2、共识、线性一致性与顺序一致性
etcd 是线性一致性读,而 zk 却是顺序一致性读,再加上各种共识、强弱一致的名词,看的时候总会混淆,这篇文档就列举下分布式系统中的那些"一致性名词",引用了很多其他的文章,不过会多出一些例子来帮助理解。
什么是一致性
consensus
consensus准确的翻译是共识,即多个提议者达成共识的过程,例如Paxos,Raft 就是共识算法,paxos 是一种共识理论,分布式系统是他的场景,一致性是他的目标。
一些常见的误解:使用了 Raft或者 paxos 的系统都是线性一致的(Linearizability 即强一致),其实不然,共识算法只能提供基础,要实现线性一致还需要在算法之上做出更多的努力。
因为分布式系统引入了多个节点,节点规模越大,宕机、网络时延、网络分区就会成为常态,任何一个问题都可能导致节点之间的数据不一致,因此Paxos 和 Raft 准确来讲是用来解决一致性问题的共识算法,用于分布式场景,而非”缓存一致性“这种单机场景。所以很多文章也就简称”Paxos是分布式系统中的一致性算法“,
一致性(Consistency)的含义比共识(consensus)要宽泛,一致性指的是多个副本对外呈现的状态。包括顺序一致性、线性一致性、最终一致性等。而共识特指达成一致的过程,但注意,共识并不意味着实现了一致性,一些情况下他是做不到的。
Paxos与Raft
这里提一下Paxos,Paxos 其实是一类协议,Paxos 中包含 Basic Paxos、Multi-Paxos、Cheap Paxos 和其他的变种。Raft 就是 Multi-Paxos 的一个变种,Raft 通过简化 Multi-Paxos 的模型,实现了一种更容易让人理解和工程实现的共识算法,
Paxos是第一个被证明完备的共识算法,能够让分布式网络中的节点在出现错误时仍然保持一致,当然前提是没有恶意节点,也就是拜占庭将军问题。在传统的分布式系统领域是不需要担心这种问题的,因为不论是分布式数据库、消息队列、分布式存储,你的机器都不会故意发送错误信息,最常见的问题反而是节点失去响应,所以它们在这种前提下,Paxos是足够用的。
顺序一致性(Sequential Consistency)
虽然强度上 线性一致性 > 顺序一致性,但因为顺序一致性出现的时间比较早(1979年),线性是在顺序的基础上的加强(1990 年)。因此先介绍下顺序一致性
顺序一致性也算强一致性的一种,他的原理比较晦涩,论文看这里
举例说明1:下面的图满足了顺序一致,但不满足线性一致。
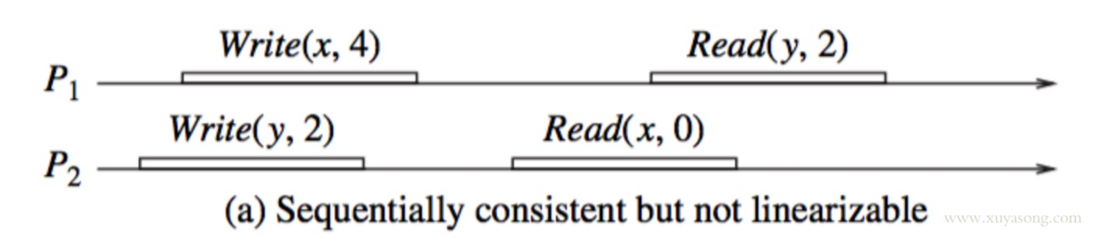
- x 和 y 的初始值为 0
- Write(x,4)代表写入 x=4,Read(y,2)为读取 y =2
从图上看,进程P1,P2的一致性并没有冲突。因为从这两个进程的角度来看,顺序应该是这样的:
Write(y,2), Read(x,0), Write(x,4), Read(y,2)
这个顺序对于两个进程内部的读写顺序都是合理的,只是这个顺序与全局时钟下看到的顺序并不一样。在全局时钟的观点来看,P2进程对变量X的读操作在P1进程对变量X的写操作之后,然而P2读出来的却是旧的数据0
举例说明 2:
假设我们有个分布式 KV 系统,以下是四个进程对其的操作顺序和结果:
–表示持续的时间,因为一次写入或者读取,客户端从发起到响应是有时间的,发起早的客户端,不一定拿到数据就早,有可能因为网络延迟反而会更晚。
情况 1:
A: --W(x,1)----------------------
B: --W(x,2)----------------------
C: -R(x,1)- --R(x,2)-
D: -R(x,1)- --R(x,2)--
情况 2:
A: --W(x,1)----------------------
