Mybatis分页插件之PageHelper生效and失效原理解析
文章目录
| Mybatis拦截器系列文章: |
|---|
| 从零开始的 MyBatis 拦截器之旅:实战经验分享 |
| 构建自己的拦截器:深入理解MyBatis的拦截机制 |
| Mybatis分页插件之PageHelper原理解析 |
前言
PageHelper是一个优秀的Mybatis分页插件,它可以帮助我们自动完成分页查询的工作。它的使用非常简单,只需要在查询之前调用PageHelper.startPage方法,传入页码和每页大小,就可以实现分页效果。PageHelper还提供了很多其他的配置和功能,例如排序、合理化、分页参数映射等。
那么,PageHelper是如何实现分页功能的呢?本文将从源码的角度,一步步分析PageHelper的实现原理,希望能够对大家有所帮助。
整合PageHelper
整合 PageHelper 并不难,先导入 PageHelper 的依赖:
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper</artifactId>
<version>5.1.11</version>
</dependency>
之后给 MyBatis 配置上 PageHelper 的核心拦截器:
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean">
<property name="dataSource" ref="dataSource"/>
<property name="configLocation" value="classpath:mybatis-config.xml"/>
<property name="typeAliasesPackage" value="com.apple.entity"/>
<property name="plugins">
<list>
<bean class="com.github.pagehelper.PageInterceptor">
<property name="properties">
<props>
<prop key="helperDialect">mysql</prop>
<prop key="reasonable">true</prop>
</props>
</property>
</bean>
</list>
</property>
</bean>
之后在需要分页查询的位置前面,加上一句话:
PageHelper.startPage(1, 2);
List<Department> departmentList = departmentMapper.findAll();
这样运行的时候,PageHelper 就起作用了:
[main] DEBUG extra.DepartmentMapper.findAll - ==> Preparing: SELECT * FROM tbl_department WHERE (isdel = 0) LIMIT ?
[main] DEBUG extra.DepartmentMapper.findAll - ==> Parameters: 2(Integer)
[main] DEBUG extra.DepartmentMapper.findAll - <== Total: 2
可以发现 SQL 的最后有 limit 的后缀,只查了两条数据。
PageHelper生效原理
它的基本原理是通过拦截Executor,StatementHandler,ParameterHandler和ResultSetHandler这四个对象,修改原始的sql语句,增加limit和count等语句,从而实现分页效果。
我们仅仅加上 PageHelper.startPage(1, 2); 这句代码,分页就生效了,那一定是这句代码的背后发生了重要的事情,我们可以跟进去看一下。
