机器学习在量化中的应用
| 随便聊聊
想了很多,写了删,删了写,还是随性一些。
如果有人问人工智能(Artificial Intelligence,AI)带来了什么变化,那么就是让机器具备了学习和总结的能力。计算机视觉(Computer Vision,CV)让机器学会了识别人脸,识别车牌,识别一切。自然语言处理(Nature Language Processing,NLP)则赋予机器理解和处理语言的能力,从而实现文章分类、内容理解和多语言翻译。机器学习(Machine Learning,ML)(通过总结数据间的规律,使机器能够进行复杂的预测和决策。
在股市中,我们能用到的就是机器学习和自然语言处理。机器学习能够分析和总结不同因子与目标值之间的关系。而NLP模型则通过处理时序类数据,如股票的历史价格,进行预测。NLP不仅可以利用因子预测股票目标值,还能处理新闻舆论,将其作为基本面因子来预测股票的走势。然而,这里存在一个挑战:当新闻舆论发布时,你可能尚未及时获取到相关信息,导致模型无法及时提供建议。当你做出反应时,股票市场可能已经发生了变化。
| 机器学习
在机器学习和量化的结合中,小木屋采用的更多是树模型。什么是树模型呢?就是随机森林(RF)、XGBoost、CatBoost、lightGBM模型这一系列。那么这几个模型有什么太大的区别吗?有的,RF、XGBoost、CatBoost、lightGBM这四个模型在训练速度、内存使用,对缺失值的处理、对类别特征的处理上有很大的不同。但是这些区别对预测结果的准确性影响并不大,除非训练数据量很大,则需要考虑训练速度和内存使用的问题。
树模型的结构是怎样的呢?树模型的结构如下图所示,以预测股票涨跌为例。这是一个二分类任务,模型通过学习各种因子之间的关系,将股票划分为可能涨的一类和可能跌的一类。树模型的层次结构直观地展示了模型对数据进行分割的过程,使得它成为处理复杂关系和非线性问题的强大工具。
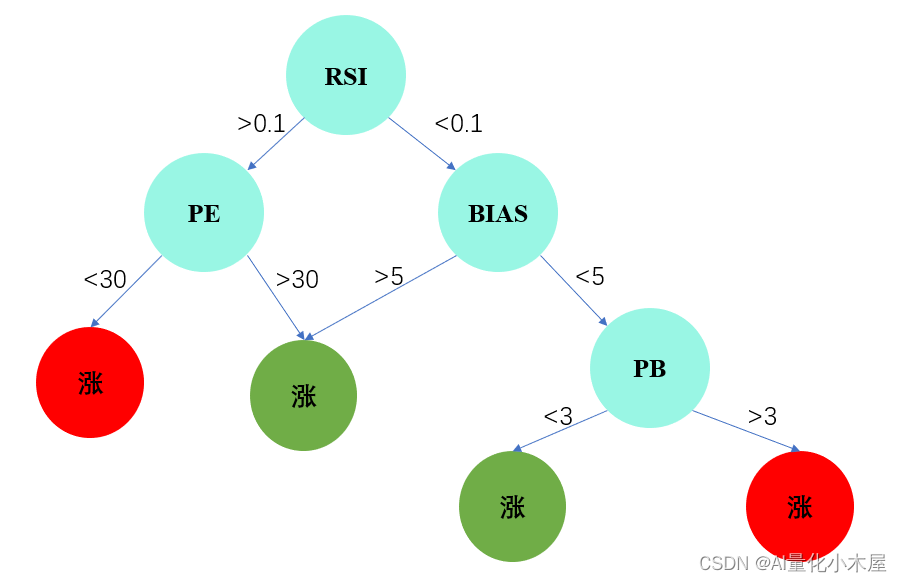
在这个结构中,每个节点表示一个特征,分支代表特征值的分割,叶子节点表示最终的分类结果。通过多棵树的集成,树模型能够更准确地捕捉数据中的模式和规律,为量化分析提供强大的预测能力。另外,图中显示,树模型通过一系列因子的大小判断。这些因子的大小是通过向树模型提供大量历史数据进行学习得到的,树模型通过总结这些历史因子和目标值之间的关系进行预测。
随机森林模型由许多这样的决策树组成。我们之所以选择使用多棵树,是因为我们认为单棵树学习到的规律可能不够准确。这类似于我们在做决策时依赖于过去学习和经历的事物,而每个人的经历和学习都是不同的,因此做出的决策也会有所不同。模型也是如此,因此我们训练多颗树,并通过对它们的决策进行投票(对于分类任务)或平均(对于回归任务),从而获得更加准确的结果。
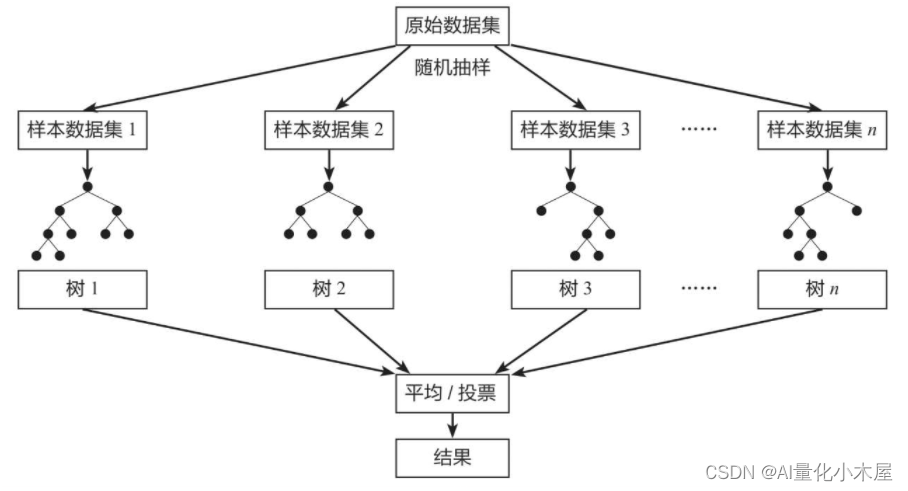
XGBoost、CatBoost、lightGBM模型大同小异,也是由多棵树组合而成。下面就不一一赘述了。如果对这三个模型有兴趣,可以找对应的论文或者找一些讲解文章看看。
