【JVM】第一章:内存结构
一、内存结构
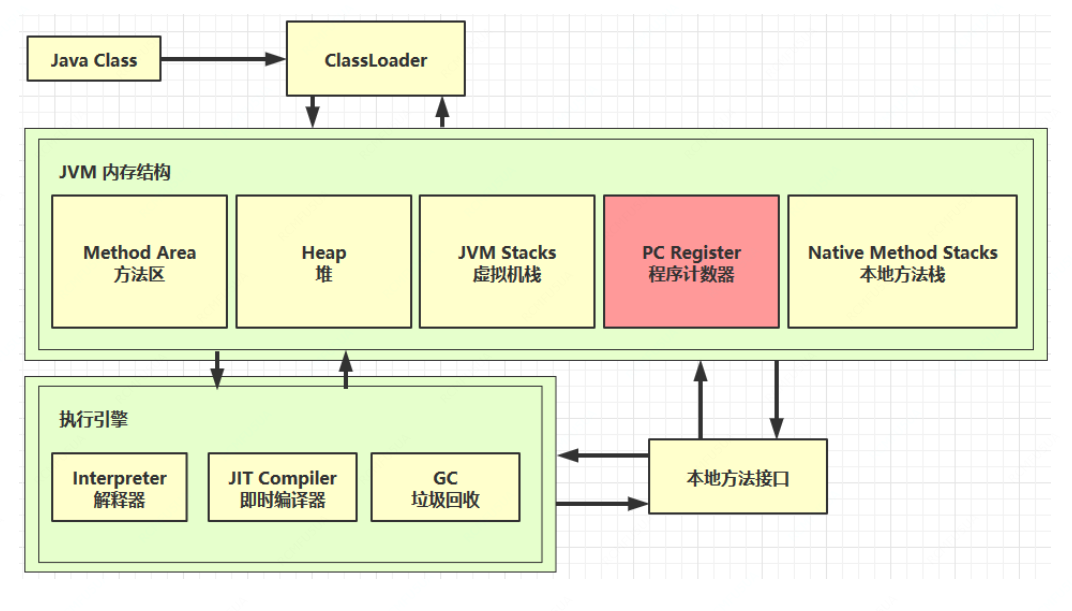
程序计数器
程序计数器是一块较小的内存空间,可以看作是当前线程执行的字节码的行号指示器。在虚拟机的概念模型里,字节码解释器工作时就是通过改变这个计数器的值来选取下一条需要执行的字节码指令。
程序计数器主要有以下两个功能:
- 计数器可以存放下一条指令所在单元的地址,当执行一条指令时,首先需要根据PC中存放的指令地址,将指令由内存取到指令寄存器中,此过程称为“取指令”。与此同时,PC中的地址或自动加1或由转移指针给出下一条指令的地址。此后经过分析指令,执行指令。完成第一条指令的执行,而后根据PC取出第二条指令的地址,如此循环,执行每一条指令。
- 由于java虚拟机的多线程是通过线程轮流切换并处理器执行的方式来实现的,在任何一个确定的时刻,一个处理器(对于多核处理器来说是一个内核)都只会执行一条线程中的指令。因此,为了线程切换后能恢复到正确的执行位置,每条线程都需要有一个独立的程序计数器,各条线程之间计数器互不影响,独立存储。这类内存区域被称为“线程私有”的内存。此内存区域是唯一一个java虚拟机规范中没有规定任何OutOfMenoryError情况的区域。
虚拟机栈
每个线程运行时所需要的内存,称为虚拟机栈。
虚拟机栈是Java虚拟机中的一个重要组成部分,用于支持Java方法的执行。更详细来说,它的功能包括:
- 每个Java线程在创建时都会创建一个虚拟机栈,这个栈与线程的生命周期一致,即当线程结束时,其对应的虚拟机栈也会被销毁。
- 虚拟机栈中存储的是一个个的栈帧,每一个栈帧对应着一次Java方法的调用。当Java方法被调用时,会创建一个新的栈帧并入栈,当方法执行结束后,对应的栈帧会出栈。
- 每个栈帧中存储了方法的局部变量、操作数栈、动态链接、方法出口等信息。这些信息用于支持Java方法的执行,例如局部变量表用于存储方法的参数和局部变量,操作数栈用于存储运算的中间结果(后缀表达式)等。
- 虚拟机栈还参与了Java方法的调用和返回。在方法调用时,会创建一个新的栈帧并入栈,然后在这个栈帧上执行方法。当方法执行结束后,栈帧会出栈,然后返回到调用该方法的地方。
- 每个线程只能由一个活动栈帧,对应着当前正在执行的那个方法。
综上所述,虚拟机栈是Java虚拟机的一个重要组成部分,它用于存储Java方法的执行上下文,支持Java方法的调用和返回,是Java程序运行的基础。
问题辨析:
- 垃圾回收是否涉及栈内存?
每次方法调用都会船舰一个新的栈帧进入栈中,方法调用结束后,对于的栈帧就会出栈,也就会自动的回收掉,所以不需要垃圾回收。
- 栈内存分配越大越好吗?
栈内存的大小在一定程度上影响了程序的运行。如果栈内存分配得过大,反而可能会减少能够同时运行的线程数量,因为物理内存大小是固定的。所以,合理的分配栈内存的大小是很重要的,要综合考虑程序的特性和需求,避免不必要的资源浪费和性能下降。
- 方法的局部变量是否线程安全?
- 如果方法内局部变量没有逃离方法的作用访问,它是线程安全的
- 如果是局部建立引用了对象,并逃离方法的作用范围,需要考虑线程安全
public static void m1() {
StringBuilder sb = new StringBuilder();
sb.append(1);
sb.append(2);
sb.append(3);
System.out.println(sb.toString());
}// 线程安全
public static void m2(StringBuilder sb) {
sb.append(1);
sb.append(2);
sb.append(3);
System.out.println(sb.toString());
}// 线程不安全,sb是外面传过来的引用变量,外部也会访问到
public static StringBuilder m3() {
StringBuilder sb = new StringBuilder();
sb.append(1);
sb.append(2);
sb.append(3);
return sb;
}//线程不安全,sb会返回给外面,外面可能会使用这个变量,造成线程不安全
栈内存溢出
栈帧过多导致栈内存溢出:比如递归,如果递归次数过多的话就会超过分配的栈内存空间,就会导致溢出。
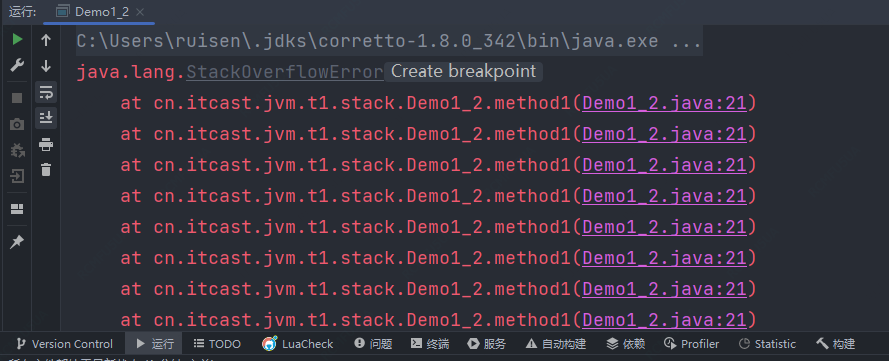
第一个例子:无限递归调用
/**
* 演示栈内存溢出 java.lang.StackOverflowError
* -Xss256k
*/
public class Demo1_2 {
private static int count;
public static void main(String[] args) {
try {
method1();
} catch (Throwable e) {
e.printStackTrace();
System.out.println(count);
}
}
private static void method1() {
// 无限递归,没有终止条件,就会导致栈内存溢出,java.lang.StackOverflowError
count++;
method1();
}
}
第二个例子:第三方库导致栈内存溢出
这个库在做Json转换的时候会一直转换它的引用对象,如果两个对象之间是循环引用的关系,那么就会一直递归下去,所以就会导致栈内存溢出。
解决办法:给属性加上 @JsonIgnore注解,就会破坏循环引用,就不会一直递归转换下去。
import com.fasterxml.jackson.annotation.JsonIgnore;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import java.util.Arrays;
import java.util.List;
/**
* json 数据转换
*/
public class Demo1_19 {
public static void main(String[] args) throws JsonProcessingException {
Dept d = new Dept();
d.setName("Market");
Emp e1 = new Emp();
e1.setName("zhang");
e1.setDept(d);
Emp e2 = new Emp();
e2.setName("li");
e2.setDept(d);
d.setEmps(Arrays.asList(e1, e2));
// { name: 'Market', emps: [{ name:'zhang', dept:{ name:'', emps: [ {}]} },] }
ObjectMapper mapper = new ObjectMapper();
System.out.println(mapper.writeValueAsString(d));
}
}
class Emp {
private String name;
// 如果不想要继续转换某个属性可以在这个属性上加上 @JsonIgnore
@JsonIgnore
private Dept dept;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Dept getDept() {
return dept;
}
public void setDept(Dept dept) {
this.dept = dept;
}
}
class Dept {
private String name;
private List<Emp> emps;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public List<Emp> getEmps() {
return emps;