B: --W(x,2)----------------------
C: -R(x,2)- --R(x,1)-
D: -R(x,2)- --R(x,1)--
上面情况 1 和 2 都是满足顺序一致性的,C 和 D 拿的顺序都是 1-2,或 2-1,只要CD 的顺序一致,就是满足顺序一致性。只是从全局看来,情况 1 更真实,情况 2 就显得”错误“了,因为情况2 是这样的顺序
B W(x,2) -> A W(x,1) -> C R(x,2) -> D R(x,2) -> C R(x,1) -> D R(x,1)
不过一致性不保证正确性,所以这仍然是一个顺序一致。再加一种情况 3:
情况 3:
A: --W(x,1)----------------------
B: --W(x,2)----------------------
C: -R(x,2)- --R(x,1)-
D: -R(x,1)- --R(x,2)--
情况 3 就不属于顺序一致了,因为C 和 D 两个进程的读取顺序不同了。
回到情况 2,C 和 D 拿数据发起的时间是不同的,且有重叠,有可能 C 拿到 1 的时候,D 已经拿到了 2,这就导致了不同的客户端在相同的时间获取了不一样的数据,但其实这种模式在现实中的用的挺广泛的:
ZooKeeper
一种说法是 ZooKeeper 是最终一致性,因为由于多副本、以及保证大多数成功的 Zab 协议,当一个客户端进程写入一个新值,另外一个客户端进程不能保证马上就能读到这个值,但是能保证最终能读取到这个值。
另外一种说法是 ZooKeeper 的 Zab 协议类似于 Paxos 协议,提供了强一致性。
但这两种说法都不准确,ZooKeeper文档中明确写明它的一致性是 Sequential consistency即顺序一致。
ZooKeeper中针对同一个Follower A提交的写请求request1、request2,某些Follower虽然可能不能在请求提交成功后立即看到(也就是强一致性),但经过自身与Leader之间的同步后,这些Follower在看到这两个请求时,一定是先看到request1,然后再看到request2,两个请求之间不会乱序,即顺序一致性
其实,实现上ZooKeeper 的一致性更复杂一些,ZooKeeper 的读操作是 sequential consistency 的,ZooKeeper 的写操作是 linearizability 的,关于这个说法,ZooKeeper 的官方文档中没有写出来,但是在社区的邮件组有详细的讨论。ZooKeeper 的论文《Modular Composition of Coordination Services》 中也有提到这个观点。
总结一下,可以这么理解 ZooKeeper:从整体(read 操作 +write 操作)上来说是 sequential consistency,写操作实现了 Linearizability。
线性一致性 (Linearizability)
线性一致性又被称为强一致性、严格一致性、原子一致性。是程序能实现的最高的一致性模型,也是分布式系统用户最期望的一致性。CAP 中的 C 一般就指它
顺序一致性中进程只关心大家认同的顺序一样就行,不需要与全局时钟一致,线性就更严格,从这种偏序(partial order)要达到全序(total order)
要求是:
- 1.任何一次读都能读到某个数据的最近一次写的数据。
- 2.系统中的所有进程,看到的操作顺序,都与全局时钟下的顺序一致。
以上面的例 3 继续讨论:
B1 看到 x 的新值,C1 反而看到的是旧值。即对用户来说,x 的值发生了回跳。
在线性一致的系统中,如果 B1 看到的 x 值为1,则 C1 看到的值也一定为1。任何操作在该系统生效的时刻都对应时间轴上的一个点。如果我们把这些时刻连接起来,如下图中紫线所示,则这条线会一直沿时间轴向前,不会反向回跳。所以任何操作都需要互相比较决定,谁发生在前,谁发生在后。例如 B1 发生在 A0 前,C1 发生在 A0 后。而在前面顺序一致性模型中,我们无法比较诸如 B1 和 A0 的先后关系。