PageHelper的分页参数和线程绑定
public static <E> Page<E> startPage(int pageNum, int pageSize) {
return startPage(pageNum, pageSize, DEFAULT_COUNT);
}
public static <E> Page<E> startPage(int pageNum, int pageSize, boolean count) {
return startPage(pageNum, pageSize, count, null, null);
}
public static <E> Page<E> startPage(int pageNum, int pageSize, boolean count, Boolean reasonable, Boolean pageSizeZero) {
Page<E> page = new Page<E>(pageNum, pageSize, count);
page.setReasonable(reasonable);
page.setPageSizeZero(pageSizeZero);
// 当已经执行过orderBy的时候
Page<E> oldPage = getLocalPage();
if (oldPage != null && oldPage.isOrderByOnly()) {
page.setOrderBy(oldPage.getOrderBy());
}
//将Page对象绑定到当前线程的局部变量中
setLocalPage(page);
return page;
}
自上而下调用直至最底下的方法,而最底下的方法中有一句代码我们要着重的去看:setLocalPage(page);
protected static final ThreadLocal<Page> LOCAL_PAGE = new ThreadLocal<Page>();
protected static void setLocalPage(Page page) {
LOCAL_PAGE.set(page);
}
这句源码将当前的分页内容设置到了 ThreadLocal 中!那就意味着,当前线程的任意位置都能取到分页的两个参数了。
核心拦截逻辑
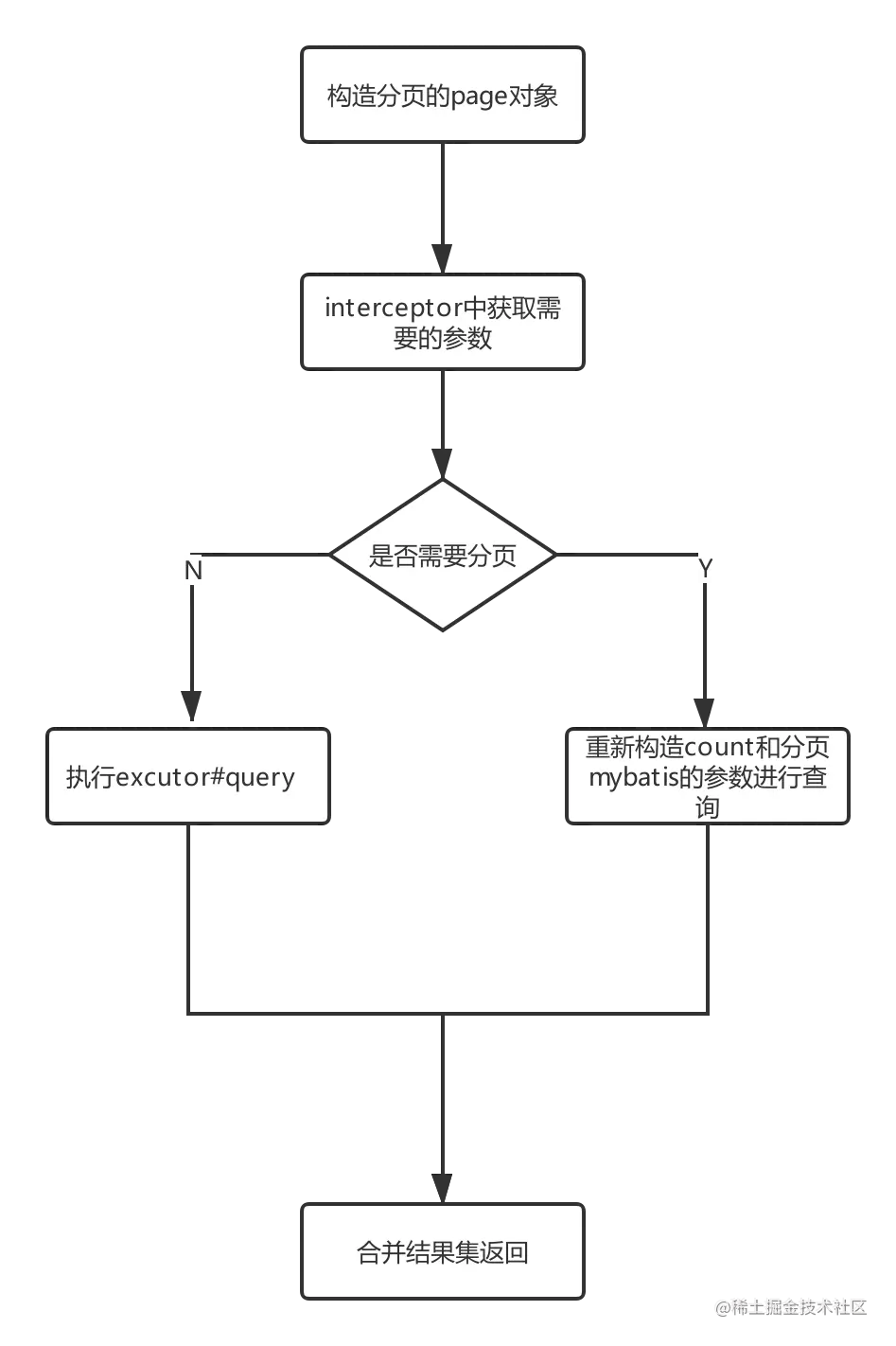
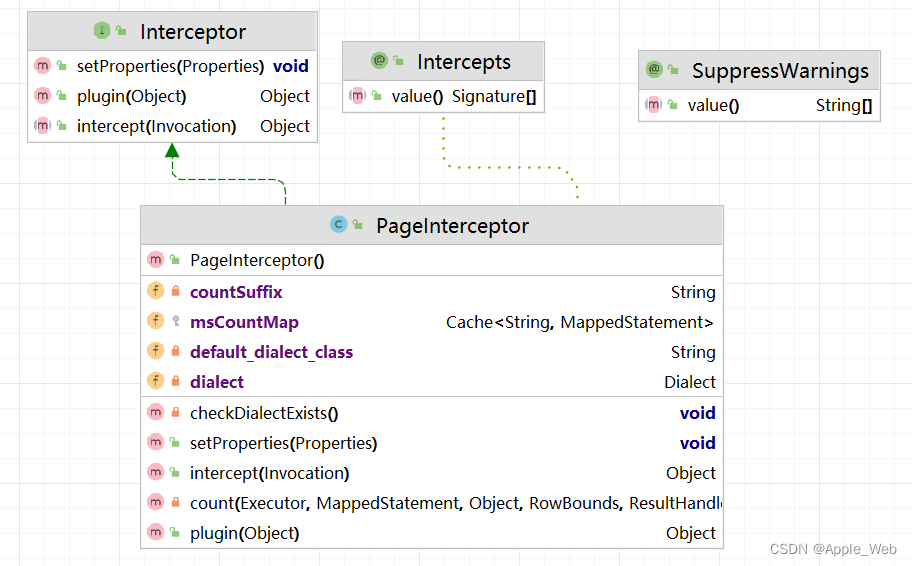
线程中有了分页的参数,下面执行到 PageHelper 的核心拦截器中,就可以顺势取出了,我们来到 PageInterceptor 中:
拦截方法主要做了两件事,一件执行countBoundsql获得count,一件执行pageBoundSql获得resultList。
@Override
public Object intercept(Invocation invocation) throws Throwable {
try {
Object[] args = invocation.getArgs();
MappedStatement ms = (MappedStatement) args[0];
Object parameter = args[1];
RowBounds rowBounds = (RowBounds) args[2];
ResultHandler resultHandler = (ResultHandler) args[3];
Executor executor = (Executor) invocation.getTarget();
CacheKey cacheKey;
BoundSql boundSql;
// 由于逻辑关系,只会进入一次
if (args.length == 4) {