}
public void setEmps(List<Emp> emps) {
this.emps = emps;
}
}
栈帧过大导致栈内存溢出:如果局部变量占用的内存空间过大也会导致栈内存溢出。
线程运行诊断:
案例1:CPU占用过多
首先,我们在Linux系统下创建一个Java程序
public class Demo1_16 {
public static void main(String[] args) {
new Thread(null, () -> {
System.out.println("1...");
while(true) {
}
}, "thread1").start();
new Thread(null, () -> {
System.out.println("2...");
try {
Thread.sleep(1000000L);
} catch (InterruptedException e) {
e.printStackTrace();
}
}, "thread2").start();
new Thread(null, () -> {
System.out.println("3...");
try {
Thread.sleep(1000000L);
} catch (InterruptedException e) {
e.printStackTrace();
}
}, "thread3").start();
}
}
为了方面我们看该程序CPU占用情况,我们选择后台运行该程序
nohup java demo01_16 &
用 top命令来查看系统中实时进程的运行情况。
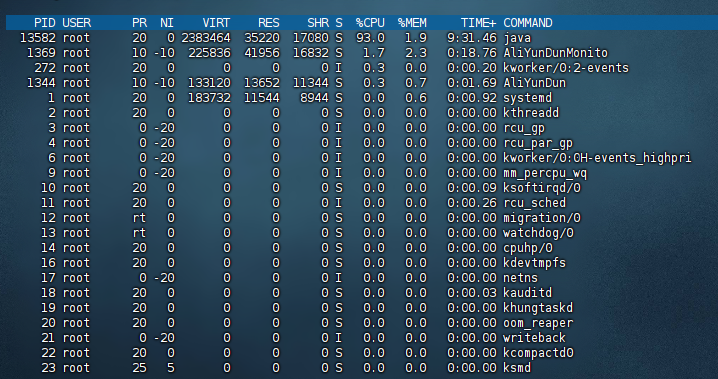
然后我可以可以发现第一个进程占用的CPU非常高,然后我们还想看该进程中的线程运行情况,寻找占用CPU最多的线程。
用ps命令进一步定位是哪个线程引起的CPU占用过高。
ps -H -eo pid,tid,%cpu | grep 进程id
然后使用jstack 进程id来找到有问题的线程ID,进一步定位到问题代码的具体位置。
**jstack 是 Java 开发工具包(JDK)中的一个命令行工具,用于生成 Java 进程的线程快照。线程快照包含了每个线程的堆栈跟踪信息,可以用于分析和调试 Java 程序的性能问题。
案例2:程序运行很长时间没有结果
我们在linux环境下创建一个Java程序如下:
/**
* 演示线程死锁
*/
class A{};
class B{};
public class Demo1_3 {
static A a = new A();
static B b = new B();
public static void main(String[] args) throws InterruptedException {
new Thread(()->{
synchronized (a) {
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (b) {
System.out.println("我获得了 a 和 b");
}
}
}).start();
Thread.sleep(1000);
new Thread(()->{
synchronized (b) {
synchronized (a) {
System.out.println("我获得了 a 和 b");
}
}
}).start();
}
}
正常执行的话会发现一直没有结果。
然后在后台执行该程序
nohup java demo1_3 &
在用jstack 进程id查看该进程
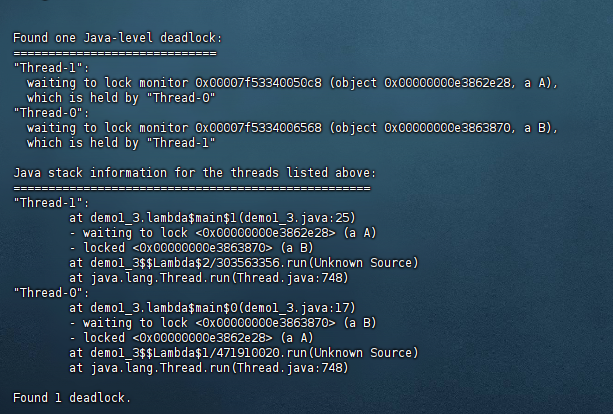
在打印的日志中我们可以看到说 发现了一个死锁,然后记录了锁的位置,然后我就根据代码行数去源代码查明原因。
本地方法栈
本地方法栈是Java虚拟机中的一个内存区域,用于存储Java虚拟机调用本地方法的相关信息。本地方法时使用本地语言(如C、C++)编写的方法,而非Java语言编写。
Java虚拟机规范将本地方法栈描述为与Java虚拟机栈类似的结构,但是它是为本地方法服务的。在调用本地方法是,Java虚拟机会使用本地方法栈来管理本地方法的调用和执行过程。
本地方法站的作用主要有两个方面:
- 管理本地方法调用:当Java代码调用本地方法时,本地方法栈用于跟踪本地方法的调用信息。。每个本地方法站都与一个线程关联,用于管理该线程调用的本地方法的状态。
- 分配本地方法栈帧:本地方法栈中的每个栈帧都对应于一个本地方法的调用。与Java虚拟机栈中的栈帧类似,本地方法栈帧包含了本地方法的局部变量、操作数栈等信息。
在Java中,通过native关键字声明的都是本地方法,当调用本地方法时,会将Java数据传递给本地方法,然后执行本地方法。
堆
堆是一个用于存储对象实例的运行时数据区域。在Java程序中,所有的对象都在堆上分配内存,包括在程序运行时动态创建的对象和数组。
只要是new出来的对象都放在堆中。
堆是Java内存管理中最大的一块区域,它被所有线程共享,用于存储对象实例和数组。堆的主要作用是提供动态内存分配,以便在程序运行时灵活地创建和管理对象。
以下是堆的一些特性和重要概念:
- 对象分配:所有对象都在对上动态分配内存。当使用
new关键字创建一个对象时,JVM会在堆上为该对象分配内存空间。 - 垃圾回收:堆上的内存是由Java虚拟机的垃圾回收器进行管理的。垃圾回收的主要目标是回收不再被引用的对象的内存,一边释放空间供新的对象使用。
- 堆的划分:堆可以被划分为两个主要区域,即新生代和老生代。新生代用于存储新创建的对象,而老生代用于存储生命周期较长的对象。这样有助于优化垃圾回收的效率。
- 堆的大小:堆的大小可以通过Java虚拟机的启动参数进行调整。常见的参数包括
**-Xms**(初始堆大小)和**-Xmx**(最大堆大小)。 - 内存分配策略:队中的内存分配通常采用分代垃圾回收策略。新生代使用复制算法,而老年代使用标记-清楚或标记-整理算法,以提高垃圾回收的效率。
- OutOfMemoryError:如果堆空间不足以容纳新创建的对象,Java程序将抛出OutOfMemoryError异常/
Java虚拟机中的堆和数据结构中的堆是一样的吗?
不、答案是否定的,它俩是两个不同的概念。
- Java虚拟机中的堆:在Java虚拟机中,“堆”指的是运行时数据区域,用于存储对象实例和数组。这个堆是一种动态内存分配的区域,由Java虚拟机的垃圾回收器进行管理。它是Java程序运行时的一部分,用于存储动态创建的对象。
- 数据结构中的堆: 在数据结构中,“堆"通常指的是一种特定的数据结构,称为"二叉堆”。二叉堆是一种树状数据结构,分为最大堆和最小堆。最大堆的每个节点的值都大于或等于其子节点的值,而最小堆的每个节点的值都小于或等于其子节点的值。在数据结构中,堆通常用于实现优先队列等算法。
堆内存溢出
虽然会有垃圾回收器回收堆中的堆,但是当堆中的对象很多并且一直在使用的时候就会当时堆内存一处。
举个例子:
字符串拼接会产生一个新的字符串对象,并将其赋值给变量a。那么变量a 一直不会被垃圾回收,而且字符串的长度呈指数型增长,而且每次拼接生成的新对象都会加入list集合中,那么生成的这些新对象也不会被垃圾回收,最后导致堆内存溢出。
/**
* 演示堆内存溢出 java.lang.OutOfMemoryError: Java heap space
* -Xmx8m
*/
public class Demo1_5 {
public static void main(String[] args) {
int i = 0;
try {
List<String> list = new ArrayList<>();
String a = "hello";
while (true) {
list.add(a); // hello, hellohello, hellohellohellohello ...
