C语言排序算法
排序的过程就是增加有序度,减少逆序度,最终达到满有序度
冒泡排序
#include <stdio.h>
#include <stdbool.h>
#define N 10
void swap(int arr[],int i,int j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
void bubble_sort(int arr[],int n) {
//i表示冒泡的次数
for(int i = 0;i < N;i++) {
bool isSorted = true;
for(int j = 0;j < N-i;j++) {
if(arr[j] > arr[j+1]) {//不能写成 >=
swap(arr,j,j+1);
isSorted = false;
}
}
if(isSorted) return ;
}
}
时间复杂度
最好情况:数组有序,O(n)
比较次数:n-1
交换次数:0
最坏情况:数组逆序,O(n^2)
比较次数:(n(n-1))/2
交换次数:(n(n-1))/2
稳定性:稳定
空间复杂度:O(1),原地排序
选择排序
表现稳定的排序算法之一,因为无论什么数据进去都是O(n^2)的时间复杂度,所以用到它的时候,数据规模越小越好。唯一的好处可能就是不占用额外的内存空间
#include <stdio.h>
void swap(int arr[],int i,int j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
void selection_sort(int arr[],int n) {
for(int i = 1;i < n;i++) {
int minIndex = i-1;
for(int j = 1;j < n;j++) {
//更新索引
if(arr[j] < arr[minIndex]) {
minIndex = j;
}
}
//交换i-1和minIndex所在位置的元素
swap(arr,i-1,minIndex);
}
}
时间复杂度
最好情况和最坏情况都是一样的,时间复杂度都是O(n)
比较次数:(n(n-1))/2
减缓次数:n-1
空间复杂度:O(1)
稳定性:不稳定(发生长距离交换)
插入排序
工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。插入排序在从后向前扫描过程中,需要反复把已排序元素逐步向后挪位ui,未最新元素提供插入空间,故名插入排序。
#include <stdio.h>
//将原数组分为两部分,第一部分是有序部分,第二部分是无序部分,每次for循环,有序部分空间+1,无序部分空间-1,然后再让新增的元素在有序序列里面寻找自己插入的位置
void insertion_sort(int arr[],int n) {
// i 代表无序区的第一个元素
for(int i = 1;i < n;i++) {
int val = arr[i];
int j = i-1;
while(j >= 0 && arr[j] > val) {
arr[j+1] = arr[j];
j--;
}
arr[]j+1] = val;
}
}
时间复杂度
最好情况:原数组有序,O(n)
比较次数:n-1
交换次数“:0
最坏情况:原数组逆序,O(n^2)
比较次数:(n(n-1))/2
交换次数:(n(n-1))/2
当元素基本 有序时,性能非常好
空间复杂度:O(1),原地排序
稳定性:稳定
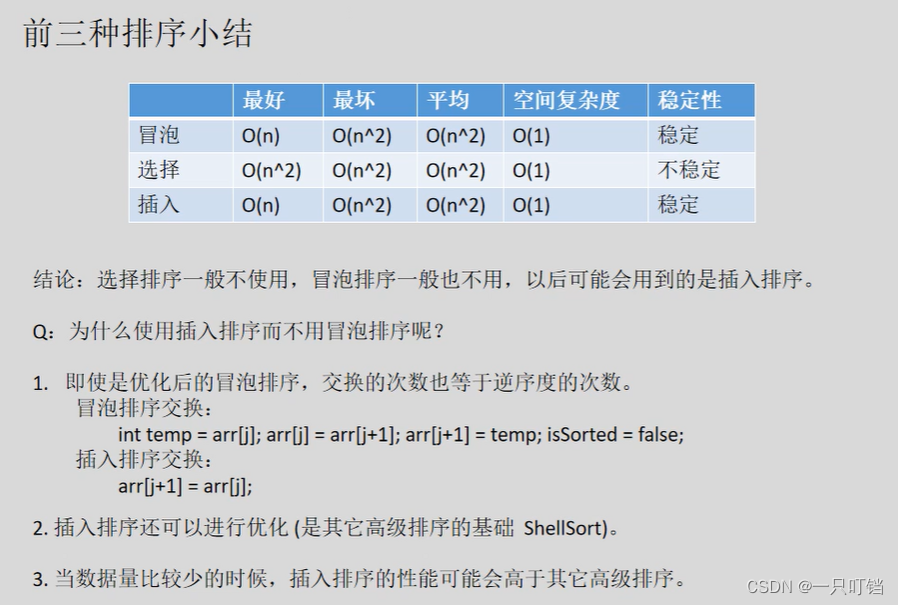
希尔排序
希尔排序又叫做缩小增量排序,是插入排序的改进版本,他是唯一打破时间复杂度O(n)的排序算法
