P51 各式各样的神奇的自注意力机制
2023-12-19 21:44:14
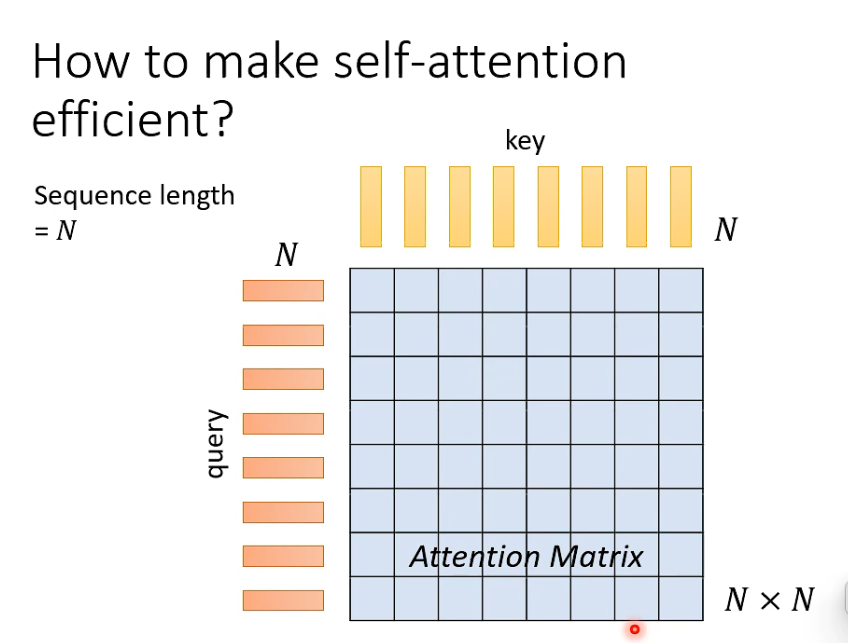
计算量大
当input sequence 很长时,计算量特别大
- self-atttention 至少一个大模型的一部分
- 当input sequence 很长时,主要运算来自self - attention, 加快 self attention ,才能有明显的加快速度