// 4 个参数时
boundSql = ms.getBoundSql(parameter);
cacheKey = executor.createCacheKey(ms, parameter, rowBounds, boundSql);
} else {
// 6 个参数时
cacheKey = (CacheKey) args[4];
boundSql = (BoundSql) args[5];
}
checkDialectExists();
List resultList;
// 调用方法判断是否需要进行分页,如果不需要,直接返回结果
if (!dialect.skip(ms, parameter, rowBounds)) {
// 判断是否需要进行 count 查询
if (dialect.beforeCount(ms, parameter, rowBounds)) {
// 查询总数
Long count = count(executor, ms, parameter, rowBounds, resultHandler, boundSql);
// 处理查询总数,返回 true 时继续分页查询,false 时直接返回
if (!dialect.afterCount(count, parameter, rowBounds)) {
// 当查询总数为 0 时,直接返回空的结果
return dialect.afterPage(new ArrayList(), parameter, rowBounds);
}
}
// 【看这里!!!】
resultList = ExecutorUtil.pageQuery(dialect, executor,
ms, parameter, rowBounds, resultHandler, boundSql, cacheKey);
} else {
// rowBounds用参数值,不使用分页插件处理时,仍然支持默认的内存分页
resultList = executor.query(ms, parameter, rowBounds, resultHandler, cacheKey, boundSql);
}
return dialect.afterPage(resultList, parameter, rowBounds);
} finally {
if(dialect != null){
dialect.afterAll();
}
}
}
大段的源码虽然长,但是 PageHelper 毕竟是我们自己人的产品,注释都是中文的看起来也友好的多。这里们我们最应该关注的动作,是中间偏下的,有方括号标注的那个静态方法调用:ExecutorUtil.pageQuery 。
public static <E> List<E> pageQuery(Dialect dialect, Executor executor, MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql, CacheKey cacheKey) throws SQLException {
// 判断是否需要进行分页查询
if (dialect.beforePage(ms, parameter, rowBounds)) {
// 生成分页的缓存 key
CacheKey pageKey = cacheKey;
// 处理参数对象
parameter = dialect.processParameterObject(ms, parameter, boundSql, pageKey);
// 调用方言获取分页 sql
String pageSql = dialect.getPageSql(ms, boundSql, parameter, rowBounds, pageKey);
