学习笔记10——Mysql的DDL语句
2023-12-13 05:44:20
学习笔记系列开头惯例发布一些寻亲消息
链接:https://baobeihuijia.com/bbhj/contents/3/197161.html

-
数据库创建:
CREATE DATABASE books; CREATE DATABASE IF NOT EXISTS books; -
更改字符集
ALTER DATABASE books CHARACTER SET gbk; -
库的删除
DROP DATABASE IF EXISTS books; -
表的创建
CREATE TABLE book( id INT, bName VARCHAR(20), price DOUBLE, authorId INT, publishDate DATETIME ); -
表的修改
# 改列名改列属性 ALTER TABLE book CHANGE COLUMN publishdate pubDate DATETIME; # 改列属性 ALTER TABLE book MODIFY COLUMN pubDate TIMESTAMP; # 改表名字 ALTER TABLE book RENAME TO books; ALTER TABLE book ADD COLUMN pubDate TIMESTAMP 【first/after 字段名】; ALTER TABLE book DROP COLUMN pubDate; -
表的删除
DROP TABLE IF EXISTS book; -
表的复制
# 仅仅复制表的结构 CREATE TABLE author_copy LIKE author; # 复制表的结构+数据 CREATE TABLE author_copy2 SELECT * FROM author; # 仅仅复制某些字段 CREATE TABLE copy4 SELECT id,an_name FROM author WHERE 0; # 可以跨库,只要写成 库名.表名 CREATE TABLE dept2 SELECT department_id, department_name from my_employees.departments; -
常见数据类型
# 整型 Tinyint/Smallint/Mediumint/Int/integer/bigint # 默认为有符号,大于范围则插入临界值 CREATE TABLE tab_int( t1 INT, t2 INT UNSIGNED # 长度不够7用0来填充 t3 INT(7) ZEROFILL ); # 浮点小数 :MD都可以省略,随着插入的数据改变 float(M,D):M代表整数+小数部分长度,D代表小数部分长度 double(M,D) # 定点小数 :MD都可以省略,M默认为10,D默认为0,精度更高 dec(M,D) # 短的字符型 char 不可变长,可以省略默认为1 不可超过最大字符数 效率高 varchar 可变 不可超过最大字符数 效率低 # ENUM:枚举,只能选择列表中一个插入 e1 enum('a','b','c'); # set :选择列表中一个或者多个插入 s1 set('a','b','c','d') # binary和varbinary 保存较短的二进制 # 长的字符型 text,blob(长的二进制) # 日期 date 1001-01-01 time 22:22:22 year 1001 datetime:1001-01-01 00:00:00,只插入年份会自动给时间 timestamp:和datetime表示一样,但是会受当前的时区影响,更能反映真实时间 INSERT INTO tab_date VALUES (NOW(),NOW()); -
常见约束
列级约束 - NOT NULL - DEFAULT:保证字段有默认值 - PRIMARY KEY:主键,唯一且非空 - UNIQUE:唯一但是可以为空 CREATE TABLE stuinfo1( id INT PRIMARY KEY, stuName VARCHAR(20) NOT NULL, gender CHAR(1) CHECK(gender='男' OR gender ='女'), age INT DEFAULT 18, majorId INT, seat INT UNIQUE ); 表级约束 - CHECK:mysql没效果 - PRIMARY KEY:主键,唯一且非空 - UNIQUE:唯一但是可以为空 - FOREIGN KEY:外键,该表格的该字段值来自于主表的关联列的值 CREATE TABLE stuinfo1( id INT , stuName VARCHAR(20) , gender CHAR(1) , age INT , majorId INT, CONSTRAINT pk PRIMARY KEY(id), CONSTRAINT uq UNIQUE(seat), CONSTRAINT fk_stuinfo_major FOREIGN KEY(majorid) REFERENCES major(id) # 或者不起名 PRIMARY KEY(id), UNIQUE(seat), FOREIGN KEY(majorid) REFERENCES major(id) ); -
