MySQL的体系结构(超全总结版)
MySQL组成
- 连接池组件
- 管理服务和工具组件
- SQL接口组件
- 查询分析器组件
- 优化器组件
- 缓冲组件
- 插件式存储引擎
- 物理文件
存储引擎
InnoDB存储引擎
主要面向OLTP(在线事务处理)方面的应用,特点是行锁设计、支持外键,默认情况下读取操作不会产生锁。通过使用多版本并发控制(MVCC)获得高并发性,实现SQL的4种隔离级别,默认为REPEATABLE级别。同时使用一种next-key locking的策略来避免幻读现象的产生。还提供插入缓冲、二次写、自适应哈希索引、预读等高性能和高可用的功能。
MyISAM存储引擎
官方提供的存储引擎,特点是不支持事务、表锁和全文索引,对于一些OLAP(在线分析处理)操作速度快,是除Windows版本外,所有MySQL版本默认的存储引擎。
MyISAM存储引擎表由MYD和MYI组成,MYD用来存放数据文件,MYI用来存放索引文件。MySQL5.0版本之前,MyISAM默认支持的表大小为4G,若要大于4G需制定MAX_ROWS和AVG_ROW_LENGTH属性。从5.0开始,默认支持256T的单表数据。
NDB存储引擎
是一个集群存储引擎,特点是数据全部放在内存中(5.1版本开始可以将非索引数据放在磁盘上),因此主键查找的速度极快,并且通过添加NDB数据存储节点可以线性提高数据库性能,是高可用高性能的集群系统。
Memory存储引擎
将表中的数据存放在内存中,如果数据库重启或崩溃,表中的数据都将消失。非常适用于存储临时数据的临时表、数据仓库中的纬度表,默认使用哈希索引而不是B+树索引。
虽然速度非常快,但是有一定限制:只支持表锁、并发性能差、不支持TEXT和BLOB列类型、存储变长字段(varchar)是按照定长字段(char)方式进行,会浪费内存。
Archive存储引擎
只支持INSERT和SELECT操作,5.1开始支持索引。使用zlib算法将数据行(row)进行压缩后存储,压缩比率一般可达1:10。非常适合存储归档数据,如日志信息。使用行锁来实现高并发的插入操作,但本身不是事务安全的存储引擎,设计目的主要是提供高速的插入和压缩功能。
Federated存储引擎
不存放数据,指向一台远程MySQL数据库服务器上的表。
Maria存储引擎
新开发,目标是取代MyISAM存储引擎,成为MySQL的默认存储引擎。特点是缓存数据和索引文件,行锁设计,提供MVCC功能,支持事务和非事务安全的选项支持,以及更好的BLOB字符类型的处理性能。
其它存储引擎
Merge、CSV、Sphinx、Infobright等,都有各自的使用场景。
InnoDB存储引擎
后台线程
默认情况下InnoDB存储引擎的后台线程有13个—10个IO thread, 1个master thread,1个锁监控线程,1个错误监控线程。
show engine innodb status;
可以看到,10个IO线程分别是insert buffer thread、log thread、 read thread、 write thread。Linux平台下,IO thread数量不能调整,windows平台可以通过参数inodb_read_io_threads和innodb_write_io_threads来调大线程。
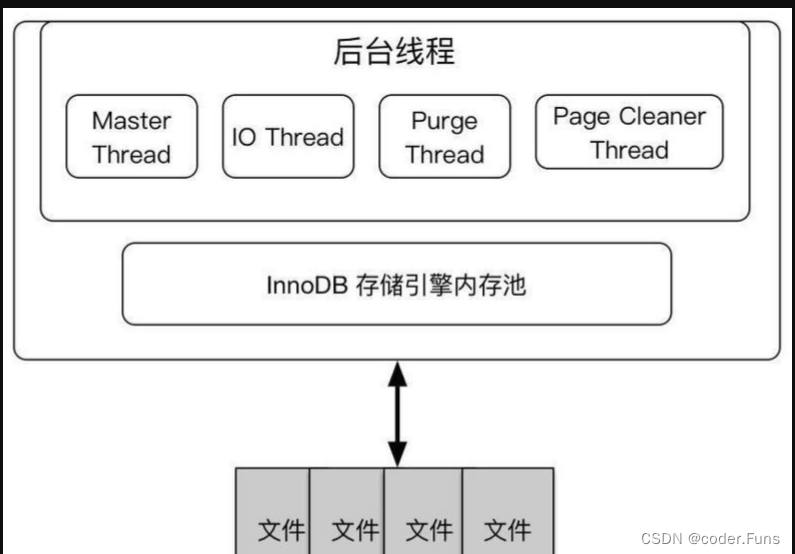
内存
Innodb存储引擎的内存由以下几个部分组成: 缓冲池、重做日志缓冲池以及额外的内存池。分别由配置文件中的参数innodb_buffer_pool_size和innodb_log_buffer_size的大小决定。
缓冲池是占最大块内存的部分,用来存放各种数据的缓存。InnoDB将数据文件按页(16KB/页)读取到缓冲池,按LRU(最近最少)的算法保留缓冲池中的缓存数据。若数据文件需修改,总是先修改缓存池中的页(发生修改后,该页即为脏页),然后按一定频率将缓冲池的脏页刷新(flush)到文件。可通过
show engine innodb status
