使用 Python 解析电子表格数据
大型组织和企业通常将数据存储在电子表格中,并且需要一个界面来将这些数据输入其 Web 应用。一般的想法是上传文件,阅读其内容,并将其存储在网络应用程序使用的文件或数据库中。组织可能还需要从 Web 应用导出数据。例如,他们可能需要导出一个班级中所有学生的成绩。同样,电子表格是首选的介质。
在这篇文章中,我们将讨论处理这些文件的不同方法,并分析它们,以便使用 Python 获取所需的信息。
快速电子表格引号
在分析电子表格之前,您必须了解电子表格的结构。电子表格文件是表集的集合,每张表都是放置在网格中的数据单元集合,类似于表。在表中,数据单元由两个值标识:其行号和列号。
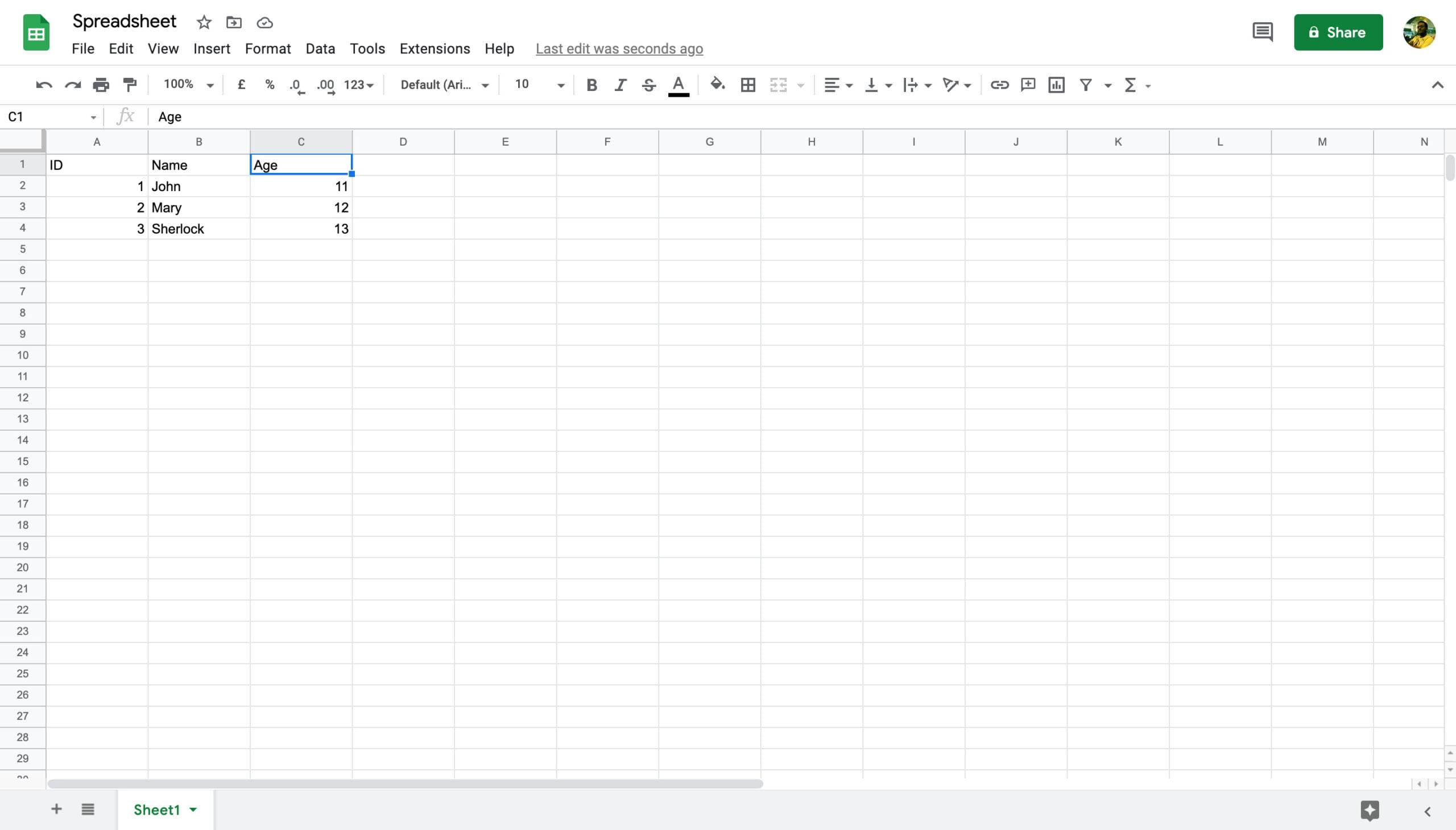
例如,在上面的屏幕截图中,电子表格仅包含一张"Sheet1"。单元格"2A"对应于第二行和 列。单元格2A值为1。
虽然带有GUI的程序会向列的名称分配字母,但当我们解析数据时,我们将从 0 开始行和列编号。这意味着,单元格 2A 将对应于 (1,0)、4B 到 (1,3)、3C 到 (2、2) 等。
建立 Python 环境
我们将使用Python 3读写电子表格。要读写 XLSX 文件,您需要安装熊猫模块。您可以通过 Python 安装程序之一:或 .熊猫使用openpyxl模块来读取新的电子表格 (.xlsx) 文件,xlrd模块用于读取旧电子表格 (.xls 文件)。当您安装熊猫时,这两者都是作为依赖项安装的:pipeasy_installopenpyxlxlrd
pip3 install pandas
要读取和编写CSV文件,您需要与 Python 预装的模块。您也可以通过熊猫阅读CSV文件。csv
阅读电子表格
如果您有一个文件,并且要解析其中的数据,则需要按以下顺序执行以下命令:
- 导入模块
pandas - 打开电子表格文件(或工作簿)
- 选择一张纸
- 提取特定数据单元的值
打开电子表格文件
让我们先在 Python 中打开一个文件。要遵循,您可以使用以下样本电子表格,由学习容器提供:
import pandas as pd
workbook = pd.read_excel('sample-xlsx-file-for-testing.xlsx')
workbook.head()
| 段 | 国家 | 产品 | 折扣带 | 已售出单位 | 制造价格 | 销售价格 | 销货总额 | 折扣 | 销售 | 齿轮 | 利润 | 日期 | 月号 | 月名称 | 年 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 政府 | 加拿大 | 卡雷泰拉 | 没有 | 1618.5 | 3 | 20 | 32370.0 | 0.0 | 32370.0 | 16185.0 | 16185.0 | 2014-01-01 | 1 | 一月 | 2014 |
| 1 | 政府 | 德国 | 卡雷泰拉 | 没有 | 1321.0 | 3 | 20 | 26420.0 | 0.0 | 26420.0 | 13210.0 | 13210.0 | 2014-01-01 | 1 | 一月 | 2014 |
| 2 | 中端市场 | 法国 | 卡雷泰拉 | 没有 | 2178.0 | 3 | 15 | 32670.0 | 0.0 | 32670.0 | 21780.0 | 10890.0 | 2014-06-01 | 6 | 六月 | 2014 |
| 3 | 中端市场 | 德国 | 卡雷泰拉 | 没有 | 888.0 | 3 | 15 | 13320.0 | 0.0 | 13320.0 | 8880.0 | 4440.0 | 2014-06-01 | 6 | 六月 | 2014 |
| 4 | 中端市场 | 墨西哥 | 卡雷泰拉 | 没有 | 2470.0 | 3 | 15 | 37050.0 | 0.0 | 37050.0 | 24700.0 | 12350.0 | 2014-06-01 | 6 | 六月 | 2014 |