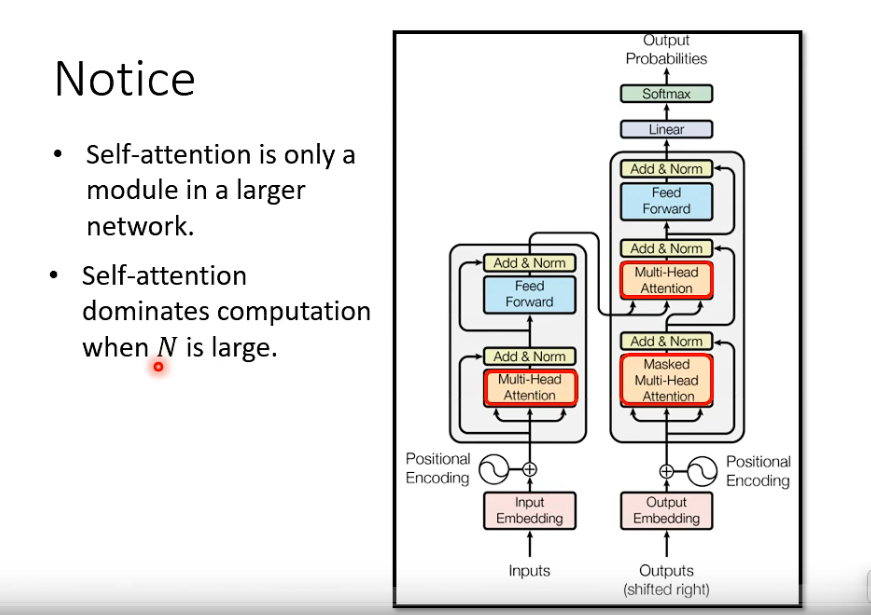
变形
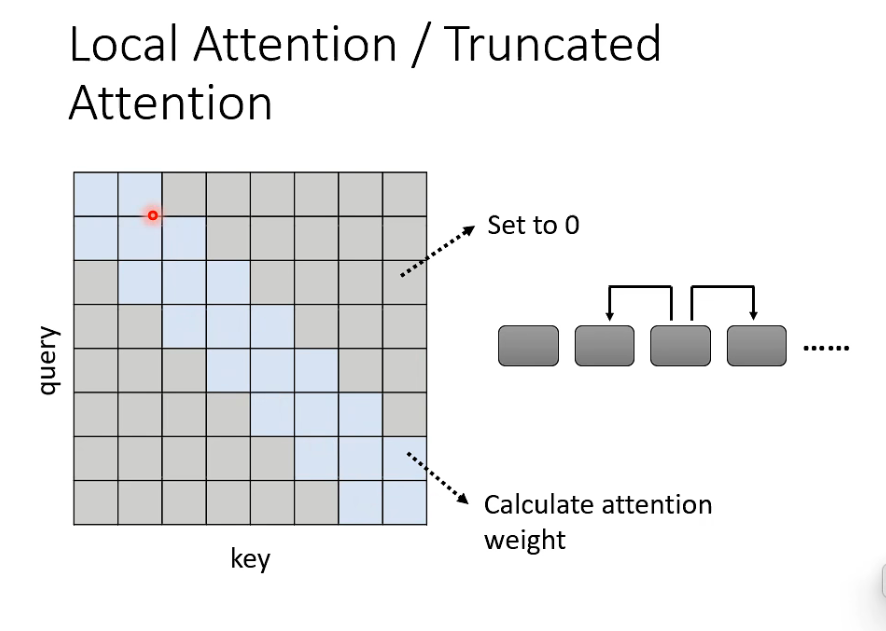
- local attention
只计算左右两个位置的 attention weight, 其他位置设为0
缺陷: 只看到某个小范围的咨询
那岂不是跟CNN一样
计算快,但是效果不一定好
