通过生成模拟释放无限数据以实现机器人自动化学习
该工作推出RoboGen,这是一种生成机器人代理,可以通过生成模拟自动大规模学习各种机器人技能。 RoboGen 利用基础模型和生成模型的最新进展。该工作不直接使用或调整这些模型来产生策略或低级动作,而是提倡一种生成方案,该方案使用这些模型自动生成多样化的任务、场景和训练监督,从而在最少的人类监督下扩大机器人技能的学习。
该工作的方法为机器人代理提供了一个自我引导的提议(propose)-生成(generate)-学习(learning)循环。
1、代理首先提出要开发的感兴趣的任务和技能,然后通过使用适当的空间配置填充相关对象和资产来生成相应的模拟环境。
2、代理将propose的高级任务分解为子任务,选择最佳学习方法(强化学习、运动规划或轨迹优化),生成所需的训练监督,然后学习策略以获得提议的技能。
该工作的工作试图提取大型模型中嵌入的广泛且通用的知识,并将其转移到机器人领域。该工作的完全生成pipeline可以重复查询,产生与不同任务和环境相关的无穷无尽的技能演示。
介绍
这项工作的动机是机器人研究中一个长期存在且具有挑战性的目标:赋予机器人多种技能,使它们能够在各种非工厂环境中操作并为人类执行广泛的任务。近年来,在教机器人各种复杂技能方面取得了令人瞩目的进展:从可变形物体和流体操纵到动态和灵巧技能,如物体投掷、手部重新定向、踢足球甚至机器人跑酷。然而,这些技能仍然各自为政,视野相对较短,并且需要人为设计的任务描述和训练监督。值得注意的是,由于现实世界数据收集的成本高昂且费力,许多这些技能都是在具有适当领域随机化的模拟中进行训练,然后部署到现实世界中。

robogen可以自主生成任务和环境并且学习技能
事实上,模拟环境已经成为多样化机器人技能学习背后的关键驱动力。与现实世界中的探索和数据收集相比,模拟中的技能学习具有以下几个优点:1)模拟环境提供了特权低级状态的访问和无限的探索机会;2) 仿真支持大规模并行计算,能够显著加快数据收集速度,而无需依赖对机器人硬件和人力的大量投资;3)模拟探索允许机器人开发闭环策略和错误恢复能力,而现实世界的演示通常只提供专家轨迹。然而,模拟中的机器人学习也存在其自身的局限性:虽然在模拟环境中探索和练习具有成本效益,但构建这些环境需要大量的劳动力,需要繁琐的步骤,包括设计任务、选择相关且语义上有意义的资产、生成合理的场景布局和配置,以及制定训练监督,例如奖励或损失函数。创建这些组件并为该工作日常生活中遇到的无数任务构建个性化模拟设置的繁重任务是一项巨大的挑战,即使在模拟世界中,这也极大地限制了机器人技能学习的可扩展性。
解决的两个问题:1、机器人的技能各自孤立,且需要人为设计的任务描述和训练监督;(2)在模拟器上进行训练,虽然模拟器有很多优势,但也在一定程度上限制了机器人技能学习的可扩展性。
