ResNeXt(pytorch)
2023-12-17 05:10:29
相比resnet更新了block,如下图,性能也更好一些。可以这样理解,这里的GConv还是用的分组组数还不是g=Cin,之前的ResNet中还是用的普通3*3卷积,但ResNet中引入了1*1卷积来改变通道数,减少3*3卷积的参数,后续的研究对1*1,3*3卷积进行分组来减少参数,直到ShuffleNetV2提出不能一味关注FLOPs,使得模型的结构设计更加合理,这里ResNeXt用的是3*3组卷积,之后的MobileNet用PW+DW+PW,即更特殊的组卷积DW,是这样一个发展过程,shuffleNetV1中1*1也采用组卷积来计算,也用DW卷积,创新是引入了组卷积的每组通道进行重组。ShuffleNetV2对之前的研究进行汇总,给出了新的模型结构。
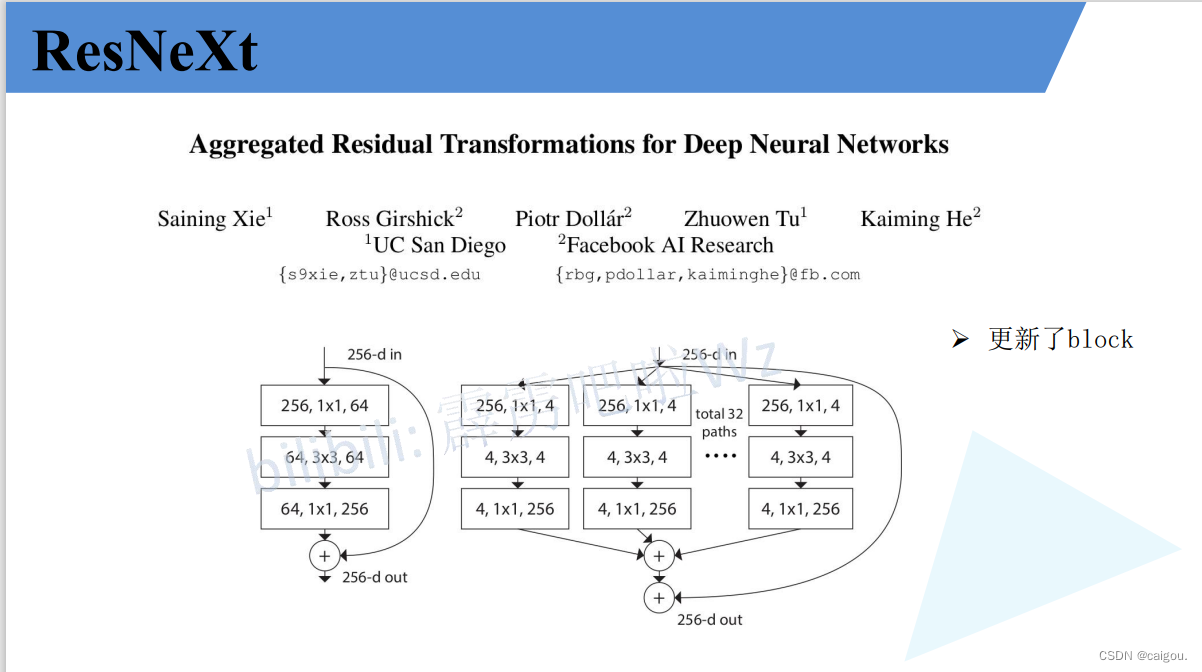
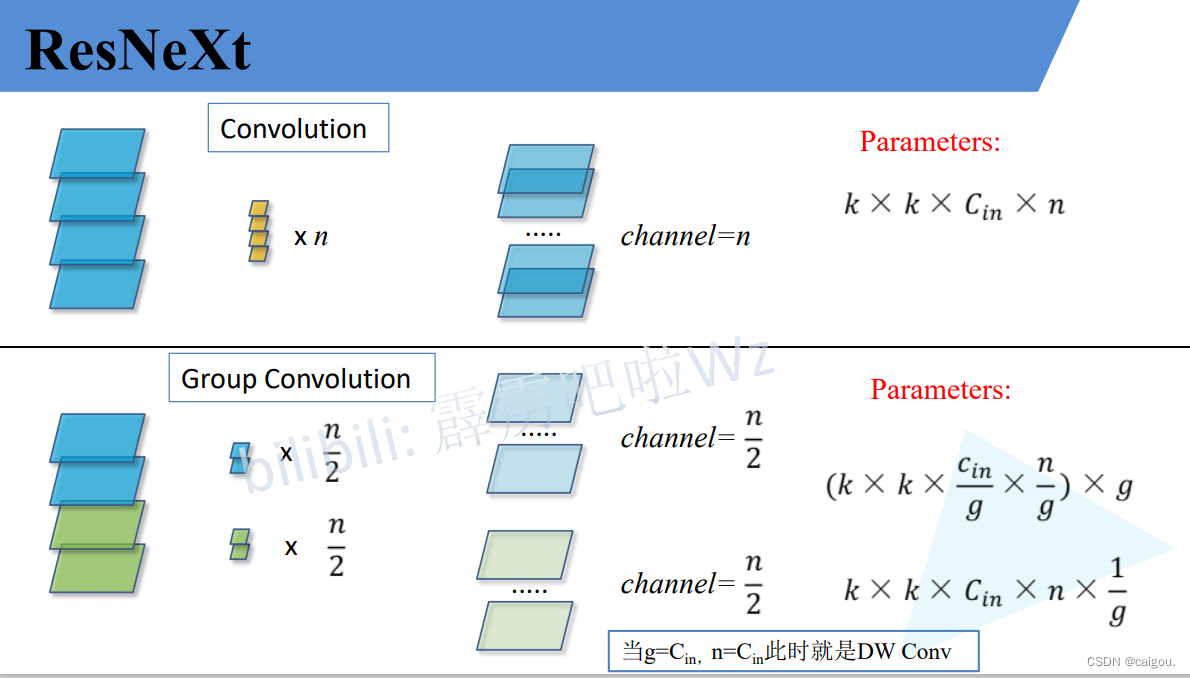
关于组卷积:DW卷积在后续很多模型中都有应用,用来减少模型参数,加快训练速度。
在resnet系列的block中,还是用1*1PW卷积用来先降维,再升维。
PW卷积就是用来改变维度的,因为DW卷积的卷积核没办法改变维度。

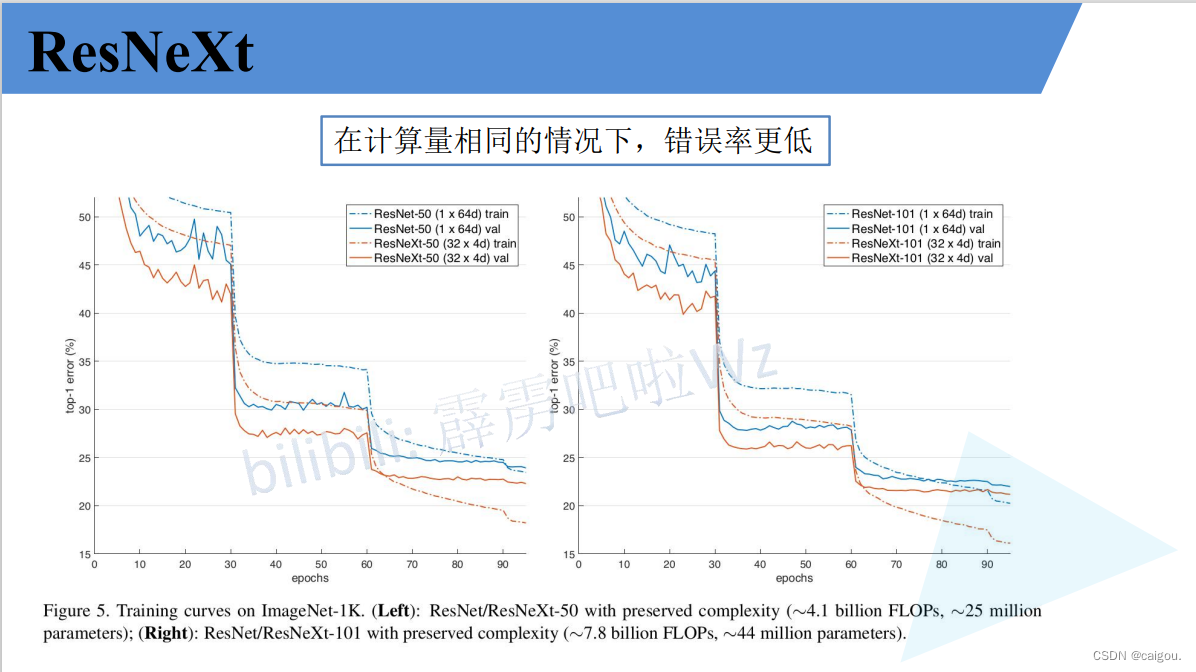
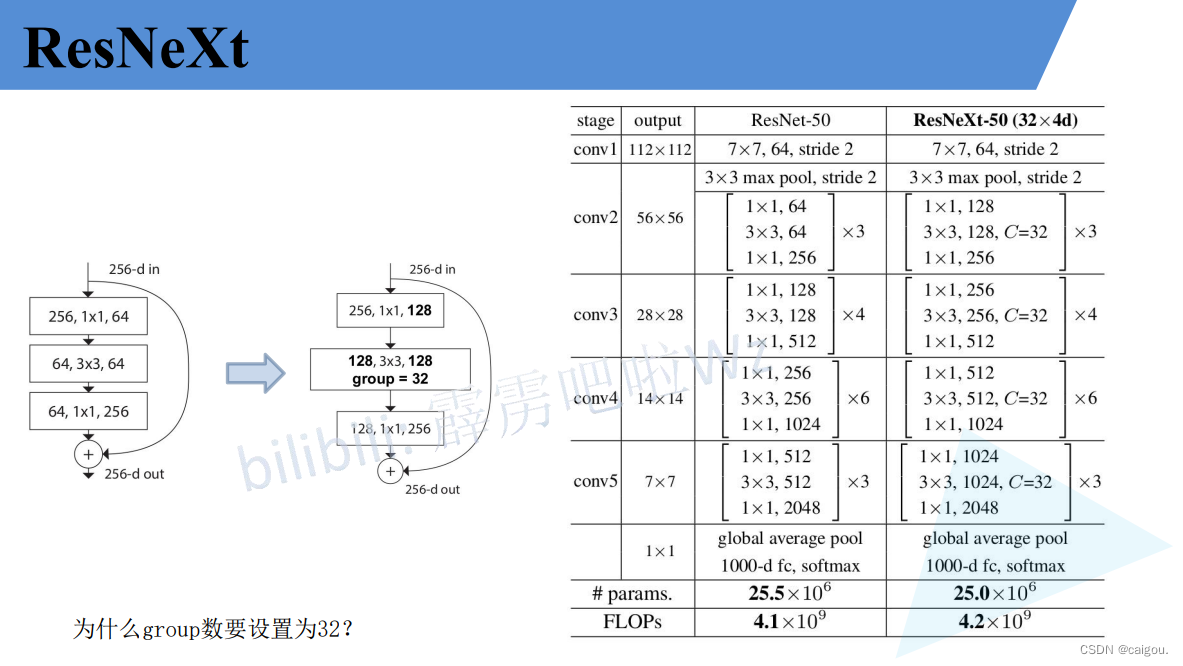
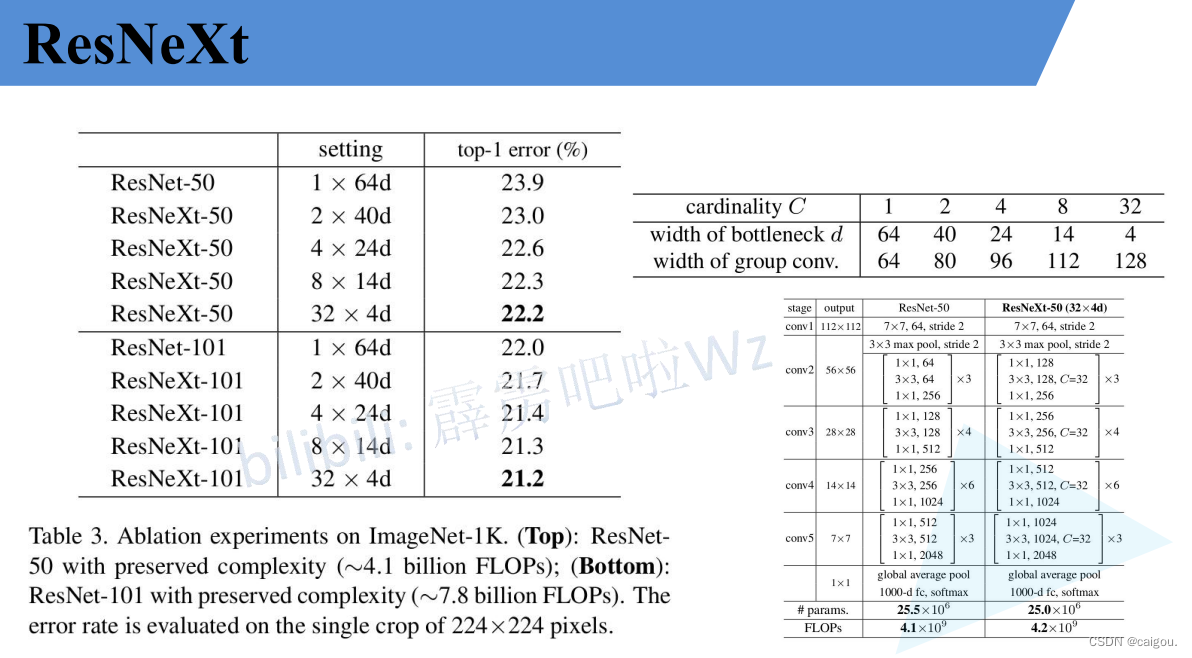
ResNet50和ResNeXt50的模型参数对比:组数设置为32组,每个卷积核是4通道,参数d表示的是卷积核的通道数,如32*4d,就是说把通道分成32组,每个卷积核的通道数是4.实验证明,32组错误率最低。
model.py
和resnet几乎一模一样,改一下Conv2d的组数即可实现,其他参数均是改变的输入输出通道数,分组卷积实现的核心步骤是groups参数,这是Conv2d的一个参数,通过这个参数,Conv2d自动实现分组卷积,具体通道变换见如下代码的bottleneck的实现分组卷积的注释部分