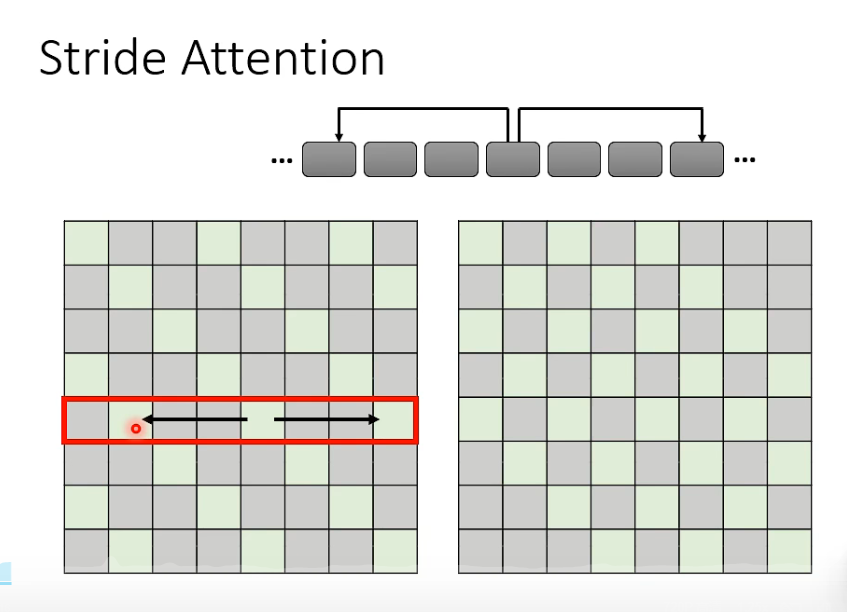
2. stride attention
如看两个间隔一个, 或者看一个间隔一个
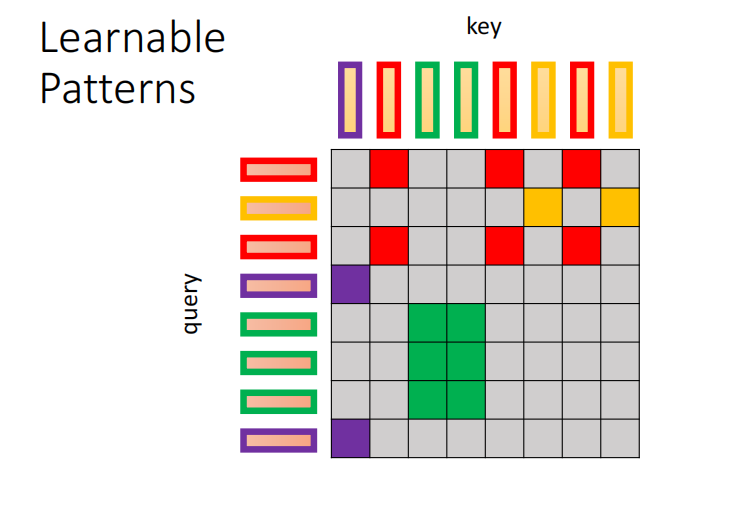
3. global attention
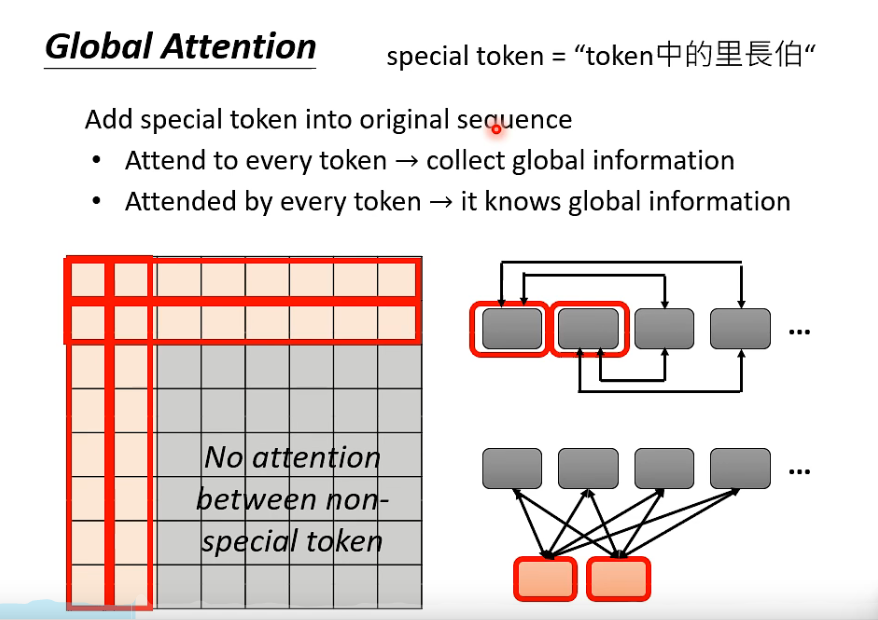