有鉴于此,该工作提出了一种称为生成模拟的范例,将模拟机器人技能学习、基础大模型和生成模型的最新进展结合起来。利用最先进的基础模型的生成能力,生成模拟旨在为模拟中各种机器人技能学习所需的所有阶段生成信息:从高级任务和技能建议,到任务相关的场景描述,资产选择和生成、策略学习选择和训练监督。得益于最新基础模型中编码的全面知识,以这种方式生成的场景和任务数据有可能与现实世界场景的分布非常相似。此外,这些模型还可以进一步提供分解的低级子任务,这些子任务可以通过特定领域的策略学习方法无缝处理,从而产生各种技能和场景的闭环演示。
本文的RoboGen结合模拟机器人技能学习、基础大模型和生成模型,想达到目标:1、生成机器人技能学习过程中所需要的信息:任务和技能的生成、为相关的任务配备虚拟环境;2、将高级任务分解成低级子任务,策略选择学习、生成训练监督。
方法介绍
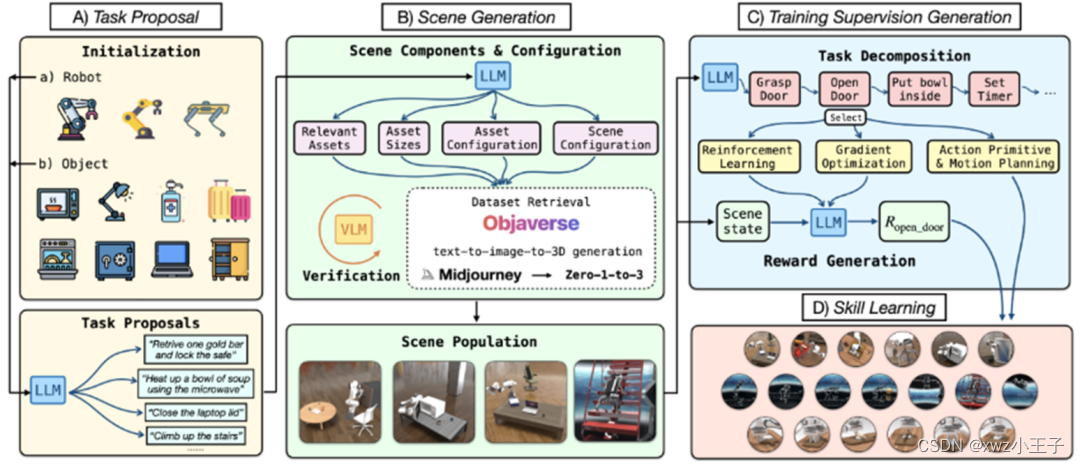
robogen工作流程图
RoboGen是一个自动化pipeline,利用最新基础模型的嵌入式常识和生成功能来自动生成任务、场景和训练监督,从而实现大规模的多样化机器人技能学习。该工作在图中展示了整个流程,由几个完整的阶段组成:任务提议、场景生成、训练监督生成和技能学习。
任务提议:
RoboGen首先生成有意义的、多样化的、高水平的任务供机器人学习。该工作没有直接向 LLM 查询任务建议,而是使用特定的机器人类型和从池中随机采样的对象来初始化系统。然后将提供的机器人和采样对象信息用作 LLM 的输入以执行任务建议。这样的采样过程确保了生成任务的多样性:例如,四足机器人等腿式机器人能够获得多种运动技能,而机械臂操纵器在配对时有可能执行多种操纵任务与不同的采样对象。此初始化步骤充当播种阶段,为LLM可以进行调节并随后进行推理和推断以生成各种任务提供基础,同时考虑到机器人和物体的可供性。除了基于对象的初始化之外,另一种选择是采用基于示例的初始化,其中使用提供的机器人和从列表 11 个预定义任务中采样的几个示例任务来初始化查询。
场景生成:
给定一个提议的任务,继续生成相应的模拟场景,以学习完成该任务的技能。如图 2 所示,根据任务描述生成场景组件和配置,并检索或生成对象资产以随后填充模拟场景。具体来说,场景组件和配置由以下元素组成:查询要填充到场景中的相关资产、其物理参数(例如大小)、配置(例如初始关节角度)以及资产的整体空间配置。
训练监督生成:
为了获得解决所提出的任务的技能,需要对技能学习进行监督。为了促进学习过程,RoboGen 首先查询 GPT-4 来规划和分解生成的任务(可以是长范围的)为较短范围的子任务。关键假设是,当任务被分解为足够短的子任务时,每个子任务都可以通过现有的算法(例如强化学习、运动规划或轨迹优化)可靠地解决。
