[Longformer]论文实现:Longformer: The Long-Document Transformer
文章目录
论文:Longformer: The Long-Document Transformer
作者:Iz Beltagy, Matthew E. Peters, Arman Cohan
时间:2020
地址:https://github.com/allenai/longformer
一、完整代码
这里我们使用python代码进行实现
# 完整代码在这里
# https://github.com/allenai/longformer
二、论文解读
论文中有大量的文字性描述,不太好看,可是当我真正理解其意思后,感觉也画不了多少图,好像怪不了作者;
2.1 介绍
限制于Transformer-based model的局限性,无法处理过长的文本序列,为了解决这一个问题,作者提出了一个处理长文本序列的模型Longformer,该模型利用特殊的注意力机制将内存和计算量从平方转化为线性;
Transformer利用自注意力机制在广泛的自然语言处理任务中取得了先进的成果,这种成功部分是由于自注意成分,它使网络能够从整个序列中捕获上下文信息;但是这种处理方式有一个缺点,内存和计算量是随着序列的长度成平方次增长;这导致在长序列任务中内存和计算需求特别高,实际上是不可行的;
为了解决这个问题,作者提出了Longformer模型,该模型在transformer的基础上进行了修改,使用了独特的注意力机制,使注意力机制的规模不是随序列长度平方增长而是线性增长,这样就可以处理长序列任务了;
有人可能会奇怪,长序列任务AR语言模型不能做吗?例如transformer-xl可以充分利用记忆力机制和循环来生成优化;但是这里要注意的是,AR模型是单向的,只有两种方式,一个是从左到右,一个是从右到左;

因此,要充分结合上下文信息,AR模型是行不通的,而对应的,attention matrix采取的ltr方式是行不通的,所以我们采用sparse方式构造注意力矩阵;
Longformer的注意力机制是局部窗口和全局注意力的结合,局部窗口注意力主要用于构建上下文表示,而全局注意允许Longformer构建用于预测的全序列表示,适用于特定的任务;
sparse源于Sparse-Transfomer,其使用了BlockSparse类似的尺寸为8*8的膨胀滑动窗口,如下图的c 图采取的方式一样,但是Longformer为了使某些token具有全局代表性预测能力,对某些使用了全局注意力机制,得到最后的结果便是d 图;

现在有许多的特定任务模型采取了一些措施去绕过像BERT一样的预训练语言模型的512 tokens的限制去处理长序列文档,其不外乎以下几种方法:
- 直接将长文本截断;
- 将长文本分成长度都是
512 tokens的小块,然后结合各个小块处理后的结果; - 使用两阶段模型,第一阶段检索出相关的文档,第二阶段结合第一阶段的文档提取出答案;这适用于答案有多次跳越和开放领域的QA任务;
两阶段模型来源于[2004.06753] A Simple Yet Strong Pipeline for HotpotQA (arxiv.org),其具体采取的方法如下:

以上的三种处理方法都会因为截段或者阶段检索错误而导致信息不完整出现损失,相比之下,Longformer直接对文本进行处理不会出现损失;
那么Longformer是如何获取全局信息的呢?其类似于CNN模型的感受野;