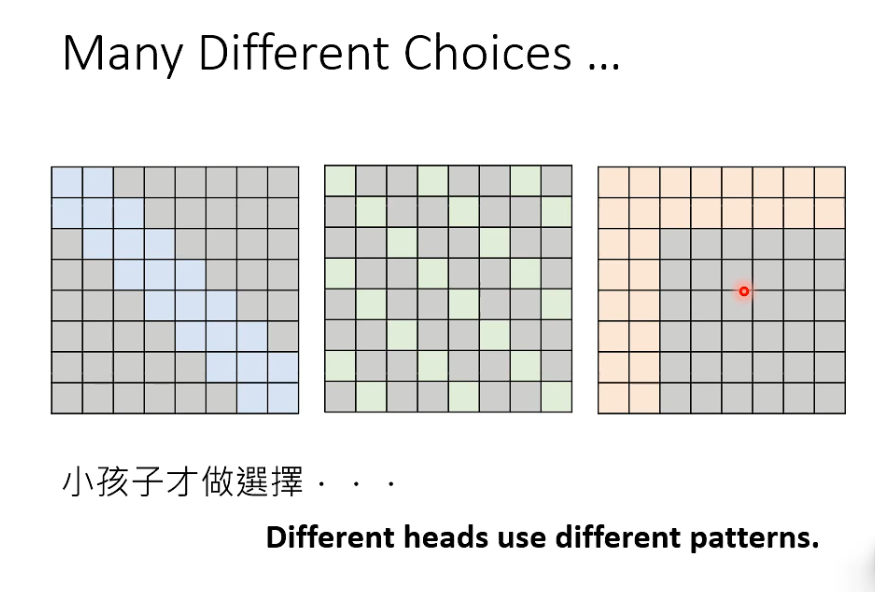
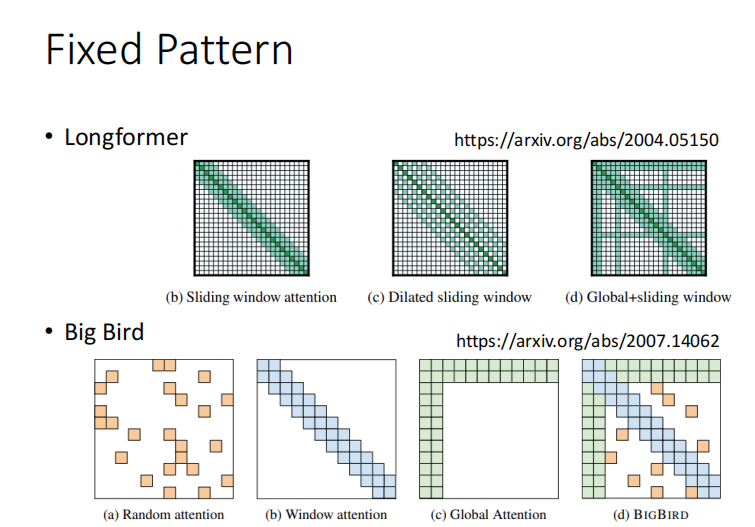
所有的 attention 变形一起上
直接估计在 atteontion matrix 里哪些位置数值大,哪些小,小的直接设为0
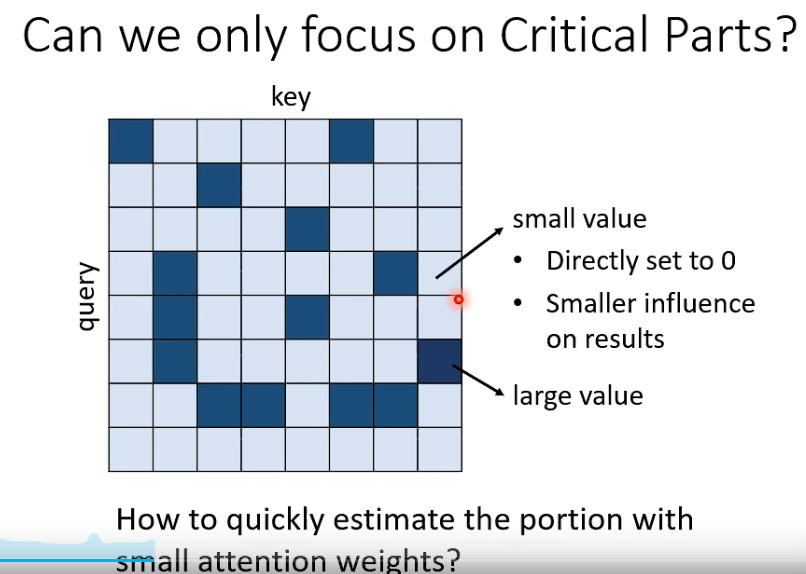
- 怎么快速预估attention weights?
