Redis设计与实现之跳跃表
目录
三、跳跃表和其他数据结构(如数组、链表等)相比有什么优点和缺点?
八、Redis的跳跃表和其他数据库(如MySQL、MongoDB等)的索引结构有何不同?
一、跳跃表
跳跃表(skiplist)是一种随机化的数据,由 William Pugh 在论文《Skip lists: a probabilistic alternative to balanced trees》中提出,这种数据结构以有序的方式在层次化的链表中保存元 素,它的效率可以和平衡树媲美——查找、删除、添加等操作都可以在对数期望时间下完成, 并且比起平衡树来说,跳跃表的实现要简单直观得多。
以下是一个典型的跳跃表例子:
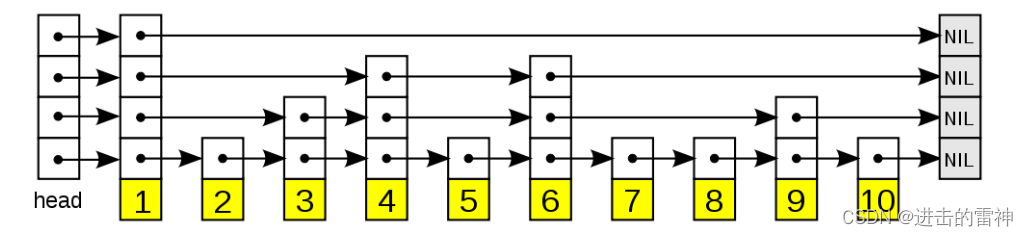
从图中可以看到,跳跃表主要由以下部分构成:?
?表头( head) :负责维护跳跃表的节点指针。
?跳跃表节点:保存着元素值,以及多个层。
?层:保存着指向其他元素的指针。高层的指针越过的元素数量大于等于低层的指针,为了提高查找的效率,程序总是从高层先开始访问,然后随着元素值范围的缩小,慢慢降低层次。
?表尾:全部由 NULL组成,表示跳跃表的末尾。
因为跳跃表的定义可以在任何一本算法或数据结构的书中找到,所以本章不介绍跳跃表的具体
实现方式或者具体的算法,而只介绍跳跃表在 Redis的应用、核心数据结构和 API。
1、跳跃表的实现
为了适应自身的功能需要, Redis基于 William Pugh 论文中描述的跳跃表进行了以下修改:
1.允许重复的 score值:多个不同的 member的score值可以相同。
2.进行对比操作时,不仅要检查 score值,还要检查 member:当score值可以重复时,单靠score值无法判断一个元素的身份,所以需要连 member域都一并检查才行。
3.每个节点都带有一个高度为 1层的后退指针,用于从表尾方向向表头方向迭代:当执行ZREVRANGE 或 ZREVRANGEBYSCORE 这类以逆序处理有序集的命令时,就会用到这个属性。
这个修改版的跳跃表由 redis.h/zskiplist 结构定义:
typedef structzskiplist {
//头节点,尾节点