分解后,RoboGen随后查询 GPT-4 以选择合适的算法来解决每个子任务。RoboGen中集成了三种不同类型的学习算法:强化学习和进化策略、基于梯度的轨迹优化、具有运动规划的动作原语。每一种都适合不同的任务,例如,基于梯度的轨迹优化更适合学习涉及软体的细粒度操作任务,例如将面团塑造成目标形状;与运动规划相结合的动作基元在解决任务时更加可靠,例如通过无碰撞路径接近目标对象;强化学习和进化策略更适合接触丰富且涉及与其他场景组件持续交互的任务,例如腿运动,或者当所需的动作不能通过离散的末端执行器姿势简单地参数化时,例如转动烤箱的旋钮。
该工作提供示例,让 GPT-4 根据生成的子任务在线选择使用哪种学习算法。考虑的动作原语包括抓取、接近和释放目标对象。由于平行爪式夹具在抓取不同尺寸的物体时可能会受到限制,因此考虑使用配备吸盘的机器人操纵器来简化物体抓取。抓取和接近基元的实现如下:首先随机采样目标对象或链接上的一个点,计算与采样点法线对齐的夹具姿势,然后使用运动规划来找到一条无碰撞路径达到目标夹具姿势。达到姿势后,继续沿着法线方向移动,直到与目标物体接触。
技能学习:
一旦获得了所提出的任务所需的所有信息,包括场景组件和配置、任务分解以及分解的子任务的训练监督,就能够为机器人构建模拟场景,以学习完成任务所需的技能任务。
如上所述,结合使用多种技术进行技能学习,包括强化学习、进化策略、基于梯度的轨迹优化以及带有运动规划的动作原语,因为每种技术都适合不同类型的任务。对于对象操作任务,使用 SAC 作为学习技能的 RL 算法。观察空间是任务中物体和机器人的低层状态。强化学习策略的动作空间包括机器人末端执行器的增量平移或目标位置(由 GPT-4 确定)及其增量旋转。使用开放运动规划库(OMPL)(Sucan 等人,2012)中实现的BIT* 作为动作基元的底层运动规划算法。对于涉及多个子任务的长视野任务,采用顺序学习每个子任务的简单方案:对于每个子任务,运行 RL N = 8 次,并使用具有最高奖励的最终状态作为初始状态为下一个子任务。对于运动任务,交叉熵方法(CEM)用于技能学习,发现它比 RL 更稳定、更高效。CEM中采用地面真值模拟器作为动态模型,需要优化的动作是机器人的关节角度值。对于软体操纵任务,与 Adam 一起运行基于梯度的轨迹优化来学习技能,其中梯度由使用的完全可微模拟器提供。
实验
RoboGen是一个自动化pipeline,可以无限查询,并为不同的任务生成连续的技能演示流。在实验中,旨在回答以下问题:
? 任务多样性:RoboGen机器人技能学习提出的任务有多多样化?
? 场景有效性:RoboGen是否生成与建议的任务描述相匹配的有效模拟环境?
? 训练监督有效性:RoboGen 是否为任务生成正确的任务分解和训练监督,从而诱导预期的机器人技能?
? 技能学习:在RoboGen中集成不同的学习算法是否可以提高学习技能的成功率?
? 系统:结合所有自动化阶段,整个系统能否产生多样化且有意义的机器人技能?
