Elasticsearch 查询命令执行时,如何通过词项索引、词项字典、倒排表定位文档逻辑介绍
这里不涉及到源码,只是根据网上的一些文章总结一下,目前不需要细究,只需要知道大概就好,除非你的工作是二次开发ES
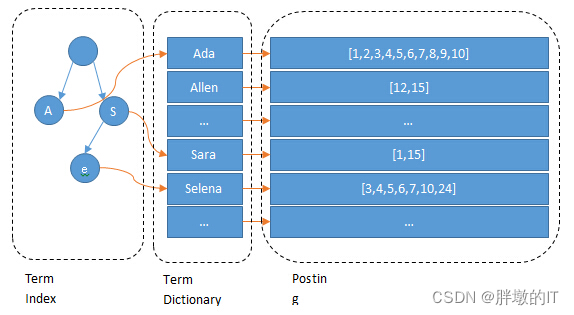
这张图你可以认为粗糙的描述倒排索引对应关系,下面的文章也是主要讲解这张图各个部分含义
一、?Term Index(词项索引)
看这个
?Term Index是不是特别想树的数据结构?比如二叉树或者多叉树?其实是FST,下面看一下它是怎么出来的
1、FSM(Finite State Machine)有限状态机
表示有限个状态(State)集合以及这些状态之间转移和动作的数学模型。其中一个状态被标记为开始状态,0个或更多的状态被标记为final状态。来自[转]ElasticSearch 查询的秘密
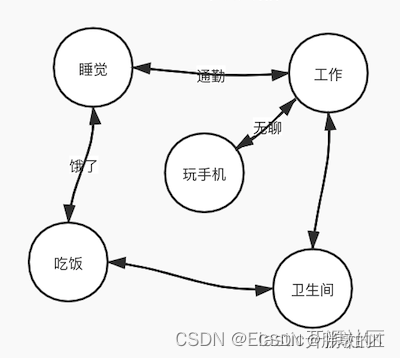
这种模型使用原型的节点标示某个“状态”,状态之间可以互相转换,但是转换过程是无向的。
比如睡觉醒了可以去工作,工作累了可以去玩手机;或者工作中想去上厕所等等。
在这个模型中,标示状态的节点是有限多个的,但状态的转换的情况是无限多的,同一时刻只能处于某一个状态,并且状态的转换是无序切循环的。
显然这种模型并不适用于描述Term Dictionary这样的数据结构,所以再看一下演变的FSA
2、FSA(Finite State Acceptor)确定无环有限状态接收机
相较于FSM,FSA增加了Entry和Final的概念,这样就增加了如下3个特性
1、确定:意味着指定任何一个状态,只可能最多有一个转移可以访问到。
2、无环: 不可能重复遍历同一个状态
3、接收机:有限状态机只“接受”特定的输入序列,并终止于final状态。
来自:关于Lucene的词典FST深入剖析
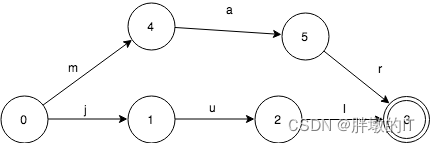
我们如何来表示只有一个key:jul 的集合。FSA是这样的:

当查询这个FSA是否包含“jul”的时候,按字符依序输入。
输入j,FSA从0->1
输入u, FSA从1->2
输入l,FSA从2->3
这个时候,FSA处于final状态3,所以jul是在这个集合的。
增加一个key:mar 就如下表
再增加一个key:jun
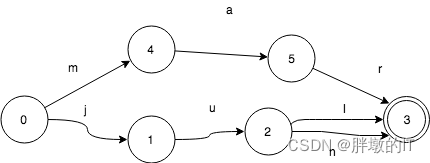
遍历算法是这样的:
初始状态0, key=””
->1, key=”j”
->2, key=”ju”
->3, key=”jul”, 找到jul
2<-, key=”ju”
->3, key=”jun”, 找到jun
2<-, key=”ju”
1<-, key=”j”
0<-, key=””
->4, key=”m”
->5, key=”ma”,
->3, key=”mar”,找到mar
这个算法时间复杂度O(n),n是集合里所有的key的大小, 空间复杂度O(k),k是结合内最长的key字段length。
再看一下更复杂的,由“october”,“november”,”december”构成的FSA
所以FSA不光共用前缀,后缀也一样可以共用
即使FSA已经满足了对Term Dictionary数据高效存储的基本要求,但是仍然不满足的一个问题就是,FSA无法存储key-value的数据类型,
3、FST(Deterministic acyclic finite state transducer)确定无环状态转换器
FST在FSA基础上为每一个出度添加了一个output属性,用来表示每个term的value值,
来自:倒排索引:ES倒排索引底层原理及FST算法的实现过程
下面拿key:msb输出 要输出一个value:10 和再新增一个key:msbtech输出一个value:5的FST是如何构建的

当第一个term:msb被写入FST中,其输出值被保存在了其第一个节点的出度上,在数据从FST中读取的时候, 计算其每个节点对应的出度的输出值以及终止节点的final output值的累加和,从而得出输出值,此时msb的输出值就是10+0+0+0=10,但是这里我用0来标识没有输出值,但实际情况没有输出值就是空而不是0,这里写0只是为了方便你去理解,这一点是需要注意的。