structzskiplistNode *header, *tail;
//节点数量
unsigned longlength;
//目前表内节点的最大层数
intlevel;
} zskiplist;跳跃表的节点由 redis.h/zskiplistNode 定义:
typedef structzskiplistNode {
// member 对象
robj*obj;
//分值
doublescore;
//后退指针
structzskiplistNode *backward;
//层
structzskiplistLevel {
//前进指针
structzskiplistNode *forward;
//这个层跨越的节点数量
unsigned intspan;
} level[];
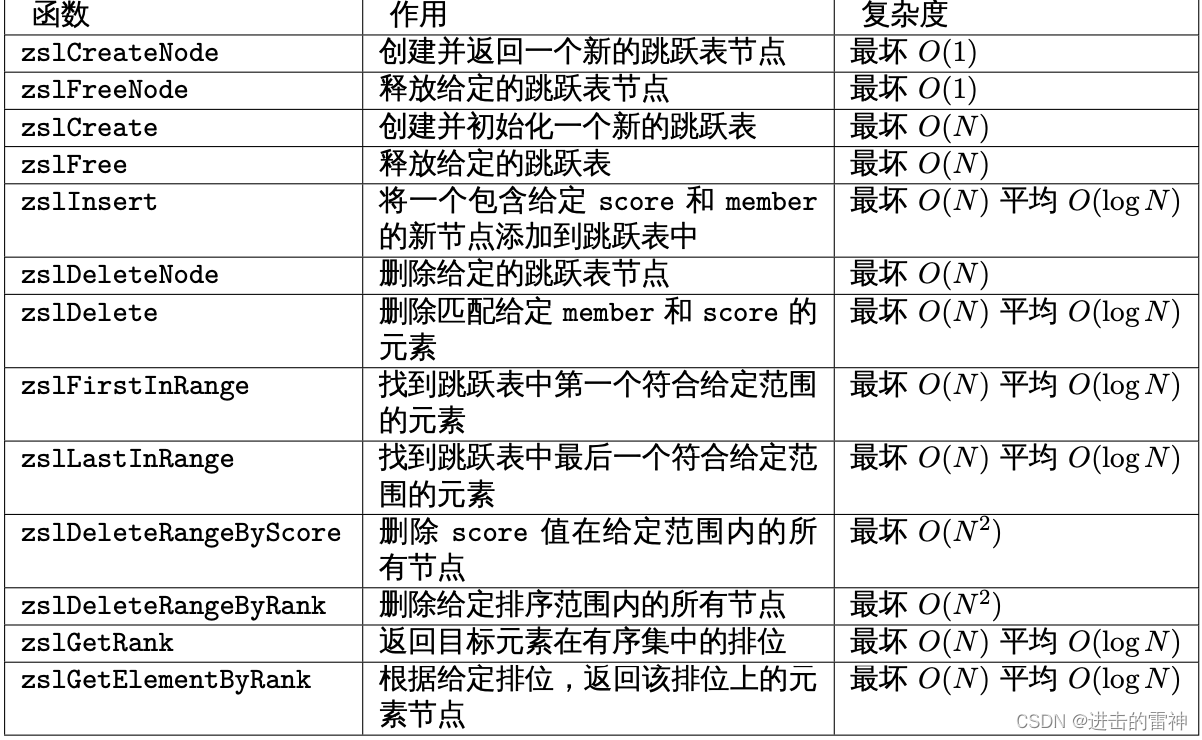
} zskiplistNode;以下是操作这两个数据结构的 API,它们的作用以及相应的算法复杂度:
2、跳跃表的应用
和字典、链表或者字符串这几种在 Redis中大量使用的数据结构不同,跳跃表在 Redis的唯一作用,就是实现有序集数据类型。
跳跃表将指向有序集的 score值和member域的指针作为元素,并以 score值为索引,对有序集元素进行排序。
举个例子,以下代码就创建了一个带有 3个元素的有序集:
redis>ZADD s6x10y15z
(integer) 3
redis>ZRANGE s 0-1WITHSCORES
1)"x"
2)"6"
3)"y"
4)"10"
5)"z"
6)"15"在底层实现中, Redis为x、y和z三个member分别创建了三个字符串,并为 6、10和15分别创建三个 double类型的值,然后用一个跳跃表将这些指针有序地保存起来,形成这样一个跳跃表:
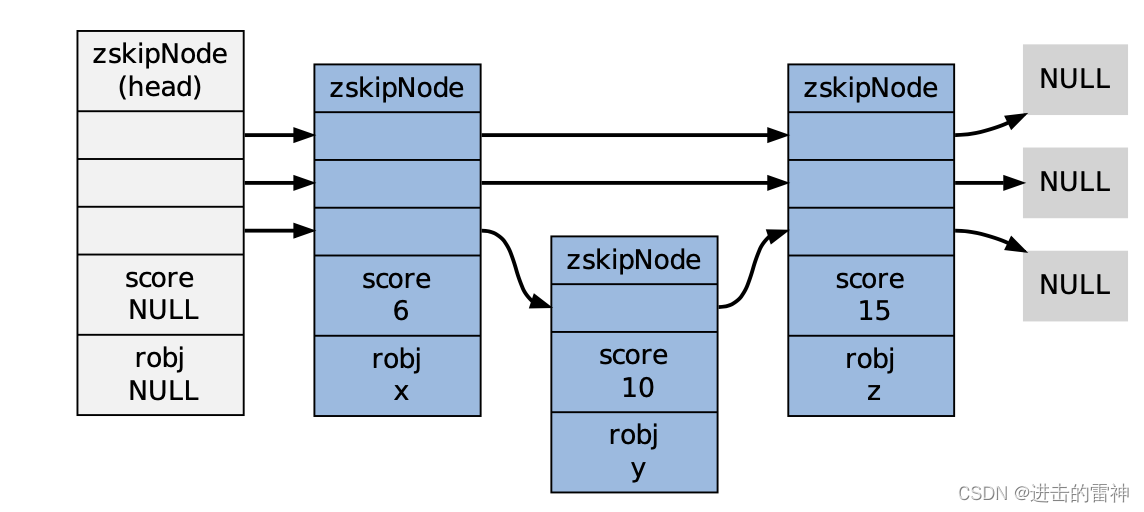
为了展示的方便,在图片中我们直接将 member和score值包含在表节点中,但是在实际的定义中,因为跳跃表要和另一个实现有序集的结构(字典)分享 member和score值,所以跳跃表只保存指向 member和score的指针。
3、跳跃表的时间复杂度是什么?
