SpringBoot--入门使用
目录
SpringBoot简介
??Spring Boot是由Pivotal团队提供的一套开源框架,可以简化spring应用的创建及部署。它提供了丰富的Spring模块化支持,可以帮助开发者更轻松快捷地构建出企业级应用。Spring Boot通过自动配置功能,降低了复杂性,同时支持基于JVM的多种开源框架,可以缩短开发时间,使开发更加简单和高效。
众所周知 Spring 应用需要进行大量的配置,各种 XML 配置和注解配置让人眼花缭乱,且极容易出错,因此 Spring 一度被称为“配置地狱”。为了简化 Spring 应用的搭建和开发过程,Pivotal 团队在 Spring 基础上提供了一套全新的开源的框架,它就是Spring Boot。
只是为了提升Spring开发者的工具,特点:敏捷式、快速开发。
什么是SpringBoot
SpringBoot 基于 Spring 开发。SpringBoot 本身并不提供 Spring 框架的核心特性以及扩展功能,也就是说,它并不是用来替代 Spring 的解决方案,而是和 Spring 框架紧密结合用于提升 Spring 开发者体验的工具。
??关于 SpringBoot 有一句很出名的话就是约定大于配置。采用 Spring Boot 可以大大的简化开发模式,它集成了大量常用的第三方库配置,所有你想集成的常用框架,它都有对应的组件支持,例如 Redis、MongoDB、Jpa、kafka,Hakira 等等。SpringBoot 应用中这些第三方库几乎可以零配置地开箱即用,大部分的 SpringBoot 应用都只需要非常少量的配置代码,开发者能够更加专注于业务逻辑。
相比Spring,SpringBoot的有哪些特点
-
独立运行的 Spring 项目? Spring Boot 可以以 jar 包的形式独立运行,Spring Boot 项目只需通过命令“ java–jar xx.jar” 即可运行。
-
内嵌 Servlet 容器? ? Spring Boot 使用嵌入式的 Servlet 容器(例如 Tomcat、Jetty 或者 Undertow 等),应用无需打成 WAR 包 。
-
提供 starter 简化 Maven 配置? ?Spring Boot 提供了一系列的“starter”项目对象模型(POMS)来简化 Maven 配置。
-
提供了大量的自动配置? ?Spring Boot 提供了大量的默认自动配置,来简化项目的开发,开发人员也通过配置文件修改默认配置。
-
自带应用监控? Spring Boot 可以对正在运行的项目提供监控。
-
无代码生成和 xml 配置? Spring Boot 不需要任何 xml 配置即可实现 Spring 的所有配置。
SpringBoot入门使用
创建SpringBoot项目
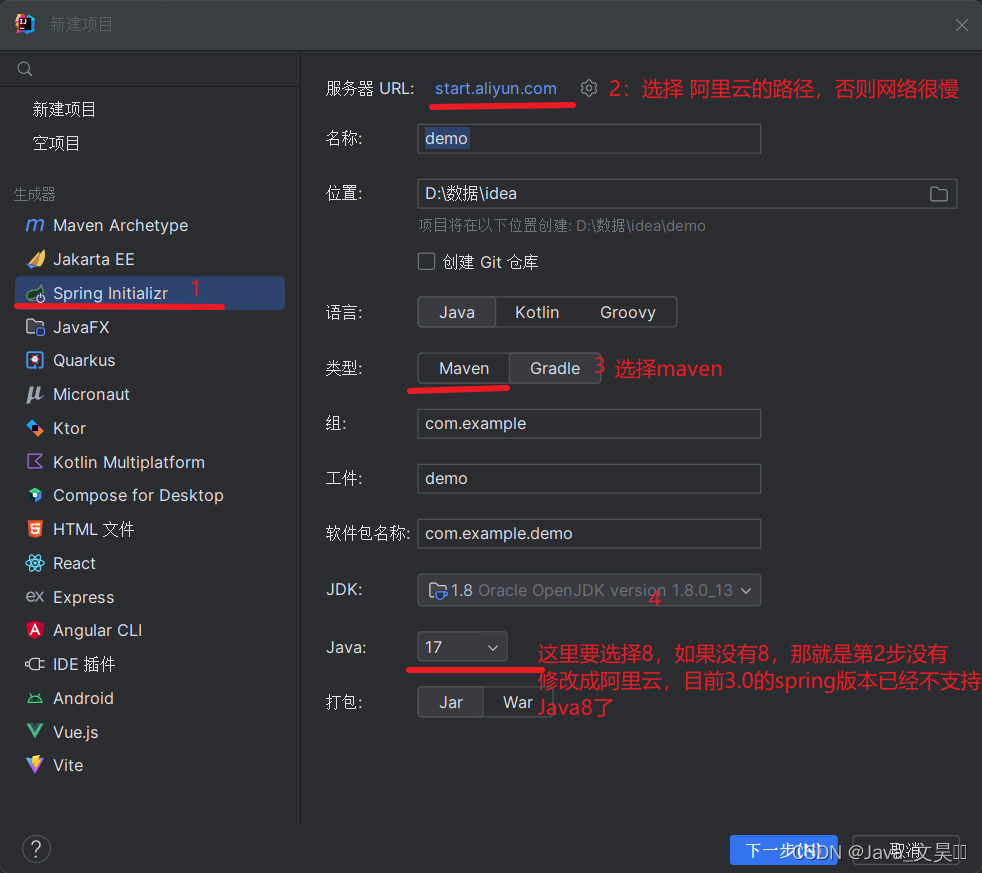
目录介绍,这里有一个忘记标记了,springboot启动成功后,默认访问static种的index.html文件