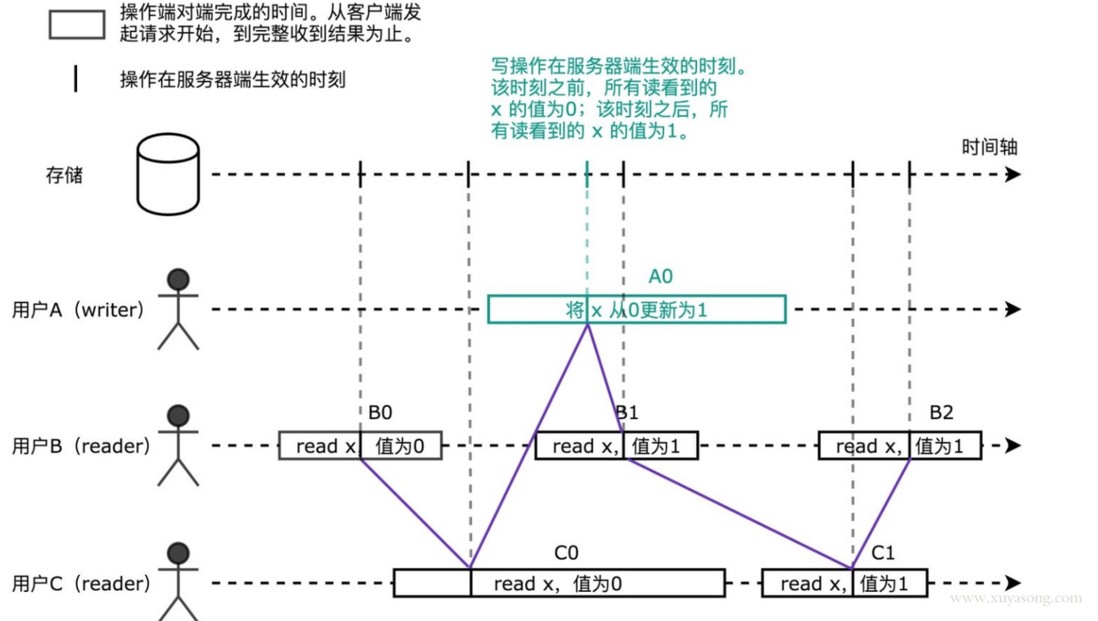
线性一致性的理论在软件有哪些体现呢?
etcd 与 raft
上面提到ZooKeeper的写是线性一致性,读是顺序一致性。而 etcd读写都做了线性一致,即 etcd 是标准的强一致性保证。
etcd是基于raft来实现的,raft是共识算法,虽然共识和一致性的关系很微妙,经常一起讨论,但共识算法只是提供基础,要实现线性一致还需要在算法之上做出更多的努力如库封装,代码实现等。如raft中对于一致性读给出了两种方案,来保证处理这次读请求的一定是 Leader:
- ReadIndex
- LeaseRead
基于 raft 的软件有很多,如 etcd、tidb、SOFAJRaft等,这些软件在实现一致读时都是基于这两种方式。
关于 etcd 的选主架构这里不做描述,可以看这篇文章,这里对ReadIndex和Lease Read做下解释,即etcd 中线性一致性读的具体实现
由于在 Raft 算法中,写操作成功仅仅意味着日志达成了一致(已经落盘),而并不能确保当前状态机也已经 apply 了日志。状态机 apply 日志的行为在大多数 Raft 算法的实现中都是异步的,所以此时读取状态机并不能准确反应数据的状态,很可能会读到过期数据。
基于以上这个原因,要想实现线性一致性读,一个较为简单通用的策略就是:每次读操作的时候记录此时集群的 commited index,当状态机的 apply index 大于或等于 commited index 时才读取数据并返回。由于此时状态机已经把读请求发起时的已提交日志进行了 apply 动作,所以此时状态机的状态就可以反应读请求发起时的状态,符合线性一致性读的要求。这便是 ReadIndex 算法。
那如何准确获取集群的 commited index ?如果获取到的 committed index 不准确,那么以不准确的 committed index 为基准的 ReadIndex 算法将可能拿到过期数据。
为了确保 committed index 的准确,我们需要:
- 让 leader 来处理读请求;
- 如果 follower 收到读请求,将请求 forward 给 leader;
- 确保当前 leader 仍然是 leader;
leader 会发起一次广播请求,如果还能收到大多数节点的应答,则说明此时 leader 还是 leader。这点非常关键,如果没有这个环节,leader 有可能因网络分区等原因已不再是 leader,如果读请求依然由过期的 leader 处理,那么就将有可能读到过去的数据。
这样,我们从 leader 获取到的 commited index 就作为此次读请求的 ReadIndex。
以网络分区为例:
? 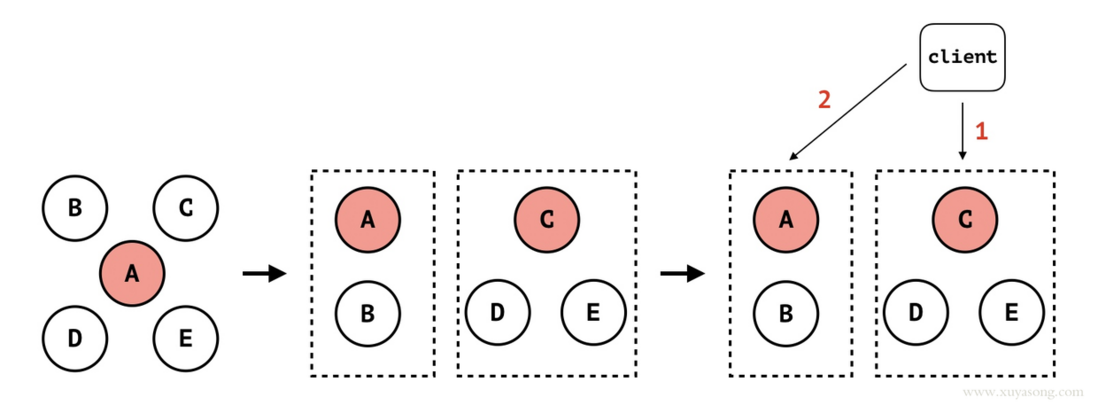
如上图所示:
- 初始状态时集群有 5 个节点:A、B、C、D 和 E,其中 A 是 leader;
- 发生网络隔离,集群被分割成两部分,一个 A 和 B,另外一个是 C、D 和 E。虽然 A 会持续向其他几个节点发送 heartbeat,但由于网络隔离,C、D 和 E 将无法接收到 A 的 heartbeat。默认地,A 不处理向 follower 节点发送 heartbeat 失败(此处为网络超时)的情况(协议没有明确说明 heartbeat 是一个必须收到 follower ack 的双向过程);