a = a + a; // hellohellohellohello
i++;
}
} catch (Throwable e) {
e.printStackTrace();
System.out.println(i);
}
}
}
报错日志:
java.lang.OutOfMemoryError: Java heap space
at java.util.Arrays.copyOfRange(Arrays.java:3664)
at java.lang.String.(String.java:207)
at java.lang.StringBuilder.toString(StringBuilder.java:407)
at cn.itcast.jvm.t1.heap.Demo1_5.main(Demo1_5.java:19)
24
堆内存诊断:
jps工具:用于显示当前系统中所有正在运行的Java进程的信息。
jmap工具:用于生成Java进程的内存转储快照,可以了解Java应用程序的内存使用情况,包括堆和非堆的内存区域的详细信息。
jconsole工具:用于监控和管理Java虚拟机的图形化工具,它提供了实时监控和分析Java应用程序的性能、内存使用情况、线程执行、垃圾回收等信息。
案例代码:
/**
* 演示堆内存
*/
public class Demo1_4 {
public static void main(String[] args) throws InterruptedException {
System.out.println("1...");
Thread.sleep(30000);
byte[] array = new byte[1024 * 1024 * 10]; // 10 Mb
System.out.println("2...");
Thread.sleep(20000);
array = null;
System.gc();
System.out.println("3...");
Thread.sleep(1000000L);
}
}
当我们执行上诉代码后,在终端敲入jps命令,就会显示Java进程信息
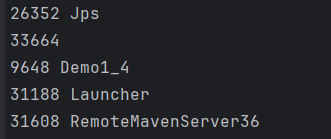
然后在执行jmap -heap 进程id命令,查看当前进程堆使用情况,注意这时进程还在睡眠状态,还没有创建array对象。
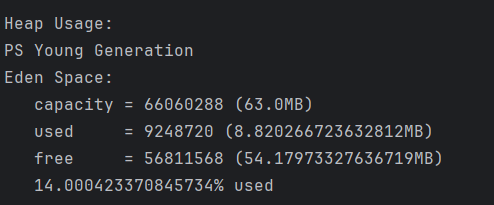
当控制台打印"2…"的时候,说明已经创建了新对象,那么在执行jmap命令,查看堆内存使用情况。我们发现堆内存多使用了10MB,正是因为我们创建了一个10MB的array对象,该对象已经加入到了堆中。
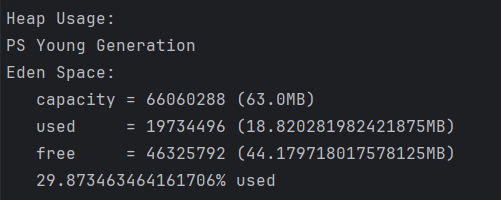
当控制台打印"3…"的时候,说明垃圾回收器已经回收了array对象,那么在执行jmap命令,查看堆内存使用情况,这时你可以发现堆内存大部分空间已经被回收了。
接下来我们使用以下jconsole工具,还是上面那个代码,执行之后去终端敲入jconsole命令直接会出现一个弹窗界面,里面展示了进程信息,而且是动态展示。
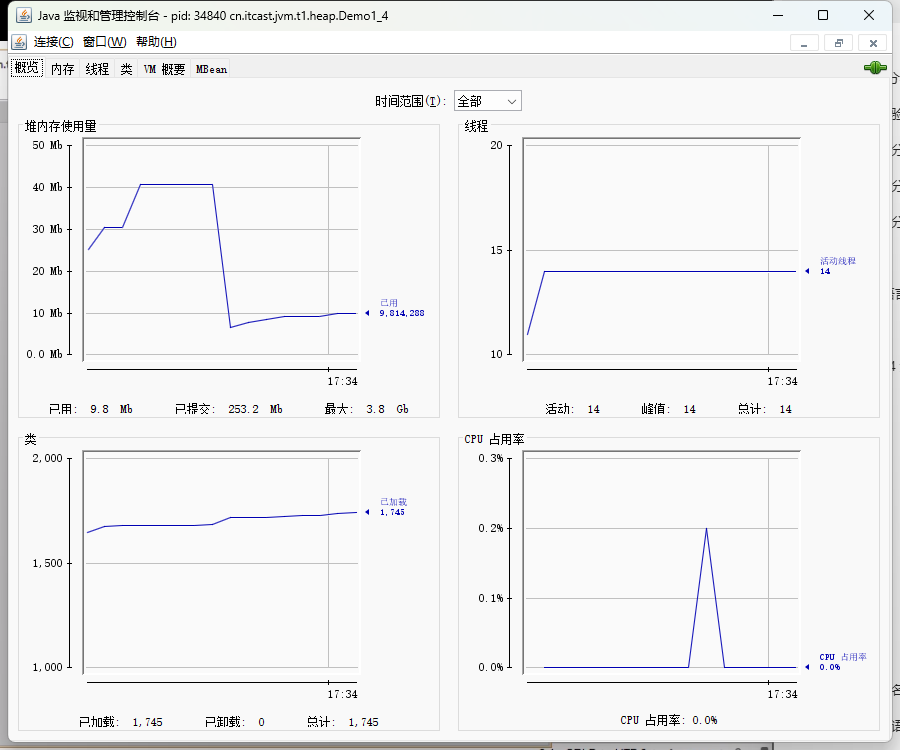
jvisualvm工具:是Java JDK 自带的一款强大的图形化工具,用于监控、分析和调试Java应用程序,提供了全面的性能分析和诊断功能。
案例:当执行完垃圾回收后,内存还是大量空间没有回收掉
/**
* 演示查看对象个数 堆转储 dump
*/
public class Demo1_13 {
public static void main(String[] args) throws InterruptedException {
List<Student> students = new ArrayList<>();
for (int i = 0; i < 200; i++) {
students.add(new Student());
// Student student = new Student();
}
Thread.sleep(1000000000L);
}
}
class Student {
private byte[] big = new byte[1024*1024];
}
我们先执行上述代码,然后去命令行中敲入jvisualvm命令,之后会弹出一个图形化
然后我们再去点监视按钮,查看当前堆内存使用情况,发现有两百多M,然后在点击执行垃圾回收查看回收后的情况,发现还是两百多M,没什么太大变化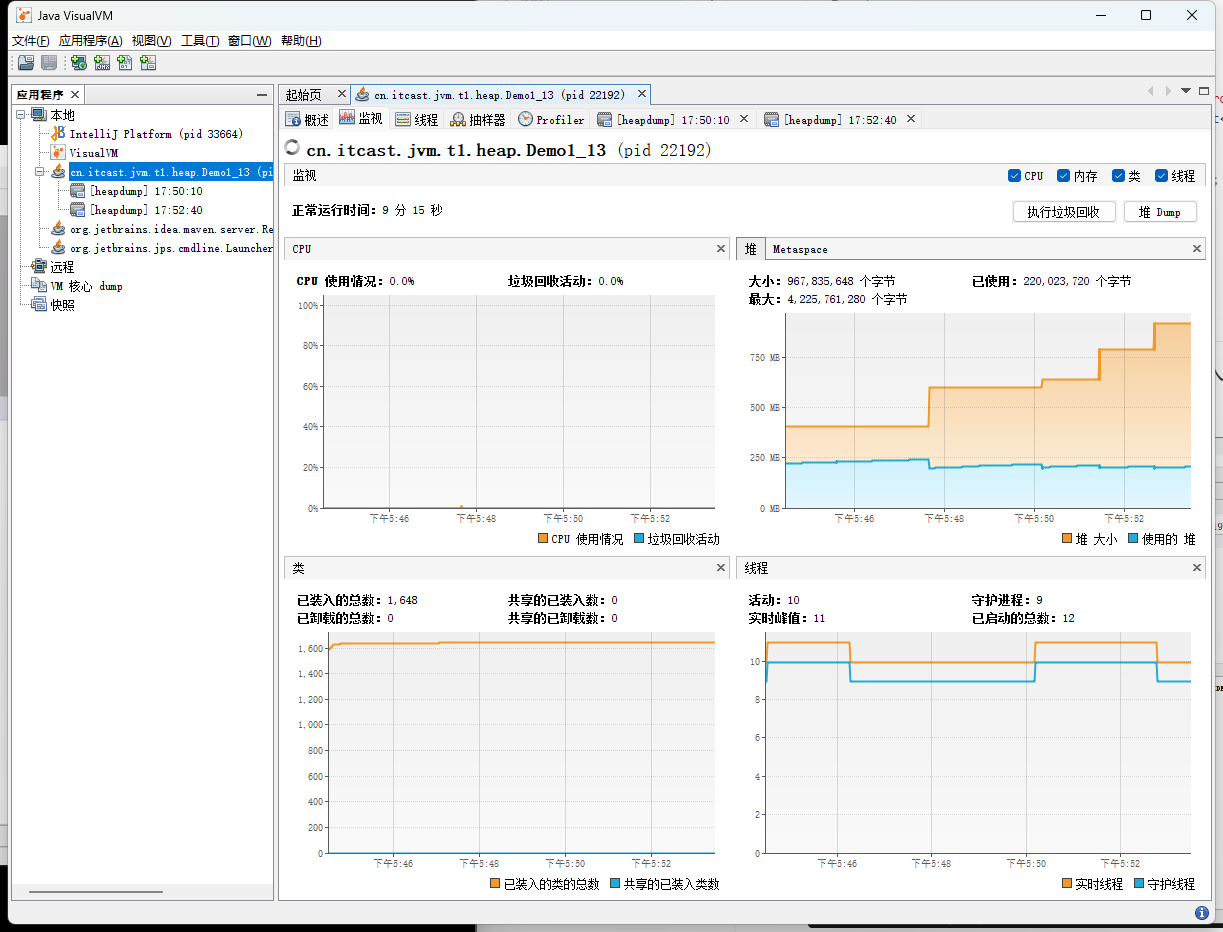
然后我们在点击堆 Dump按钮,查看当前堆内存中的占用情况
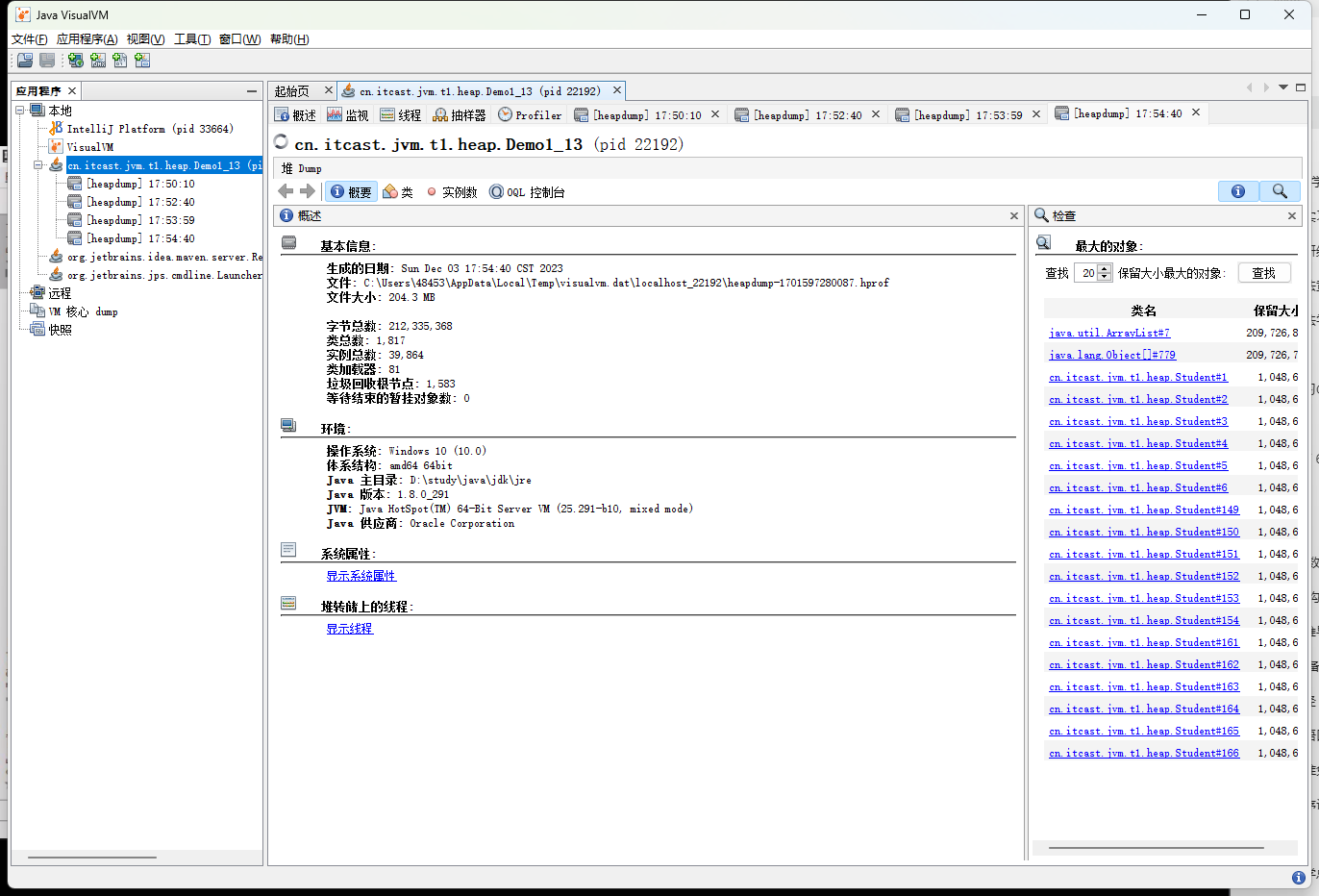
然后我们在查找当前最大的对象,发现是一个ArrayList对象,然后在点击该对象,查看该对象的详细信息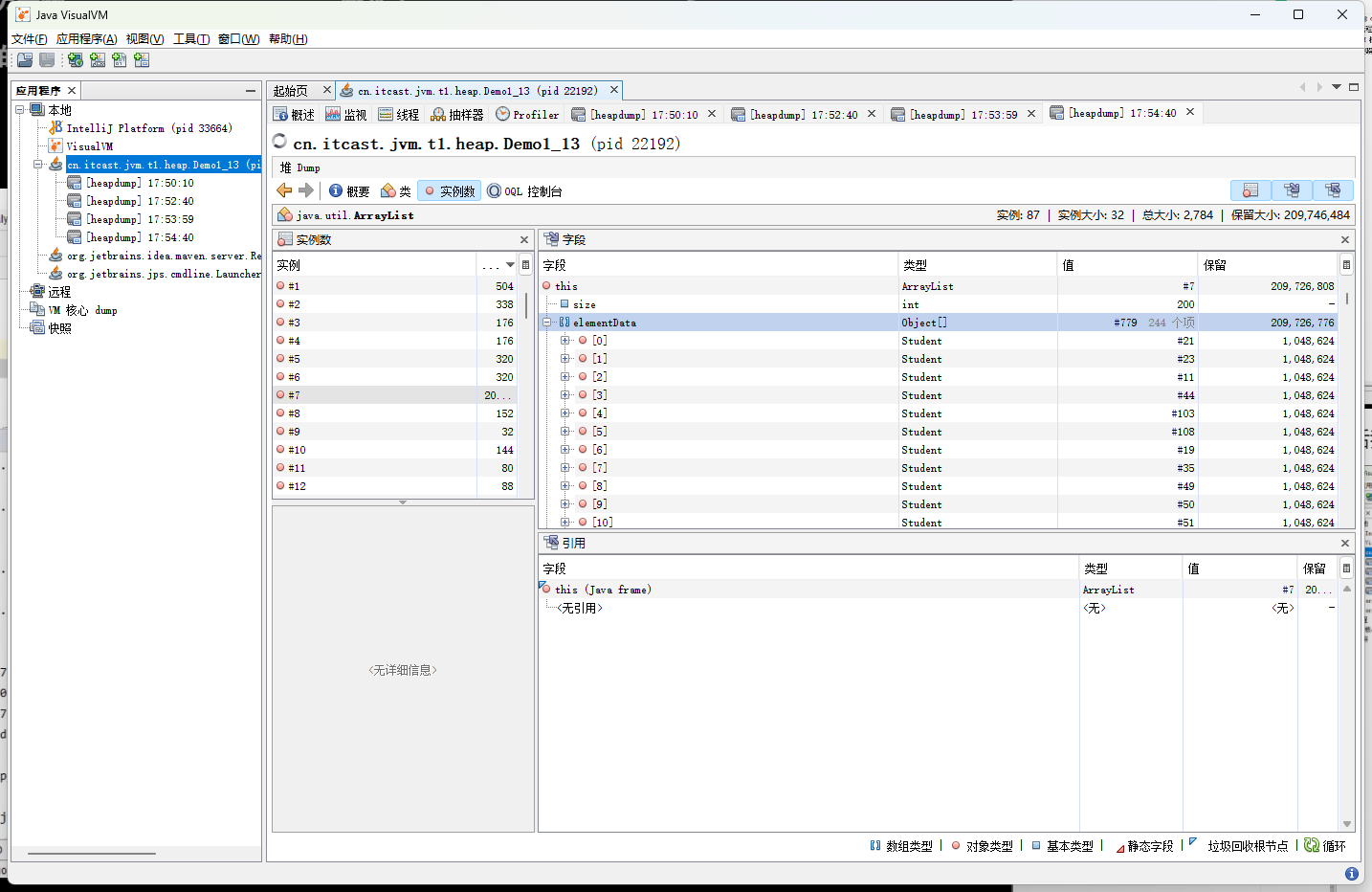
然后我们就可以知道为啥这个对象占用那么高的内存,存储了哪些元素导致的,然后再去分析我们的代码,找到原因。
方法区
在JVM中,方法去是一块存储类信息、常量、静态变量以及即时编译器编译后的代码的内存区域,也是各个线程共享的内存区域。它是堆的一部分,但是在一些虚拟机实践中,也可能被实现为堆之外的特殊区域。
方法去的主要作用包括:
- 存储类信息:每个类的结构信息,包括类的字段、方法、父类、接口等。这些信息在类加载时被加载到方法区。
- 存储常量:方法区包含运行时常量池,用于存储编译器生成的各种字面量和符号引用。这些查明和字符常量、类常量、接口常量等。
- 存储静态变量:所有被声明为静态的变量都被存储在方法区中。
- 存储即时编译器编译后的代码:当某个方法被JIT编译后的本地机器代码被存储在方法区。
方法区和永久代以及元空间是什么关系呢? 方法区和永久代以及元空间的关系很像 Java 中接口和类的关系,类实现了接口,这里的类就可以看作是永久代和元空间,接口可以看作是方法区,也就是说永久代以及元空间是 HotSpot 虚拟机对虚拟机规范中方法区的两种实现方式。并且,永久代是 JDK 1.8 之前的方法区实现,JDK 1.8 及以后方法区的实现变成了元空间。
元空间的引入解决了一些传统方法区的限制,例如固定大小和垃圾回收导致的停顿问题。元空间不再受到固定大小的限制,而且可以通过JVM选项动态调整大小。垃圾回收的责任也被转移到了元空间的一部分。这些改变提高了Java应用程序的灵活性和性能。
方法区内存溢出
代码案例:
在jdk1.8中,我们可以通过设置元空间大小来让方法区内存溢出,报错中会显示:java.lang.OutOfMemoryError: Metaspace
/**
* 演示元空间内存溢出 java.lang.OutOfMemoryError: Metaspace
* -XX:MaxMetaspaceSize=8m
*/
public class Demo1_8 extends ClassLoader { // 可以用来加载类的二进制字节码
public static void main(String[] args) {
int j = 0;
try {
Demo1_8 test = new Demo1_8();
for (int i = 0; i < 30000; i++, j++) {
// ClassWriter 作用是生成类的二进制字节码
ClassWriter cw = new ClassWriter(0);
// 版本号, public, 类名, 包名, 父类, 接口
cw.visit(Opcodes.V1_8, Opcodes.ACC_PUBLIC, "Class" + i, null, "java/lang/Object", null);
// 返回 byte[]
byte[] code = cw.toByteArray();
// 执行了类的加载
test.defineClass("Class" + i, code, 0, code.length); // Class 对象
}
} finally {
System.out.println(j);
}
}
}