?在springboot之中,默认的总配置文件是properties文件,但是properties文件的格式并不美观,所以我们可以将其修改成yml文件

如下图

配置项目名称
首先springboot访问后端请求是不需要添加项目名称的,但是如果非要添加的话也可以,只需要在yml文件种添加以下代码
#spring启动项目访问后台请求是不需要加上项目名字的,如果需要加上项目名字也可以
#项目名
# servlet:
# context-path: 项目名
# 集成数据库配置文件启动SpringBoot
SpringBoot内嵌入了一个tomcat如果想要启动项目,需要找到我们的SpringBoot启动类,直接启动即可

出现以下效果代表启动成功了
SpringBoot整合依赖,配置开发环境
SpringBoot整合jdbc
导入所需依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.44</version>
</dependency>配置.yml总配置文件
spring:
datasource:
url: jdbc:mysql://localhost:3306/bookshop?useUnicode=true&characterEncoding=UTF-8&SSL=false
username: root
password: 123456
# 配置驱动
driver-class-name: com.mysql.jdbc.Driver此时我们已经能够连接mysql了,但是没有配置好我们的mybatis持久层框架
SpringBoot整合mybatis
导入依赖
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.3.0</version>
</dependency>配置SpringBoot总配置文件
#mybatis配置
mybatis:
#配置SQL映射文件路径
mapper-locations: classpath:mapper/*.xml
#配置别名
type-aliases-package: com.wenhao.boot_1.pojo当我们配置好这一步之后,就可以连接数据库,生成对应的实体类以及对应的mapper文件了
在idea最右侧有一个火药桶样式的图标,点击它

写好配置信息后连接数据库

连接成功后,右键表格,点击图中的按钮,生成文件

然后就会出现这个界面
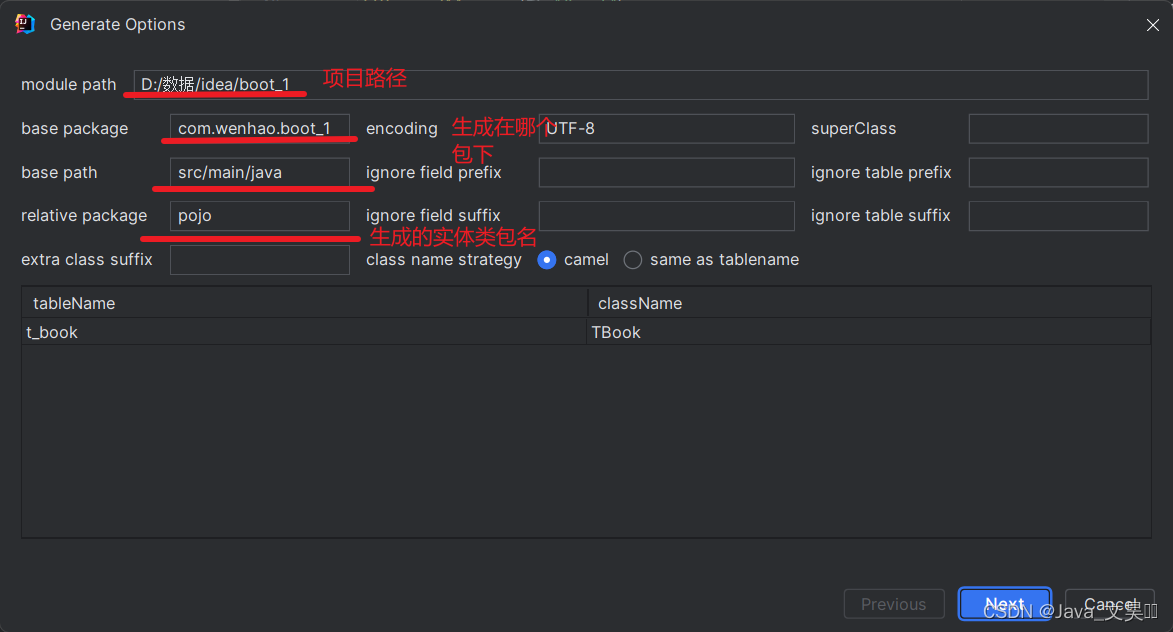
完成之后,我们对应的左侧目录就会在启动类所处的同级目录下生成相应的mapper文件和实体类,mapper类的映射文件则会生成在rescouce目录下