(聚类,根据相似性)
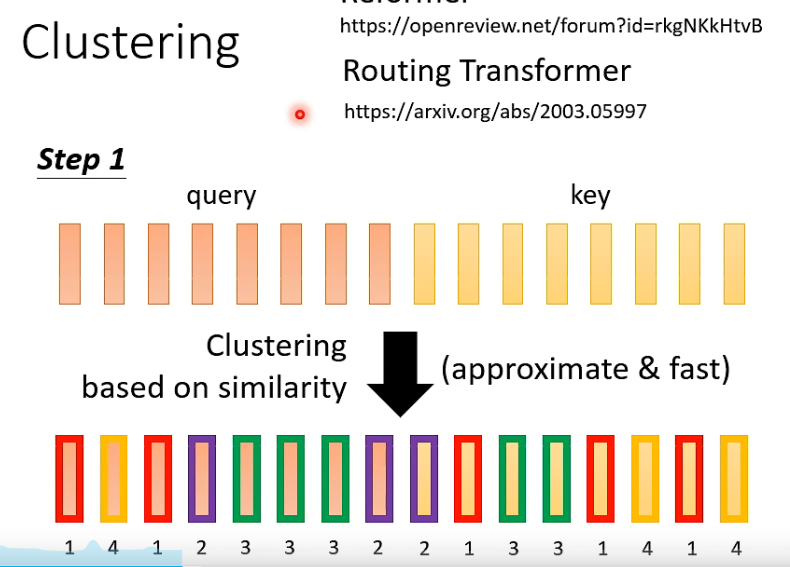
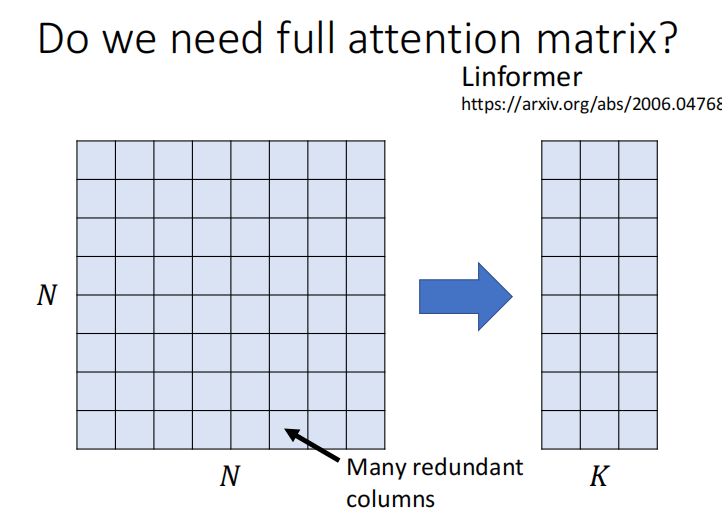
是否需要所有的 attention matrix
选择有代表性的K
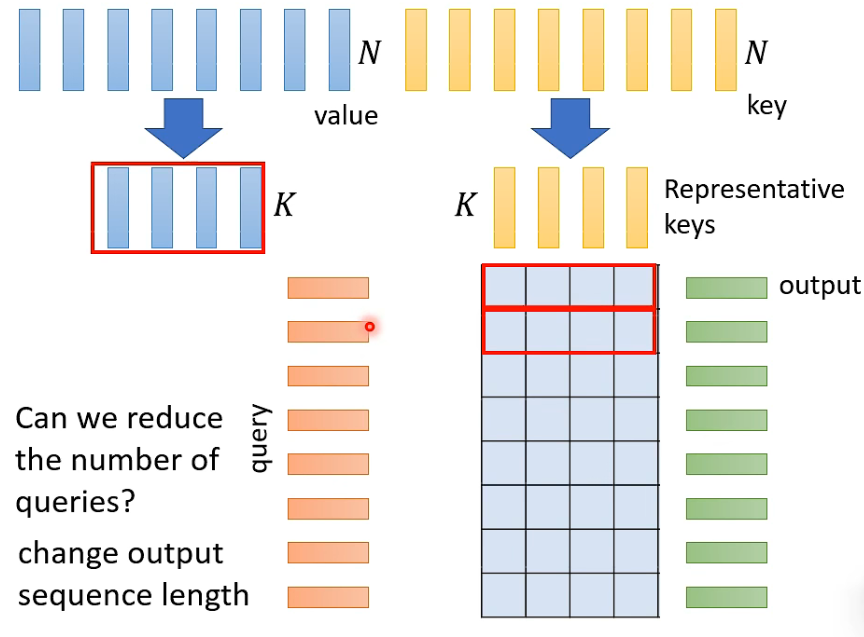