在jdk1.6中,我们可以通过设置永久代大小来让方法区内存溢出,报错中会显示:java.lang.OutOfMemoryError: PermGen space
/**
* 演示永久代内存溢出 java.lang.OutOfMemoryError: PermGen space
* -XX:MaxPermSize=8m
*/
public class Demo1_8 extends ClassLoader {
public static void main(String[] args) {
int j = 0;
try {
Demo1_8 test = new Demo1_8();
for (int i = 0; i < 30000; i++, j++) {
ClassWriter cw = new ClassWriter(0);
cw.visit(Opcodes.V1_6, Opcodes.ACC_PUBLIC, "Class" + i, null, "java/lang/Object", null);
byte[] code = cw.toByteArray();
test.defineClass("Class" + i, code, 0, code.length);
}
} finally {
System.out.println(j);
}
}
}
运行时常量池
常量池:就是一张表,虚拟机指令根据这张表找到要执行的类名、方法名、参数类型、字面量等信息。
常量池的作用就是给指令提供一些符号可以直接引用。相当于有一个工具包,杂七杂八的东西都放在里面,想用的时候直接去里面拿就行了,而且东西也都是摆放整齐的,很方便使用。
举个例子:
public class HelloWorld {
public static void main(String[] args) {
int a = 1;
int b = 2;
if (a == b) {
int abs = Math.abs(a + b);
}
System.out.println("hello world");
}
}
先编译成字节码文件,然后在终端中输入javap -v 字节码文件,就得到了反编译之后的字节码内容。
Constant pool: // 常量池的开始
#1 = Methodref #7.#25 // java/lang/Object."<init>":()V
#2 = Methodref #26.#27 // java/lang/Math.abs:(I)I
#3 = Fieldref #28.#29 // java/lang/System.out:Ljava/io/PrintStream;
#4 = String #30 // hello world
#5 = Methodref #31.#32 // java/io/PrintStream.println:(Ljava/lang/String;)V
#6 = Class #33 // cn/itcast/jvm/t5/HelloWorld
#7 = Class #34 // java/lang/Object
#8 = Utf8 <init> // Utf8编码的字符串,表示构造方法的名称
#9 = Utf8 ()V // Utf8编码的字符串,表示无参数的方法
#10 = Utf8 Code // Utf8编码的字符串,表示方法区中的字节码
#11 = Utf8 LineNumberTable// Utf8编码的字符串,表示行号表
#12 = Utf8 LocalVariableTable// Utf8编码的字符串,表示局部变量表
#13 = Utf8 this // Utf8编码的字符串,表示关键字 "this"
#14 = Utf8 Lcn/itcast/jvm/t5/HelloWorld; // Utf8编码的字符串,表示类的类型签名
#15 = Utf8 main // Utf8编码的字符串,表示main方法的名称
#16 = Utf8 ([Ljava/lang/String;)V // Utf8编码的字符串,表示main方法的签名
#17 = Utf8 args // Utf8编码的字符串,表示参数名称
#18 = Utf8 [Ljava/lang/String; // Utf8编码的字符串,表示参数类型签名
#19 = Utf8 a // Utf8编码的字符串,表示局部变量名称
#20 = Utf8 I // Utf8编码的字符串,表示int类型
#21 = Utf8 b // Utf8编码的字符串,表示局部变量名称
#22 = Utf8 StackMapTable // Utf8编码的字符串,表示栈映射表
#23 = Utf8 SourceFile // Utf8编码的字符串,表示源文件
#24 = Utf8 HelloWorld.java// Utf8编码的字符串,表示源文件的名称
#25 = NameAndType #8:#9 // "<init>":()V,表示构造方法的名称和类型签名
#26 = Class #35 // java/lang/Math
#27 = NameAndType #36:#37 // abs:(I)I,表示Math类的abs方法的名称和类型签名
#28 = Class #38 // java/lang/System
#29 = NameAndType #39:#40 // out:Ljava/io/PrintStream;,表示System类的out字段的名称和类型签名
#30 = Utf8 hello world // Utf8编码的字符串,表示字符串常量 "hello world"
#31 = Class #41 // java/io/PrintStream
#32 = NameAndType #42:#43 // println:(Ljava/lang/String;)V,表示PrintStream类的println方法的名称和类型签名
{
public cn.itcast.jvm.t5.HelloWorld();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=1, locals=1, args_size=1
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
LineNumberTable:
line 4: 0
LocalVariableTable:
Start Length Slot Name Signature
0 5 0 this Lcn/itcast/jvm/t5/HelloWorld;
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=4, args_size=1
0: iconst_1 // 将常量1压入栈顶
1: istore_1 // 将栈顶的值存储到本地变量槽1(a)
2: iconst_2 // 将常量2压入栈顶
3: istore_2 // 将栈顶的值存储到本地变量槽2(b)
4: iload_1 // 将本地变量槽1(a)的值加载到栈顶
5: iload_2 // 将本地变量槽2(b)的值加载到栈顶
6: if_icmpne 16 // 如果a不等于b,跳转到第16行
9: iload_1 // 将本地变量槽1(a)的值加载到栈顶
10: iload_2 // 将本地变量槽2(b)的值加载到栈顶
11: iadd // 将栈顶两个值相加
12: invokestatic #2 // Method java/lang/Math.abs:(I)I,调用Math类的abs方法
15: istore_3 // 将栈顶的值存储到本地变量槽3
16: getstatic #3 // Field java/lang/System.out:Ljava/io/PrintStream;
19: ldc #4 // String hello world,将字符串常量 "hello world" 加载到栈顶
21: invokevirtual #5 // Method java/io/PrintStream.println:(Ljava/lang/String;)V,调用PrintStream的println方法
24: return // 返回
LineNumberTable: // 行号表