- C、D 和 E 组成的分区在经过一定时间没有收到 leader 的 heartbeat 后,触发 election timeout,此时 C 成为 leader。此时,原来的 5 节点集群因网络分区分割成两个集群:小集群 A 和 B,A 为 leader;大集群 C、D 和 E,C 为 leader;
- 此时有客户端进行读写操作。在 Raft 算法中,客户端无法感知集群的 leader 变化(更无法感知服务端有网络隔离的事件发生)。客户端在向集群发起读写请求时,一般是从集群的节点中随机挑选一个进行访问。如果客户端一开始选择 C 节点,并成功写入数据(C 节点集群已经 commit 操作日志),然后因客户端某些原因(比如断线重连),选择节点 A 进行读操作。由于 A 并不知道另外 3 个节点已经组成当前集群的大多数并写入了新的数据,所以节点 A 无法返回准确的数据。此时客户端将读到过期数据。不过相应地,如果此时客户端向节点 A 发起写操作,那么写操作将失败,因为 A 因网络隔离无法收到大多数节点的写入响应;
- 针对上述情况,其实节点 C、D 和 E 组成的新集群才是当前 5 节点集群中的大多数,读写操作应该发生在这个集群中而不是原来的小集群(节点 A 和 B)。如果此时节点 A 能感知它已经不再是集群的 leader,那么节点 A 将不再处理读写请求。于是,我们可以在 leader 处理读请求时,发起一次 check quorum 环节:leader 向集群的所有节点发起广播,如果还能收到大多数节点的响应,处理读请求。当 leader 还能收到集群大多数节点的响应,说明 leader 还是当前集群的有效 leader,拥有当前集群完整的数据。否则,读请求失败,将迫使客户端重新选择新的节点进行读写操作。
这样一来,Raft 算法就可以保障 CAP 中的 C 和 P,但无法保障 A:网络分区时并不是所有节点都可响应请求,少数节点的分区将无法进行服务,从而不符合 Availability。因此,Raft 算法是 CP 类型的一致性算法。
Raft保证读请求Linearizability的方法:
- Leader把每次读请求作为一条日志记录,以日志复制的形式提交,并应用到状态机后,读取状态机中的数据返回。(一次RTT、一次磁盘写)
- 使用Leader Lease,保证整个集群只有一个Leader,Leader接收到都请求后,记录下当前的commitIndex为readIndex,当applyIndex大于等于readIndex 后,则可以读取状态机中的数据返回。(0次RTT、0次磁盘写)
- 不使用Leader Lease,而是当Leader通过以下两点来保证整个集群中只有其一个正常工作的Leader:(1)在每个Term开始时,由于新选出的Leader可能不知道上一个Term的commitIndex,所以需要先在当前新的Term提交一条空操作的日志;(2)Leader每次接到读请求后,向多数节点发送心跳确认自己的Leader身份。之后的读流程与Leader Lease的做法相同。(一次RTT、0次磁盘写)
- 从Follower节点读:Follower先向Leader询问readIndex,Leader收到Follower的请求后依然要通过2或3中的方法确认自己Leader的身份,然后返回当前的commitIndex作为readIndex,Follower拿到readIndex后,等待本地的applyIndex大于等于readIndex后,即可读取状态机中的数据返回。(2次或1次RTT、0次磁盘写)
Linearizability 和 Serializability
Serializability是数据库领域的概念,而Linearizability是分布式系统、并发编程领域的东西,在这个分布式SQL时代,自然Linearizability和Serializability会经常一起出现。
- Serializability: 数据库领域的ACID中的I。 数据库的四种隔离级别,由弱到强分别是Read Uncommitted,Read Committed(RC),Repeatable Read(RR)和Serializable。