实验设置
提出的系统是通用的,并且与特定的模拟平台无关。然而,由于考虑了从刚性动力学到软体模拟的广泛任务类别,并且还考虑了技能学习方法,例如基于梯度的轨迹优化,这需要可微分的模拟平台,因此使用 Genesis 来部署 RoboGen(一个模拟平台)用于使用多种材料和完全可微分的机器人学习。对于技能学习,使用 SAC 作为 RL 算法。策略和 Q 网络都是大小为 [256, 256, 256] 的多层感知器 (MLP),以 3e ? 4 的学习率进行训练。对于每个子任务,使用 1M 环境步骤进行训练。使用 BIT* 作为运动规划算法,使用 Adam 用于软体操纵任务的基于梯度的轨迹优化。

长周期任务技能学习效果
评估指标和baseline:
任务多样性:生成的任务的多样性可以从许多方面来衡量,例如任务的语义、生成的模拟环境的场景配置、检索到的对象资产的外观和几何形状以及执行任务所需的机器人动作。对于任务的语义意义,通过计算生成的任务描述的 Self-BLEU 和嵌入相似度来进行定量评估,其中较低的分数表明更好的多样性。与既定基准进行比较,包括 RLBench、Maniskill2、Meta-World和 Behaviour-100。对于对象资产和机器人动作,使用生成的模拟环境和所学机器人技能的可视化来定性评估 RoboGen。
场景有效性:为了验证检索到的对象是否符合任务要求,计算模拟场景中检索到的对象的渲染图像与对象的文本描述之间的 BLIP-2 分数。A)无对象验证:我们不使用VLM来验证检索到的对象,而只是基于文本匹配来检索对象。B) 无大小验证:我们不使用 GPT-4 输出的对象大小;相反,我们使用 Objaverse 或 PartNetMobility 中提供的默认资源大小。
实验结果如下图所示:
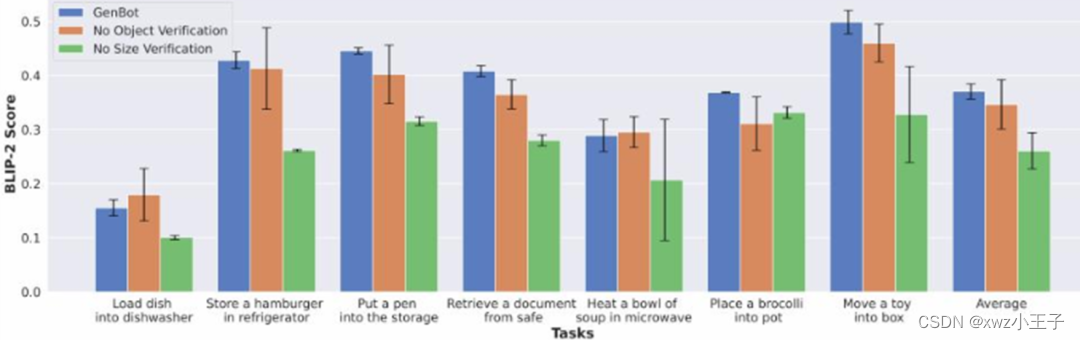
robogen在7个任务上的结果
总结
该工作引入了RoboGen,这是一种生成代理,可以通过生成模拟自动大规模地提出和学习各种机器人技能。RoboGen 利用基础模型的最新进展,在模拟中自动生成不同的任务、场景和训练监督,为模拟中可扩展的机器人技能学习迈出了基础一步,同时部署后只需要最少的人工监督。系统是一个完全生成的pipeline,可以无限查询,产生大量与不同任务和环境相关的技能演示。RoboGen与后端基础模型无关,并且可以使用可用的最新模型不断升级。
当前的系统仍然存在一些局限性:1)对所学技能的大规模验证(即所得技能是否真的通过文本描述解决了相应的任务)仍然是当前pipeline中的一个挑战。未来可以通过使用更好的多模式基础模型来解决这个问题。Ma还探索了使用环境反馈对生成的监督(奖励函数)进行迭代细化,希望将来将其整合到范式中。2)当涉及到现实世界的部署时,范例本质上受到模拟与真实差距的限制。然而,随着物理精确模拟的最新和快速发展,以及域随机化和逼真的感官信号渲染等技术,预计模拟与真实的差距在未来将进一步缩小。3)系统假设,通过正确的奖励函数,现有的策略学习算法足以学习所提出的技能。对于在本文中测试的策略学习算法(具有 SAC 的 RL 和 delta 末端执行器姿势的动作空间,以及基于梯度的轨迹优化),观察到它们仍然不够鲁棒,并且通常需要多次运行才能产生成功某些生成任务的技能演示。将更强大的策略学习算法集成到 RoboGen 中,例如那些具有更好动作参数化的算法,作为未来的工作。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!