line 6: 0 // 第6行,字节码偏移0
line 7: 2 // 第7行,字节码偏移2
line 8: 4 // 第8行,字节码偏移4
line 10: 9 // 第10行,字节码偏移9
line 12: 16 // 第12行,字节码偏移16
line 13: 24 // 第13行,字节码偏移24
LocalVariableTable: // 局部变量表
Start Length Slot Name Signature
0 25 0 args [Ljava/lang/String; // 参数 args
2 23 1 a I // 本地变量 a,类型 int
4 21 2 b I // 本地变量 b,类型 int
StackMapTable: number_of_entries = 1
frame_type = 253 /* append */
offset_delta = 16
locals = [ int, int ] // 局部变量表更新,添加两个 int 类型的变量
}
在Java虚拟机中,运行常量池是方法区的一部分,用于存储编译时生成的各种字面量和符号引用。当该类被加载,它的常量池信息就会放入运行时常量池,并把里面的符号地址转换为真实物理地址。
主要作用:
- 存储字面量:运行时常量池包含了字符串常量、数值常量以及其他字面量。这些字面量实在编译期间确定的,并在运行时存储在运行时常量池。
- 存储符号引用:运行时常量池存储类和接口的全限定名、字符按的名称和描述符、方法的名称和描述符等符号引用。这些符号引用在类加载时解析为直接引用,帮助程序正确地执行方法调用、字段访问等操作。
- 动态生成:Java语言支持字符串的拼接操作,而这种操作在编译期并不总是能够确定结果。通过将拼接操作的结果存储在运行时常量池中,实现了字符串的动态生成。
StringTable
先看几道面试题:
String s1 = "a";
String s2 = "b";
String s3 = "a" + "b";
String s4 = s1 + s2;
String s5 = "ab";
String s6 = s4.intern();
// 问
System.out.println(s3 == s4);
System.out.println(s3 == s5);
System.out.println(s3 == s6);
String x2 = new String("c") + new String("d");
String x1 = "cd";
x2.intern();
// 问,如果调换了【最后两行代码】的位置呢,如果是jdk1.6呢
System.out.println(x1 == x2);
StringTable 在 Java 虚拟机中是字符串池的一部分,它用于存储字符串常量。字符串池是 Java 中用于存储字符串的一种数据结构,以确保相同的字符串在内存中只有一份拷贝,以节省内存。
在 JDK 7 及之前的版本,字符串池是通过 PermGen(永久代)来实现的,而在 JDK 8 及之后的版本,随着永久代的移除,字符串池被移到了堆中的一部分,具体说是放在了 Metaspace(元数据区)。这个池被称为 StringTable。
以下是一些关于 StringTable 的主要特点和用途:
存储字符串常量: StringTable 主要用于存储在程序中出现的字符串常量。这些字符串通常是通过字面值或者 String 类的构造方法创建的。
- 唯一性: 字符串池的设计保证相同的字符串常量在内存中是唯一的,即任何时候,如果两个字符串的内容相同,它们在 StringTable 中的引用都是相同的。
- 提高性能: 字符串池的存在提高了字符串的使用效率。由于字符串是不可变的,可以通过共享相同的字符串常量来减少内存占用。
- 减少内存占用: 通过共享相同的字符串,StringTable 可以有效地减少程序运行时所需的内存。
什么时候创建的字符串对象?
在Java字节码中,ldc(load constant)指令用于将常量值(如字符串、整数、浮点数等)从常量池中加载到操作数栈上。对于字符串常量,ldc 指令会将字符串常量的引用压入操作数栈。
但是,请注意,ldc 指令并不直接创建字符串对象。它加载的是字符串常量在常量池中的引用,并将该引用推送到栈上。实际的字符串对象可能已经在常量池中创建好了,或者在堆上创建。
如果字符串常量在常量池中已经存在,那么 ldc 指令会将该字符串的引用直接加载到操作数栈上。如果常量池中没有该字符串,ldc 指令会先在常量池中创建一个新的字符串常量,然后将其引用加载到栈上。
当执行到String s = "hello"这行代码时才会创建字符串对象,并不是在编译时就已经创建了对象。创建完之后就会将该字符串常量加入到StringTable中,这个数据结构是一个hash表,用判重的功能,所以下次在创建一个hello字符串对象时,会发现已经存在于表中了,不需要再次创建了。
为啥**System.out.println(s3 == s4);**结果为**false**
public class demo1 {
public static void main(String[] args) {
String s1 = "a";
String s2 = "b";
String s3 = "ab";
String s4 = s1 + s2;
System.out.println(s3 == s4);
}
}
我们再通过反编译字节码文件查看为啥不同
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=3, locals=5, args_size=1
0: ldc #2 // String a,将字符串"a"添加到串池中
2: astore_1
3: ldc #3 // String b,将字符串"b"添加到串池中
5: astore_2
6: ldc #4 // String ab,将字符串"ab"添加到串池中
8: astore_3
9: new #5 // class java/lang/StringBuilder
12: dup
13: invokespecial #6 // Method java/lang/StringBuilder."<init>":()V
16: aload_1
17: invokevirtual #7 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
20: aload_2
21: invokevirtual #7 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
24: invokevirtual #8 // Method java/lang/StringBuilder.toString:()Ljava/lang/String;
27: astore 4
29: getstatic #9 // Field java/lang/System.out:Ljava/io/PrintStream;
32: aload_3
33: aload 4
35: if_acmpne 42
38: iconst_1
39: goto 43
42: iconst_0
43: invokevirtual #10 // Method java/io/PrintStream.println:(Z)V
46: return
我们发现s1 + s2这段代码底层原来是通过new StringBuilder().append("a").append("b").toString()来创建的
public String toString() {
// Create a copy, don't share the array
return new String(value, 0, count);
}
我们又看该函数的源码发现是new String("ab"),而凡是new 出来的对象都会放到堆中,而不是方法区中的串池中,所以s3和s4是放在不同位置的两个对象,所以使用==比较的对象物理地址并不相同。即使内容相同,但对象地址不同。
为啥**System.out.println(s3 == s5);**结果是**true**?
