Dialogue Transformers:如何解决医学大模型【偏离主诉和没抓住核心】,建立抗干扰的能力,使得发现用户问题会一追到底?
Dialogue Transformers:实现抗干扰能力的对话模型
?
抗干扰能力
Dialogue Transformers 论文地址:https://arxiv.org/pdf/1910.00486.pdf
医学大模型的一个问题:偏离主诉和没抓住核心,顶级医生发现用户问题会一追到底,而不是跟随用户关注无关内容,单纯理解对几句话是毫无意义。
论文中的一段话:
- BOT:您的总额是15.50美元——我要从您上次用的那张卡上扣钱吗?
- 用户:我收到退款后,我的账户上还有存款吗?
- BOT:是的,您的账户有10美元。
- 用户:好的,很好。
- BOT:我可以下订单吗?(普通的对话系统,ta不会要催用户下单,这个跟人一样)
- 用户:是的。
- 机器人:完成。你明天应该能拿到你的东西。
第一行系统的回复是:“您的总额是15.50美元——我要从您上次用的那张卡上扣钱吗?”。
而用户在第二行提出的问题是:“我收到退款后,我的账户上还有存款吗?”这两句话之间的相关性并不明显。
系统给出了【我可以下订单吗?】,而这个回复同第一行内容高度相关,重新回到了之前的对话上下文里的核心问题。
基于 Transformer 的实现技术
论文证明了,Transformer架构比 循环神经网络RNN 模型,更适合于多轮对话的抗干扰能力。
3 种技术实现方案:
-
对话栈:将对话视为一个堆栈,按照后进先出的方式进行操作。然而,这种技术的缺点是一旦子对话完成并从栈中移除,就无法回到原来的子对话。因此,无法灵活地处理干扰和回到之前的对话上下文。
-
RNN网络:核心思想是当前状态包含过去的信息。然而,在实际业务对话中,很难获得足够的训练数据来满足RNN的训练需求,导致训练结果不确定性较高。此外,RNN默认使用整个输入进行编码,如果前面的输出有偏差,会导致后续训练结果偏离目标。
-
Transformers:Transformer相比于前两种技术,在处理意外输入内容时具有更强的抗干扰性。Transformer利用自注意力机制预先选择哪些tokens对当前状态有影响,忽略对当前状态无意义的其他tokens。ta能够独立地进行每一步的预测,并在发现无关输入时保持对话的连贯性。相比之下,使用RNN的REDP机制复制对话历史信息来回到正轨,但相对于Transformer,REDP的网络结构更复杂且泛化能力较差。
对于开放领域的对话,Transformer可以将对话上下文和领域背景知识合并,用于处理开放领域的对话任务。
可以使用 retrieve 模式或通用模式来实现,retrieve 模式使用两层 Transformer 进行相似度对比和回复编码,通用模式则将 Transformer 用作解码器逐个生成回复的 token。
总之,相对于 对话栈 和 RNN 网络,Transformer 在处理对话中的干扰和回到原对话上下文方面,具有更好的性能和灵活性。
优化目标

在Transformer的对话机制中,会将对话状态和每个系统行为进行编码,并在训练时最大化ta们之间的相似度。
- 对当前用户输入的信息 User Intent Entities、系统 BOT 给予的信息、历史信息 Previous System Action 进行编码,形成一个嵌入层 embedding layer。
- 再将 嵌入层里的隐藏状态 与每个系统行为 System Action 生成的向量,形成另一个嵌入层,进行相似度比较,以选择相似度 Similarity 排名最高的系统行为。
在这个过程中,采用了单向注意力机制,目的是让 Transformer 无法看到接下来的内容,需要将其遮住。
在端到端的 TED(Transformer Encoder Decoder)策略中,仍然采用 retrieve 模式,不会生成新的响应。
-
Retrieve模式是从预定义的候选回复集合中选择最合适的回复。在这种模式下,系统不会生成新的响应,而是从候选回复集合中检索出一个最相关的回复作为系统的回应。
-
基于检索或排序的方法来选择最合适的回复。计算对话历史和每个候选回复之间的相似度或相关性来实现。常见的方法是使用基于词向量或句向量的相似度计算方法,如余弦相似度或点积相似度。
用户和系统的对话被编码成 “bag-of-words” 的向量。
- 用户:[我, 想, 预订, 一张, 机票, 去, 纽约]
- 每个句子被转换成了一个向量,表示句子中出现的单词及其频率。
在每一轮对话中,Transformer 动态地使用自注意力机制来访问对话历史信息的不同部分。
- 如果认为 “预订” 和 “机票” 这两个单词对于生成回复很重要,那ta会分配更高的注意力权重给这两个单词,从而更关注这部分信息。
Transformer 的对话机制通过编码对话状态和系统行为,并使用自注意力机制来进行相似度比较,以选择最合适的系统行为。
这种方法能够动态地利用对话历史信息,并在训练过程中最大化状态和行为之间的相似度。
损失函数:
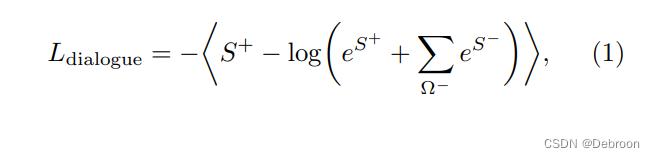
把输入向量和系统行为向量,放在同一个网络里进行训练,通过 Loss 进行反向传播。
损失度的计算公式, S+ 代表正样本的损失度,S- 代表负样本的损失度。
- 正样本表示属于目标类别的样本(订机票、天气,相关的信息)
- 负样本表示不属于目标类别的样本(有什么好的零食,无关的信息)
这个公式核心就是,最大化正样本,最小化负样本。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!