主键和唯一的区别
-
外键:
- 关联列必须是主键/唯一键
- 插入数据时,先插入主表再插入从表,删除的时候先删除从表再删主表
-
修改约束
# 主键的增删只需要一次,不需要每次motify都带着 # 列级约束 ALTER TABLE stuinfo1 MODIFY COLUMN id INT PRIMARY KEY; ALTER TABLE stuinfo1 MODIFY COLUMN stuName VARCHAR(10) NOT NULL; # 表级约束 ALTER TABLE stuinfo1 ADD PRIMARY KEY(seat); # 必须先存在再添加 ALTER TABLE stuinfo1 ADD UNIQUE(seat); # 必须先存在再添加 ALTER TABLE stuinfo1 ADD FOREIGN KEY (majorId) REFERENCES major(id); ALTER TABLE stuinfo1 ADD CONSTRAINT fk_stuinfo_major FOREIGN KEY (majorId) REFERENCES major(id); -
删除约束
ALTER TABLE stuinfo1 MODIFY COLUMN id INT; # 删除主键和唯一键的名字(主键起名也没有效果),列级约束无法删除主键 ALTER TABLE stuinfo1 DROP PRIMARY KEY; ALTER TABLE stuinfo1 DROP INDEX seat; # 删除外键 ALTER TABLE stuinfo1 DROP FOREIGN KEY fk_stuinfo_major; -
标识列
# 只有key才能设置标识列、只有有一个、只能是数值类型的 CREATE TABLE tab_identify( id INT PRIMARY KEY AUTO_INCREMENT, NAME VATCHAR(20) ); # 无需手动增加 INSERT INTO tab_identify values(NULL,'JOIN'); # 所有库都会被修改 SHOW VARIABLES LIKE '%auto_increment%'; SET auto_increment_increment = 3; # 起始位置可以手动插入 # 增删标识列 ALTER TABLE tab MOTIFY COLUMN id INT PRIMARY KRY AUTO_INCREMENT; ALTER TABLE tab MOTIFY COLUMN id INT; -
事务
要么全部执行、要么全部不执行 # 四大特性:原子性、一致性、隔离性、持久性 # 需要设置自动提交功能为OFF,只有当前事务设置有效 set autocommit = 0; start transaction; 仅限 sql语句不包含DDL语句 commit/rollback; 二选一,上述sql只是提交到了内存中,如果要执行那么就commit,如果不执行那就rollback - 脏读:没有提交 - 不可重复读:更新 - 幻读:插入 # 查看隔离级别 select @@tx_isolation set session|global transaction isolation level read committed; # 四种隔离级别 read uncommitted:事务尚未提交,库中的数据就已经修改了,当事务rollback的时候,这些临时修改且被读到的数据成为脏数据 read committed:可以避免脏读(未提交就不会修改),但是该事务commit前后,另一个事务的读取不可重复 repeatable_read:不管另一个事务是否提交,读到什么就一直是什么,避免不可重复读;但是另一个事务插入行之后,数据还是会变多 serializable:串行化,另一个事务的修改都会被阻塞 # 设置保存点 SAVEPOINT a; ROLLBACK TO a; -
视图
# 只保存了sql语句,没有保存真实的数据 - 简化sql,不必了解查询细节 - 保护数据,提高安全性 # 创建 CREATE VIEW avg_salary AS SELECT AVG(salary),department_id FROM employees GROUP BY department_id; # 使用 SELECT * FROM avg_salary; # 修改1 CREATE OR REPLACE VIEW myv3 AS SELECT AVG(salary),job_id FROM employees GROUP BY job_id; # 修改2 ALTER VIEW myv3 AS SELECT AVG(salary),job_id FROM employees GROUP BY job_id; # 删除 DROP VIEW myv3; # 修改,原始表也会修改(要看视图定义方式,有的可以更新有的不能) INSERT INTO myv3 VALUES('张飞','qq,com'); UPDATE myv3 SET NAME='吴京' WHERE email = 'qq,com'; DELETE FROM myv3 WHERE email = 'qq,com'; -
删除带外键的主表的方式