BoundSql pageBoundSql = new BoundSql(ms.getConfiguration(), pageSql, boundSql.getParameterMappings(), parameter);
Map<String, Object> additionalParameters = getAdditionalParameter(boundSql);
// 设置动态参数
for (String key : additionalParameters.keySet()) {
pageBoundSql.setAdditionalParameter(key, additionalParameters.get(key));
}
// 执行分页查询
return executor.query(ms, parameter, RowBounds.DEFAULT, resultHandler, pageKey, pageBoundSql);
} else {
// 不执行分页的情况下,也不执行内存分页
return executor.query(ms, parameter, RowBounds.DEFAULT, resultHandler, cacheKey, boundSql);
}
}
注意这个 if 结构的逻辑,它是先生成一条带有分页片段的新 SQL ,之后封装为一个全新的 BoundSql ,交给 Executor 执行。所以我们可以总结为一点:分页插件的工作核心其实就是偷梁换柱!将原有的 SQL 替换为带分页语法的 SQL ,交给 Executor ,而 Executor 本身不会感知到,所以最后查询得到的就是分页之后的数据了。
另外调用方言获取分页 SQL 的动作,这句代码,会将原有的全表查询,修饰为分页片段查询,这是分页 SQL 的核心生成逻辑,我们一定要进去看看。
生成分页SQL
这个分页 SQL 的生成,又是体现着模板方法的设计了,我们进入 dialect.getPageSql 方法中:
// AbstractHelperDialect
public String getPageSql(MappedStatement ms, BoundSql boundSql, Object parameterObject, RowBounds rowBounds, CacheKey pageKey) {
String sql = boundSql.getSql();
Page page = getLocalPage();
//支持 order by
String orderBy = page.getOrderBy();
if (StringUtil.isNotEmpty(orderBy)) {
pageKey.update(orderBy);
sql = OrderByParser.converToOrderBySql(sql, orderBy);
}
if (page.isOrderByOnly()) {
return sql;
}
return getPageSql(sql, page, pageKey);
}
上面支持 order by 语法的逻辑我们就不关心了,主要是来看最后一句 getPageSql 的实现,
这个方法本身是一个模板方法,它的实现有好多个:
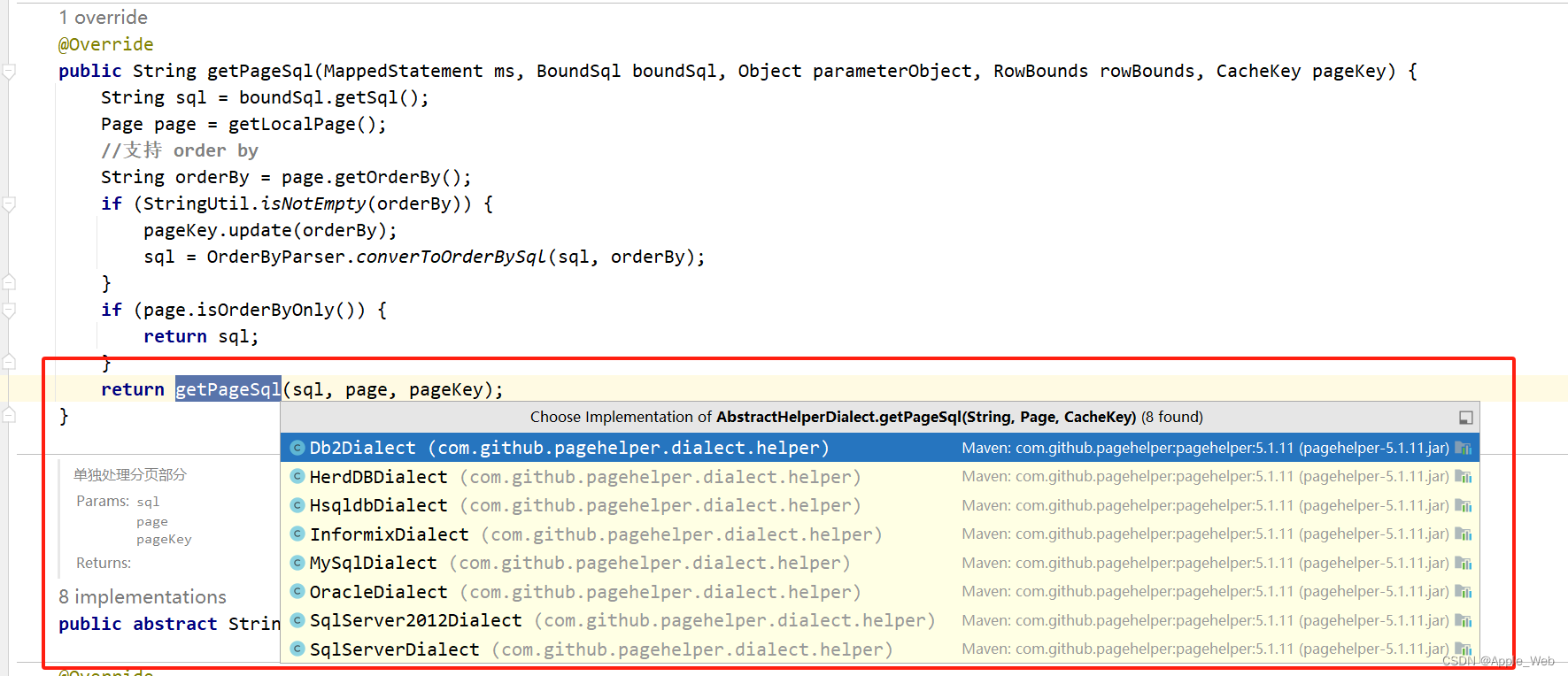
而我们目前正在使用的 MySQL 的实现如下:
// MySqlDialect
public String getPageSql(String sql, Page page, CacheKey pageKey) {
StringBuilder sqlBuilder = new StringBuilder(sql.length() + 14);
sqlBuilder.append(sql);
if (page.getStartRow() == 0) {
