从零开发短视频电商 JMH压测真实示例DEMO
文章目录
JMH 测试的对象可以是任一方法,颗粒度更小,例如本地方法,Rest Api,DB 连接等。
原理
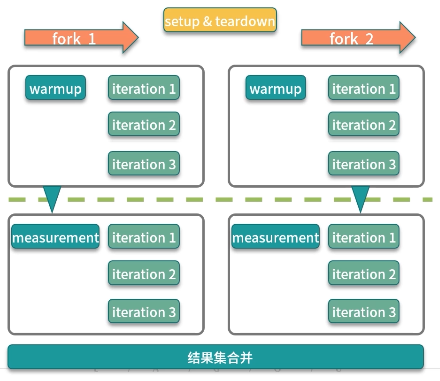
上面图来自 - https://juejin.cn/post/7031008727645831176
依赖
类似单元测试,常放在test目录下运行。
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-core</artifactId>
<version>1.33</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-generator-annprocess</artifactId>
<version>1.33</version>
<scope>test</scope>
</dependency>
基础示例
下面是用多线程测试一个Spring Bean的示例代码。
@BenchmarkMode(Mode.Throughput) // 设置基准测试的模式为吞吐量模式
@OutputTimeUnit(TimeUnit.SECONDS) // 设置输出时间单位为秒
@State(Scope.Benchmark) // 指定类的状态范围为基准测试,即embedService等全局变量为线程共享,注意线程安全问题
// 这里其实就是模拟spring的单例 bean
public class BenchmarkTest {
private TextEmbedServiceImpl embedService;
@Setup
public void setup() {
embedService = new TextEmbedServiceImpl(xxx); // 初始化TextEmbedServiceImpl实例
}
@Benchmark
@Warmup(iterations = 1, time = 1, timeUnit = TimeUnit.SECONDS) // 预热阶段设置,1次迭代,1秒时间
@Measurement(iterations = 3, time = 1, timeUnit = TimeUnit.SECONDS) // 测量阶段设置,3次迭代,1秒时间
// 即一共运行了4秒
@Threads(2) // 设置线程数为2
public void benchmarkEmbed(Blackhole blackhole) {
// 执行嵌入式方法的基准测试,使用Blackhole来防止JVM优化掉未使用的结果
Float[] result = embedService.embed("123123", ModelTypeEnum.BERT_EN_UNCASED);
blackhole.consume(result); // 防止编译器优化掉未使用的结果
}
public static void main(String[] args) throws Exception {
Options options = new OptionsBuilder()
.include(BenchmarkTest.class.getSimpleName()) // 指定要运行的基准测试类
.forks(1) // 设置forks数为1,即单进程运行
.build();
new Runner(options).run(); // 运行基准测试
}
}
结果
# JMH version: 1.33 // JMH 版本信息
# VM version: JDK 17.0.7, Java HotSpot(TM) 64-Bit Server VM, 17.0.7+8-LTS-224 // Java虚拟机版本信息
# VM invoker: C:\Program Files\Java\jdk-17\bin\java.exe // JVM启动器路径
# VM options: -javaagent:xxx\IntelliJ IDEA 2021.2.2\bin -Dfile.encoding=UTF-8 // JVM启动参数
# Blackhole mode: full + dont-inline hint (default, use -Djmh.blackhole.autoDetect=true to auto-detect) // Blackhole模式和选项
# Warmup: 1 iterations, 1 s each // 预热阶段设置,1次迭代,每次1秒
# Measurement: 3 iterations, 1 s each // 测量阶段设置,3次迭代,每次1秒
# Timeout: 10 min per iteration // 每次迭代的超时时间为10分钟
# Threads: 2 threads, will synchronize iterations // 线程数为2,迭代将同步执行
# Benchmark mode: Throughput, ops/time // 基准测试模式为吞吐量模式,单位为操作数/时间
# Benchmark: com.laker.xxx.benchmark.BenchmarkTest.benchmarkEmbed // 执行的基准测试方法
# Run progress: 0.00% complete, ETA 00:00:04 // 运行进度
# Fork: 1 of 1 // Fork次数
# Warmup Iteration 1: 0.885 ops/s // 预热阶段迭代1的吞吐量
Iteration 1: 1.242 ops/s // 测量阶段迭代1的吞吐量
Iteration 2: 2.193 ops/s // 测量阶段迭代2的吞吐量
Iteration 3: 1.665 ops/s // 测量阶段迭代3的吞吐量
Result "com.laker.xxx.benchmark.BenchmarkTest.benchmarkEmbed":
1.700 ±(99.9%) 8.694 ops/s [Average] // 结果统计,平均吞吐量1.700,99.9%置信度范围为[1.700-8.694, 1.700+8.694]
(min, avg, max) = (1.242, 1.700, 2.193), stdev = 0.477 // 最小、平均、最大值和标准偏差
