Stable Diffusion 基本原理
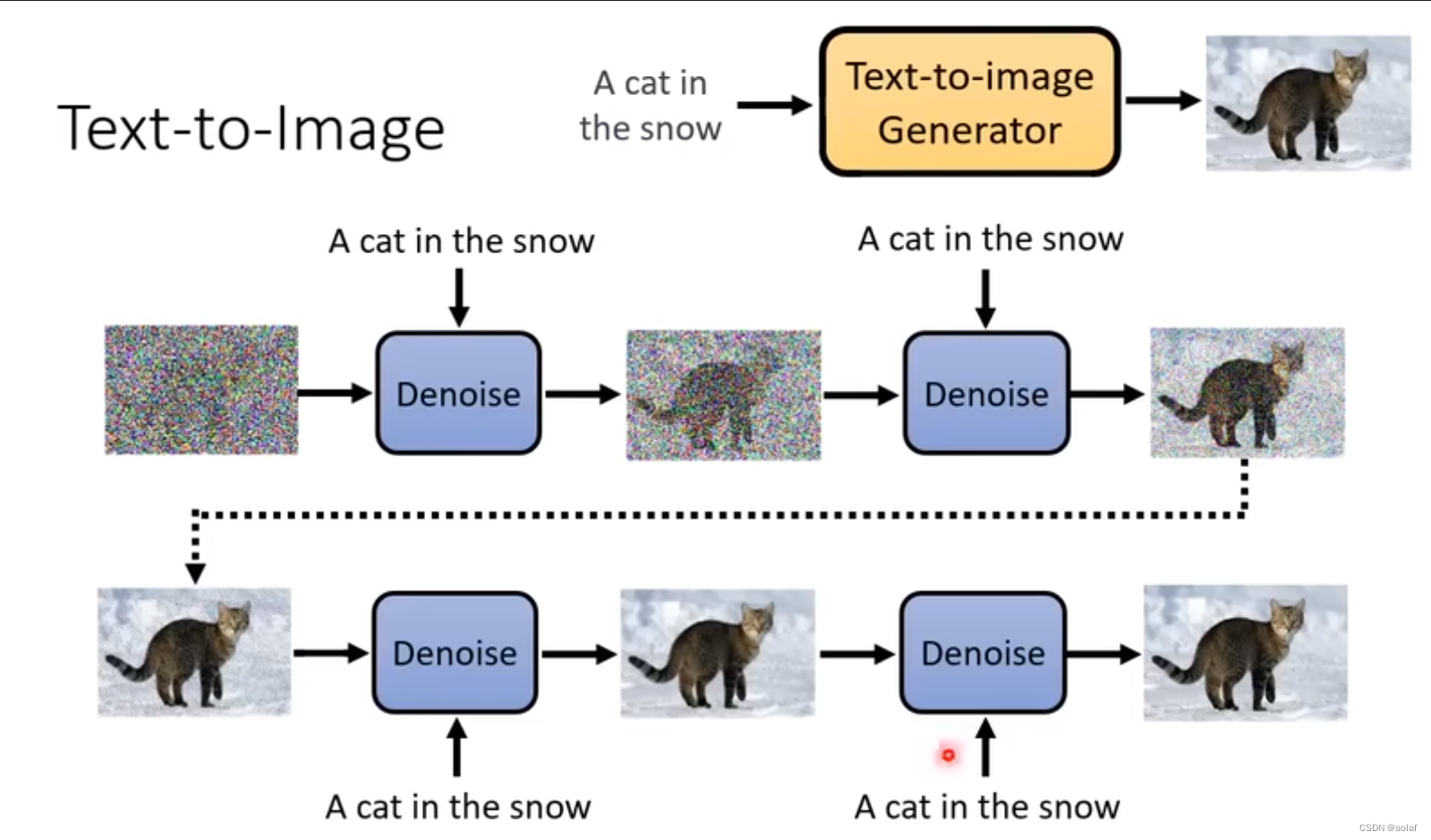
1 Diffusion Model的运作过程
输入一张和我们所需结果图尺寸一致的噪声图像,通过Denoise模块逐步减少noise,最终生成我们需要的效果图。
图中Denoise模块虽然是同一个,但是它会根据不同step的输入图像和代表noise严重程度的参数选择denoise的程度。