- 级联删除,主表内容删除会把从表内容删除 ALTER TABLE stuinfo ADD CONSTRAINT fk_stu_major FOREIGN KEY(majorid) REFERENCES major(id) ON DELETE CASCADE; - 级联置空 ALTER TABLE stuinfo ADD CONSTRAINT fk_stu_major FOREIGN KEY(majorid) REFERENCES major(id) ON DELETE SET NULL; -
系统变量
系统变量:系统提供,属于服务器层面 - 全局变量服务器每次启动会将全局变量赋初始值,针对所有会话有效,重启无效 SHOW GLOBAL【SESSION】 VARIABLES; SHOW GLOBAL【SESSION】 VARIBLIES LIKE '%char%'; SELECT @@global|session.系统变量名 SET global|session.系统变量名 = VALUE; SET @@global|session.系统变量名 = VALUE; SELECT @@global.tx_isolation; SET @@global.autocommit = 0; - 会话变量:仅针对当前会话有效,换一个连接就无效了 SHOW SESSION VARIABLES; SELECT @@SESSION.transaction_isolation; SELECT @@SESSION.transaction_isolation = read uncommitted; -
自定义变量
- 用户变量:仅当前会话有用,要加@,不需要限定类型 SET @用户变量名:=值; SELECT 字段 INTO @变量名 FROM 表; SELECT COUNT(*) INTO @count FROM emplyees; # 使用 SELECT @count; - 局部变量:作用于begin end中的第一句话,一般不用加@,需要限定类型 声明: DECLARE 赋值:SET/SELECT 使用:SELECT SET @m = 1; SET @n = 2; SELECT @n: = 2;(加冒号) SET @sum= @m + @n; SELECT @sum; BEGIN DECLARE m INT DEFAULT 1; SET m = 2; SELECT @m = 3; SELECT m; END -
存储过程和函数
- 提高代码的重用 - 减少编译次数 - 减少了逐步与服务器的连接次数 # 创建 CREATE PROCEDURE 名字(参数) BEGIN 一组合法的SQL语句 END 参数模式 IN:参数可以作为输入 OUT:参数作为返回值 INOUT:既需要输入值,又可以返回值 #### IN DELIMITER $ CREATE PROCEDURE myp1(IN beautyName VARCHAR(20)) BEGIN SELECT bo.* FROM boys bo RIGHT JOIN beauty b ON b.boyfriend_id = bo.id WHERE b.name = beautyName; END $ CALL myp1('柳岩'); #### OUT DELIMITER $ CREATE PROCEDURE myp1(IN beautyName VARCHAR(20),OUT boyName VARCHAR(20),OUT userCP INT) BEGIN SELECT bo.boyName, bo.userCP INTO boyName, INTO userCP FROM boys bo RIGHT JOIN beauty b ON b.boyfriend_id = bo.id WHERE b.name = beautyName; END $ SET @boyName$ CALL myp1('小昭',@boyName)$ select @boyName; #### INOUT SET @a=3; SET @b=4; DELIMITER $ CREATE PROCEDURE myp1(INOUT a INT,INOUT b INT) BEGIN SET a = a*2; SET b = b*2; END $ CALL myp1(@a,@b)$ SELECT @a$ # 删除 DROP PROCEDURE myp1; # 查看 SHOW CREATE PROCEDURE myp1; # 一般无法修改存储过程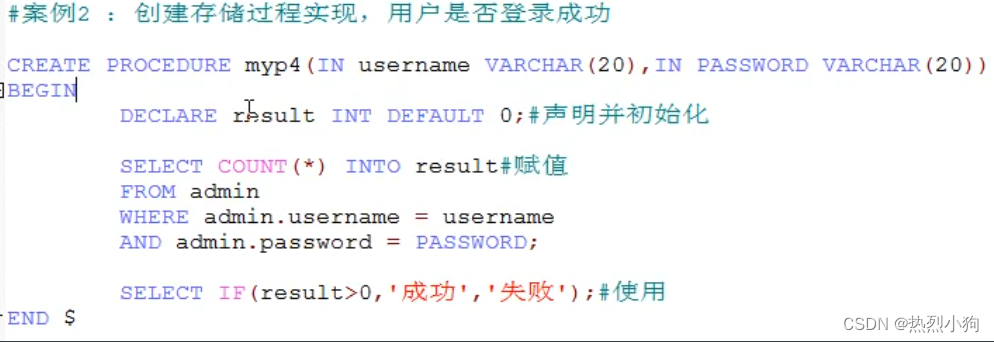