此时我们可以启动一下项目试试看看会不会报错
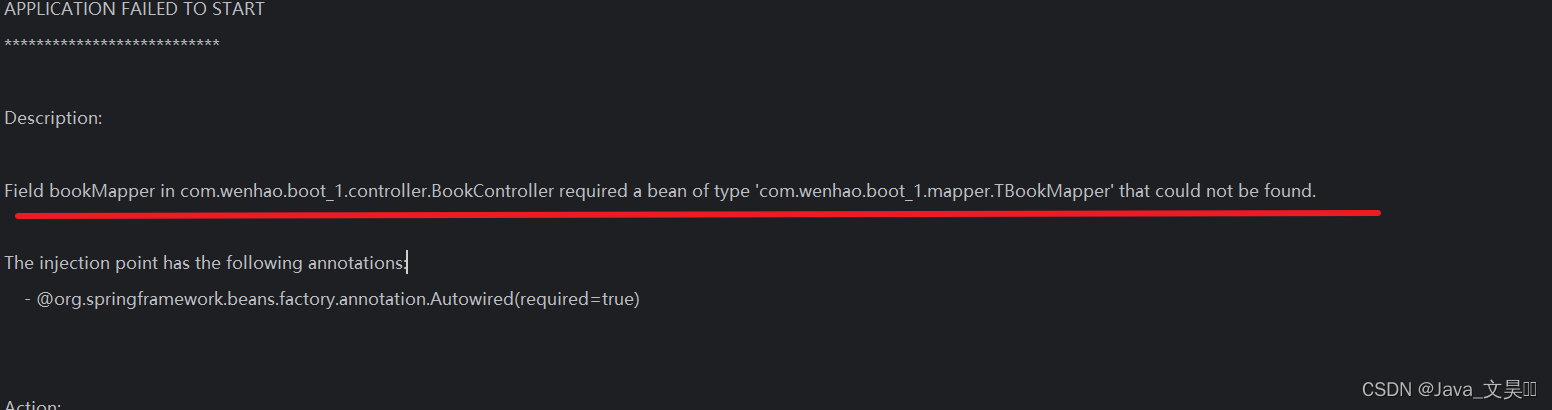
这个错误告诉我们在控制层的类中,需要一个mapper类,但是找不到那个mapper类,为什么呢,因为我们并没有配置扫描器呀,所以我们需要在启动类中配置mapper扫描器
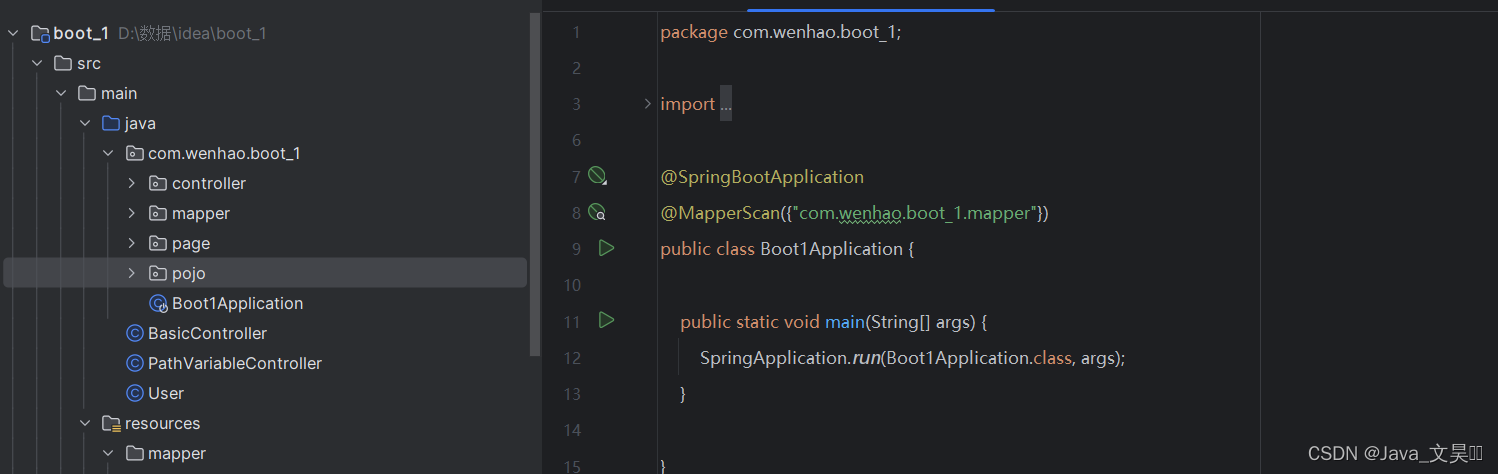
这个扫描器会自动扫描mapper包中,标注了@Repository注解的类,将其注入到其中,然后启动就不会报错了
配置开启log日志
在.yml文件中配置以下代码即可
#log日志配置
logging:
level:
#指定项目目录输入日志信息
com.wenhao.boot_1.mapper: debug测试,我自己写了一个查询方法,访问看看能不能拿到想要的数据