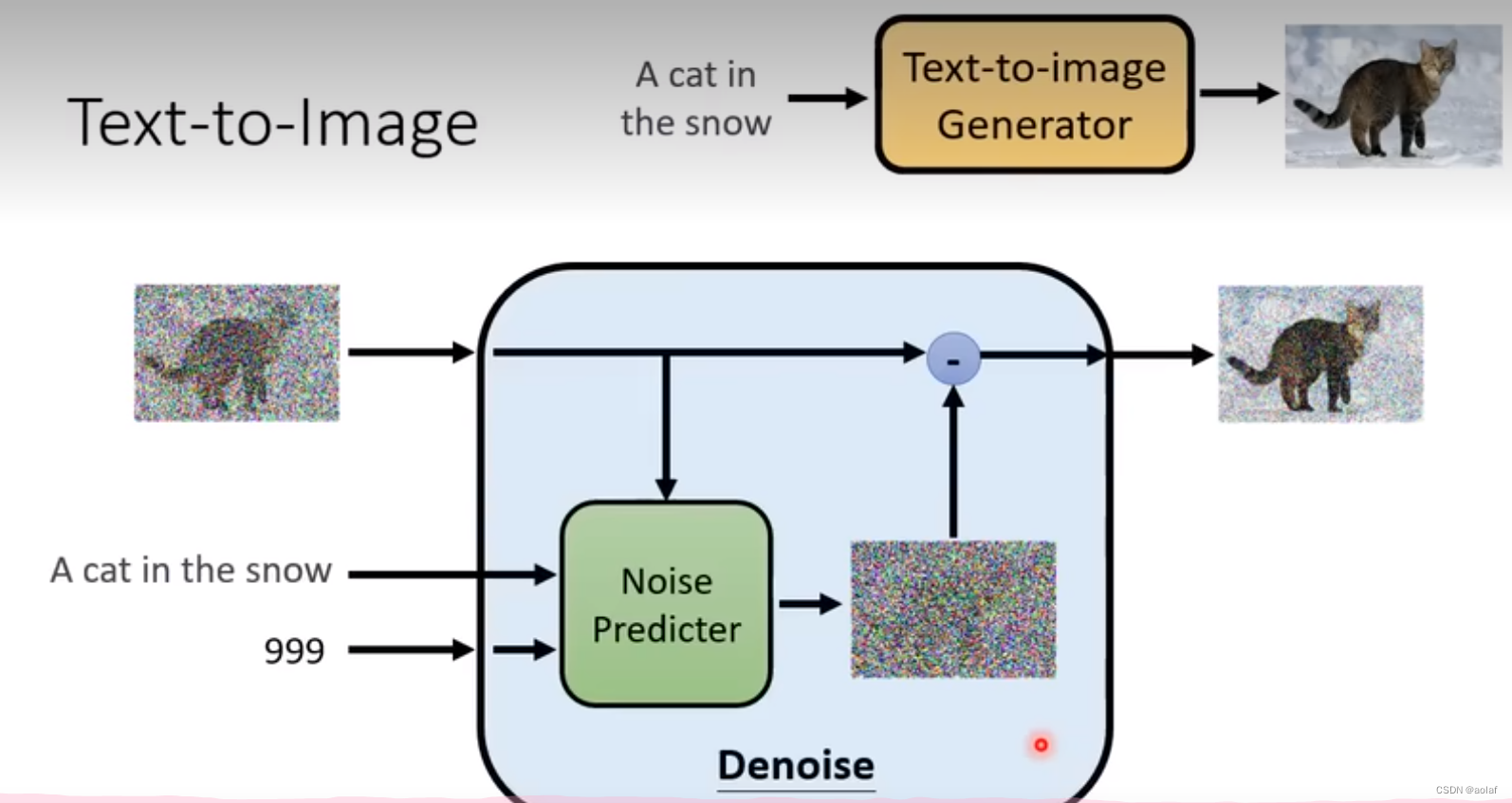
1.1 Denoise 模块的内部过程
根据我们输入带噪声的图像和去噪程度的参数,Denoise模块中的Noise pred模块会预测出图中的noise部分,此时输入图像和预测噪声的差即为该step的输出结果。
问:为何选择预测噪声做差而不是直接预测消除部分噪声后的图像?