如何选择有代表性的K
CNN : 长sequence 变成 短 sequence
Linformer
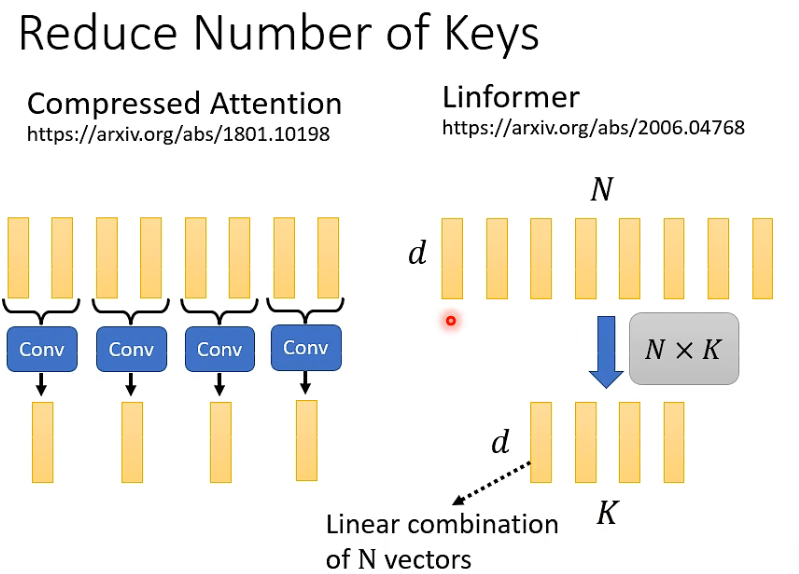
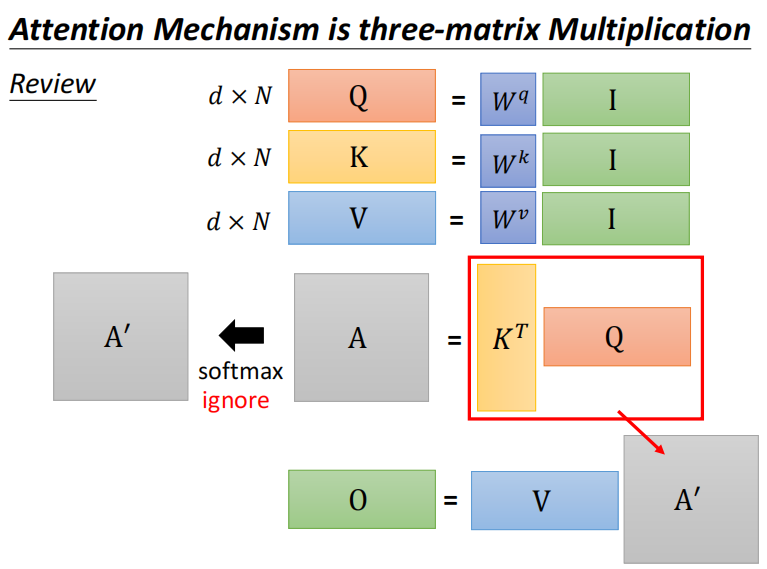
Q K 维数需要一样,V不一定
转变计算顺序 矩阵相乘的顺序,计算量不一样