熊猫将电子表格读成表格,并将其存储为熊猫数据框架。
如果您的文件具有非ASCII字符,则应以以下单码格式打开它:
import sys
workbook = pd.read_excel('sample-xlsx-file-for-testing.xlsx', encoding=sys.getfilesystemencoding())
如果您的电子表格非常大,则可以添加参数,该参数仅将某些列加载到数据帧中。例如,以下参数仅阅读前五列:use_cols
workbook = pd.read_excel('~/Desktop/import-export-data.xlsx', usecols = 'A:E')
workbook.head()
| 段 | 国家 | 产品 | 折扣带 | 已售出单位 | |
|---|---|---|---|---|---|
| 0 | 政府 | 加拿大 | 卡雷泰拉 | 没有 | 1618.5 |
| 1 | 政府 | 德国 | 卡雷泰拉 | 没有 | 1321.0 |
| 2 | 中端市场 | 法国 | 卡雷泰拉 | 没有 | 2178.0 |
| 3 | 中端市场 | 德国 | 卡雷泰拉 | 没有 | 888.0 |
| 4 | 中端市场 | 墨西哥 | 卡雷泰拉 | 没有 | 2470.0 |
此外,您可以使用和参数分别读取特定数量的行,或忽略开头的一定数量的行。nrowsskiprows
打开特定的表
您可以使用参数从电子表格中选择某张表。默认情况下,read_excel()函数解析文件中的 张纸。您可以提供表的名称作为字符串,或表的索引(从0开始):sheet_name
# Read the sheet with the name 'Sheet1'
worksheet = pd.read_excel('sample-xlsx-file-for-testing.xlsx', sheet_name = 'Sheet1')
# Read the 1st sheet in the file
worksheet = pd.read_excel('sample-xlsx-file-for-testing.xlsx', sheet_name = 0)
您还可以通过传递参数列表来选择一些要存储的表作为熊猫数据框架的听写:sheet_name
# Read the first two sheets and a sheet with the name 'Sheet 3'
worksheets = pd.read_excel('~/Desktop/import-export-data.xlsx', sheet_name = [0, 1, 'Sheet 3'])
从单元格获取数据
将工作表选入数据帧后,您可以通过查询到熊猫数据框架来提取特定数据单元的价值:
import pandas as pd
workbook = pd.read_excel('sample-xlsx-file-for-testing.xlsx')
# Print the 1st value of the Product column
print(workbook['Product'].iloc[0])
=> Carretera
.iloc()方法可帮助您根据索引位置搜索值。在上述代码中,在 0 索引位置搜索值。同样,您可以使用.loc()方法使用标签搜索值。例如,如果您将参数传递给该方法,它将在索引中搜索标签:.iloc()0.loc()0
print(workbook['Product'].loc[0])
=> Carretera
一旦数据集加载到具有熊猫内置功能的数据框架中,您可以查询其数据集。这里有一篇关于探索熊猫数据框架值的文章。
创建电子表格
创建工作表的工作流程与前一节类似。
- 导入模块
pandas - 将数据保存到工作簿中
- 在工作簿中创建一张纸
- 在工作簿中的单元格中添加造型
创建新文件
要创建新文件,我们首先需要一个数据框架。让我们从文章顶部重新创建演示表:
import pandas as pd
name = ['John', 'Mary', 'Sherlock']
age = [11, 12, 13]
df = pd.DataFrame({ 'Name': name, 'Age': age })
df.index.name = 'ID'
Then you can create a new spreadsheet file by calling the to_excel() function on the dataframe, specifying the name of the file it should save as:
df.to_excel('my_file.xlsx')
You can also open the same file using the function .read_excel()
添加纸张
您可以使用参数将数据框架保存为工作簿中的某个表。此参数的默认值是:sheet_nameSheet1
df.to_excel('my_file.xlsx', sheet_name = 'My Sheet')
在保存电子表格的同时提供更多选项
您可以使用ExcelWriter类获得更多选项,同时保存到电子表格。如果您想将多个数据框架保存到同一个文件,您可以使用以下语法:
import pandas as pd
workbook = pd.read_excel('my_file.xlsx')
# Creating a copy of workbook
workbook_2 = workbook.copy()
with pd.ExcelWriter('my_file_1.xlsx') as writer:
workbook.to_excel(writer, sheet_name='Sheet1')
workbook_2.to_excel(writer, sheet_name='Sheet2')
要将数据框架附加到现有电子表格中,请使用该参数。请注意,仅当您指定发动机为:modeopenpyxl
with pd.ExcelWriter('my_file_1.xlsx', engine="openpyxl", mode='a') as writer:
workbook_2.to_excel(writer, sheet_name='Sheet3'
此外,使用并设置日期和时间值的值:date_formatdatetime_format
with pd.ExcelWriter('my_file.xlsx',
date_format='YYYY-MM-DD',
datetime_format='YYYY-MM-DD HH:MM:SS') as writer:
workbook.to_excel(writer)
阅读旧版(.xls)电子表格
您可以使用熊猫中相同的语法阅读带有扩展的旧电子表格:.xls
workbook = pd.read_excel('my_file_name.xls')
虽然您使用了相同的功能,但熊猫会使用引擎来读取它。您可以使用与本教程中前面讨论的语法相同的语法读写旧电子表格。read_excel()xlrd
CSV 文件的快速摘要
CSV 代表"逗号分离值"(或者有时字符分离,如果使用的分界线是逗号以外的某个字符),并且名称是相当自我解释的。典型的CSV文件如下所列:
'ID', 'Name', 'Age'
'1', 'John', '11'
'2', 'Mary', '12'
'3', 'Sherlock', '13'
您可以将电子表格转换为CSV文件,以简化解析。除了熊猫之外,CSV 文件还可以使用 Python 中的模块轻松解析:csv
workbook = pd.read_csv('my_file_name.csv')
结论
正如我前面提到的,创建和分析电子表格是不可避免的,当你与巨大的网络应用程序工作。因此,熟悉分析库只有在需要时才能帮助您。
您使用什么脚本语言来处理电子表格?Python 是否有任何其他图书馆用于此目的,您更喜欢?随时在推特上打我。