由于预测噪声的难度更低,如果直接预测带噪声后的图像其实就已经相当于可以实现图像的生成了。
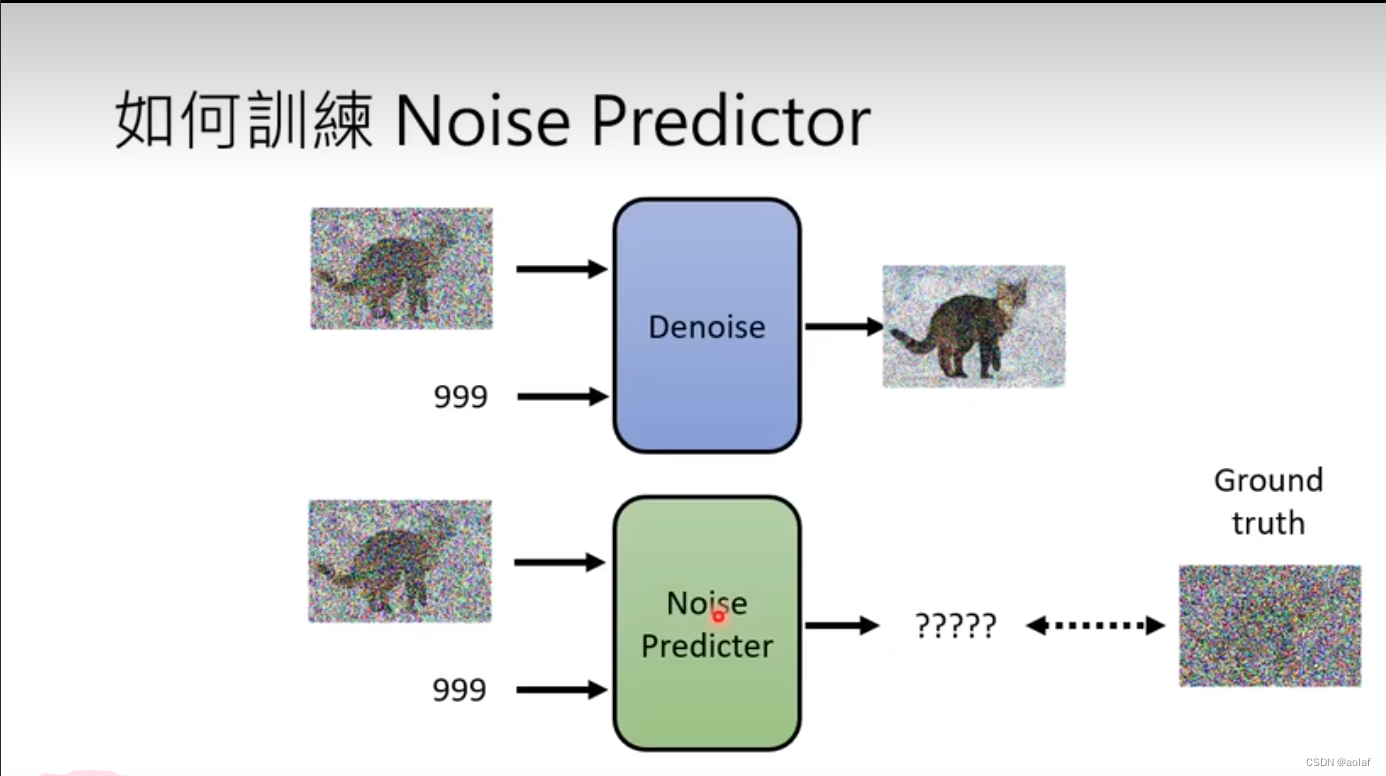
1.2 如何训练Noise_predictor
想要训练Noise_predictor预测出来噪声,我们需要提供噪声的Ground truth,这个如何获得?