CI (99.9%): [≈ 0, 10.394] (assumes normal distribution) // 99.9%置信度的置信区间,假设正态分布
# Run complete. Total time: 00:00:22 // 运行完成,总时间
Benchmark Mode Cnt Score Error Units
BenchmarkTest.benchmarkEmbed thrpt 3 1.700 ± 8.694 ops/s
// 基准测试结果摘要,吞吐量模式,迭代次数3,平均得分1.700,误差范围8.694,单位为操作数/时间
main
public static void main(String[] args) throws RunnerException {
Options options = new OptionsBuilder()
.include(BenchmarkTest.class.getSimpleName()) // 包含要运行的Benchmark类名
.warmupIterations(1) // 预热迭代次数
.warmupTime(TimeValue.seconds(1)) // 预热时间
.forks(1) // 子进程数
.measurementIterations(5) // 测量迭代次数
.measurementTime(TimeValue.seconds(1)) // 测量时间
.threads(Runtime.getRuntime().availableProcessors() * 2) // 线程数,通常是可用处理器数的两倍
.syncIterations(true) // 是否需要同步预热
.resultFormat(ResultFormatType.JSON) // 输出格式
.addProfiler(GCProfiler.class) // 性能剖析
.build();
new Runner(options).run(); // 运行Benchmark测试
}
-
syncIterations如果设置为true代表等所有线程预热完成,然后所有线程一起进入测量阶段,等所有线程执行完测试后,再一起进入关闭;
-
当syncIterations设置为true时更准确地反应了多线程下被测试方法的性能,这个参数默认为true,无需手动设置。
-
内置的性能剖析工具查看基准测试消耗在什么地方,具体的剖析方式内置的有如下几种:
- ClassloaderProfiler:类加载剖析
- CompilerProfiler:JIT编译剖析
- GCProfiler:GC剖析
- StackProfiler:栈剖析
- PausesProfiler:停顿剖析
- HotspotThreadProfiler:Hotspot线程剖析
- HotspotRuntimeProfiler:Hotspot运行时剖析
- HotspotMemoryProfiler:Hotspot内存剖析
- HotspotCompilationProfiler:Hotspot编译剖析
- HotspotClassloadingProfiler:Hotspot 类加载剖析
-
JMH 支持 5 种格式结果
-
TEXT 导出文本文件。
-
CSV 导出 csv 格式文件。
-
SCSV 导出 scsv 等格式的文件。
-
JSON 导出成 json 文件。
-
LATEX 导出到 latex,一种基于 ΤΕΧ 的排版系统。
一般来说,我们导出成 CSV 文件,直接在 Excel 中操作,生成图形就可以了。
-
关键注解示例
@Benchmark
@Benchmark标签是用来标记测试方法的,只有被这个注解标记的话,该方法才会参与基准测试,但是有一个基本的原则就是被@Benchmark标记的方法必须是public的。
@Warmup
@Warmup(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
- timeUnit:时间的单位,默认的单位是秒,默认为-1,但是实际测下来是10;
- iterations:预热阶段的迭代数,默认为-1;
- time:每次预热的时间,默认为秒;
- batchSize:批处理大小,指定了每次操作调用几次方法,默认为-1。
上面的注解,意思是对代码预热总计 5 秒(迭代 5 次,每次一秒)。预热过程的测试数据,是不记录测量结果的。
@State(Scope.Thread)
public class BenchmarkTest {
List<String> list = new LinkedList<>();
@Benchmark
@Warmup(iterations = 1, batchSize = 10)
@Measurement(iterations = 5, batchSize = 10)
public List<String> measureRight() {
list.add("something");
return list;
}
-- 结果
Benchmark Mode Cnt Score Error Units
BenchmarkTest.measureRight thrpt 5 11896.410 ± 10953.826 ops/s
@Measurement
Measurement 和 Warmup 的参数是一样的,不同于预热,它指的是真正的迭代次数。
@BenchmarkMode
用来指定基准测试类型,对应 Mode 选项,用来修饰类和方法都可以。这里的 value,是一个数组,可以配置多个统计维度。比如:
@BenchmarkMode({Throughput,Mode.AverageTime}),统计的就是吞吐量和平均执行时间两个指标。
可以分为以下几种:
-
Throughput: 整体吞吐量,比如 QPS,单位时间内的调用量等;
-
AverageTime: 平均耗时,指的是每次执行的平均时间。
-
SampleTime: 是基于采样的执行时间,采样频率由JMH自动控制,同时结果中也会统计出p90、p95等时间。
-
SingleShotTime: 单次执行时间,只执行一次,可用于冷启动的测试,其实和传统的 main 方法没有什么区别;
-
All: 所有的指标,都算一遍。
@Benchmark
@BenchmarkMode(Mode.All)
public void measureAll() throws InterruptedException {
TimeUnit.MILLISECONDS.sleep(100);
