Python基础学习—Pandas数据分析实战剖析【文末送书-09】
文章目录
在当今信息时代,数据被认为是一种宝贵的资源。为了更好地理解、处理和分析海量数据,数据科学家和分析师采用了各种工具和技术。其中,Python语言中的Pandas库凭借其强大的数据结构和丰富的功能,成为数据分析领域的核心工具之一。本文将深入探讨Python学习中的一个关键主题——Pandas数据分析。
一.Pandas数据分析
Pandas是一个基于NumPy的Python数据分析库,它提供了大量的数据结构和数据分析工具,用于高效地处理和分析大型数据集。Pandas最初被开发出来是为了解决金融数据分析问题,因此它对时间序列分析提供了很好的支持。
1.1 Pandas的主要应用包括:
- 数据读取:Pandas可以方便地读取各种格式的数据,如CSV、Excel、SQL数据库等。
- 数据集成:Pandas可以将不同来源的数据集成到一个数据集中,并进行合并、连接等操作。
- 透视表:Pandas提供了透视表功能,可以对数据进行分组、汇总、过滤等操作,并生成各种统计指标。
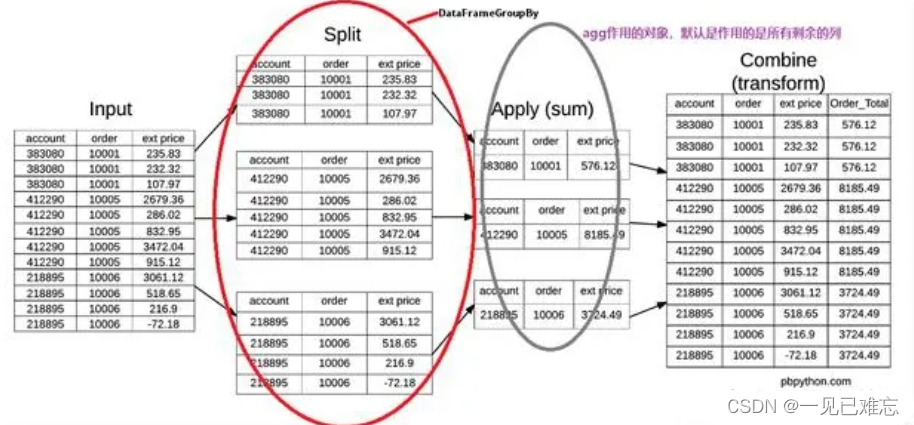
- 数据聚合与分组运算:Pandas可以按照指定的列进行聚合和分组,并对每个组进行各种运算,如求和、平均值、方差等。
- 分段统计:Pandas可以对数据进行分段统计,如按照年龄段统计人口数量、按照销售额段统计销售数量等。
- 数据可视化:Pandas可以与各种绘图库配合使用,如Matplotlib、Seaborn等,将数据以图表的形式呈现出来。
- 在使用Pandas进行数据分析时,需要先导入Pandas库,并熟悉其基本数据类型和常用函数和方法的使用。常用的数据类型包括DataFrame和Series,其中DataFrame是一个二维表格,可以包含多列数据,每列可以是不同的数据类型;而Series则是一维数组,可以包含不同类型的数据。Pandas提供了许多函数和方法来操作这些数据类型,如选取、过滤、排序、聚合等操作。
1.2 Pandas核心数据结构
Pandas基于NumPy构建,提供了两个主要的数据结构:Series和DataFrame。Series是一维标签数组,而DataFrame则是二维表格,类似于关系型数据库中的表格。这两种数据结构的强大之处在于它们允许以一种直观的方式处理和操作数据。
1.3 安装和导入Pandas
首先,确保你已经安装了Python。然后,通过以下命令安装Pandas:
pip install pandas
导入Pandas库:
import pandas as pd

二.Pandas数据分析实战:用Python进行数据分析
在现代数据科学中,Pandas是一种不可或缺的工具,它提供了丰富的数据结构和功能,使得数据分析变得更加高效和愉快。在本文中,我们将通过一个实际的数据集来展示如何使用Pandas进行数据分析,并深入了解数据背后的故事。
1. 数据集介绍
我们选用的数据集是关于电商销售的记录,包含了商品、销售额、日期等信息。数据集的目标是通过分析这些数据,洞察销售趋势、热门商品以及销售额的波动。
2. 数据加载与初步观察
首先,我们需要加载数据并初步观察。使用Pandas的read_csv方法可以轻松读取CSV文件:
import pandas as pd
# 读取数据
sales_data = pd.read_csv('sales_data.csv')
# 显示数据的基本信息
print(sales_data.info())
# 显示数据的前几行
print(sales_data.head())
通过观察基本信息和前几行数据,我们可以了解数据的结构、缺失情况等。
3. 数据清洗
在进行进一步的分析之前,我们需要清洗数据,处理缺失值、异常值等。例如,去除缺失值:
# 去除缺失值
sales_data_cleaned = sales_data.dropna()
4. 数据分析
4.1 销售趋势分析
首先,让我们分析销售随时间的变化趋势。我们可以创建一个新的日期列,并按月份对销售额进行汇总:
# 将日期列转换为日期类型
sales_data_cleaned['Date'] = pd.to_datetime(sales_data_cleaned['Date'])
# 提取月份信息
sales_data_cleaned['Month'] = sales_data_cleaned['Date'].dt.month
# 按月份汇总销售额
monthly_sales = sales_data_cleaned.groupby('Month')['Sales'].sum()
# 绘制销售趋势图
monthly_sales.plot(kind='line', marker='o')
plt.title('Monthly Sales Trend')
plt.xlabel('Month')
plt.ylabel('Sales')
plt.show()
4.2 热门商品分析
接下来,我们想知道哪些商品最受欢迎。我们可以使用value_counts方法来统计商品的销售数量,并选择前几名:
# 统计商品销售数量
top_products = sales_data_cleaned['Product'].value_counts().head(5)
# 绘制热门商品条形图
top_products.plot(kind='bar')
plt.title('Top 5 Popular Products')
plt.xlabel('Product')
plt.ylabel('Sales Quantity')
plt.show()
通过实际的数据集分析,我们成功地洞察了销售趋势和热门商品。这仅仅是Pandas在数据分析中的冰山一角,你可以根据项目需求进一步深入挖掘数据。希望这篇文章能够激发你对Pandas数据分析实战的兴趣,并在实际项目中得以应用。
三.Pandas数据分析【文末送书-09】

编辑推荐
Pandas是强大且流行的库,是Python中数据科学的代名词。本书将向你介绍如何使用Pandas对真实世界的数据集进行数据分析,如股市数据、模拟黑客攻击的数据、天气趋势、地震数据、葡萄酒数据和天文数据等。Pandas使我们能够有效地处理表格数据,从而使数据整理和可视化变得更容易。
内容简介
《Pandas数据分析》详细阐述了与Pandas数据分析相关的基本解决方案,主要包括数据分析导论、使用PandasDataFrame、使用Pandas进行数据整理、聚合Pandas DataFrame、使用Pandas和Matplotlib可视化数据、使用Seabom和自定义技术绘图、金融分析、基于规则的异常检测、Python机器学习入门、做出更好的预测、机器学习异常检测等内容。此外,该书还提供了相应的示例、代码,以帮助读者进一步理解相关方案的实现过程。
《Pandas数据分析》适合作为高等院校计算机及相关专业的教材和教学参考书,也可作为相关开发人员的自学用书和参考手册。
作者简介
Stefanie Molin是纽约彭博有限合伙企业(Bloomberg LP)的数据科学家和软件工程师,负责解决信息安全方面的棘手问题,特别是围绕异常检测、构建数据收集工具和知识共享等方面的工作。她在数据科学、设计异常检测解决方案以及在广告技术(AdTech)和金融科技(FinTech)行业中利用R和Python的机器学习方面拥有丰富的经验。
她拥有哥伦比亚大学傅氏基金工程和应用科学学院运筹学学士学位,辅修经济学、创业与创新。在闲暇时间,她喜欢环游世界、发明新食谱、学习人与计算机之间使用的新语言。
官方购书地址:
京东:https://item.jd.com/14065178.html
当当:http://product.dangdang.com/29599087.html
3.1 粉丝福利:文末推荐与福利免费包邮送书!
?参与方式:必须关注博主、点赞。(采取随机算法程序在满足关注、点赞的用户中随机抽取~)【评论不做硬性要求,但评论会增加获奖权重哦!】
??本次送书1~3本【取决于阅读量,阅读量越多,送的越多】
📆 活动截止时间:2023-12-19 21:00:00 | 由博主公布抽奖结果
送书名单:
待更新
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!