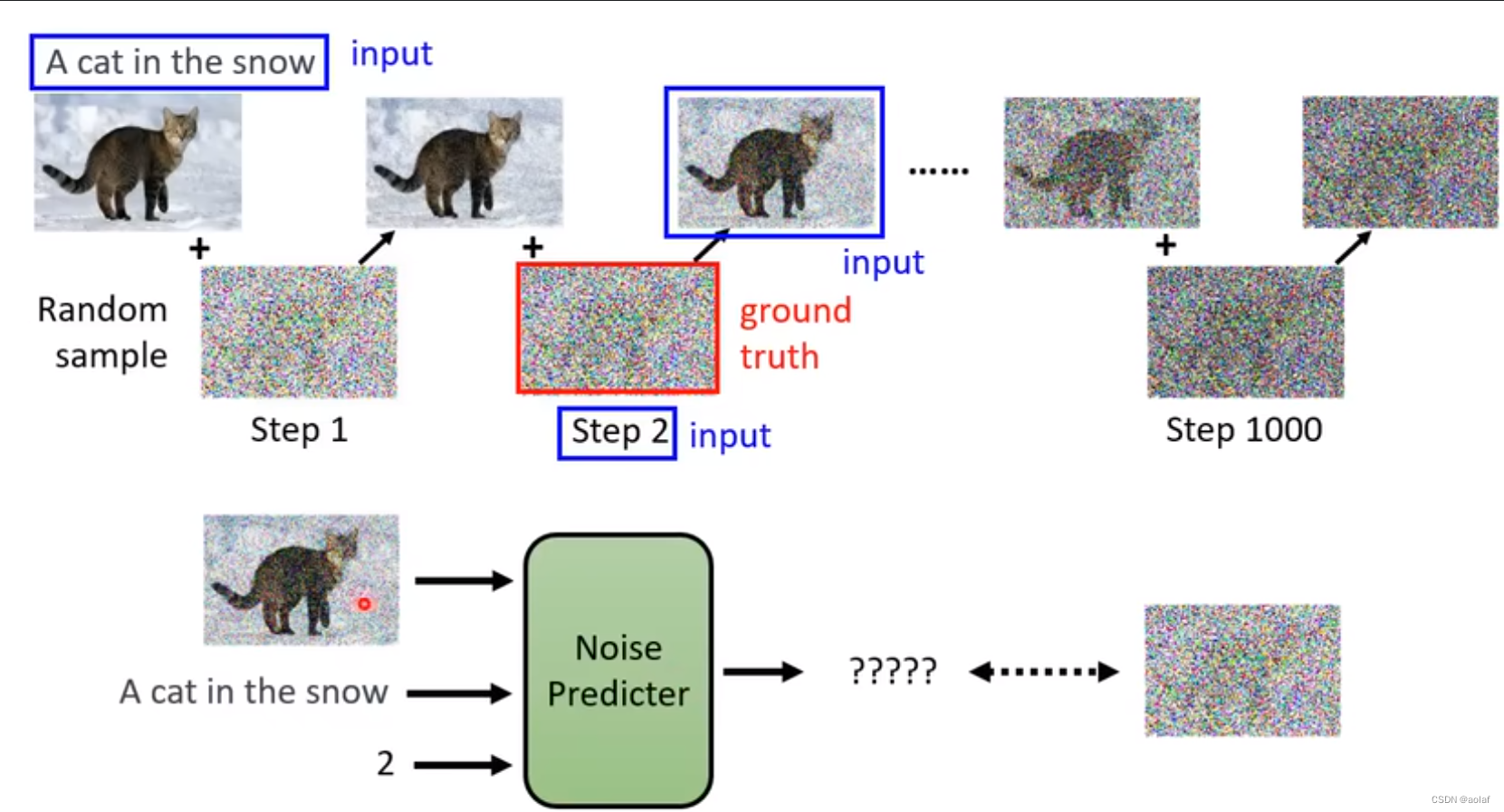
我们从训练数据集中随机抽取一张图像,然后人为给其加噪声,我们人为添加的噪声即是Noise_predictor中的groundTruth,该添加噪声的过程也被称为foward process。
2 Stable Diffusion
stable diffusion包括三大模块:TextEncoder、Generation Model、Decoder,三个模块独立训练,最终组合。
