Python中Pandas详解之数据结构
文章目录
Pandas 数据分析
Pandas 简介
Pandas是Python生态下的一个数据分析包,他对于Python数据分析的意义是十分重大的,他与NumPy的不同之处是支持图标和混杂数据运算的,而NumPy是基于数组构建的内容,他的各种图像生成也十分方便,并且支持各种数据存储文件、数据库、甚至Web中读取数据
Pandas 安装
和NumPy的安装一样使用
pip install pandas
命令安装即可
Series 类型数据
Series是Pandas的核心数据结构之一,也是理解DataFrame的基础
Series的创建
Series的中文翻译是系列,是一种类似于一维数组的结构,是数组和索引构成的
import pandas as pd
pd.Series(data, index = index)
在这两个参数中,data是数据源,可以是整数,字符串等,而默认索引就是数据的标签(label)
例如
a = pd.Series([1, 2, 5, 3, 2])
print(a)
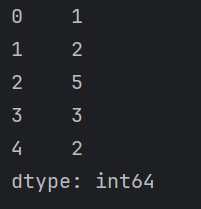
需要注意的是Series的内部是基于NumPy的N维数组构建的,因此内部的数据需要统一
其次Series增加对应的label作为索引,如果没有显示添加索引,Python会自动添加一个0到n-1的索引值,通常都是索引在左,数值在右边
当然,其中的索引也可以被更改为其他的内容,是类似于Python中的字典
Series还提供了一些简单的统计方法,describe()
例如
print(a.describe())
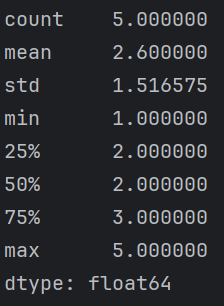
| 参数 | 说明 |
|---|---|
| count | 数据个数 |
| mean | 均值 |
| std | 均方差 |
| min | 最小值 |
| max | 最大值 |
| 25% | 前25%的数据分位数 |
| 50% | 前50%的数据分位数 |
| 75% | 前75%的数据分位数 |
Series的访问
第一种最简单的访问方式就是通过下标存取Series对象内部的元素
当然也可以用label进行访问
需要说明的是,可以按照任意顺序一次访问多个数据
例如
print(a[[1,2,3]])
需要说明的是,同时访问多个数值就需要以列表的形式出现
对于两个Series对象还可以通过append()方法进行叠加操作,用来合并对象
但是当叠加对象时,索引就会混乱,因此当叠加时可以采用ignore_index=True,这样就可以重新添加索引
例如
a1.append(a2,ignore_index=True)
Series 中向量化操作与布尔索引
类似于NumPy,Pandas也支持广播操作,也就是加减乘除一个标量,
同样的Series也支持用布尔表达式提取符合条件的数值,而且Series也可以作为NumPy函数的一个参数进行数据运算
Series的切片
对于Series也可以使用切片操作选取处理其中的值,返回值依然是Series的对象
需要注意的时,与数字的切片不同,用label切片不是左闭右开,而是两边都是闭区间
Series的缺失值
在数据处理中会遇到缺失值,在Pandas会用NaN来表示
我们可以使用Pandas中的isnull()和notnull()来检测是否含有缺失值
对于isull()方法,他的返回值是一个布尔值Series对象,True表示为缺失值,False表示不是缺失值,notnull正好与之相反
这对海量数据的操作是十分友好的
Series的增与删
当我们要删除Series中的数据时,使用drop方法即可,他的参数就是label,也可以是列表,用于删除多项元素
添加数据就可以使用我们之前所说的append方法即可
Series的name
除了index和value,还有两个属性,是name和index.name
name可以立即为数值(value)列的名称,index可以理解为一个特殊的索引列,index.name就是索引列(index)的名称,就相当于是列名的作用
默认情况下都被设置为None,我们也可以通过代码进行直接赋值
DataFrame 数据类型
如果Series是Excel中的一列,那DataFrame就是Excel中的一张表
DataFrame的创建
DataFrame实际上可以理解为数据结构中带标签的二维数组,他由若干个Series构成
构建DataFrame的最常用的方法是先构建一个由列表或NumPy数组组成的字典,再将字典作为DataFrame中的参数
例如
df = pd.DataFrame({'name':['summer','morty','rick','jerry']})
print(df)
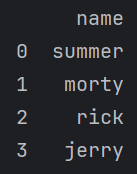
这样我们就可以用若干字典的项来构建一张表了,左边的数字就是行数
例如
df = pd.DataFrame({'name': ['summer', 'morty', 'rick', 'jerry'],
'age': [17 , 14, 60,35],
'gender': ['female', 'male', 'male', 'male']})
print(df)
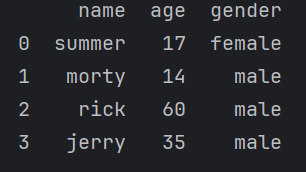
我们也可以通过NumPy的数组生成DataFrame,我们也可以在创建DataFrame时指定列名和行名
例如
df2 = pd.DataFrame(data,columns=['one','two'],index=['a','b'])
本质上,DataFrame是由若干个Series构成的,那么Series就是DataFrame的天然数据源,同样的DataFrame也支持NumPy转置操作,也可以使用transpose()方法完成转置
DataFrame的访问
访问DataFrame的列很方便,因为DataFrame提供了columns属性,可以通过具体的列名称进行访问
例如
df.columns # 访问列名
df.columns.values[0] # 访问元素
DataFrame的一个神奇的地方在于,他可以把列明当作为对象中的一个元素进行获取
例如
df.列名
想要获取切片就和NumPy的数组操作时一模一样的,这里不多赘述
DataFrame的删除
类似于Series,删除操作也是使用drop方法删除一行或一列
我们也可以使用全局内置函数del,直接在DF中删除某行某列,因为drop方法是生成新的DF
DataFrame的添加
添加行
我们直接创建一个空的DF对象,再利用for循环逐个添加新的行即可
例如
df = pd.DataFrame(columns = ['1','2'])
for index in range(5):
df.loc[index] = ['name '+str(index)] + list(randint(10, size=2))
使用loc方法就可以添加一个新的行,index就是DF对象中原先没有的行索引,再进行赋值
我们还可以使用append方法,可以同时批量添加多行数据,类似于NumPy的vstack,垂直堆叠的效果
添加列
和添加行相比就更加简单,实际上就是添加了一个列的名称,再对其内容进行赋值,我们也可以使用concat方法,类似于hstack,水平堆叠,将两个DF对象进行拼接
对于以上两种添加方法,也可以设置忽略原有的索引,进行重新定义索引的编号
对于Pandas的操作指令还有非常多,我们需要在实践中不断掌握,慢慢摸索,越用越熟,越用越精 感谢各位的支持,如果你发现文章中有任何不严谨或者需要补充的部分,欢迎在评论区指出
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!