分库分表之Mycat应用学习五
5 Mycat 离线扩缩容
当我们规划了数据分片,而数据已经超过了单个节点的存储上线,或者需要下线节
点的时候,就需要对数据重新分片。
5.1 Mycat 自带的工具
5.1.1 准备工作
1、mycat 所在环境安装 mysql 客户端程序。
2、mycat 的 lib 目录下添加 mysql 的 jdbc 驱动包。
3、对扩容缩容的表所有节点数据进行备份,以便迁移失败后的数据恢复。
5.1.2 步骤
以取模分片表 sharding-by-mod 缩容为例

1、复制 schema.xml、rule.xml 并重命名为 newSchema.xml、newRule.xml 放
于 conf 目录下。
2、修改 newSchema.xml 和 newRule.xml 配置文件为扩容缩容后的 mycat
配置参数(表的节点数、数据源、路由规则)。
注意:
只有节点变化的表才会进行迁移。仅分片配置变化不会迁移。
newSchema.xml
<table name="sharding_by_mod" dataNode="dn1,dn2,dn3" rule="qs-sharding-by-mod" />
改成(减少了一个节点):
<table name="sharding_by_mod" dataNode="dn1,dn2" rule="qs-sharding-by-mod" />
newRule.xml 修改 count 个
<function name="qs-sharding-by-mod-long" class="io.mycat.route.function.PartitionByMod">
<property name="count">2</property>
</function>
3、修改 conf 目录下的 migrateTables.properties 配置文件,告诉工具哪些表需要进行扩容或缩容,没有出现在此配置文件的 schema 表不会进行数据迁移,格式:
注意,1)不迁移的表,不要修改 dn 个数,否则会报错。
2)ER 表,因为只有主表有分片规则,子表不会迁移。
catmall=sharding-by-mod
4、dataMigrate.sh 中这个必须要配置
通 过 命 令 “find / -name mysqldump” 查 找 mysqldump 路 径 为"/usr/bin/mysqldump",指定#mysql bin 路径为"/usr/bin
#mysql bin 路径
RUN_CMD="$RUN_CMD -mysqlBin= /usr/bin/
5、停止 mycat 服务
6、执行执行 bin/ dataMigrate.sh 脚本
注意:必须要配置 Java 环境变量,不能用 openjdk
7 、 脚 本 执 行 完 成 , 如 果 最 后 的 数 据 迁 移 验 证 通 过 , 就 可 以 将 之 前 的
newSchema.xml 和 newRule.xml 替换之前的 schema.xml 和 rule.xml 文件,并重启 mycat 即可
注意事项:
1)保证分片表迁移数据前后路由规则一致(取模——取模)。
2)保证分片表迁移数据前后分片字段一致。
3)全局表将被忽略。
4)不要将非分片表配置到 migrateTables.properties 文件中。
5)暂时只支持分片表使用 MySQL 作为数据源的扩容缩容。
migrate 限制比较多,还可以使用 mysqldump。
5.2 mysqldump 方式
系统第一次上线,把单张表迁移到 Mycat,也可以用 mysqldump。
MySQL 导出
mysqldump -uroot -p123456 -h127.0.0.1 -P3306 -c -t --skip-extended-insert gpcat > mysql-1017.sql
-c 代表带列名
-t 代表只要数据,不要建表语句
–skip-extended-insert 代表生成多行 insert(mycat childtable 不支持多行插入ChildTable multi insert not provide)
Mycat 导入
mysql -uroot -p123456 -h127.0.0.1 -P8066 catmall
Mycat 导出
mysqldump -h192.168.8.151 -uroot -p123456 -P8066 -c -t --skip-extended-insert catmall customer > mycat-cust.sql
其他导入方式:
load data local infile ‘/mycat/customer.txt’ into table customer;
source sql ‘/mycat/customer.sql’;
6 核心流程总结
官网的架构图
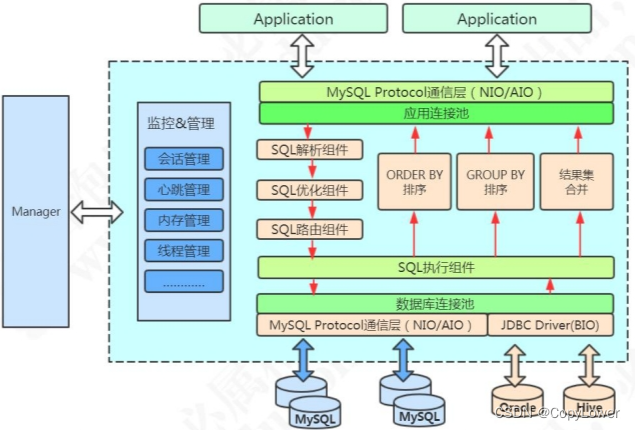
6.1 启动
1、MycatServer 启动,解析配置文件,包括服务器、分片规则等
2、创建工作线程,建立前端连接和后端连接
6.2 执行 SQL
1、前端连接接收 MySQL 命令
2、解析 MySQL,Mycat 用的是 Druid 的 DruidParser
3、获取路由
4、改写 MySQL,例如两个条件在两个节点上,则变成两条单独的 SQL
例如 select * from customer where id in(5000001, 10000001);
改写成:
select * from customer where id = 5000001;(dn2 执行)
select * from customer where id = 10000001;(dn3 执行)
又比如多表关联查询,先到各个分片上去获取结果,然后在内存中计算
5、与后端数据库建立连接
6、发送 SQL 语句到 MySQL 执行
7、获取返回结果
8、处理返回结果,例如排序、计算等等
9、返回给客户端
6.3 源码下载与调试环境搭建
6.3.1 下载源代码,导入工程
git clone https://github.com/MyCATApache/Mycat-Server