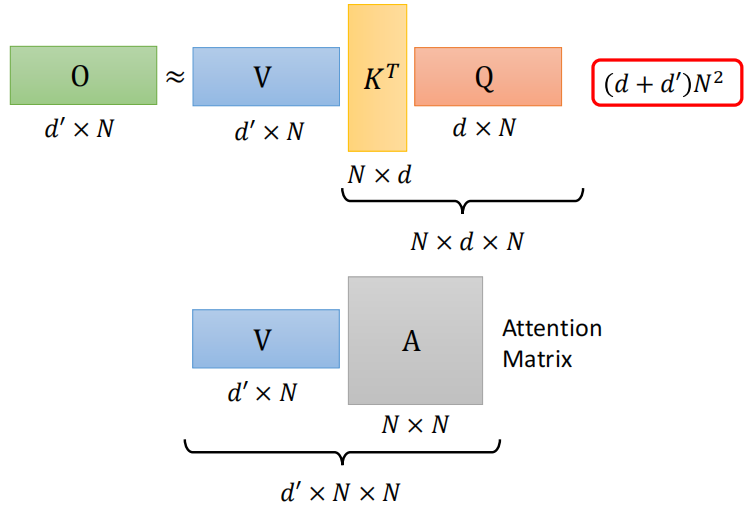
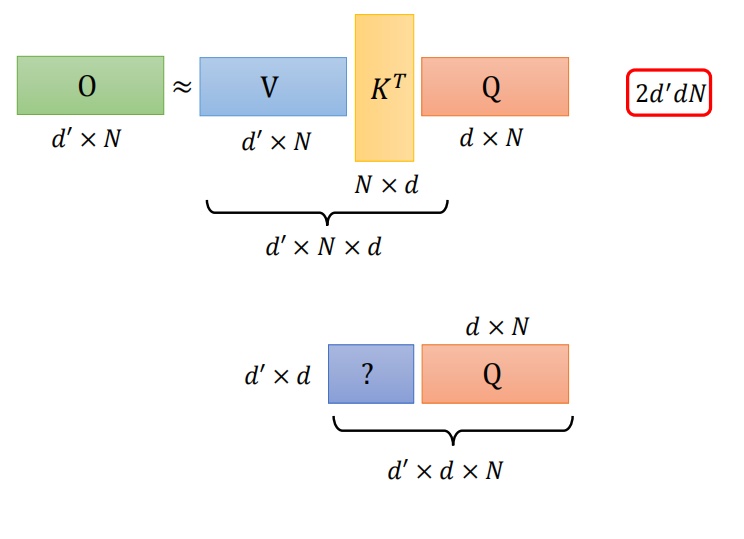
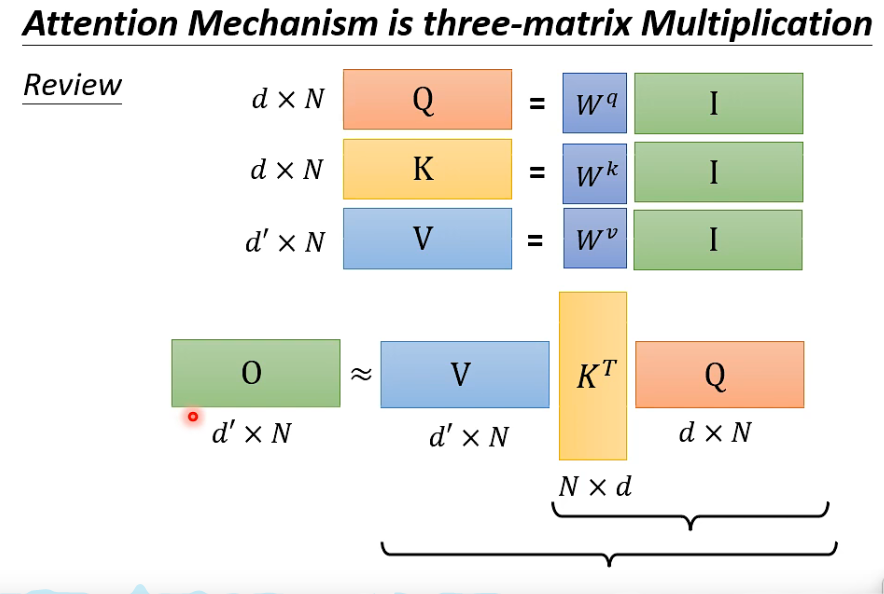
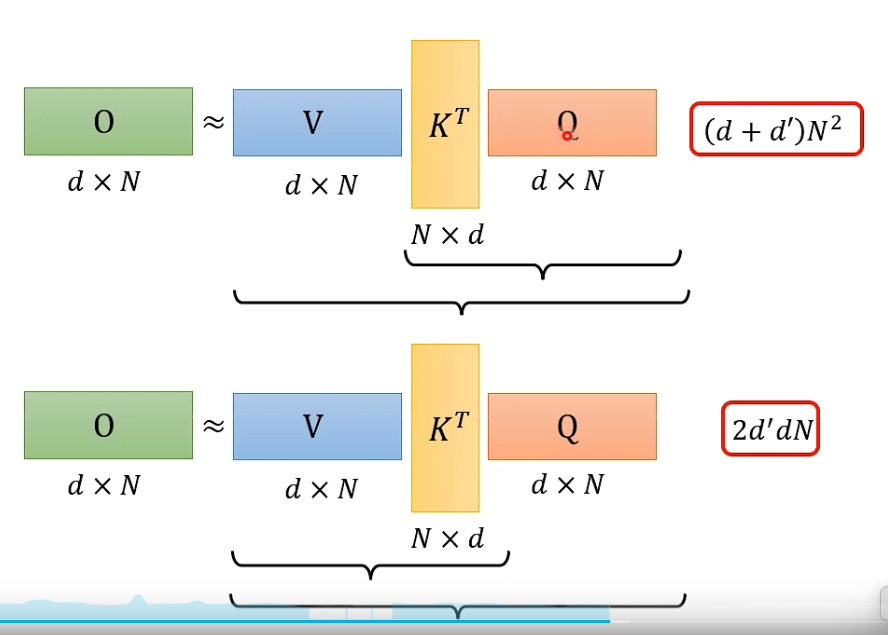