?在这里可以提一个小玩意

这个别名是从哪里来的呢?

就是这里,指定了在哪个包下面的类会生成一个别名?
SpringBoot配置分页插件
导入切面,以及分页依赖
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper-spring-boot-starter</artifactId>
<version>1.4.6</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>在.yml文件中配置分页参数
pagehelper:
# 指定sql方言
helperDialect: mysql
# 指定是否合理化查询
reasonable: true
# 表示是否支持通过方法参数来传递分页查询的参数,例如直接在方法中传入 pageNum 和 pageSize 参数。
supportMethodsArguments: true
#指定用于查询总数的 SQL 语句,通常是使用 count(*) 的方式来统计记录总数,但也可以自定义统计总数的 SQL 语句。
params: count=countSql
配置完成后,我们可以结合aop来使用,这样减少代码的重复
首先我们可以定义一个自定义的注解类
package com.wenhao.boot_1.page;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
@Target(ElementType.METHOD)
//这个注解代表这个注解只能标注在方法上
@Retention(RetentionPolicy.RUNTIME)
//这个注解代表,标注了这个注解的方法可以被反射读取信息
public @interface PageAnnotation {
}
然后再定义一个切面类来过滤请求
package com.wenhao.boot_1.page;
import com.github.pagehelper.Page;
import com.github.pagehelper.PageHelper;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.Around;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Pointcut;
import org.springframework.stereotype.Component;
/**
* 分页切面类,用于处理分页相关的逻辑
*/
@Aspect
@Component
public class PageAspect {
/**
* 切入点定义,指定使用 @PageAnnotation 注解的方法为切入点
*/
@Pointcut("@annotation(PageAnnotation)")
public void cut() {
}
/**
* 环绕通知,在切入点方法执行前后进行处理
* @param point 切入点信息
* @return 切入点方法的返回值
* @throws Throwable 异常
*/
@Around("cut()")
public Object aroundHandler(ProceedingJoinPoint point) throws Throwable {
// 获取切入点方法的参数
Object[] args = point.getArgs();
// 默认的分页信息对象
PageBean pageBean = new PageBean().setOpen(false);
// 遍历参数,找到类型为 PageBean 的参数
for (Object arg : args) {
if (arg instanceof PageBean) pageBean = (PageBean) arg;
}
// 使用 PageHelper 进行分页设置
PageHelper.startPage(pageBean.getPage(), pageBean.getRows(), pageBean.isOpen());
// 执行切入点方法
Object val = point.proceed();
// 如果开启了分页功能,则设置总记录数到 PageBean 对象中
if (pageBean.isOpen()) {
Page<?> page = (Page<?>) val;
pageBean.setTotal(page.getTotal());
}
// 返回切入点方法的返回值
return val;
}
}
最后还有一个pagebean实体类
package com.wenhao.boot_1.page;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.experimental.Accessors;
@Data
@NoArgsConstructor
@AllArgsConstructor
@Accessors(chain = true)
public class PageBean {
private Integer page = 1;
private Integer rows = 5;
private Long total = 0L;
private boolean open = true;
public int start() {
return (page - 1) * rows;
}
public int previous() {
return Math.max(this.page - 1, 1);
}
public int next() {
return Math.min(this.page + 1, maxPage());
}
public int maxPage() {
return (int) Math.ceil(this.total.intValue() / (this.rows * 1.0));
}
}
接下来我们可以在控制层测试一下
package com.wenhao.boot_1.controller;
import com.wenhao.boot_1.mapper.TBookMapper;
import com.wenhao.boot_1.page.PageAnnotation;
import com.wenhao.boot_1.page.PageBean;
import com.wenhao.boot_1.pojo.TBook;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
/**
* @ 用户 liwen
* @当前日期 2023/12/12
* @当前项目名称 boot_1
*/
@RestController
@RequestMapping("/book")
public class BookController {
@Autowired
private TBookMapper bookMapper;
@PageAnnotation
@RequestMapping("/query")
public List<TBook> list(PageBean pageBean){
List<TBook> selectbook = bookMapper.selectbook();
return selectbook;
};
}
往后台发送请求