跳跃表(Skip List)是一种数据结构,用于实现有序的集合数据。对于搜索、插入和删除操作,跳跃表的时间复杂度为O(log n),其中n是跳跃表中元素的数量。这是因为跳跃表通过层级索引的方式加速搜索的速度,使得每次搜索都能减少一半的搜索范围,从而使得时间复杂度保持在O(log n)。
二、跳跃表有哪些应用场景?
Redis跳跃表(Skip List)是一种有序数据结构,它通过使用多级索引来加快对元素的查找速度。它在Redis中的应用场景有:
-
有序集合:Redis的有序集合数据类型就是使用跳跃表来实现的。跳跃表能够保持集合元素的有序性,并且支持高效地插入、删除和查找操作。
-
排行榜:跳跃表可以用于实现排行榜功能,可以根据某个指标对用户进行排名,并且支持快速的插入和删除操作。
-
范围查询:跳跃表可以快速地查找某个范围内的元素,例如在一个有序集合中查找某个分数范围内的成员。
-
分数计算:跳跃表可以用于对成绩、评分等进行计算和排名。在Redis中,有序集合的元素可以关联一个分数,可以通过跳跃表来快速进行分数计算和排名。
-
事件排序:跳跃表可以用于对时间事件进行排序和管理,例如定时任务管理器、事件调度器等。
总的来说,Redis跳跃表适用于需要高效地进行元素排序、查找和范围查询的场景。它的优势在于简单、高效,适用于有序集合等需要有序性的场景。
三、跳跃表和其他数据结构(如数组、链表等)相比有什么优点和缺点?
Redis跳跃表相对于其他数据结构(如数组、链表等)具有以下优点和缺点:
优点:
- 快速查找:跳跃表通过索引层级的方式实现了快速查找,其时间复杂度为O(logn),比数组和链表的线性查找效率更高。
- 低延迟:由于跳跃表的查找和插入操作的时间复杂度都是O(logn),不随数据量的增长而增加,因此能够保持低延迟的性能。
- 支持有序集合:跳跃表能够自然有序地存储数据,因此非常适合实现有序集合等需要有序存储的数据结构。
- 空间效率高:跳跃表的索引层级结构为每个节点增加了额外的空间开销,但相对于数组和链表来说,其空间利用率更高,可以节省存储空间。
缺点:
- 复杂实现:相对于数组和链表等简单的数据结构来说,跳跃表的实现较为复杂,需要维护索引层级结构,并且需要考虑各节点之间的维护和调整操作。
- 内存占用:跳跃表的索引层级结构需要额外的空间来存储索引节点,因此会占用较多的内存空间。
- 不适合频繁的插入和删除操作:跳跃表的插入和删除操作需要对索引层级进行调整和维护,对于频繁进行这些操作的场景来说,性能可能较差。
四、Redis的跳跃表支持并发操作吗?如何保证并发安全?
Redis的跳跃表(Skip List)本身并不支持并发操作,因为跳跃表的插入、删除和查找操作都需要涉及到修改指针的过程,这样会存在并发安全问题。
为了保证并发安全性,Redis使用了一种叫做"多个跳跃表"的数据结构来实现有序集合(Sorted Set)。在每个有序集合中,Redis维护了一个正常的有序跳跃表,同时还维护了一个用于支持并发的层级跳跃表。
-
正常的有序跳跃表:用于执行读操作,每个线程可以拥有自己的迭代器去遍历跳跃表。
-
层级跳跃表:用于执行写操作,避免并发写入过程中对同一个节点进行修改。在更新节点时,首先会在层级跳跃表上进行更新,然后再更新到正常的有序跳跃表上。
通过这种方式,Redis实现了有序集合的并发操作,保证了并发安全性。
五、跳跃表的大小和内存占用是如何计算的?