当第二个term:msbteach被写入的时候,其输出值5与msb的输出值10发生了冲突,这时,通用最小化算法法则发挥了功效。数字虽然不能像字符那样以前缀作为复用手段,但是数字是可以累加的,10可以拆成两个数字5,这样10和5就产生了公共部分,即5,所以这个时候m的输出值就需要改成5,那另一个5就需要找一个合适的位置,然而把它存放在任何一个节点的出度上似乎都会影响msbtech的计算结果,为了避免这个问题,可以把这个多出来的属于msb的输出值存入msb的final节点的final output中,节点的final output只会在当前出度是输入值的最后一个字符并且出度的target指向的是final节点的时候,才会参与计算。因此此时的msb和msbtech就各自把输出值存入了合适的位置,互不影响而且做到了“通用最小化”原则。
所以大体上就知道了?Term Index 中的FST是怎样的数据结构了
二、Term Dictionary(词项字典)
这个就比较直白,就是各个分词后的字段列表
来自:倒排索引:ES倒排索引底层原理及FST算法的实现过程
下面拿右边的做一个例子,这样Term Dictionary会把右边的表中product字段的内容分词,分成左边的表格中的样例
但是既然都已经知道上面的term index了,那看存储词项索引的文件.tip数据结构和输出如何映射到词项字典文件.tim
词项字典包含了
index field的所有经过normalization token filters处理之后的词项数据,最终存储在.tim文件中。
所谓normalization其实是一个如去重、时态统一、大小写统一、近义词处理等类似的相关操作;词项索引就是为了加速词项字典检索的一种数据结构,落地文件为.tip
所以,词项字典也是存储了很多东西的,一个block代表像小米、手机这样的分词块
三、Posting List(倒排表)
倒排表这里主要说一下两种压缩算法,因为都知道倒排表存储的是词项字典对应的文档的id,那如何存储的呢?因为要考虑到量的问题,虽然不是文档本身,但是id这个字段存储几十亿的量还是挺大的
1、FOR(Frame Of Reference)压缩算法(差值存储)
即不存储原本的数值,而是存储每个数值与前一个数字的差值,这个适用于id之间差值都很小,或者只有几个id之间差值大的场景,这种数组也叫
稠密数组
下面以某个id的集合是[1,2,3…100万]和[73,300,302,332,343,372]举例
如果是[1,2,3…100万],用差值存储你可能就知道为什么这么做了,节省的空间存储很多,压缩了32倍。
下面又用了一个特殊的例子[73,300,302,332,343,372]来演示特殊的情况,就是某两个id之间差值之间太大的情况,数组经过拆分,分为了两个数组,第一个数组每个数字占用1个Byte,共两个数字,总占用为2Bytes,记录数组单位大小的Record Space大小为1Byte,第二个数组每个数字占用5个bit,一共四个数字,共计20bit,但是计算空间的最小单位是Byte,所以实际占用的大小为3Bytes,第二个数组的Record Space大小也是1Byte,因此压缩后的数据总大小为1B+2x1B+3B+1B=7Bytes,相比压缩之前,大小不到原先的三分之一。
但是可能还有更特殊的,每一个id之间相差都很大,就有了下面这种压缩算法RBM
2、RBM(RoaringBitmap)压缩算法(32位int拆成两个16位的short存储)
针对id数据大部分id之间差值都很大,用差值存储压缩不了多少的情况,这里称这种数组为
稀疏数组,Lucene对于这种稀疏数组采用了另一种压缩算法
下面用 [1000,62101,131385,132052,191173,196658] 这种典型稀疏数组为例
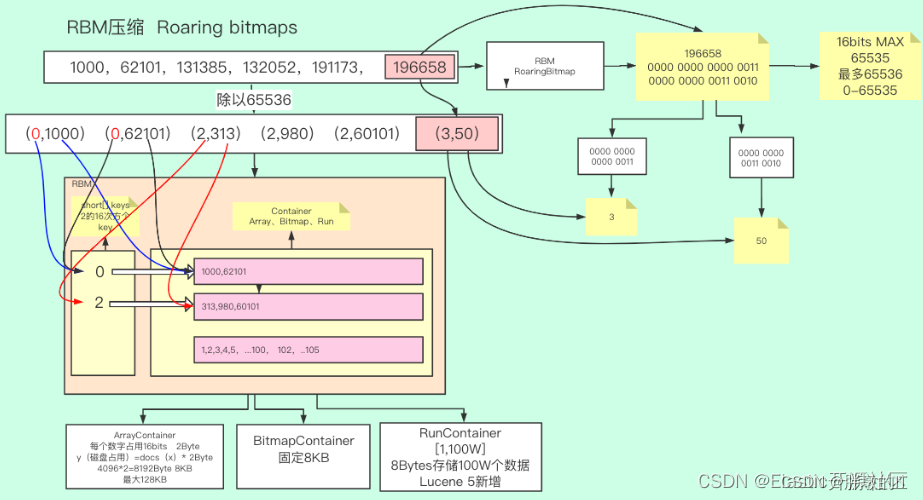
RBM算法本身的设计思路是将原数字的的32个bit分为了高16位和低16位。以原数组中的196658这个id为例,将其转化为二进制结果为 110000000000110010,我们看到其实结果是不足32bits的,但因为每个int型都是有32个bit组成的,不足32bit会在其前面补0,实际其占用的空间大小仍然为32bits,如果这一点不理解,打个比方,公交车有32个座位,无论是否坐满,都是使用了32个座位。最终196658转换成二进制就是0000 0000 0000 0011 0000 0000 0011 0010,前16位就是高16位,转换成十进制就是3,后16位也就是低16位,转换成十进制就是50