Serializable的含义是:对并发事务包含的操作进行调度后的结果和某种把这些事务一个接一个的执行之后的结果一样。最简单的一种调度实现就是真的把所有的事务进行排队,一个个的执行,显然这满足Serializability,问题就是性能。可以看出Serializability是与数据库事务相关的一个概念,一个事务包含多个读,写操作,这些操作由涉及到多个数据对象。
- Linearizability: 针对单个操作,单个数据对象而说的。属于CAP中C这个范畴。一个数据被更新后,能够立马被后续的读操作读到。
- Strict Serializability: 同时满足Serializability和Linearizability。
举个最简单的例子:两个事务T1,T2,T1先开始,更新数据对象o,T1提交。接着T2开始,读数据对象o,提交。以下两种调度:
- T1,T2,满足Serializability,也满足Linearizability。
- T2,T1,满足Serializability,不满足Linearizability,因为T1之前更新的数据T2读不到。
最终一致性 Eventual consistency
最终一致性这个词大家听到的次数应该是最多的,也是弱一致性,不过因为大多数场景下用户可以接受,应用也就比较广泛。
理念:不保证在任意时刻任意节点上的同一份数据都是相同的,但是随着时间的迁移,不同节点上的同一份数据总是在向趋同的方向变化。
简单说,就是在一段时间后,节点间的数据会最终达到一致状态。不过最终一致性的要求非常低,除了像gossip这样明确以最终一致性为卖点的协议外,包括redis主备、mongoDB、乃至mysql热备都可以算是最终一致性,甚至如果我记录操作日志,然后在副本故障了100天之后手动在副本上执行日志以达成一致,也算是符合最终一致性的定义。有人说最终一致性就是没有一致性,因为没人可以知道什么时候算是最终。
上边提到的因果一致性可以理解为是最终一致性的变种, 如果进程 A 通知进程 B 它已经更新了一个数据项,那么进程 B 的后续访问将返回更新后的值,并且写操作将被保证取代前一次写入。和进程 A 没有因果关系的 C 的访问将遵循正常的最终一致性规则。
最终一致其实分支很多,以下都是他的变种:
- Causal consistency(因果一致性)
- Read-your-writes consistency (读己所写一致性)
- Session consistency (会话一致性)
- Monotonic read consistency (单调读一致性)
- Monotonic write consistency (单调写一致性)
后面要提到的 BASE理论中的 E,就是Eventual consistency最终一致
ACID理论
ACID 是处理事务的原则,一般特指数据库的一致性约束,ACID 一致性完全与数据库规则相关,包括约束,级联,触发器等。在事务开始之前和事务结束以后,都必须遵守这些不变量,保证数据库的完整性不被破坏,因此 ACID 中的 C 表示数据库执行事务前后状态的一致性,防止非法事务导致数据库被破坏。比如银行系统 A 和 B 两个账户的余额总和为 100,那么无论 A, B 之间怎么转换,这个余额和是不变,前后一致的。
这里的C代表的一致性:事务必须遵循数据库的已定义规则和约束,例如约束,级联和触发器。因此,任何写入数据库的数据都必须有效,并且完成的任何事务都会改变数据库的状态。没有事务可以创建无效的数据状态。注意,这与CAP定理中定义的“一致性”是不同的。
ACID 可以翻译为酸,相对应的是碱,也就是 BASE,不过提BASE之前要先说下 CAP,毕竟 BASE是基于 CAP 提出的折中理论
CAP理论