import torch.nn as nn
import torch
class BasicBlock(nn.Module):
expansion = 1
#resnet18,resnet34的残差块结构定义
def __init__(self, in_channel, out_channel, stride=1, downsample=None, **kwargs):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel,
kernel_size=3, stride=stride, padding=1, bias=False)
#resnet引入批标准化,加快训练速度
self.bn1 = nn.BatchNorm2d(out_channel)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel,
kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channel)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
#残差连接,这里是直接相加,googlenet是堆叠不同尺度的输出层
out += identity
out = self.relu(out)
return out
class Bottleneck(nn.Module):
"""
resnet50,101,150残差结构定义
注意:原论文中,在虚线残差结构的主分支上,第一个1x1卷积层的步距是2,第二个3x3卷积层步距是1。
但在pytorch官方实现过程中是第一个1x1卷积层的步距是1,第二个3x3卷积层步距是2,
这么做的好处是能够在top1上提升大概0.5%的准确率。
可参考Resnet v1.5 https://ngc.nvidia.com/catalog/model-scripts/nvidia:resnet_50_v1_5_for_pytorch
"""
expansion = 4
def __init__(self, in_channel, out_channel, stride=1, downsample=None,
groups=1, width_per_group=64):
super(Bottleneck, self).__init__()
#resnext50_32x4d 分32组,width=128,
#resnext50 的残差块里是四倍膨胀,resnext50_32x4d是两倍膨胀
#输出通道一样,第一层升维后通道数是不分组的2倍
width = int(out_channel * (width_per_group / 64.)) * groups
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=width,
kernel_size=1, stride=1, bias=False) # squeeze channels
self.bn1 = nn.BatchNorm2d(width)
# -----------------------------------------
# resnXt中,在3*3卷积部分使用组卷积,resnext50_32x4d 分32组,
# 在普通卷积中,输出通道数等于卷积核个数,
# 在分组卷积中,设定Conv2d中的一个groups即可实现,不用再写代码实现
# 对于resnext50_32x4d ,第一次执行到这行代码输入128,输出128,分32组,每个卷积核4通道,
# 一个4通道的卷积核对输入的128通道的特征图进行卷积得到一个输出通道
# 一共有out_channels 个4通道的卷积核
self.conv2 = nn.Conv2d(in_channels=width, out_channels=width, groups=groups,
kernel_size=3, stride=stride, bias=False, padding=1)
self.bn2 = nn.BatchNorm2d(width)