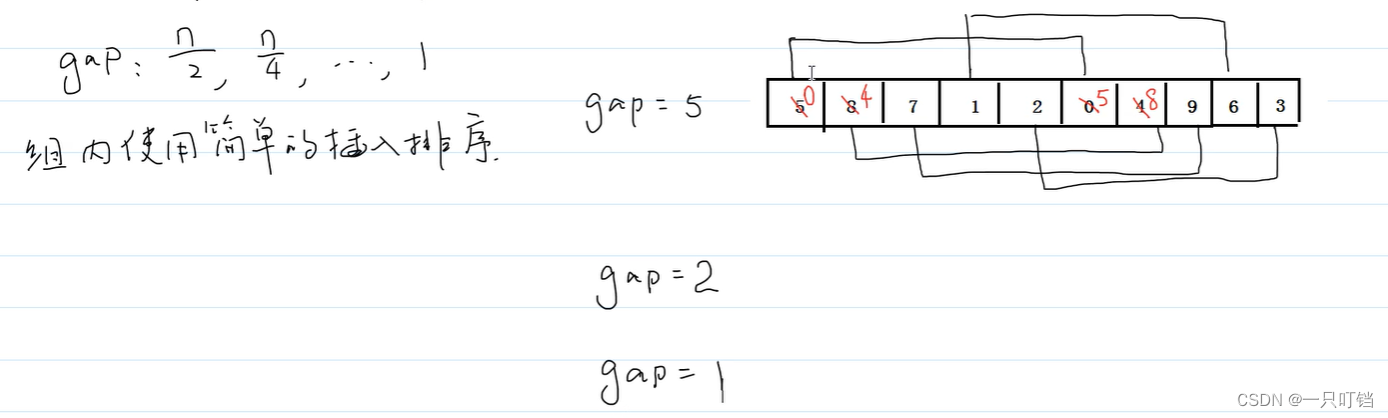
分组之后使用插入排序对每个分组进行排序
#include <stdio.h>
void shell_sort(int arr[],int n) {
int gap = n/2;
while(gap != 0) {
//组内插入排序
for(int i = gap;i < n;i++) {
int val = arr[i];
int j = i - gap;
while( j >= 0 && arr[j] > val) {
arr[j+gap] = arr[j];
j -= gap;
}
}
// 缩小增量
gap /= 2;
}
}
时间复杂度:比O(n^2)小,和具体的gap序列相关
空间复杂度:O(1),原地排序
稳定性:不稳定(会发生长距离交换)
归并排序
归并排序基于分治思想,将数组拆分未元素更小的数组排序,排完序再合并小数组的结果
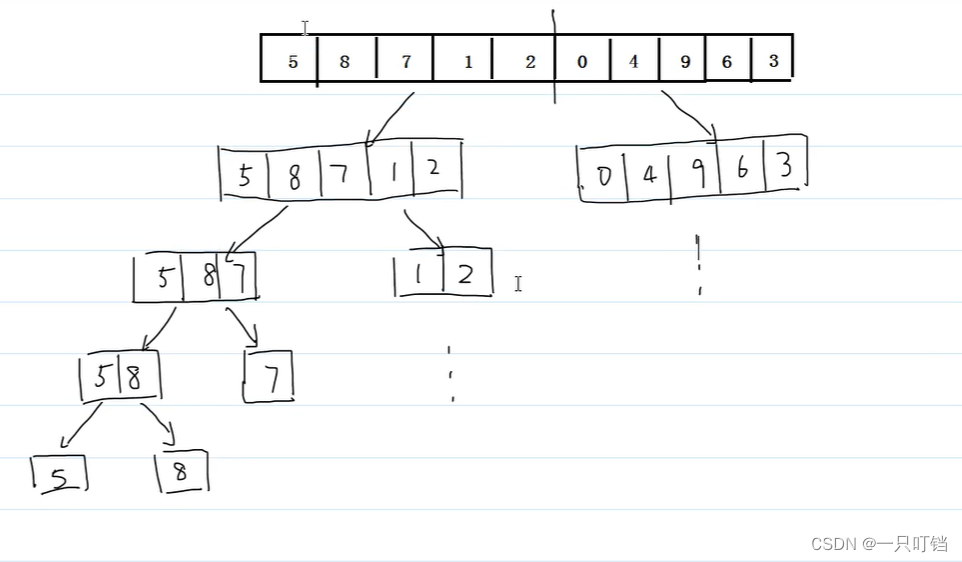
#include <stdio.h>
#include <stdlib.h>
void merfe_sort(int arr[],int n) {
merge_sort1(arr, 0, n - 1);
}
void merge_sort1(int arr[],int left,int right) {
//边界条件
if(left >= right) return ;
int mid = left + ((right - left) >> 1);
//对左半区间排序
merge_sort1(arr,left,mid);
//对右半区间排序
merge_sort1(arr,mid + 1,right);
//合并两个区间
mergr(arr, left, mid, right)
}
void merge(int arr[],int left,int mid,int right) {
int len = right - left + 1 ;
int* temp = (int*)malloc((right - left + 1)*sizeof(int));
if(temp == NULL) {
printf("Error:malloc failed in merge.\n");
exit(1);
}
int i = left,j = mid + 1, k = 0;
while(i <= mid && j <= right) {
if(arr[i] <= arr[j]) {//如果写成 < 就变成不稳定的了
temp[k++] = arr[i++];
}else {
temp[k++] = arr[j++];
}
}
while(i <= mid) {
temp[k++] = arr[i++];
}
while(j <= right) {
temp[k++] = arr[j++];
}
//复制数据回原数组
for(int i = 0;i < len;i++) {
arr[left + i] = temp[i];
}
//释放
free(temp);
}
时间复杂度:O(n^logbn)
空间复杂度:O(n)
稳定性:稳定
快速排序
快速排序可能是引用最广泛的派苏算法,快速排序流行多的原因是因为它实现简单,适用于各种不同的输入数据且在一般应用中比其他排序算法都要快很多,快速排序也是基于分治的思想。
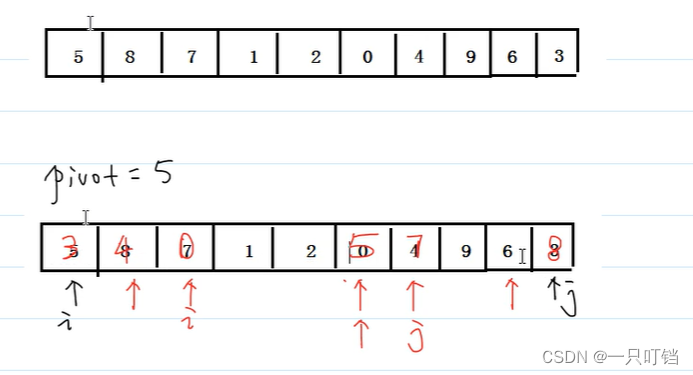
快速排序的步骤:
(1)选取基本值(pivot),一般选取第一个数据未基准值
(2)分区(partition),将所有比基准值小的数移动到基本值的左边,把所有比基准值大的数移动到基准值的右边