反编译之后可以发现这个字符串拼接操作是直接在编译器就完成的,直接变成了String s5 = "ab",所以就会直接到串池中引用"ab"对象,不用在创建新对象,所以结果是true。
为啥s4执行的时候不是直接拼接呢,因为s1和s2都是变量,变量是可能发生变化的,需要具体执行的时候才能确定。而常量直接拼接是一定可以直接确定的。
字符串延迟加载
在JVM中,字符串字面量有一个特殊的处理方式,即字符串池的概念。字符串字面量在Java中是不可改变的,这使得他们可以被共享并在需要时延迟加载。
当Java程序中遇到字符串字面量时,JVM会首先检查字符串池,如果字符串已经存在与池中,就直接返回池中的引用,而不会创建新的对象。这就是字符串字面量 在JVM中的延迟加载效果,因为如果字符串池中已经有相同的字符串,那么就不需要在创建新的字符串。
public class StringLiteralDemo {
public static void main(String[] args) {
// 字符串字面量 "Hello" 在编译时就放入字符串池
String str1 = "Hello";
String str2 = "Hello";
// 字符串字面量相同,因此它们引用的是同一个对象
System.out.println(str1 == str2); // 输出 true
}
}
在这个例子中,str1 和 str2 引用的都是字符串池中的同一个字符串对象,因此 str1 == str2 返回 true。
这种字符串字面量在字符串池中共享的机制有助于减少内存占用,因为相同的字符串字面量只需要在内存中存储一份。在实际应用中,这样的优化可以提高程序的性能和节省内存。
需要注意的是,这种延迟加载仅适用于字符串字面量,而不一定适用于动态生成的字符串,例如通过使用 new String(“Hello”) 来创建字符串对象,这样会强制创建一个新的对象,而不考虑字符串池。
intern 方法
在Java中,intern() 方法是String类提供的一个方法,它用于将字符串对象添加到字符串池中,并返回池中相应字符串的引用。如果字符串池中已经存在该字符串,intern() 方法则返回池中现有的引用。
public class InternExample {
public static void main(String[] args) {
String str1 = new String("Hello");
String str2 = "Hello";
// 使用 intern() 方法将字符串添加到字符串池中
String str3 = str1.intern();
// 检查字符串的引用是否相同
System.out.println(str1 == str2); // 输出 false
System.out.println(str2 == str3); // 输出 true
}
}
在上述示例中,str1 是通过 new String(“Hello”) 显式创建的字符串对象,而str2 是字符串字面量,它在编译时已经被添加到字符串池中。通过调用 intern() 方法,str1 的引用被添加到字符串池中,并且 str3 引用的是字符串池中的对象。
import java.util.*;
public class Main {
public static void main(String[] args) {
// "a"、"b" 在编译时都会加入到常量池,因为他们是字面量,所以编译器会把它们加入到常量池中
String a = new String("a");
String b = new String("b");
String s = a + b;
// 字符串变量底层是通过new String("ab")创建的,而编译的时候是不会执行创建的,
//所以"ab"在编译时不会加入到常量池中
String s2 = s.intern();
// intern()方法会把字符串放到常量池中,如果常量池中已经存在了这个字符串,那么就返回常量池中的字符串
// 否则就把这个字符串放到常量池中,然后返回这个字符串
// 此时"ab"是不在常量池中,所以s就加入到常量池中了,它的引用地址和常量池中的字符串"ab"的引用地址是一样的了
// 所以 s == "ab" 成立
System.out.println(s == "ab"); // true
System.out.println(s == s2);// true
// 这是"aaa"在编译时已经在常量池中了
String b1 = new String("aaa");
// b1.intern()方法会把字符串放到常量池中,如果常量池中已经存在了这个字符串,那么就返回常量池中的字符串
// 常量池中已经存在了这个字符串"aaa",所以返回的是常量池中引用的"aaa"地址,而b1不会发生变化
String b2 = b1.intern();
System.out.println(b1 == "aaa");// false
System.out.println(b1 == b2); // false
}
}
回答之前说的面试题
import java.util.*;
public class Main {
public static void main(String[] args) {
String s1 = "a";
String s2 = "b";
String s3 = "a" + "b";
String s4 = s1 + s2;
String s5 = "ab";
String s6 = s4.intern();
// 问
System.out.println(s3 == s4); //false,s3在串池中,s4在堆中
System.out.println(s3 == s5); //true,都在串池中
System.out.println(s3 == s6); //true,都在串池中
String x2 = new String("c") + new String("d");
String x1 = "cd";
x2.intern();
// 问,如果调换了【最后两行代码】的位置呢,如果是jdk1.6呢
System.out.println(x1 == x2); // false,x1在串池中,x2在堆中
// 如果调换最后两行代码的位置,结果是什么呢?
// 答案是true,因为x2调用intern()方法后,发现串池中没有"cd",那么x2就加入到了串池中
// x1就会到串池中引用"cd"对象
// 如果是jkd1.6
// 答案是false,因为x2不会加入到串池中,而是创建一个新对象加入到串池中,x2仍然在堆中
}
}
串池在内存中的位置
在Java中,字符串池是存储字符串字面量的一种特殊 的内存区域。字符串池位于堆内存中,是堆内存中的一部分。堆内存是JVM用于存储对象实例的区域,而字符串池是堆内存中专门用于存储字符串字面量的一部分。
当你创建字符串字面量是,例如使用双引号括起来的字符串常量("hello"),这些字符串穿常量会首先被存储在字符串池中。如果在程序的其他地方创建相同内容的字符串穿常量,Java会检查字符串池,如果已经存在相同内容的字符串,就会重用池中的字符串对象,而不会创建新的对象。
StringTable 垃圾回收
串池在内存不够用时也会产生垃圾回收。
我们通过一个例子来演示串池的垃圾回收
/**
* 演示 StringTable 垃圾回收
* -Xmx10m -XX:+PrintStringTableStatistics -XX:+PrintGCDetails -verbose:gc
*/
public class Demo1_7 {
public static void main(String[] args) throws InterruptedException {
int i = 0;
try {
} catch (Throwable e) {
e.printStackTrace();
} finally {
System.out.println(i);
}
}
}
通过打印出来的串池日志我们可以发现,此时串池中对象的数量只有1777