来查看innodb_buffer_pool的具体使用情况。
----------------------
BUFFER POOL AND MEMORY
----------------------
Total large memory allocated 0
Dictionary memory allocated 487648
Buffer pool size 8191
Free buffers 6922
Database pages 1263
Old database pages 486
Modified db pages 0
Pending reads 0
Pending writes: LRU 0, flush list 0, single page 0
Pages made young 0, not young 0
0.00 youngs/s, 0.00 non-youngs/s
Pages read 1120, created 143, written 202
0.00 reads/s, 0.00 creates/s, 0.00 writes/s
Buffer pool hit rate 1000 / 1000, young-making rate 0 / 1000 not 0 / 1000
Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s
LRU len: 1263, unzip_LRU len: 0
I/O sum[0]:cur[0], unzip sum[0]:cur[0]
buffer pool size表明一共有多少缓冲帧(buffer frame),每帧16K, 所以这里一共分配了8191*16/1024=127M内存的缓冲池。Free buffers表示空闲的缓冲帧, Database pages 表示已使用的缓冲帧, Modified db pages 表示脏页的数量。可以用这些参数来观察当前数据库的压力。
注意:show engine innodb status显示的不是当前的状态,而是过去某个时间范围内InnoDB的状态。
Per second averages calculated from the last 30 seconds 表示的信息是过去30秒内的数据库状态。
缓冲池中缓存的数据页具体类型有:索引页、数据页、undo页、插入缓冲、自适应哈希索引、InnoDB存储的锁信息、数据字典信息等。

关键三大特性
插入缓冲
数据库最主要的性能问题是I/O, 插入缓冲的作用就是把普通索引上的DML操作从随机I/O,变为顺序I/O,从而提高I/O的效率。
原理: 先判断插入的普通索引页是否在缓冲池中,如果在就可以直接插入,如果不在就先放在 change buffer中,然后进行 change buffer和普通索引的合并操作,可以将多个插入合并到一个操作中,提高普通索引的插入性能。
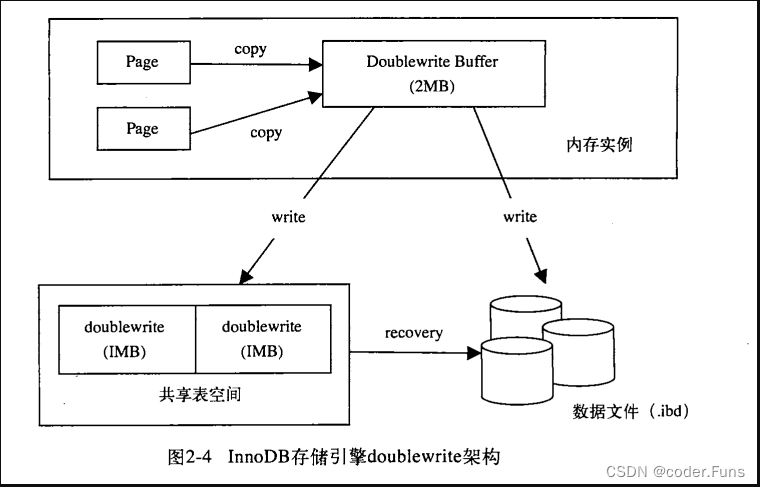
两次写
保证写入的安全性,防止实例宕机时,innoDB发生数据页部分写的问题(部分写失效,导致数据丢失)。
自适应哈希
哈希是一种非常快的查找方法,一般时间复杂度为O(1),常用于连接(join)操作。InnoDB会监控对表上索引的查找,如果观察到建立哈希索引可以带来速度的提升,则建立哈希索引,所以称之为自适应的。自适应哈希索引通过缓冲池的B+树构造而来,因此建立的速度很快。而且不需要将整个表都建哈希索引,InnoDB会自动根据访问的频率和模式来为某些页建立哈希索引。
启用自适应哈希索引后,读取和写入速度可以提高2倍(官方文档说的);对于辅助索引的连接操作,性能可以提高5倍。
可以通过innodb_adaptive_hash_index来禁用或启用此特性,默认启用。
文件
参数文件
可以把数据库参数看成一个键值对。通过 show variables 查看所有参数。MySQL参数可以分为两类:动态参数和静态参数。静态参数说明在整个实例生命周期内不得进行修改。可以通过SET 命令对动态参数值进行修改。