6.3.2 配置
schema.xml
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="true" sqlMaxLimit="100">
<table name="travelrecord" dataNode="dn1,dn2,dn3" rule="auto-sharding-long" />
<table name="company" primaryKey="ID" type="global" dataNode="dn1,dn2,dn3" />
<table name="hotnews" primaryKey="ID" autoIncrement="true" dataNode="dn1,dn2,dn3" rule="mod-long" />
</schema>
<dataNode name="dn1" dataHost="localhost1" database="db1" />
<dataNode name="dn2" dataHost="localhost1" database="db2" />
<dataNode name="dn3" dataHost="localhost1" database="db3" />
<dataHost name="localhost1" maxCon="20" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="127.0.0.1:3306" user="root" password="123456">
</writeHost>
</dataHost>
</mycat:schema>
6.3.3 表结构
本地数据库创建 db1、db2、db3 数据库,全部执行建表脚本
CREATE TABLE `company` (
`id` bigint(20) NOT NULL AUTO_INCREMENT, `name` varchar(64) DEFAULT '', `market_value` bigint(20) DEFAULT '0', PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8mb4;
CREATE TABLE `hotnews` (
`id` bigint(20) NOT NULL AUTO_INCREMENT, `title` varchar(64) DEFAULT '', `content` varchar(512) DEFAULT '0', `time` varchar(8) DEFAULT '', `cat_name` varchar(10) DEFAULT '', PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `travelrecord` (
`id` bigint(20) NOT NULL AUTO_INCREMENT, `city` varchar(32) DEFAULT '', `time` varchar(8) DEFAULT '', PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
6.3.4 逻辑表配置
travelrecord 表配置
<table name="travelrecord" dataNode="dn1,dn2,dn3" rule="auto-sharding-long" />
<tableRule name="auto-sharding-long">
<rule>
<columns>id</columns>
<algorithm>rang-long</algorithm>
</rule>
</tableRule>
<function name="rang-long" class="io.mycat.route.function.AutoPartitionByLong">
<property name="mapFile">autopartition-long.txt</property>
</function>
hotnews 表配置
<table name="hotnews" primaryKey="ID" autoIncrement="true" dataNode="dn1,dn2,dn3" rule="mod-long" />
<tableRule name="mod-long">
<rule>
<columns>id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!-- how many data nodes -->
<property name="count">3</property>
</function>
company 表配置
<table name="company" primaryKey="ID" type="global" dataNode="dn1,dn2,dn3" />
6.3.5 debug 方式启动
debug 方式启动 main 方法
Mycat-Server-1.6.5-RELEASE\src\main\java\io\mycat\MycatStartup.java
6.3.6 连接本机 Mycat 服务
测试语句
insert into travelrecord(`id`, `city`, `time`) values(1, '长沙', '20191020');
insert into hotnews(`title`, `content`) values('咕泡', '盆鱼宴');
insert into company(`name`, `market_value`) values('spring', 100);
6.3.7 调试入口
连接入口:
io.mycat.net.NIOAcceptor#accept
SQL 入口:
io.mycat.server.ServerQueryHandler#query
Step Over 可以看到上一层的调用
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!