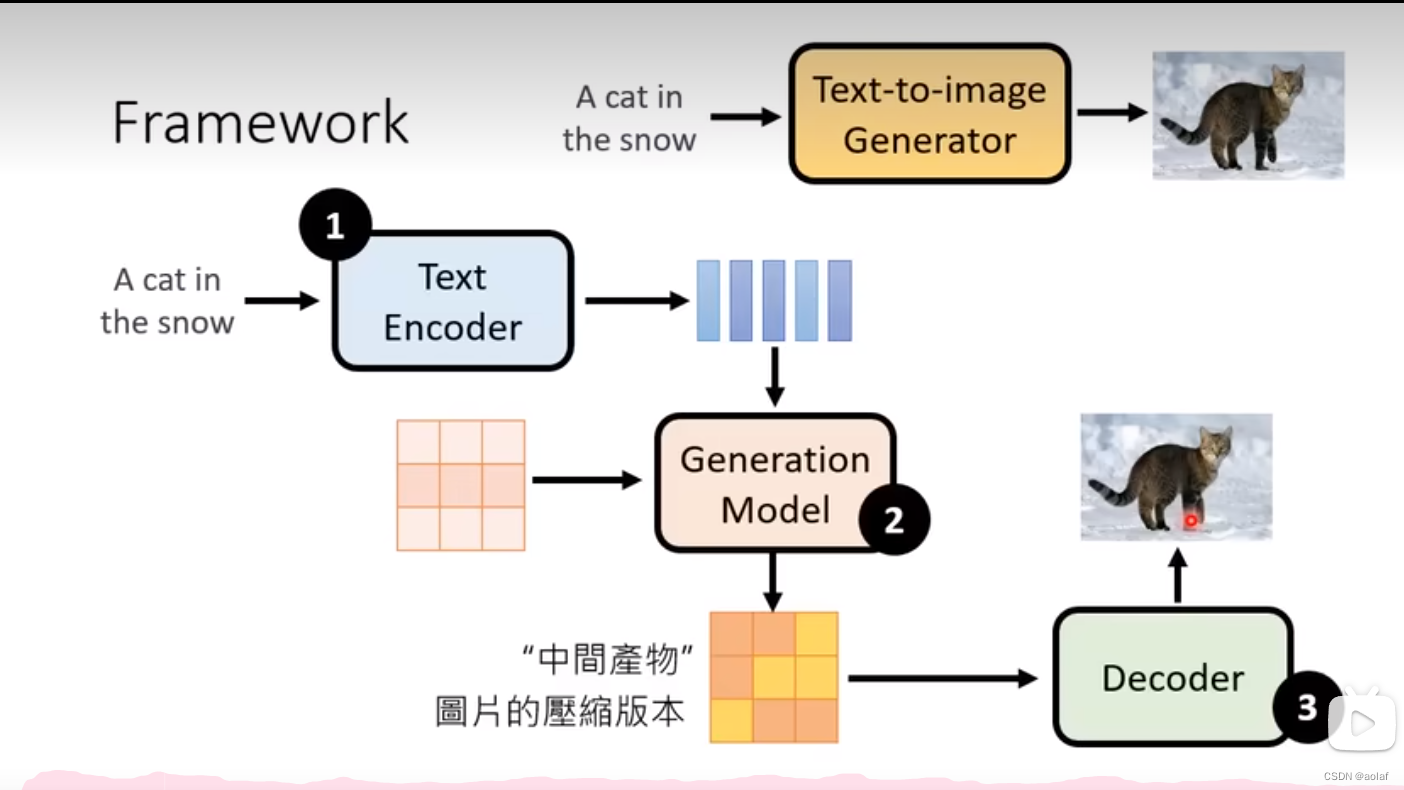
2.1 TextEncoder
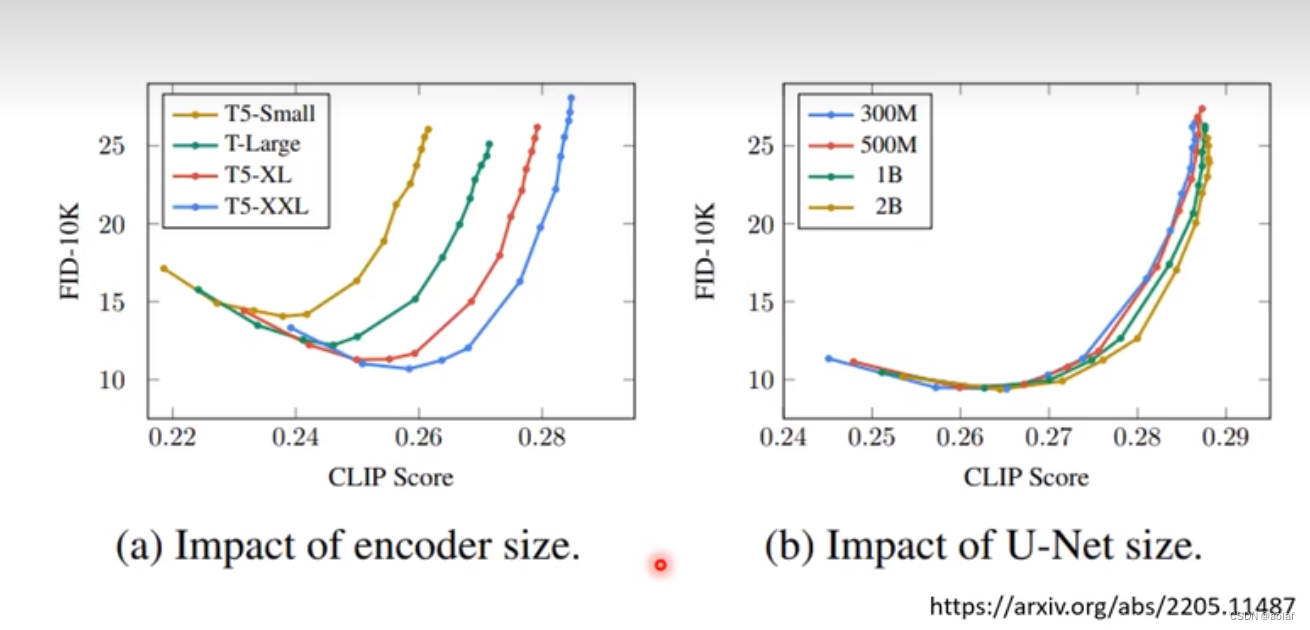
TextEncoder对结果的影响很大,远大于diffusion model,增大TextEncoder模型,效果明显,而增大diffusion model模型,效果则没那么显著。