}
-- 结果
Benchmark Mode Cnt Score Error Units
BenchmarkTest.measureAll thrpt 5 9.176 ± 0.042 ops/s 吞吐量
BenchmarkTest.measureAll avgt 5 0.109 ± 0.001 s/op 平均耗时
BenchmarkTest.measureAll sample 461 0.109 ± 0.001 s/op p0
BenchmarkTest.measureAll:measureAll·p0.00 sample 0.106 s/op
BenchmarkTest.measureAll:measureAll·p0.50 sample 0.109 s/op
BenchmarkTest.measureAll:measureAll·p0.90 sample 0.110 s/op
BenchmarkTest.measureAll:measureAll·p0.95 sample 0.111 s/op
BenchmarkTest.measureAll:measureAll·p0.99 sample 0.112 s/op p99
BenchmarkTest.measureAll:measureAll·p0.999 sample 0.114 s/op
BenchmarkTest.measureAll:measureAll·p0.9999 sample 0.114 s/op
BenchmarkTest.measureAll:measureAll·p1.00 sample 0.114 s/op p100
BenchmarkTest.measureAll ss 5 0.109 ± 0.011 s/op 每轮单词执行时间
@OutputTimeUnit
@OutputTimeUnit 可以指定输出的时间单位,可以传入 java.util.concurrent.TimeUnit 中的时间单位,最小可以到纳秒级别。
@Benchmark
@OutputTimeUnit(TimeUnit.SECONDS)
public void second() throws InterruptedException {
TimeUnit.MILLISECONDS.sleep(100);
}
@Benchmark
@OutputTimeUnit(TimeUnit.MICROSECONDS)
public void microseconds() throws InterruptedException {
TimeUnit.MILLISECONDS.sleep(100);
}
-- 结果
Benchmark Mode Cnt Score Error Units
BenchmarkTest.microseconds thrpt 5 ≈ 10?? ops/us
BenchmarkTest.second thrpt 5 9.174 ± 0.041 ops/s
@Fork
@Fork 可以指定代码运行时是否需要 fork 出一个JVM进程,如果在同一个JVM中测试则会相互影响,一般fork进程设置为1。
由于JVM的复杂性,每次测试结果都有差异,可以使用 @Fork 注解启动多个 JVM 经过多次测试来消除这种差异。
可以做完全的环境隔离,避免交叉影响
@Fork(value = 1, jvmArgsAppend = {"-Xmx2048m", "-server", "-XX:+AggressiveOpts"})
@Threads
fork 是面向进程的,而 Threads 是面向线程的。指定了这个注解以后,将会开启并行测试。如果配置了 Threads.MAX,则使用和处理机器核数相同的线程数。
@Benchmark
@Warmup(iterations = 1, batchSize = 10)
@Measurement(iterations = 5, batchSize = 10)
@Threads(2)
public List<String> measureRight() {
System.out.println(Thread.currentThread().getName());
list.add("something");
return list;
}
-- 结果
com.laker.xxx.measureRight-jmh-worker-2
com.laker.xxx.measureRight-jmh-worker-1
com.laker.xxx.measureRight-jmh-worker-1
com.laker.xxx.measureRight-jmh-worker-2
@State
用于多线程的测试
@State 指定了在类中变量的作用范围,用于声明某个类是一个“状态”,可以用 Scope 参数用来表示该状态的共享范围。这个注解必须加在类上,否则提示无法运行。
Scope 有如下三种值。
-
Benchmark :表示变量的作用范围是某个基准测试类。
- 可以理解为线程共享的变量,注意线程安全问题。
-
Thread :每个线程一份副本,如果配置了 Threads 注解,则每个 Thread 都拥有一份变量,它们互不影响。
- 可以理解为一个ThreadLocal变量。
-
Group :用不到不管他。
// 变量 x 的默认作用范围是 ThreadLocal 无线程安全问题
@State(Scope.Thread)
public class JMHSample_04_DefaultState {
double x = Math.PI;
@Benchmark
public void measure() {
x++;
}
}
// 变量 x 的默认作用范围是 共享变量 有线程安全问题
@State(Scope.Benchmark)
public static class BenchmarkState {
volatile double x = Math.PI;
}
// 变量 x 的默认作用范围是 ThreadLocal 无线程安全问题
@State(Scope.Thread)
public static class ThreadState {
volatile double x = Math.PI;
}
@Benchmark
public void measureUnshared(ThreadState state) {
state.x++;
}
@Benchmark