(3)对左边区间进行快速排序,对右边区间进行快速排序
#include <stdio.h>
void quick_sort(int arr[],int n) {
quick_sort1(arr, 0, n - 1);
}
void quick_sort1(int arr[], int left, int right) {
//边界条件
if(left >= right) return ;
// idx 为基准值
int idx = partition(arr, left, right);
quick_sort1(arr, left, idx - 1);
quick_sort1(arr,idx + 1, right);
}
int partition(int arr[], int left, int right) {
int pivot = arr[left];
int i = left, j = right;
while(i < j) {
while(i < j && arr[j >= pivot]) {
j--;
}
arr[i] = arr[j];
while(i < j && arr[i] <= pivot) {
i++
}
arr[j] = arr[i];
}
arr[i] = pivot;
return i;
}
时间复杂度
最好情况:每次分区都分成大希奥相等的两份,O(nlogn)
最坏情况:每次基准值都位于最左边或者最右边,O(n^2)
空间复杂度:O(logn),递归的深度
稳定性:不稳定
改进策略:
(1)基准值的选取:随机选择,选择多个元素的中位数作为基准值
(2)分区操作优化,
(3)选择多个基准值
堆排序
二叉堆:
(1)大顶堆,根结点的键大于左右子树所有结点的键,并且左右子树都是大顶堆;
(2)小顶堆,根结点的键小于左右子树所有结点的键,并且左右子树都是小顶堆
堆排算法步骤:
(1)构大顶堆,找到第一个非叶子结点,从后往前构建大顶堆
(2)把堆顶元素和无序区的最后一个元素交换,无序区的长度减一
(3)把无序区重新调整成大顶堆
(4)重复(2)、(3)的操作,知道无序区的长度为0
#include <stdio.h>
void heap_sort(int arr[],int n){
// 构建大顶堆
build_heap(arr,n);
// 无序区的长度
int len = n;
while(len > 1) {
swap(arr, 0, len - 1);
len--;
// 把无序区重新调整成大顶堆
heapify(arr, 0, len);
}
}
void build_heap(int arr[],int n) {
for(int i = (n-2)/2;i >= 0;i--) {
heapify(arr, i, n);
}
}
void heapify(int arr[],int i,int len) {
// i 表示可能违反大顶堆规则检点的索引,len表示大顶堆包含元素的个数
int leftChild = 2 * i + 1;
int rightChild = 2 * i + 2;
int maxIdx = i;
if(leftChild < len && arr[leftChild] > arr[maxIdx]) {
maxIdx = leftChid;
}
if(rightChild < len && arr[rightChild] > arr[maxIdx]) {
maxIdx = rightChild;
}
if(maxIdx == i) {
break;
}
swap(arr,i,maxIdx);
i = maxIdx;
}
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!