如图,虽然说在最底层a1和a5没得信息交流的作用,但是在c 层中的c1,a1和a5间接形成了交流,虽然不如Full attention强烈,但是总是有效果的;
2.2 Longformer
注意力模式
其使用的注意力模式包括了前面的三种,结合前面的三种,就是Longformer采取的注意力模式,就是第四种模式;
滑动窗口:类似于CNN,给定一个固定的窗口大小w,每个token关注左右两边的
1
2
\frac{1}{2}
21?个w的token;计算度从n*n降低为n*w,如果每层的w是固定的,则顶层的接受域大小为l*w;可以根据应用的不同,可以在不同的层使用不同的w值来在效率和模型表示能力之间保持一个良好的平衡;
膨胀滑动窗口:为了在不增加计算量的情况下进一步的提升感受野,可以通过把滑动窗口进行膨胀的方式来处理;假设点与点之间的间隙为d,接受域就变成了l*w*d;这样的话,即使计算量很小,也可以拥有很大的接受域;我们可以通过在多头注意中,对每个头部配置不同的扩张设置,允许一些没有扩张的头部关注局部环境,而其他有扩张的头部关注更长的环境,从而提高了性能,就相当于不同大小的核的CNN
全局注意:在类似于BERT的语言模型处理自然语言任务时,其输入表示又任务的不同而发生变化,例如BERT在文本分类中使用<cls>,在其他任务中<cls>并没有多大用处;例如MLM机制,利用上下文来预测masked token;这些都是根据任务的不同而改变了输入的表示;在Longformer中,滑动窗口和膨胀滑动窗口都收到了一定的限制,其不如全局注意力有那么强的表示能力;我们可以在少数预先的位置添加全局注意,同时对称化:全局注意的token要关注所有的token,同样的所有的token都要关注全局注意的token;例如,在分类任务中,对<CLS>标记使用全局注意,而在QA任务中,对所有问题标记提供全局注意。由于这类标记的数量相对于n较小,且与n无关,因此局部和全局注意力组合的复杂性仍然是O (n);
注意力计算
Linear Projections for Global Attention:
transformer的注意力机制计算如下:

在这里,由于我们使用了局部注意力和全局注意,我们需要两种投影, Q s , K s , V s Q_s,K_s,V_s Qs?,Ks?,Vs?去建立滑动窗口构造局部注意力, Q g , K g , V g Q_g,K_g,V_g Qg?,Kg?,Vg?构造全局注意;额外的投影为建模不同类型的注意力提供了灵活性,我们表明,这对于下游任务的最佳表现至关重要。 Q g , K g , V g Q_g,K_g,V_g Qg?,Kg?,Vg?使用 Q s , K s , V s Q_s,K_s,V_s Qs?,Ks?,Vs?的值初始化;
在常规的transformer模型中,
Q
K
T
QK^T
QKT由于维度都是
n
n
n,需要计算
n
(
o
2
)
n(o^2)
n(o2)次,而在Longformer中,膨胀滑动窗口注意只需要计算出一个固定数量的
Q
K
T
QK^T
QKT对角线,只需要计算
n
(
o
)
n(o)
n(o)次;而在常规的pytorch/tensorflow中,是无法直接计算的;实现它需要一种带状矩阵乘法的形式,这在现有的pytorch/tensorflow中是不支持的;
在论文中讲解了三种不同的实现方式:
- Longformer-loop:一种在循环中分别计算每个对角线的简单实现。它的内存效率很高,因为它只计算非零值,但它的速度慢得难以使用。我们只使用它来进行测试,因为它很容易实现,但不使用它来运行实验。
- Longformer-chunks:只支持非膨胀的滑动窗口。它将
Q
Q
Q和
K
K
K块分割成大小为
w
w
w的重叠块和大小为
1
2
w
\frac{1}{2}w
21?w的重叠块,乘以这些块,然后掩蔽对角线。这是非常高效的计算效率,因为它使用了来自
PyTorch的单个矩阵乘法运算,但它消耗的内存是一个完美优化的实现应该消耗的内存的2倍,因为它计算了一些零值。由于计算效率,这种实现最适合于预训练/微调的情况; - Longformer-cuda:使用TVM实现的自定义CUDA内核,它是我们注意力的一个功能齐全的实现(没有Longformer-chunks的限制),是记忆效率最高的,和高度优化的完全自我注意力一样快;由于内存效率(允许最长的序列)和扩展的支持,主要将此实现用于自回归语言建模实验;