注意:对变量全局值进行修改,在本次实例生命周期内都有效,但MySQL实例本身不会对参数文件中的该值进行修改,因此下次启动时还是读取参数文件的值。
日志文件
记录MySQL的各种类型活动。常见日志文件有错误日志、二进制日志、慢查询日志、查询日志。这些日志文件为DBA对数据库优化、查找问题带来极大的便利。
pid文件
实例启动时,会将自己进行ID写入一个pid文件中。该文件可由参数pid_file控制,默认路径位于数据库目录下,文件名为"主机名.pid"。
show variables like 'pid_file';
表结构定义文件
MySQL对于数据的存储是按照表的,所以每个表都会有与之对应的文件(
MySQL8.0中不再单独提供表名.frm,而是合并在表名.ibd文件中)。
InnoDB存储引擎文件
上面介绍的文件都是MySQL数据库本身的文件,和存储引擎无关。每个表存储引擎有其自己独有的文件,这些文件包括重做日志文件、表空间文件。
表空间文件
InnoDB模仿Oracle,将存储的数据按表空间进行存放。默认配置下会有一个初始化大小10MB,名为ibdata1的默认表空间文件。
重做日志文件
每个innoDB存储引擎至少包含1个重做日志组,每个重做日志组至少包含2个重做日志文件,默认文件名为ib_logfile0和ib_logfile1。 重做日志文件记录了innoDB存储引擎的事物日志。
重做日志文件大小一致,并且采用循环写入的方式运行。
表
表是关于特定实体的数据集合,也是关系型数据库模型的核心。InnoDB表中,每张表都会有个主键,如果没有显式的定义主键,则会按如下方式自动创建主键:
- 判断是否有非空唯一索引(Unique NOT NULL),若有该列为主键
- 不符合上述条件,自动创建一个6字节大小的指针
逻辑存储结构
所有数据被逻辑存放在表空间中。表空间由段(segment)、区(extent)、页(page)组成。

段
表空间由各个段组成,常见的段有数据段、索引段、回滚段等。
区
区是由64个连续的页组成,每个页大小为16KB,即每个区大小为1MB。对于大的数据段,InnoDB最多每次可以申请4个区,以此来保证数据的顺序性能。
页
也可以称为块,是InnoDB磁盘管理的最小单位。常见的页类型有:
- 数据页
- Undo页
- 系统页
- 事务数据页
- 插入缓冲位图页
- 插入缓冲空闲列表页
- 未压缩的二进制大对象页
- 压缩的二进制大对象页
行
InnoDB是面向行的,就是说数据的存放按行进行。每个页最多允许存放16KB/2-200行的记录,即7792行记录。
视图
视图是一个命名的虚表,它由一个查询来定义,可以当做表使用。视图中的数据没有物理表现形式。
分区表
MySQL5.1版本时添加了对分区的支持,只支持水平分区,不支持垂直分区。(水平分区指同一表中不同行的记录分配到不同的物理文件中,垂直分区指将同一表中不同的列分配到不同的物理文件中。)
MySQL的分区是局部分区索引,一个分区中既存放了数据又存放了索引。
当前支持的分区类型:
- RANGE分区
- LIST分区
- HASH分区
- KEY分区
子分区
子分区是在分区的基础上再进行分区,也叫复合分区。MySQL允许在RANGE和LIST的分区上再进行HASH或者是KEY的子分区。如:

子分区的建立注意事项:
- 每个子分区的数量必须相同
- 如果在一个分区表上的任何分区使用SUBPARTITION定义任何子分区,那么就必须定义所有的子分区。
- 每个SUBPARTITION子句必须包括子分区的一个名称
- 每个分区内,子分区的名称必须唯一。
分区中的NULL值
MySQL允许对NULL值做分区。
对于RANGE分区,会将该值放入最左边的分区。假设删除p0这个分区,删除的是小于10的记录,并且还有NULL值的记录。
LIST分区下要使用NULL值必须显式指出哪个分区放入NULL,否则会报错。
HASH和KEY分区会将含有NULL值的记录返回为0.