sqlBuilder.append(" LIMIT ? ");
} else {
sqlBuilder.append(" LIMIT ?, ? ");
}
return sqlBuilder.toString();
}
MySQL 的分页语法是非常简单的了,只需要拼接 limit 参数就 OK 。
走到这里,分页 SQL 也就生成了,分页查询也就随之进行了。
以上就是 PageHelper 的基本原理,可以发现本身不难,其实我们来实现也是完全没问题的,我们完全可以仿照着 PageHelper 的实现机制,自己动手写一个。
dialect.afterAll()
讲这个是为了说明理解的PageHelper为什么有时候会失效
在最开始的PageInterceptor的try finally代码块中,有个
try{...}
} finally {
if(dialect != null){
// 最终执行的是清空ThreadLocal<Page>操作,LOCAL_PAGE.remove()
dialect.afterAll();
}
}
最终执行的是清空ThreadLocal< Page>操作,LOCAL_PAGE.remove()
public void afterAll() {
//这个方法即使不分页也会被执行,所以要判断 null
AbstractHelperDialect delegate = autoDialect.getDelegate();
if (delegate != null) {
delegate.afterAll();
autoDialect.clearDelegate();
}
clearPage();
}
PageHelper失效原理
分页失效案例
如下代码所示: 执行后,我们会发现departmentList2查询出来的是全量查询,并没有分页
PageHelper.startPage(1, 2);
List<Department> departmentList = departmentMapper.findAll();
List<Department> departmentList2 = departmentMapper.findAll();
分页失效原理
从上面讲到的生效原理,我们可以知道:
-
判断是否支持分页主要是根据能否存在
ThreadLocal<Page>,如果没有则不进行分页操作。 -
我们的每个mapper查询都会经过拦截器处理,拦截器处理的最后一步是
dialect.afterAll(),最终执行的是LOCAL_PAGE.remove(),即移除本地变量。 -
这也就是为什么案例中执行第一个mapper查询会按照指定页数和每页显示条数查询出对应分页数据(因为存在
ThreadLocal<Page>),而第二个mapper查询的是所有(因为第一个mapper查询完成之后会将ThreadLocal<Page>进行清除)。
清楚原因之后如何处理就简单了。如果同一个方法中多个mapper都需要支持分页操作,那都保证每个mapper前面都进行ThreadLocal<Page>初始化赋值操作。修改后代码如下:
PageHelper.startPage(1, 2);
List<Department> departmentList = departmentMapper.findAll();
PageHelper.startPage(1, 2);
List<Department> departmentList2 = departmentMapper.findAll();
总结
对指定mapper查询支持分页,前面一定要有PageHelper.startPage(currentPage,pageSize),不能有其他mapper查询,否则会失效!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!