上图是三种处理方式在Time和Memory上的对比;
2.3 自回归语言模型
注意力模式
在自回归语言模型中,我们使用膨胀滑动窗口注意力,并且在不同的层使用不同大小的size,一般来说,在较低的层使用较小的尺寸,较高的层使用较大的尺寸;这允许顶层学习整个序列的高级表示,而让较低的层捕获本地信息。此外,它还提供了效率(较小的窗口大小由于非零值更少而计算成本更低)和性能(较大的窗口大小具有更丰富的表示能力,并经常导致性能改进)之间的平衡;一般不能在底层使用膨胀滑动窗口注意力去学习和利用局部上下文,在高层时,也只用很少的两个头去实施膨胀滑动窗口注意,这使得模型能够在不牺牲本地上下文的情况下直接关注遥远的标记;
训练
理想情况下,我们可以直接使用GPU内存中可以容纳的最大窗口大小和序列长度来训练我们的模型。然而,我们发现,在学习使用更长的上下文之前,该模型需要大量的梯度更新来首先学习局部上下文。为了适应这一点,论文采用了一个阶段训练程序,在多个训练阶段增加注意窗口的大小和序列长度。在第一阶段,首先从一个较短的序列长度和窗口大小开始,然后在随后的每个阶段,我们将窗口大小和序列长度增加一倍,并将学习率减半。这使得训练更加快速,同时保持慢速部分(最长的序列和窗口大小)到最后。训练模型一共经历了5个阶段,起始序列长度为2048,结束序列长度为23040;
每个阶段的详细配置以及所有其他超参数如下:

结果
BPC:?bits-per-character,相当于困惑度PPL(Perplexity),区别在于BPC是字符层面而PPL可以是char也可以是word,BPC越小模型越好;
PPL的计算公式如下:
P
P
L
(
s
t
r
i
n
g
)
=
P
(
w
1
w
2
…
w
n
)
?
1
n
=
1
P
(
w
1
w
2
…
w
n
)
n
=
∏
i
=
1
n
1
P
(
w
i
∣
w
1
w
2
…
w
i
?
1
)
n
PPL(string)=P(w_1w_2\dots w_n)^{-\frac{1}{n}}=\sqrt[n]{\frac{1}{P(w_1w_2\dots w_n)}}=\sqrt[n]{\prod_{i=1}^{n}\frac{1}{P(w_i|w_1w_2\dots w_{i-1})}}
PPL(string)=P(w1?w2?…wn?)?n1?=nP(w1?w2?…wn?)1??=ni=1∏n?P(wi?∣w1?w2?…wi?1?)1??
BPC的计算公式如下:
B
P
C
(
s
t
r
i
n
g
)
=
1
T
∑
t
=
1
T
H
(
P
t
,
P
^
t
)
=
?
1
T
∑
t
=
1
T
∑
c
=
1
n
P
t
(
c
)
l
o
g
2
P
^
t
(
c
)
=
?
1
T
∑
t
=
1
T
l
o
g
2
P
^
t
(
x
t
)
=
l
o
g
2
(
P
P
L
)
BPC(string)=\frac{1}{T}\sum_{t=1}^TH(P_t,\widehat P_t)=-\frac{1}{T}\sum_{t=1}^T\sum_{c=1}^nP_t(c)log_2\widehat P_t(c)=-\frac{1}{T}\sum_{t=1}^Tlog_2\widehat P_t(x_t)=log_2(PPL)
BPC(string)=T1?t=1∑T?H(Pt?,P
t?)=?T1?t=1∑T?c=1∑n?Pt?(c)log2?P
t?(c)=?T1?t=1∑T?log2?P
t?(xt?)=log2?(PPL)
我们用长度为32,256的序列进行评估,将数据集分成步长为512,大小为32,256的重叠序列,对每一个序列的最后512tokens进行评估,模型的表现如下:

小模型在两个数据集中达到了最优的效果,而大模型在参数量是其一半的情况下,差距不是特别大;