# -----------------------------------------
self.conv3 = nn.Conv2d(in_channels=width, out_channels=out_channel*self.expansion,
kernel_size=1, stride=1, bias=False) # unsqueeze channels
self.bn3 = nn.BatchNorm2d(out_channel*self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out += identity
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self,
block,
blocks_num,
num_classes=1000,
include_top=True,
groups=1,
width_per_group=64):
#groups是分组的组数,是实现resnext结构的参数,resnet设置为1即可
super(ResNet, self).__init__()
self.include_top = include_top
self.in_channel = 64
self.groups = groups
self.width_per_group = width_per_group #每组宽度,resnet直接默认64即可,
#这里传入组数是32,每组宽度是4通道
self.conv1 = nn.Conv2d(3, self.in_channel, kernel_size=7, stride=2,
padding=3, bias=False) #out:112*112*64
self.bn1 = nn.BatchNorm2d(self.in_channel)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1) #out: 56*56*64
self.layer1 = self._make_layer(block, 64, blocks_num[0]) #out: 56*56*256
self.layer2 = self._make_layer(block, 128, blocks_num[1], stride=2)
self.layer3 = self._make_layer(block, 256, blocks_num[2], stride=2)
self.layer4 = self._make_layer(block, 512, blocks_num[3], stride=2)
if self.include_top:
self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) # output size = (1, 1) (c,h,w)=(512*block.expansion,1,1)
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
def _make_layer(self, block, channel, block_num, stride=1):
#执行一次_make_layer代表创建一层,只有这一层的第一个块进行下采样操作,其他块不进行下采样操作
#一层一共有block_num个块,这个几个块的结构实在这个函数的循环里实现的
#这个channel是输出通道的1/4
downsample = None
#残差连接提前提取出残差,也就是shortcut连接,之后用于传入block中,
# self.in_channel=64!=64*4,这个判断指定在哪层下采样,是每一个层结构的第一层
if stride != 1 or self.in_channel != channel * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channel, channel * block.expansion, kernel_size=1, stride=stride, bias=False),
#input:64, 64*4,...