到这一步其实你有疑问?拆开空间也没有变小啊,还是32bits啊?那可以继续往下看
对数组中每个数字进行相同的操作,会得到以下结果:(0,1000)(0,62101)(2,313)(2,980)(2,60101)(3,50),其含义就是每个数字都由一个很大的数字变为了两个很小的数字,并且这两个数字都不超过65536,更重要的是,当前结果是非常适合压缩的,因为不难看出,出现了很多重复的数字,
比如前两个数字的得数都是0,以及第2、3、4个数字的得数都是2。RBM使用了非常适合存储当前结果的数据结构。这种数据结构是一种类似于哈希的结构,只不过Key值是一个short有序不重复数组,用于保存每个商值,value是一个容器,保存了当前Key值对应的所有模,这些模式不重复的,因为同一个商值的余数是不会重复的。
这里的容器官方称之为Container,RBM中包含三种Container,分别是ArrayContainer、BitmapContainer和RunContainer,
(1)ArrayContainer
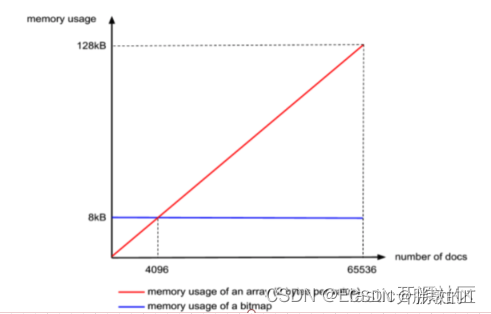
ArrayContainer,顾名思义,Container中实际就是一个short类型的数组,其空间占用的曲线如图3-4中的红色线段,注意这里是线段,因为docs的数量最大不会超过65536,其函数为 y(空间占用)=x(docs 长度) x 2Bytes,当长度达到65536极限值的时候,其占用的大小就是16bit * 65536 / 8 /1024 = 128KB,乘以65536是总bit数,除以8是换算成Byte,除以1024是换算成KB。
(2)BitmapContainer
第二种是BitmapContainer,理解BitmapContainer之前首先要了解什么是bitmap。以往最常见的数据存储方式都是二进制进位存储,比如我们使用8个bit存储数字,如果存十进制0,那二进制就是 0 0 0 0 0 0 0 0,如果存十进制1,那就是 0 0 0 0 0 0 0 1,如果存十进制2,那就是 0 0 0 0 0 0 1 1,用到了第二个bit。这种做法在当前场景下存储效率显然不高,如果我们现在不用bit来存储数据,而是用来作为“标记”,即标记当前bit位置商是否存储了数字,出的数字值就是bit的下标,如下图所示,就表示存储了2、3、5、7四个数字,第一行数字的bit仅代表当前index位置上是否存储了数字,如果存储了就记作1,否则记为0,存储的数字值就是其index,并且存储这四个数字只使用了一个字节。

不过这种存储方式的问题就是,存储的数字不能包含重复数字,并且Bitmap的大小是固定的,不管是否存储了数值,不管存储了几个值,占用的空间都是恒定的,只和bit的长度有关系。
但是我们刚才已经说过,同一个Container中的数字是不会重复的,因此这种数据类型正好适合用这种数据结构作为载体,而因为我们Container的最大容量是65536,因此Bitmap的长度固定为65536,也就是65536个bit,换算成千字节就是8KB,如图的蓝色线段所示,即Lucene的RBM中BitmapContainer固定占用8KB大小的空间,
通过对比可以发现,当doc的数量小于4096的时候,使用ArrayContainer更加节省空间,当doc数量大于4096的时候,使用BitmapContainer更加节省空间
(3)RunContainer
第三种Container叫RunContainer,这种类型是Lucene 5之后新增的类型,主要应用在连续数字的存储商,比如倒排表中存储的数组为 [1,2,3…100W] 这样的连续数组,如果使用RunContainer,只需存储开头和结尾两个数字:1和100W,即占用8个字节。这种存储方式的优缺点都很明显,它严重收到数字连续性的影响,连续的数字越多,它存储的效率就越高。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!