CAP 理论中的 C 也就是我们常说的分布式系统中的一致性,更确切地说,指的是分布式一致性中的一种: 也就是前面讲的线性一致性(Linearizability),也叫做原子一致性(Atomic consistency)。
CAP 理论也是个被滥用的词汇,关于 CAP 的正确定义可参考cap faq。很多时候我们会用 CAP 模型去评估一个分布式系统,但这篇文章会告诉你 CAP 理论的局限性,因为按照 CAP 理论,很多系统包括 MongoDB,ZooKeeper 既不满足一致性(线性一致性),也不满足可用性(任意一个工作中的节点都要可以处理请求),但这并不意味着它们不是优秀的系统,而是 CAP 定理本身的局限性(没有考虑处理延迟,容错等)。
BASE理论
正因为 CAP 中的一致性和可用性是强一致性和高可用,后来又有人基于 CAP 理论 提出了BASE 理论,即基本可用(Basically Available)、软状态(Soft State)、最终一致性(Eventual Consistency)。BASE的核心思想是即使无法做到强一致性,但每个应用都可以根据自身的业务特点,采用适当的方法来使系统达到最终一致性。显然,最终一致性弱于 CAP 中的 线性一致性。很多分布式系统都是基于 BASE 中的”基本可用”和”最终一致性”来实现的,比如 MySQL/PostgreSQL Replication 异步复制。
ACID一致性与CAP一致性的区别
ACID一致性是有关数据库规则,如果数据表结构定义一个字段值是唯一的,那么一致性系统将解决所有操作中导致这个字段值非唯一性的情况,如果带有一个外键的一行记录被删除,那么其外键相关记录也应该被删除,这就是ACID一致性的意思。
CAP理论的一致性是保证同样一个数据在所有不同服务器上的拷贝都是相同的,这是一种逻辑保证,而不是物理,因为光速限制,在不同服务器上这种复制是需要时间的,集群通过阻止客户端查看不同节点上还未同步的数据维持逻辑视图。
当跨分布式系统提供ACID时,这两个概念会混淆在一起,Google’s Spanner system能够提供分布式系统的ACID,其包含ACID+CAP设计,也就是两阶段提交 2PC+ 多副本同步机制(如 Paxos)
ACID/2PC/3PC/TCC/Paxos 关系
ACID 是处理事务的原则,限定了原子性、一致性、隔离性、持久性。ACID、CAP、BASE这些都只是理论,只是在实现时的目标或者折中,ACID 专注于分布式事务,CAP 和 BASE是分布式通用理论。
解决分布式事务时有 2pc、3pc、tcc 等方式,通过增加协调者来进行协商,里面也有最终一致的思想。
CID+CAP设计,也就是两阶段提交 2PC+ 多副本同步机制(如 Paxos)
ACID/2PC/3PC/TCC/Paxos 关系
ACID 是处理事务的原则,限定了原子性、一致性、隔离性、持久性。ACID、CAP、BASE这些都只是理论,只是在实现时的目标或者折中,ACID 专注于分布式事务,CAP 和 BASE是分布式通用理论。
解决分布式事务时有 2pc、3pc、tcc 等方式,通过增加协调者来进行协商,里面也有最终一致的思想。
而Paxos协议与分布式事务并不是同一层面的东西,Paxos用于解决多个副本之间的一致性问题。比如日志同步,保证各个节点的日志一致性,选主的唯一性。简而言之,2PC用于保证多个数据分片上事务的原子性,Paxos协议用于保证同一个数据分片在多个副本的一致性,所以两者可以是互补的关系,不是替代关系。对于2PC协调者单点问题,可以利用Paxos协议解决,当协调者出问题时,选一个新的协调者继续提供服务。原理上Paxos和 2PC相似,但目的上是不同的。etcd 中也有事务的操作,比如迷你事务
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!