StringTable statistics:
Number of buckets : 60013 = 480104 bytes, avg 8.000
Number of entries : 1777 = 42648 bytes, avg 24.000
Number of literals : 1777 = 179776 bytes, avg 101.168
然后我们加入10000个字符串对象到串池中
public class Demo1_7 {
public static void main(String[] args) throws InterruptedException {
int i = 0;
try {
for (int j = 0; j < 10000; j++) { // j=100, j=10000
String.valueOf(j).intern();
i++;
}
} catch (Throwable e) {
e.printStackTrace();
} finally {
System.out.println(i);
}
}
}
在打印日志我们可以发现只有7796个对象,说明有些对象已经被垃圾回收掉了。
StringTable statistics:
Number of buckets : 60013 = 480104 bytes, avg 8.000
Number of entries : 7796 = 187104 bytes, avg 24.000
Number of literals : 7796 = 468768 bytes, avg 60.129
StringTable 性能调优
StringTable本质上是一个哈希表,哈希表的大小越大,查询某个key花费的时间越小,相反,哈希表大小越小,查询某个key花费的时间越长。
我们可以通过设置值StringTable的大小来提高性能。
举个例子:
/**
* 演示串池大小对性能的影响
* -Xms500m -Xmx500m -XX:+PrintStringTableStatistics -XX:StringTableSize=1009
*/
public class Demo1_24 {
public static void main(String[] args) throws IOException {
try (BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream("linux.words"), "utf-8"))) {
String line = null;
long start = System.nanoTime();
while (true) {
line = reader.readLine();
if (line == null) {
break;
}
line.intern();
}
System.out.println("cost:" + (System.nanoTime() - start) / 1000000);
}
}
}
我们要读取一个有仅500000个单词的文件,我们要读取文件中的每一个字符串,然后将读取到的每一个字符串加入到串池中,然后计算程序总花费时间。
如果我们将StringTable大小设置为200000个,则总花费时间为92ms。
如果我们将StringTable大小设置为2000个,则总花费时间为1436ms。
通过结果我们可以证实StringTable大小关乎程序执行性能。
如果我们的程序中有大量的字符串对象被创建,我们要考虑是否将字符串对象加入到串池中,从而减少内存占用。
举个例子:
package cn.itcast.jvm.t1.stringtable;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.List;
/**
* 演示 intern 减少内存占用
* -XX:StringTableSize=200000 -XX:+PrintStringTableStatistics
* -Xsx500m -Xmx500m -XX:+PrintStringTableStatistics -XX:StringTableSize=200000
*/
public class Demo1_25 {
public static void main(String[] args) throws IOException {
List<String> address = new ArrayList<>();
System.in.read();
for (int i = 0; i < 10; i++) {
try (BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream("linux.words"), "utf-8"))) {
String line = null;
long start = System.nanoTime();
while (true) {
line = reader.readLine();
if (line == null) {
break;
}
address.add(line);
}
System.out.println("cost:" + (System.nanoTime() - start) / 1000000);
}
}
System.in.read();
}
}
上面这个代码每次循环都会读取500000个字符串对象,并且加入adderss集合中,然后我们打开Java VisualVM工具 ,查看Java程序运行情况。
我们发现在还没开始读入文件之前,字符串对象只占了几兆。
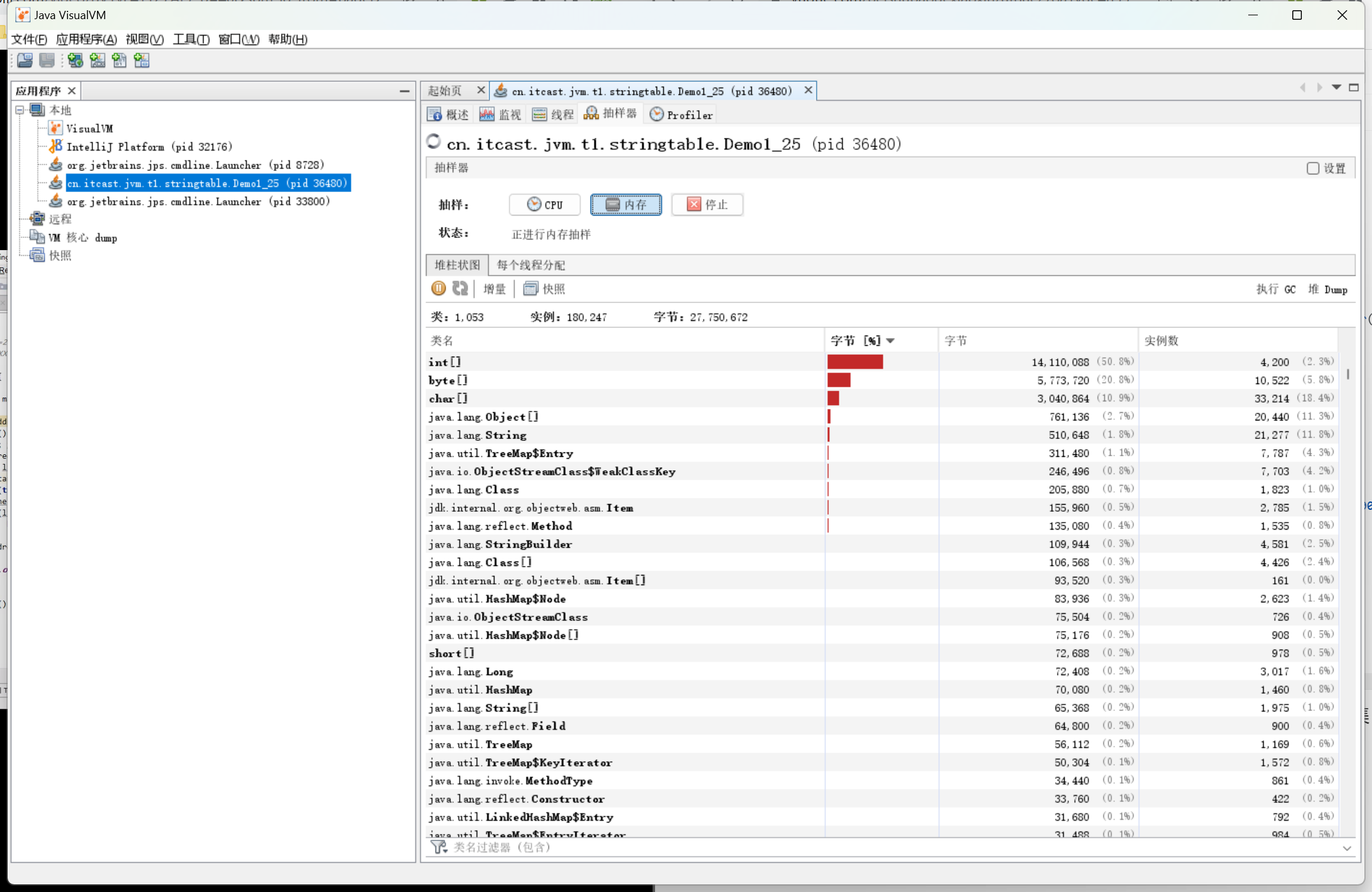
在读完文件之后,字符串对象占用了几百M,占用内存空间非常大。
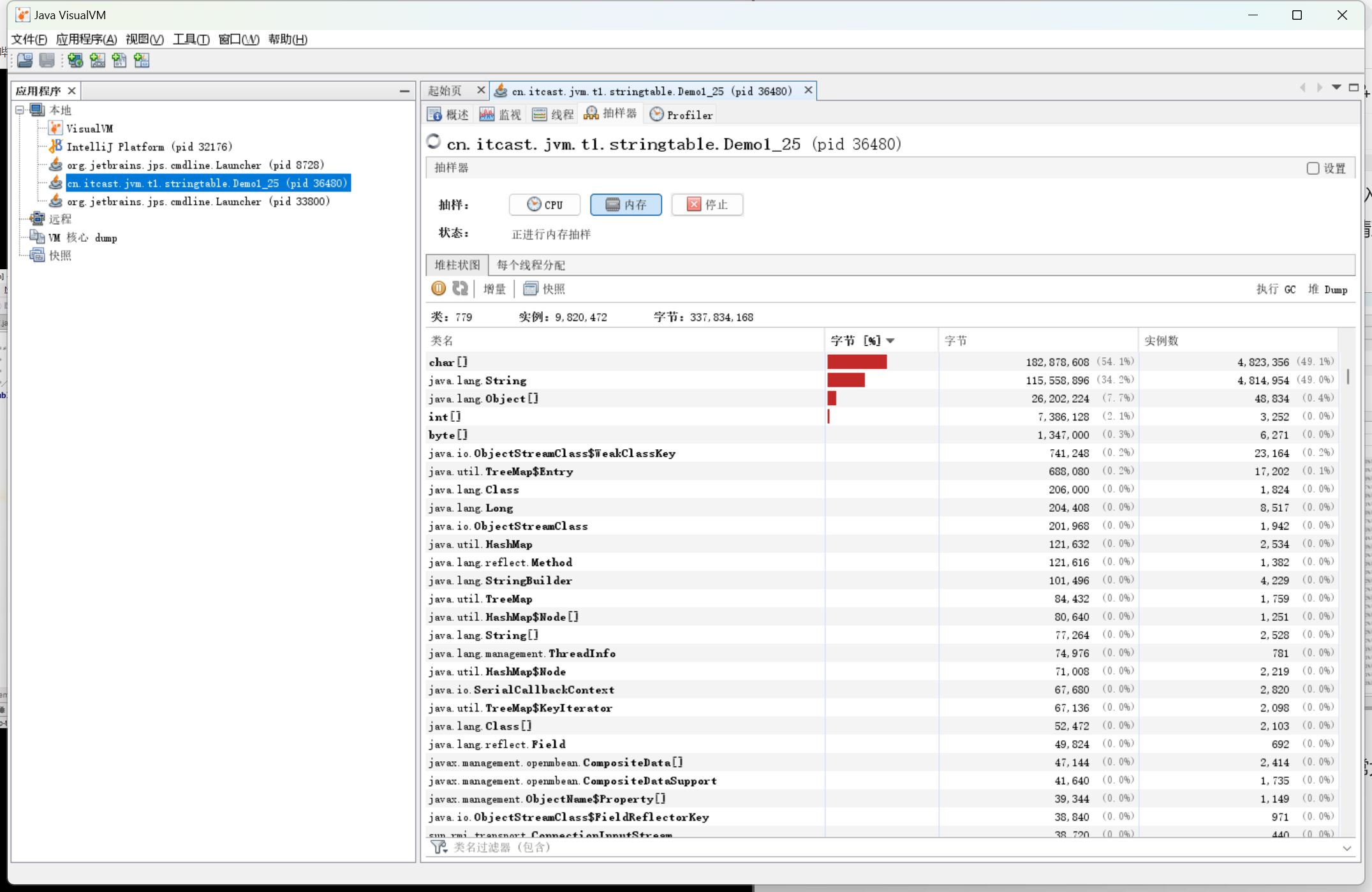
所以,为了减少对内存的占用,我们可以将字符串对象加入到串池中,重复使用相同的字符串对象。
address.add(line.intern()); // 修改代码,将字符串对象加入串池中
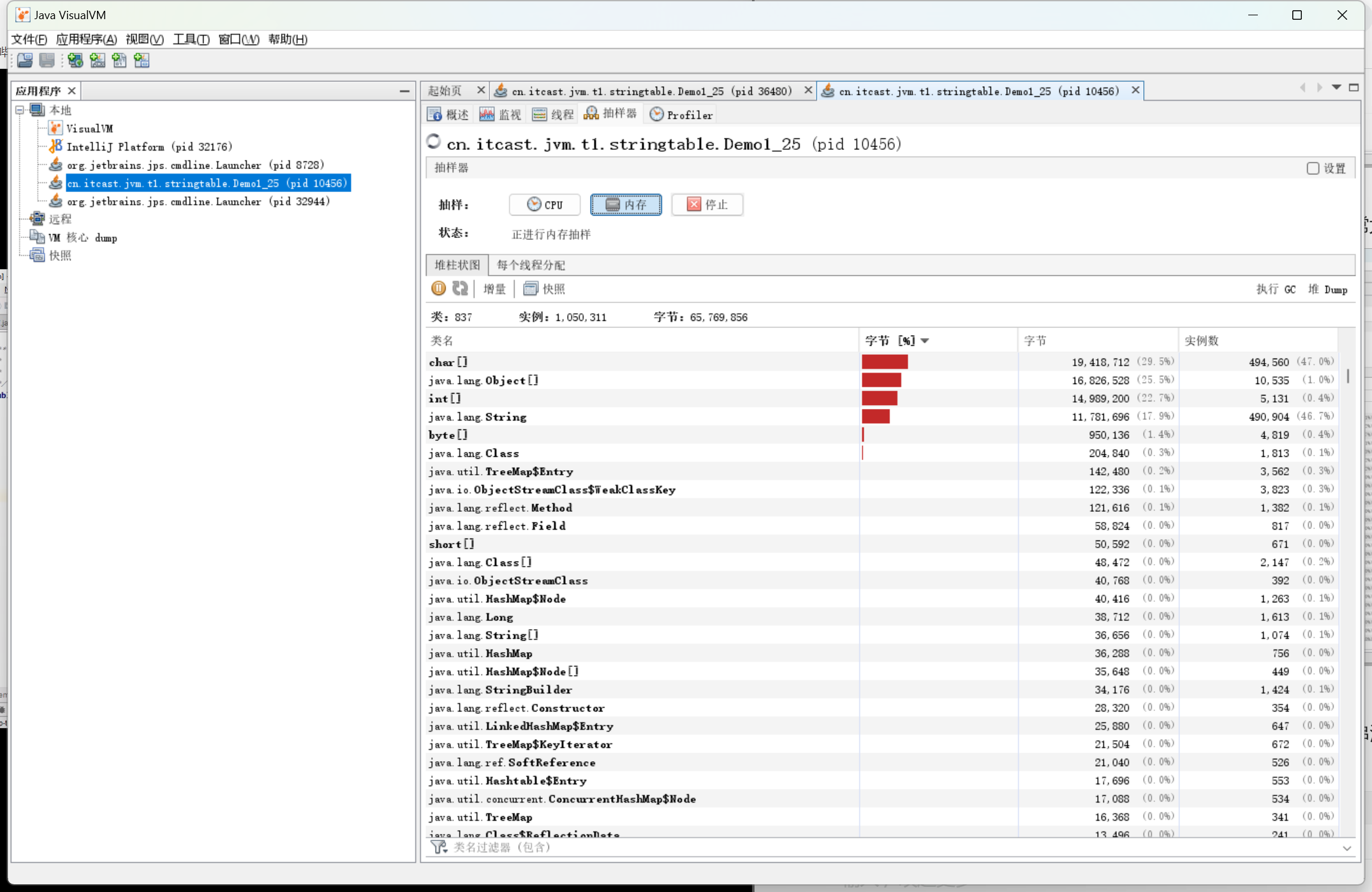
之后我们发现字符串对象只占用了几十M,非常好地解决了内存占用问题。
直接内存
直接内存通过指的是在Java中地java.nio包下的ByteBuffer。它与传统的Java堆内存有所不同。在Java中,传统的对象通常分配在堆内存中,而直接内存是通过本地方法库直接分配的,不受JVM的垃圾回收管理。
直接内存(Direct Memory)通常指的是在Java中的java.nio包下的ByteBuffer。它与传统的Java堆内存有所不同。在Java中,传统的对象通常分配在堆内存中,而直接内存是通过本地方法库直接分配的,不受Java虚拟机(JVM)的垃圾回收管理。
主要的类是java.nio.ByteBuffer,它提供了对直接字节缓冲区的支持。通过allocateDirect方法,可以在直接内存中分配缓冲区。与传统的堆内存缓冲区不同,直接内存缓冲区的生命周期不受Java堆内存管理的限制,因此不会受到Java垃圾回收的影响。
直接内存的使用有一些优势,例如:
- 零拷贝: 直接内存可以通过零拷贝技术来提高I/O操作的效率。对于直接内存,数据可以直接在Java虚拟机之外进行处理,而无需将数据复制到堆内存中。
- 减少垃圾回收压力: 直接内存的分配和释放通常不受Java垃圾回收的控制,因此可以减少垃圾回收带来的停顿时间。
- 内存映射文件: 直接内存可以与内存映射文件结合使用,实现文件和内存的直接映射,提高文件 I/O 操作的效率。
然而,直接内存也有一些潜在的问题,例如:
- 分配和释放成本: 直接内存的分配和释放通常比堆内存更昂贵,因此在某些情况下可能不适合频繁的小规模分配和释放操作。
- 不受垃圾回收管理: 尽管不受Java垃圾回收的管理,但在某些情况下,可能会由于缺乏垃圾回收而导致内存泄漏。
使用直接内存需要谨慎,并根据具体的场景和需求来选择。在大多数情况下,直接内存适用于需要处理大量数据的场景,例如网络编程、文件 I/O 操作等。
