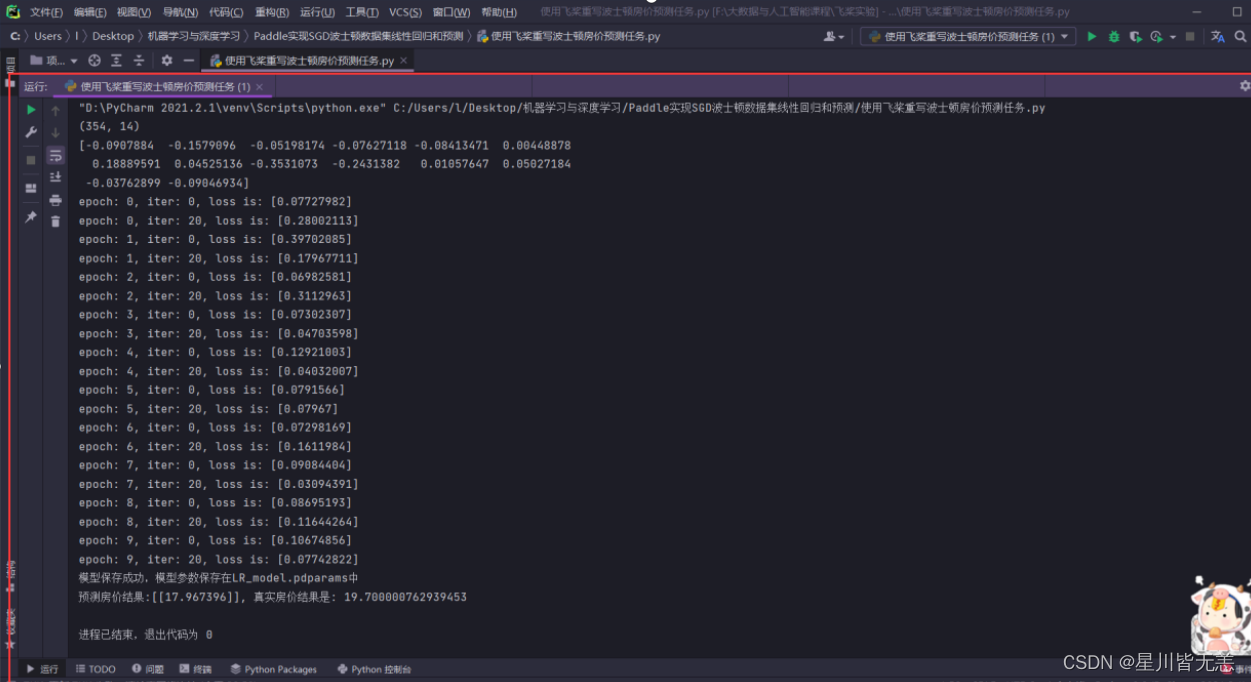
五、效果截图
保存模型参数,文件名为LR_model.pdparams
paddle.save(model.state_dict(), 'LR_model.pdparams')
print("模型保存成功,模型参数保存在LR_model.pdparams中")

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!