可以看到此时我拿到的是第2页的数据,分页成功了
整合druid数据库连接池
各大数据库连接池对比,我只能说,阿里云开发值得信任
| 功能 | dbcp | druid | c3p0 | tomcat-jdbc | HikariCP |
|---|---|---|---|---|---|
| 是否支持PSCache | 是 | 是 | 是 | 否 | 否 |
| 监控 | jmx | jmx/log/http | jmx,log | jmx | jmx |
| 扩展性 | 弱 | 好 | 弱 | 弱 | 弱 |
| sql拦截及解析 | 无 | 支持 | 无 | 无 | 无 |
| 代码 | 简单 | 中等 | 复杂 | 简单 | 简单 |
| 更新时间 | 2019.02 | 2019.05 | 2019.03 | 2019.02 | |
| 最新版本 | 2.60 | 1.1.17 | 0.9.5.4 | 3.3.1 | |
| 特点 | 依赖于common-pool | 阿里开源,功能全面 | 历史久远,代码逻辑复杂,且不易维护 | 优化力度大,功能简单,起源于boneCP | |
| 连接池管理 | LinkedBlockingDeque | 数组 | FairBlockingQueue | threadlocal+CopyOnWriteArrayList |
导入依赖
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.2.15</version>
</dependency>在.yml文件中配置
spring:
datasource:
type: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://localhost:3306/bookshop?useUnicode=true&characterEncoding=UTF-8&SSL=false
username: root
password: 123456
# 配置驱动
driver-class-name: com.mysql.jdbc.Driver
druid:
#2.连接池配置
#初始化连接池的连接数量 大小,最小,最大
initial-size: 5
min-idle: 5
max-active: 20
#配置获取连接等待超时的时间
max-wait: 60000
#配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
time-between-eviction-runs-millis: 60000