小木屋现在实盘的策略是采用了随机森林的,因此我把我实盘代码简化版的核心代码展示出来。
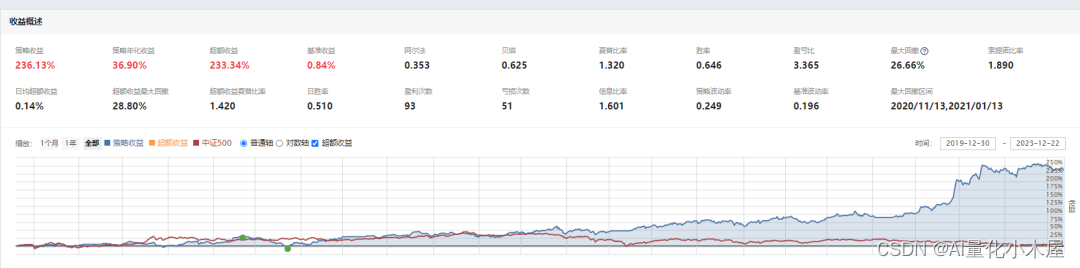
下图是小木屋经过改动并只采用了小市值因子的策略效果(没有采用随机森林)
下图是小木屋采用随机森林和多因子进行训练得到的策略效果。
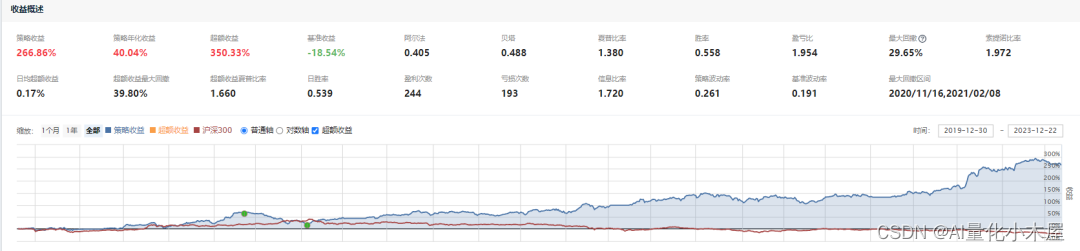
两个策略的运行时间都是2020年1月1日到2023年11月22日。第一个策略只采用了小市值因子,从策略效果图可以看出2020年该策略的效果是很差的,几乎没有正收益。而随机森林+多因子策略也有采用小市值因子,但经过随机森林和其他因子的结合,使得其在2020年的效果变好了。
再经过微调,效果变成下图所示。
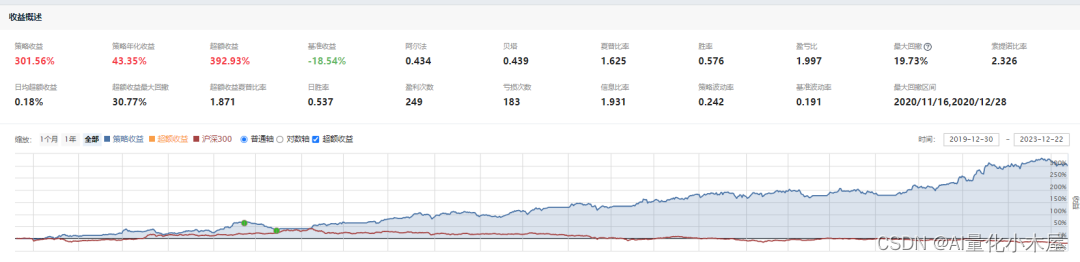
修改后的随机森林+多因子策略
上面几个图的变化,小木屋觉得随机森林模型最大的作用就是降低回撤频次和幅度,不用自己构造多个因子的组合关系,由模型总结多因子组合关系。
代码核心思想
训练和预测过程:
使用上周五的因子数据进行模型训练。
使用这周五的因子数据进行未来市值的预测。
调仓策略:
在这周五,计算预测出的未来市值与当前市值之差,选择差值最大的N只股票。 对选取的股票进行调仓,以期望获得更好的投资回报。
每周一对选取的股票进行调仓,以期望获得更好的投资回报。
基于聚宽平台的核心代码,完整可跑通代码可关注后私信我领取。
def get_stock_list(context):
final_list = set()
initial_list = list(g.pools)
today = context.current_dt
# 通过timedelta算出前一天的日期
delta = datetime.timedelta(days=1)
yesterday = today - delta
yesterday = yesterday.strftime('%Y-%m-%d')
q = query(valuation.code,
valuation.market_cap,
valuation.turnover_ratio,
valuation.pe_ratio,
valuation.pb_ratio,
valuation.ps_ratio,
indicator.roa,
income.total_operating_revenue).filter(valuation.code.in_(initial_list))
# 将获得的因子值存入一个数据表
dataset = get_fundamentals(q, date = yesterday)
dataset.columns = ['code', 'market_cap',
'换手率','PE','PB','PS','总资产收益率','营业总收入']
dataset['平均差']=list(DMA(dataset.code, yesterday)[0].values())