2.1.1 FID的理解
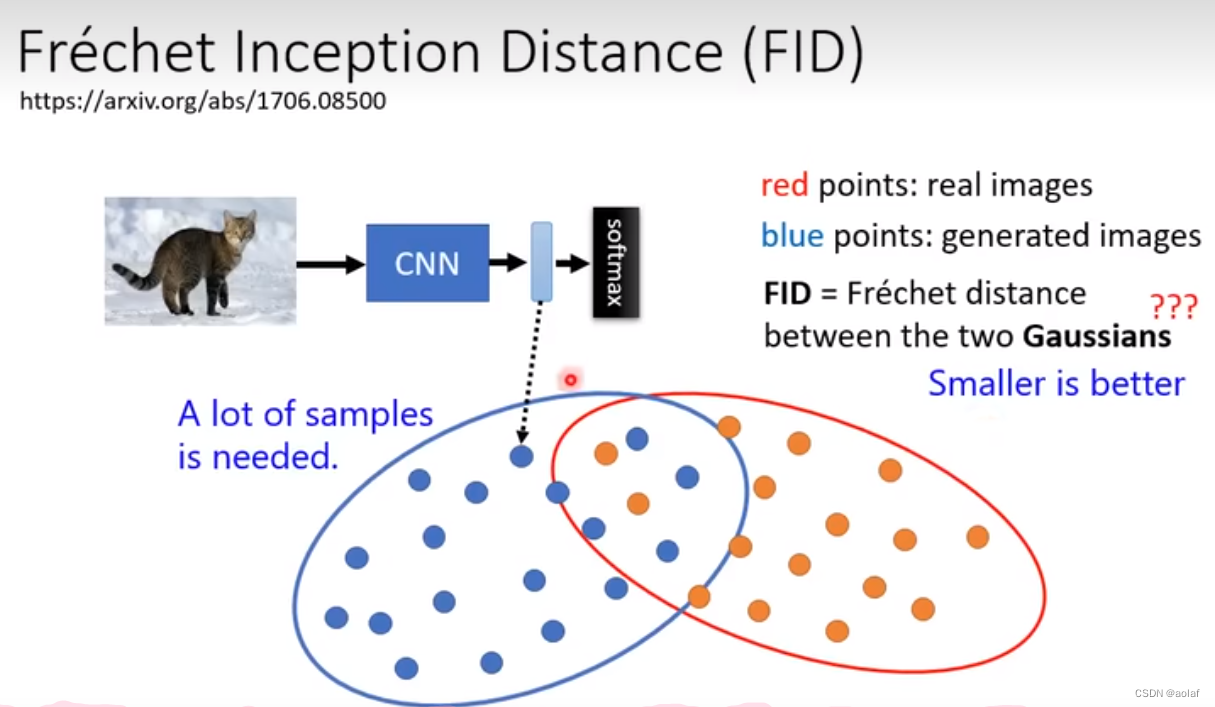
将真实图片和生成图片分别输入到一个CNN分类器,假设他们都满足高斯分布,计算他们的距离,距离越小说明生成的图片效果越好,距离越大说明生成的图片效果越差。注意,FID的计算需要充足数量的样本。
2.1.2 CLIP score的理解
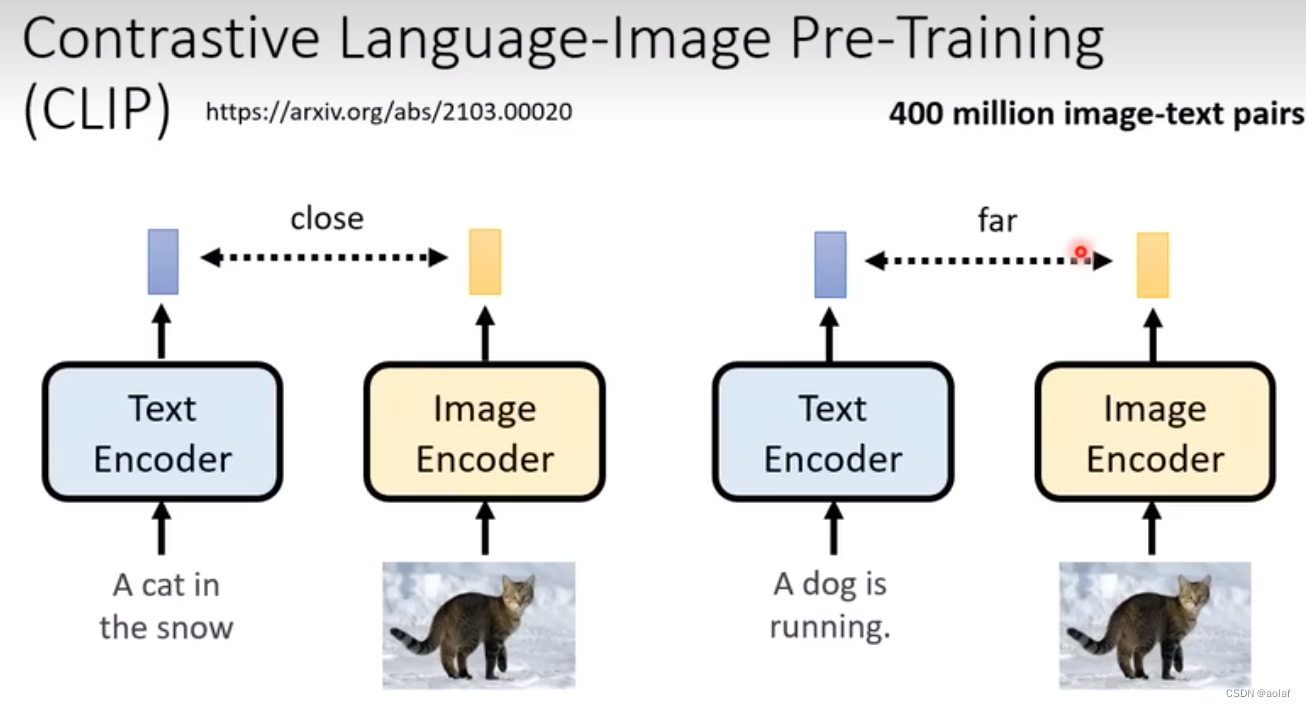
clip分为TextEncoder和imageEncoder两个模块,将text输入到TextEncoder中获得的向量与将image送入到imageEncoder中获得的向量进行比较,如果输入的text和image是成对的,则结果向量越近越好,反之,越远越好。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!