零拷贝
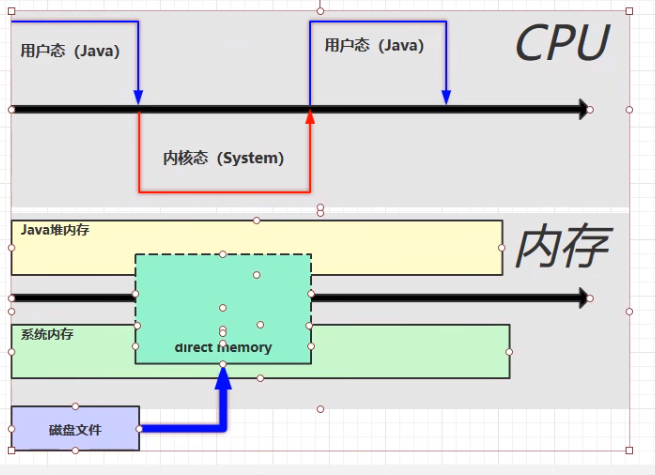
首先我们来说一下正常Java程序读取磁盘文件的流程:
- Java程序先由用户态转为内核态,因为设计到磁盘的东西需要操作系统专门处理
- 操作系统开始读取磁盘文件到系统内存,然后转为用户态
- Java程序没办法直接使用系统内存,因为Java程序有自己的虚拟机内存,JVM为了方便管理自己的内存,所以不能直接使用系统内存。所以Java程序需要将系统内存中的文件复制一份到Java程序的堆内存中。然后Java程序才可以读取堆内存中的文件。
而对于直接内存,Java程序可以直接访问而不需要在复制到堆内存中,所以提交了效率。
代码举例:
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.nio.ByteBuffer;
import java.nio.channels.FileChannel;
/**
* 演示 ByteBuffer 作用
*/
public class Demo1_9 {
static final String FROM = "D:\\software\\a.txt";
static final String TO = "D:\\software\\b.txt";
static final int _1Mb = 1024 * 1024;
public static void main(String[] args) {
io(); // io 用时:1535.586957 1766.963399 1359.240226
directBuffer(); // directBuffer 用时:479.295165 702.291454 562.56592
}
private static void directBuffer() {
long start = System.nanoTime();
try (FileChannel from = new FileInputStream(FROM).getChannel();
FileChannel to = new FileOutputStream(TO).getChannel();
) {
ByteBuffer bb = ByteBuffer.allocateDirect(_1Mb); // 直接缓冲区
while (true) {
int len = from.read(bb);
if (len == -1) {
break;
}
bb.flip();
to.write(bb);
bb.clear();
}
} catch (IOException e) {
e.printStackTrace();
}
long end = System.nanoTime();
System.out.println("directBuffer 用时:" + (end - start) / 1000_000.0);
}
private static void io() {
long start = System.nanoTime();
try (FileInputStream from = new FileInputStream(FROM);
FileOutputStream to = new FileOutputStream(TO);
) {
byte[] buf = new byte[_1Mb];
while (true) {
int len = from.read(buf);
if (len == -1) {
break;
}
to.write(buf, 0, len);
}
} catch (IOException e) {
e.printStackTrace();
}
long end = System.nanoTime();
System.out.println("io 用时:" + (end - start) / 1000_000.0);
}
}
直接内存溢出
直接内存不归JVM管理,是不是也会内存溢出呢?
答案是会的,直接内存用的是系统内存,系统内存大小受本机限制,所以无限制地使用就会导致内存溢出。
举个例子:
/**
* 演示直接内存溢出
*/
public class Demo1_10 {
static int _100Mb = 1024 * 1024 * 100;
public static void main(String[] args) {
List<ByteBuffer> list = new ArrayList<>();
int i = 0;
try {
while (true) {
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(_100Mb);
list.add(byteBuffer);
i++;
}
} finally {
System.out.println(i);
}
// 方法区是jvm规范, jdk6 中对方法区的实现称为永久代
// jdk8 对方法区的实现称为元空间
}
}
报错结果:java.lang.OutOfMemoryError: Direct buffer memory
直接内存释放原理
ByteBuffer的实现类内部使用了 Cleaner(虚引用)来检测 ByteBuffer 对象,一旦 ByteBuffer 对象被垃圾回收,那么就会由 ReferenceHandler 线程通过 Cleaner 的 clean 方法调用 FreeMemory来释放直接内存。
这里看的不是非常明白,需要在学一些垃圾回收和Java反射等知识再回来学习。
Unsafe类提供了直接操作内存和执行一些底层操作的功能。是一个专门为Java核心库、以及一些其他底层库设计的工具,而不是为普通应用程序开发者提供的公共API。Java官方并不推荐直接使用,因为它包含一些不安全的操作,容易导致内存泄漏、越界访问等问题。
Exception in thread "main" java.lang.SecurityException: Unsafe
所以我们要想使用它的话需要通过反射。
要想完成直接内存的释放,我们需要主动调用freeMemory() 方法。
ByteBuffer.allocateDirect();我们深入观察申请直接内存方法的源码,可以发现底层就是使用了Unsafe类来完成对直接内存的分配和使用,然后创建了一个Cleaner对象,当Cleaner发现发现ByteBuffer对象被垃圾回收之后,就开启线程执行FreeMemory方法来释放直接内存。
/**
* 直接内存分配的底层原理:Unsafe
*/
public class Demo1_27 {
static int _1Gb = 1024 * 1024 * 1024;
public static void main(String[] args) throws IOException {
Unsafe unsafe = getUnsafe();
// 分配内存
long base = unsafe.allocateMemory(_1Gb);
unsafe.setMemory(base, _1Gb, (byte) 0);
System.in.read();
// 释放内存
unsafe.freeMemory(base);
System.in.read();
}
public static Unsafe getUnsafe() {
try {
Field f = Unsafe.class.getDeclaredField("theUnsafe");
f.setAccessible(true);
Unsafe unsafe = (Unsafe) f.get(null);
return unsafe;
} catch (NoSuchFieldException | IllegalAccessException e) {
throw new RuntimeException(e);
}
}
}
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!