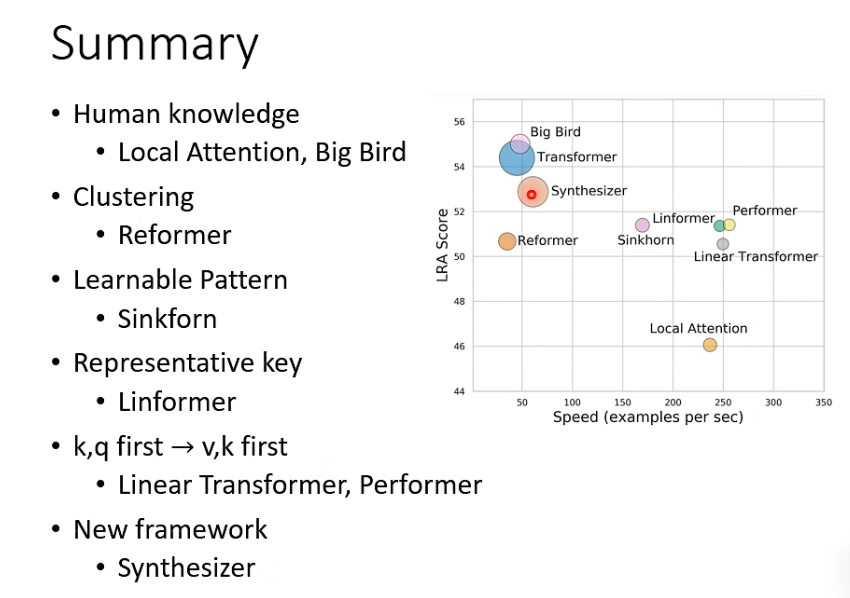
总结
文章来源:https://blog.csdn.net/weixin_39107270/article/details/135083237
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!