通过消融实验可以发现,w从32到512进行变化和在两个头使用膨胀滑动窗口可以有效的提升模型的性能;
2.4 预训练和微调
类似于BERT的预训练模型在许多NLP任务上表现非常出色,为了突破tokens的限制,这里利用Longformer在一个文档语料库上对其进行了预训练,并将其调整为6个任务,包括分类、QA和共指消解;这里共指消解表示的是识别一段文本中指向同一个实体(Entity)的不同表述(Mention)而提出的一项技术;得到的模型处理的token数量是基础BERT的6倍,能处理4096个tokens;
这里使用的是RoBERTa的预训练机制,模型不需要改变直接插入进行预训练;
注意力模式
我们使用窗口大小 w w w为512的滑动窗口注意,与RoBERTa的计算量相同;
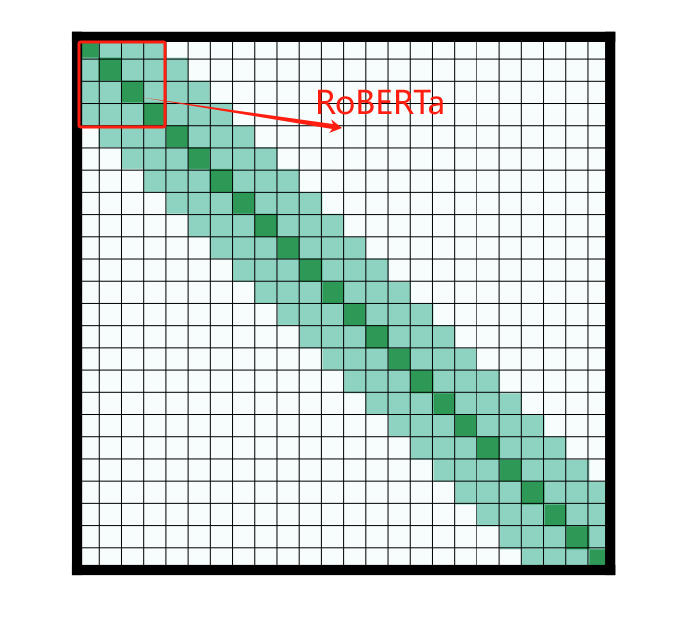
位置编码
使用的是和BERT一样的learned absolute position,直接像token embedding一样做一个position embedding,不过这里不是对token,而是对range采取embedding;
在这里,为了支持较长的文档,我们添加了额外的位置嵌入来支持4,096位的位置编码,利用RoBERTa的预先训练的权重,而不是随机初始化新位置嵌入,使用复制初始化,除了分区边界外,任何地方都保留这个结构。尽管它很简单,但这是一个非常有效的方法,允许Longformer预训练通过少量的梯度更新从而快速收敛;
预训练
和RoBERTa一样,Longformer也训练了两种不同尺寸的模型,且两种模型规模与RoBERTa一致,两种模型都进行了65K次梯度更新,序列长度为4096,批处理大小为64(
2
18
2^{18}
218个tokens),最大的学习率为3e-5,500步的linear warmup,3次多项式衰减,其余的超参数与RoBERTa相同;
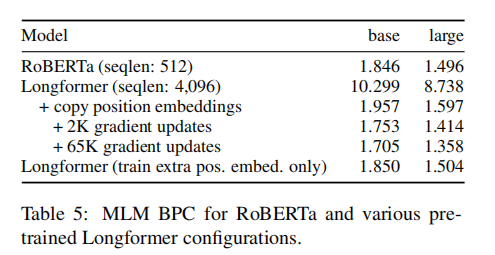
可以看到copy position embeddings可以显著的加快收敛;通过冻结RoBERTa的Weights去训练位置编码相较于直接复制BPC只降低了0.1左右,这也同样证明了copy position embeddings的必要性;
结果
通过三种任务上的训练结果,我们可以发现Longformer的效果是始终高于RoBERTa的,这说明Longformer在长序列文档上是一个优秀的替代;同时根据数据集上下文长度观察,提升幅度较小的往往都是上下文长度较小的数据集;