#out: 56*56*256 注意:这里生成的下采样
nn.BatchNorm2d(channel * block.expansion))
layers = []
layers.append(block(self.in_channel, #第一次in_channel是64
channel, # 第一次传入的channel是64,这个channel是传入的整个这一层的输出通道数
downsample=downsample, #shortcut连接部分
stride=stride,
groups=self.groups,
width_per_group=self.width_per_group))
#这个in_channel是下一次运行该层的输入通道数,256,输入256,再运行这一层第一个卷积输出64,
#这个in_channel不仅仅是这一层的第二个块的输入通道数
#同样是第二层的输入通道数,由于第一层的这个参数是256,这是个这个大类的变量,即使第二次调用这个构建层的函数in)_channel是保持不变的
#但是第二层由于in_channel=256,所以self.in_channel = channel * block.expansion,只能通过步长限制来对第二层第一个快进行
# self.in_channel 注意,这里直接改变全局的self.in_channel,在每一层运行中,这个承接上一层运行出的in_channel
self.in_channel = channel * block.expansion
for _ in range(1, block_num):
layers.append(block(self.in_channel,
channel, #通用,这个channel是传入的整个这一层的输出通道数
groups=self.groups,
width_per_group=self.width_per_group))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
# 这个全连接层通常用于将卷积层的输出特征映射转换为最终的预测或分类结果
if self.include_top:
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def resnet34(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnet34-333f7ec4.pth
return ResNet(BasicBlock, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top)
def resnet50(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnet50-19c8e357.pth
return ResNet(Bottleneck, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top)
def resnet101(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnet101-5d3b4d8f.pth
return ResNet(Bottleneck, [3, 4, 23, 3], num_classes=num_classes, include_top=include_top)
def resnext50_32x4d(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnext50_32x4d-7cdf4587.pth
groups = 32
width_per_group = 4
return ResNet(Bottleneck, [3, 4, 6, 3],
num_classes=num_classes,
include_top=include_top,
groups=groups,
width_per_group=width_per_group)
def resnext101_32x8d(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnext101_32x8d-8ba56ff5.pth
groups = 32
width_per_group = 8
return ResNet(Bottleneck, [3, 4, 23, 3],
num_classes=num_classes,
include_top=include_top,
groups=groups,
width_per_group=width_per_group)
训练了5个epoch,训练结果:
using cuda:0 device.
Using 8 dataloader workers every process
using 3306 images for training, 364 images for validation.
train epoch[1/10] loss:1.007: 100%|██████████| 207/207 [00:37<00:00, 5.45it/s]
valid epoch[1/10]: 100%|██████████| 23/23 [00:15<00:00, 1.50it/s]
[epoch 1] train_loss: 1.259 val_accuracy: 0.783
train epoch[2/10] loss:1.108: 100%|██████████| 207/207 [00:34<00:00, 6.06it/s]
valid epoch[2/10]: 100%|██████████| 23/23 [00:15<00:00, 1.50it/s]
[epoch 2] train_loss: 0.872 val_accuracy: 0.846
train epoch[3/10] loss:0.735: 100%|██████████| 207/207 [00:33<00:00, 6.09it/s]
valid epoch[3/10]: 100%|██████████| 23/23 [00:15<00:00, 1.49it/s]
[epoch 3] train_loss: 0.717 val_accuracy: 0.841
train epoch[4/10] loss:0.805: 100%|██████████| 207/207 [00:34<00:00, 6.03it/s]
valid epoch[4/10]: 100%|██████████| 23/23 [00:16<00:00, 1.43it/s]
[epoch 4] train_loss: 0.638 val_accuracy: 0.871
train epoch[5/10] loss:0.380: 100%|██████████| 207/207 [00:33<00:00, 6.11it/s]
valid epoch[5/10]: 100%|██████████| 23/23 [00:15<00:00, 1.51it/s]
[epoch 5] train_loss: 0.577 val_accuracy: 0.879
文章来源:https://blog.csdn.net/m0_56294205/article/details/134943910
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!