dataset['移动平均']=list(MA(dataset.code, yesterday).values())
dataset['乖离率']=list(BIAS(dataset.code, yesterday)[0].values())
dataset['相对强弱指标']=list(RSI(dataset.code,yesterday,N1=6).values())
dataset.fillna(0, inplace=True)
if len(g.pre_df) == 0:
dataset_pre = dataset.copy()
else:
dataset_pre = g.pre_df
dataset_pre.index = dataset_pre.code
dataset_pre = dataset_pre.drop('code', axis=1)
X_train = dataset_pre.drop('market_cap', axis=1)
y_train = dataset_pre['market_cap']
dataset_train = dataset.copy()
dataset_train.index = dataset_train.code
dataset_train = dataset_train.drop('code', axis=1)
X_test = dataset_train.drop('market_cap', axis=1)
y_test = dataset_train['market_cap']
#这里我们使用随机森林来训练模型
reg = RandomForestRegressor(random_state=200)
reg.fit(X_train, y_train)
# 找到模型市值比预测值低最多的股票
y_pred = pd.DataFrame(reg.predict(X_test), index=y_test.index, columns=['market_cap'])['market_cap']
factor = y_test - y_pred
final_list = list(factor.sort_values(ascending=True).index)
# 过滤停牌、ST、退市标签和退市公告股票
final_list = filter_paused_stock(final_list)
final_list = filter_st_stock(final_list)
target_stocks = final_list[:min(len(final_list),g.stock_num)]
message = '需要购买的股票为:\n {}'.format('\n'.join(target_stocks))
send_message(message, channel='weixin')
g.target_buy_stocks = target_stocks
g.pre_df = dataset
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!