索引和算法
InnoDB支持两种常见索引,一种是B+树索引,一种是哈希索引。哈希索引是自适应的,不能人为干预是否在一张表中生成哈希索引。
B+树索引不能找到一个给定键值的具体行,而是找到数据行所在页,把页读入内存,再在内存中查找数据(二分查找法)。
B+树索引
B+树索引本质是B+树在数据库中的实现。特点是高扇出性,因此B+树高度一般在2~3层,也就是查询需要2~3次IO。一般磁盘每秒至少可以100次IO,2~3次IO相当于查询耗时0.02~0.03秒。
B+树索引可分为聚集索引和辅助聚集索引,都是高度平衡,叶节点存放所有数据。
聚集索引
按表主键构造一颗B+树,叶节点存放整张表的行记录数据,因此索引组织表中数据也是索引的一部分。
数据页智能按一颗B+树进行排序,因此每张表只能有一个聚集索引。聚集索引能特别快的访问针对范围值的查询。优化器倾向于优先使用聚集索引。
辅助索引
叶节点不包含行的全部数据,除了包含键以外,还包含一个书签,书签指向相应行数据的聚集索引键。
辅助索引不影响数据在聚集索引中的组织,因此每张表可以有多个辅助索引。如果辅助索引高度为3,聚集索引高度也为3,那么通过辅助索引需要6次IO才能找到最终的数据页。
何时使用B+树索引
并非所有查询条件下出现的列都需要添加索引。当访问表中很少一部分行时,B+树索引才有意义。
优化器会通过EXPLAIN的rows字段预估可能得到的行,如果大于某个值(一般在20%),会选择全表扫描。
InnoDB中的锁
锁机制用于管理对共享资源的并发访问。
锁的类型
InnoDB实现如下两种标准行级锁:
- 共享锁(S Lock),允许事务读一行数据。
- 排他锁(X Lock), 允许事务删除或更新一行数据。
为了支持不同粒度上进行加锁,InnoDB支持一种额外加锁方式称为意向锁。
- 意向共享锁(IS Lock),事务想要获得某几行的共享锁。
- 意向排他锁(IX Lock), 事务想要获得某几行的排他锁。
锁的算法
InnoDB有3种锁的算法设计
- Record Lock : 单个行记录上的锁
- Gap Lock : 间隙锁,锁定一个范围,但不包含记录本身。
- Next-Key Lock: Gap Lock + Record Lock,锁定一个范围,并且锁定记录本身。
锁问题
丢失更新
如下情况会出现丢失更新问题
- 事务T1查询一行数据
- 事务T2也查询该行数据
- T1修改这行记录,更新数据库并提交
- T2修改这行记录,更新数据库并提交
脏读
不同事务下,可以读到另外事务未提交的数据,违反事务的隔离性。
不可重复读
一个事务两次读到的数据可能不一样。
事务
事务用来保证数据库的完整性,要么都做修改,要么都不做。满足四个特性
- 原子性
事务是不可分割的工作单位。事务里所有操作成功才算成功。
- 一致性
指事务将数据库从一种状态转变为下一种一致的状态。
- 隔离性
一个事务的影响在该事务提交前对其它事务不可见。
- 持久性
事务一旦提交,结果就是永久的,即使发生宕机数据库也能将数据恢复。
事务实现
redo
事务日志通过重做日志文件和InnoDB的日志缓冲(InnoDB Long Buffer)实现。
undo
用于撤销操作。若执行事务失败,或ROLLBACK,就可利用undo将数据回滚到修改前的状态。
事务隔离级别
- READ UNCOMMITTED 读未提交
- READ COMMITTED 读已提交
- REPEATABLE READ 可重复读
- SERIALIZABLE 串行
InnoDB默认隔离级别是REPEATABLE READ。
备份
根据备份方法可分为
- 热备: 在数据库中直接备份,对正在运行的数据库没有任何影响。
- 冷备:数据库停止后进行备份,拷贝相关数据库物理文件即可。
- 温备: 数据库运行时进行,但会对当前数据库操作有所影响。
mysqldump
用来完成转存数据库的备份和不通数据库之前的移植。
ibbackup
InnoDB引擎官方提供的热备工具
XtraBackup
percona开源的免费数据库热备份软件,它能对InnoDB数据库和XtraDB存储引擎的数据库非阻塞地备份(对于MyISAM的备份同样需要加表锁)
优点:
- 备份速度快,物理备份可靠
- 备份过程不会打断正在执行的事务(无需锁表)
- 能够基于压缩等功能节约磁盘空间和流量
- 自动备份校验
- 还原速度快
- 可以流传将备份传输到另外一台机器上
- 在不增加服务器负载的情况备份数据
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!