public void measureShared(BenchmarkState state) {
state.x++;
}
@Setup 和 @TearDown
和单元测试框架 JUnit 类似,@Setup 用于基准测试前的初始化动作,@TearDown 用于基准测试后的动作,来做一些全局的配置。
这两个注解,同样有一个 Level 值,标明了方法运行的时机,它有三个取值。
-
Trial :默认的级别,也就是 Benchmark 级别。
-
Iteration :执行迭代级别。
-
Invocation :每次方法调用级别,这个是粒度最细的。
如果你的初始化操作,是和方法相关的,那最好使用 Invocation 级别。但大多数场景是一些全局的资源,比如一个 Spring 的 DAO,那么就使用默认的 Trial,只初始化一次就可以。
@Setup(Level.Iteration)
public void prepare() {
System.err.println("init............");
}
@TearDown(Level.Iteration)
public void check() {
System.err.println("destroy............");
}
@Param
@Param 允许使用一份基准测试代码跑多组数据,特别适合测量方法性能和参数取值的关系。
@State(Scope.Benchmark)
public class BenchmarkTest {
@Param({"1", "31", "65", "101", "103"})
public int arg;
@Param({"0", "1", "2", "4", "8", "16", "32"})
public int certainty;
@Benchmark
public boolean bench() {
return BigInteger.valueOf(arg).isProbablePrime(certainty);
}
问题
DeadCode
private double x = Math.PI;
@Benchmark
public void baseline() {
// do nothing, this is a baseline
}
@Benchmark
public void measureWrong() {
// This is wrong: result is not used and the entire computation is optimized away.
Math.log(x);
}
@Benchmark
public double measureRight() {
// This is correct: the result is being used.
return Math.log(x);
}
-- 结果
Benchmark Mode Cnt Score Error Units
BenchmarkTest.baseline thrpt 5 2784963766.898 ± 470716767.958 ops/s
BenchmarkTest.measureRight thrpt 5 92743372.858 ± 154517945.878 ops/s
BenchmarkTest.measureWrong thrpt 5 192408102.491 ± 8132308.101 ops/s
Dead-Code Elimination (DCE) ,即死码消除,编译器非常聪明,有的代码没啥用,就在编译器被消除了,但这给我做基准测试带了一些麻烦,比如上面的代码中,baseline 和 measureWrong 有着相同的性能,因为编译器觉得 measureWrong这段代码执行后没有任何影响,为了效率,就直接消除掉这段代码,但是如果加上return语句,就不会在编译期被去掉,这是我们在写基准测试时需要注意的点。
修复
死码消除问题,JMH提供了一个 Blackholes (黑洞),这样写就不会被编译器消除了。
@Benchmark
public void measureRight1(Blackhole blackhole) {
blackhole.consume(Math.log(x));
}
常量折叠
// 会在编译期直接替换为计算结果
private double x = Math.PI;
// 会在编译期直接替换为计算结果
private final double wrongX = Math.PI;
@Benchmark
public double baseline() {
// simply return the value, this is a baseline
return Math.PI;
}
@Benchmark
public double measureWrong_1() {
// This is wrong: the source is predictable, and computation is foldable.
return Math.log(Math.PI);
}
@Benchmark
public double measureWrong_2() {
// This is wrong: the source is predictable, and computation is foldable.
return Math.log(wrongX);
}
@Benchmark
public double measureRight() {
// This is correct: the source is not predictable.
return Math.log(x);
}
常量折叠,上述代码的 measureWrong_1 和 measureWrong_2 中的运算都是可以预测的值,所以也会在编译期直接替换为计算结果,从而导致基准测试失败,注意 final 修饰的变量也会被折叠。
Loops
不要在基准测试的时候使用循环,使用循环就会导致测试结果不准确。
/*
* 永远不要在基准测试的时候使用循环
*/
private int reps(int reps) {
int s = 0;
for (int i = 0; i < reps; i++) {
s += (x + y);
}
return s;
}
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!