同时,论文还评估了Longformer-large在长上下文QA任务上的性能;
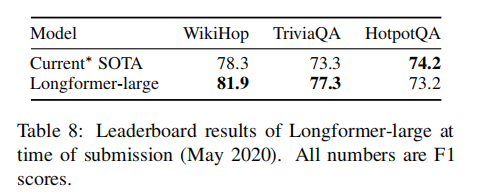
可以发现除了HotpotQA外,都取得了显著的提升,这里我们再来分析HotpotQA;

从图中可以得到,排在Longformer前面的模型为ETC,GSAN,HGN,这些模型都使用了GNNs或者实体图网络graph network of entities,这似乎能够为任务去编码一个重要的归纳偏差,并有可能进一步改善我们的结果;除此之外,Longformer优于所有的其他类型的方法;
最后我们进行消融实验分析:

所有的实验都使用了Longformer-base,除了声明以外的参数其他的保持一致,并且都微调了5 epochs,当使用Longformer(seqlen: 512, and
n
2
n^2
n2 attention)去对比RoBERTa时,可以发现效果要稍微差一点,说明其他模型效果的提高不是由于额外的预训练造成的;当使用RoBERTa模型的参数并只训练额外的位置嵌入时,性能略有下降,这表明Longformer可以在大型训练数据集如WikiHop的微调中获取远程上下文;
2.5 Longformer-Encoder-Decoder (LED)
普通的transformer模型是一个encoder-decoder架构,用于seq2seq任务,例如总结或者翻译;虽然说只包含encoder的模型在许多的NLP任务上非常有效,但是完整的encoder-decoder在seq2seq上更加有效;
LED架构是通过local+global attention的encoder和full self-attention的decoder构成的;由于对LED的预训练过于昂贵,使用BART来初始化LED的参数,并在层数和隐藏层大小上保持相同的结构,唯一的区别是处理更长的序列,BART是1k tokens,这里是16k tokens;采用类似于对RoBERTa操作,使用复制和重复BART位置嵌入矩阵的方式,初始化了新的位置嵌入矩阵,一共复制了16次,LED分为base和large,base是6层 ,large是12层;
模型结果如下所示:
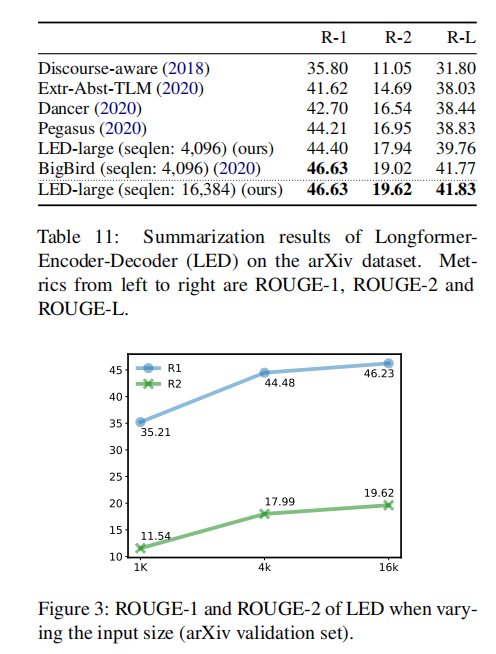
可以发现LED在arXiv上取得了SOTA,同时可以发现,序列长度越长,模型的结果越好,表明处理较长输入的能力显著提高了结果;
三、整体总结
论文中提出了三种模型,一种是类似于BERT,利用滑动窗口注意和全局注意处理长文本序列;一种类似于GPT,利用膨胀滑动窗口注意抓取上下文获取长文本序列;一种是 Longformer-Encoder-Decoder(LED),利用类似于BERT的机制做encoder,利用全注意力机制做decoder的seq2seq架构,在arXiv上超过了bigbird取得了SOTA
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!