Redis跳跃表(Skip List)是一种有序数据结构,用于实现有序集合键(Sorted Set Key)。跳跃表通过将数据分层,从而实现快速查找、插入和删除操作。
Redis跳跃表的大小取决于其中存储的键值对数量。每个节点包含一个或多个层级,每个层级维护了指向下一层级的指针。节点的数量和层级的大小都会影响跳跃表的大小。具体而言,跳跃表的大小可以通过以下公式计算:
Size = N * (entry size) + M * (pointer size)
其中,N表示跳跃表中的节点数量,entry size表示每个节点的键值对大小,M表示指针的数量,pointer size表示每个指针的大小。
跳跃表的内存占用主要取决于两个因素:节点数量和层级大小。节点数量较多会占用更多内存,而层级大小决定了每个节点的指针数量。因为指针通常比键值对更小,所以较大的层级大小可以节省内存。然而,较大的层级大小也会增加跳跃表的高度,可能增加查找操作的时间复杂度。
需要注意的是,Redis在使用跳跃表之前会使用普通的链表实现有序集合键。当数据量较小时,Redis会使用链表,当数据量超过一定阈值时,才会转换为跳跃表。因此,实际内存占用可能受到数据量和跳跃表与链表使用比例的影响。
六、Redis的跳跃表有没有限制元素数量的上限?
Redis的跳跃表(Skip List)没有固定的元素数量上限限制。每个跳跃表节点都可以包含多个元素,而每个节点的高度也是动态调整的,因此跳跃表可以根据需要动态地增长和缩小。跳跃表的高度可以通过调整概率来控制,从而控制跳跃表的大小。因此,Redis的跳跃表可以容纳非常大数量的元素。
七、跳跃表的迭代器是如何实现的?
Redis中的跳跃表(skiplist)是一种有序的数据结构,它通过多级索引来加速查询操作的效率。跳跃表的迭代器用于遍历跳跃表中的元素。
跳跃表的迭代器是通过指针和索引操作实现的。迭代器是一个可迭代对象,它在每次调用next()方法时返回下一个元素。迭代器可以在跳跃表中向前或向后遍历元素。
具体实现步骤如下:
- 创建一个迭代器对象,并初始化为跳跃表的头节点(或尾节点)。
- 在迭代器对象中,有一个指针指向当前节点。通过这个指针,可以访问当前节点的元素和索引。
- 通过指针和索引操作,可以实现在跳跃表中向前或向后遍历。例如,通过指针可以直接访问当前节点的下一个节点,从而实现向前或向后遍历。
- 在每次调用next()方法时,迭代器将返回当前节点的元素,并将指针指向下一个节点。
- 如果跳跃表中没有下一个节点,则迭代器将返回结束标记,表示遍历已经完成。
需要注意的是,当跳跃表中的元素被删除或添加时,迭代器可能会失效。为了保证迭代器的正确性,可以使用版本号或者加锁机制。
总而言之,Redis中的跳跃表迭代器通过指针和索引操作来遍历跳跃表中的元素,可以向前或向后遍历,并在每次调用next()方法时返回当前节点的元素。
八、Redis的跳跃表和其他数据库(如MySQL、MongoDB等)的索引结构有何不同?
Redis的跳跃表(skiplist)是一种有序数据结构,用于实现有序集合(Sorted Set)的索引。它通过多层级的有序链表来快速查找元素,具有类似于平衡二叉树的效率。
与其他数据库的索引结构相比,Redis的跳跃表有以下特点:
-
简单高效:跳跃表的实现相对简单,插入、删除和查找操作的时间复杂度都是O(log N),并且具有较低的常数系数。相比之下,其他数据库的索引结构如B树或哈希索引的复杂性更高。
-
内存友好:跳跃表存储在内存中,不需要进行磁盘读写操作,因此具有更低的延迟和更高的吞吐量。而其他数据库的索引结构如B树则需要频繁地读写磁盘。
-
有序性:跳跃表可以保持元素的有序性,并支持范围查询操作,如获取区间内的元素。
相比之下,其他数据库的索引结构如B树或哈希索引可能不具备这些特点。例如,B树需要进行平衡操作以维持树的平衡性,而哈希索引则无法提供范围查询操作。因此,Redis的跳跃表在某些场景下可以更加高效和灵活地满足需求。
九、小结
?跳跃表是一种随机化数据结构,它的查找、添加、删除操作都可以在对数期望时间下完成。
?跳跃表目前在 Redis的唯一作用就是作为有序集类型的底层数据结构(之一,另一个构
成有序集的结构是字典) 。
?为了适应自身的需求, Redis基于 William Pugh 论文中描述的跳跃表进行了修改,包括:
1.score值可重复。
2.对比一个元素需要同时检查它的 score和memeber 。
3.每个节点带有高度为 1层的后退指针,用于从表尾方向向表头方向迭代。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!