# 配置一个连接在池中最小生存的时间,单位是毫秒
min-evictable-idle-time-millis: 30000
validation-query: SELECT 1 FROM DUAL
test-while-idle: true
test-on-borrow: true
test-on-return: false
# 是否缓存preparedStatement,也就是PSCache 官方建议MySQL下建议关闭 个人建议如果想用SQL防火墙 建议打开
pool-prepared-statements: true
max-pool-prepared-statement-per-connection-size: 20
# 配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙
filter:
stat:
merge-sql: true
slow-sql-millis: 5000
#3.基础监控配置
web-stat-filter:
enabled: true
url-pattern: /*
#设置不统计哪些URL
exclusions: "*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*"
session-stat-enable: true
session-stat-max-count: 100
stat-view-servlet:
enabled: true
url-pattern: /druid/*
reset-enable: true
#设置监控页面的登录名和密码
login-username: admin
login-password: admin
allow: 127.0.0.1
#deny: 192.168.1.100
#pagehelper分页插件配置
?Ok,大功告成,
启动SpringBoot项目访问Druid,访问地址:http://localhost:端口号/项目名称/druid/
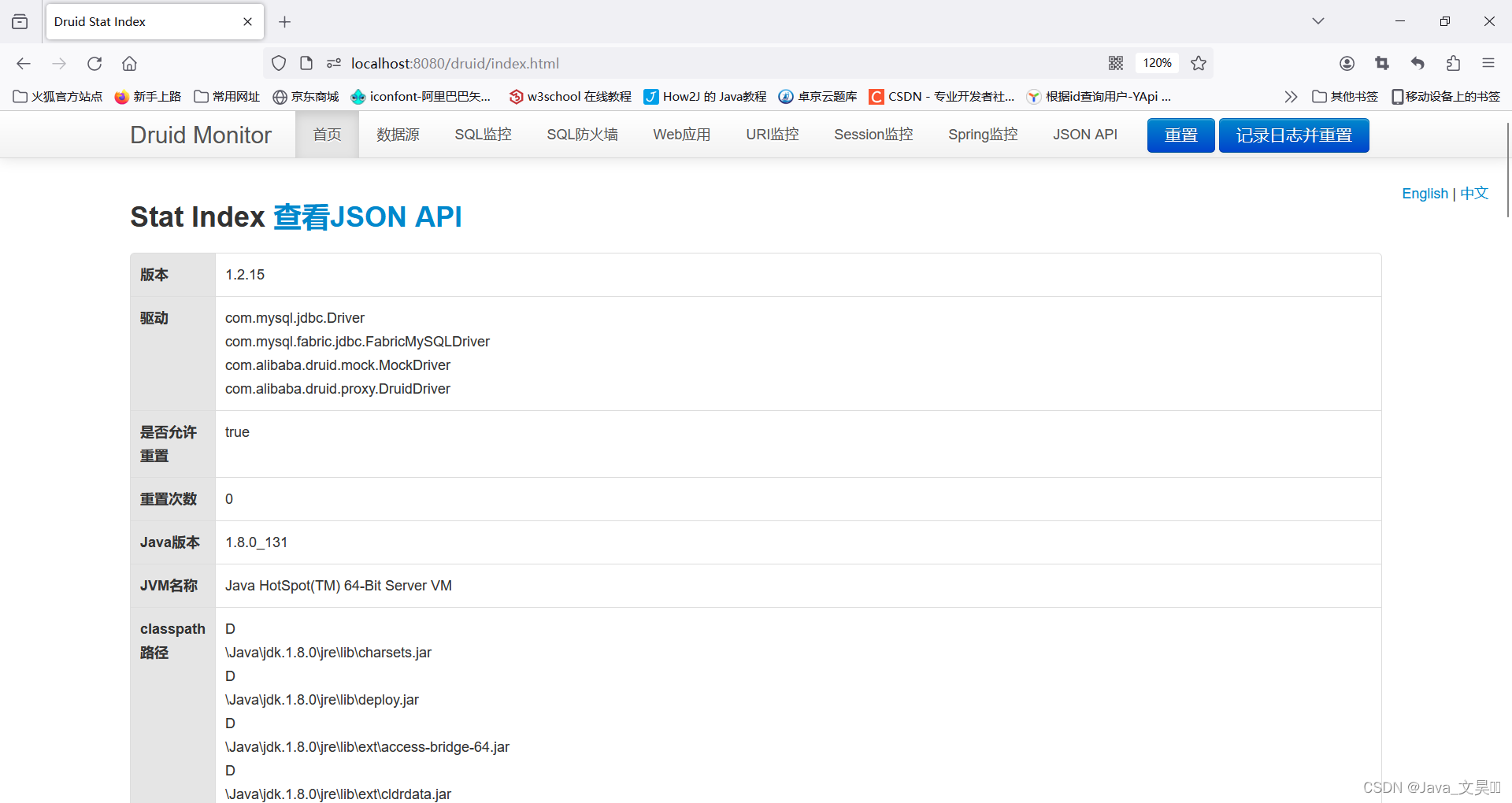
?在这里我们可以进行整个项目的监控,不得不感叹阿里云的强大
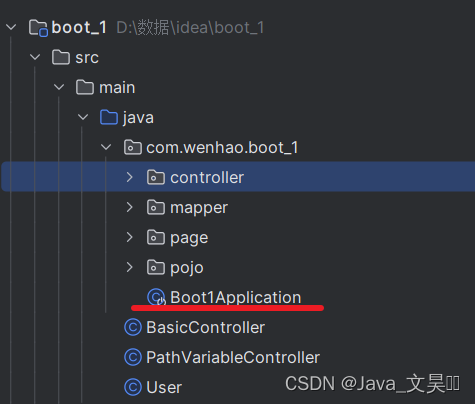
值得一提的是,在SpringBoot项目中,和springmvc相关的包都要处在和启动类同级的目录下,否则springBoot无法进行识别,如下图
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!