-
函数和存储过程的区别
- 存储过程可以0或多个返回、而函数必须有且仅有一个返回
# 无参 DELIMITER $ CREATE FUNCTION myf1() RETURNS INT BEGIN DECLARE c INT DEFAULT 0; SELECT COUNT(*) INTO c FROM employees; RETURN c; END $ SELECT myf1() $ # 有参 DELIMITER $ CREATE FUNCTION myf1(empName VARCHAR(20)) RETURNS DOUBLE BEGIN SET @SAL=0; SELECT salary INTO @SAL FROM employees WHERE first_name = empName; RETURN @SAL; END $ SELECT myf1('cynthia') $ # 实现两数相加 DELIMITER $ CREATE FUNCTION test_fun1(num1 FLOAT, num2 FLOAT) RETURNS FLOAT BEGIN DECLARE s FLOAT DEFAULT 0; SET s = num1 + num2; RETURN s; END $ SELECT test_fun1(2.3,1.7)$ # 查看函数 SHOW CREATE FUNCTION myf1; # 删除 DROP FUNCTION myf1; -
流程控制结构(顺序/分支/循环)
一、分支 - if函数:任何位置 IF(表达式1,表达式2,表达式3); - case:任何位置 DELIMITER $ CREATE PROCEDURE test(IN SCORE INT) BEGIN CASE WHEN score>=90 AND score <=100 THEN SELECT 'A'; WHEN score>=80 THEN SELECT 'B'; WHEN score>=60 THEN SELECT 'C'; ELSE SELECT 'D'; END CASE; END$ SELECT test(20)$ - if结构:只能放在begin end中 DELIMITER $ CREATE FUNCTION test(SCORE INT) RETURNS CHAR BEGIN IF score>=90 AND score <=100 THEN RETURN 'A'; ELSEIF score>=80 THEN RETURN 'B'; ELSEIF score>=60 THEN RETURN 'C'; ELSE RETURN 'D'; END IF; END$ SELECT test(20)$二、循环 while/loop/repeat,必须放在begin end之间 CREATE PROCEDURE pro_while(IN insertCount INT) BEGIN DECLARE i INT DEFAULT 1; WHILE i<=insertCount DO INSERT INTO boys VALUES(16,'zhangsan',200); SET i = i+1; END WHILE; END $ CALL pro_while(2); # 如果添加leave或者iterate,就必须添加名称 # 添加leave CREATE PROCEDURE pro_while(IN insertCount INT) BEGIN DECLARE i INT DEFAULT 1; a:WHILE i<=insertCount DO INSERT INTO boys VALUES(16,'zhangsan',200); SET i = i+1; IF i>=20 THEN LEAVE a; END IF; END WHILE a; END $ CALL pro_while(2)$ # 添加iterate CREATE PROCEDURE pro_while(IN insertCount INT) BEGIN DECLARE i INT DEFAULT 1; a:WHILE i<=insertCount DO IF MOD(i,2)!=0 THEN ITERATE a; END IF; INSERT INTO boys VALUES(16,'zhangsan',200); SET i = i+1; END WHILE a; END $ CALL pro_while(2)$
文章来源:https://blog.csdn.net/CZY925323/article/details/134945638
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!