管道进行进程间通信(上)
管道进行进程间通信
在posix和system V标准还没有出现的时候,进程间是如何进行通信的呢?这就要借助于我们今天学习的这个东西了。在进程间通信的标准没有出现之前,在os中就已经存在了文件了。而管道就是基于文件的一种进行进程间通信的方式。
什么是管道
首先一个文件是可以被一个进程打开并访问的,那么现在的问题是一个文件能否被多个进程打开并访问呢?如果能的话,那么这个文件不就是一个共享的空间吗?只要一个进程往这个文件中写数据,然后另外一个进程从这个文件中读取数据。不就实现了将一个数据从一个进程移动到另外一个进程上了吗?但是使用这种基于一个实体文件的方式有一个致命的缺点那就是,没写一个数据到文件中,这个数据就需要先刷新到磁盘上,然后再从磁盘将这个数据写到内存中,让另外一个进程读取这个数据。这样的方式就会伴生出很多的效率问题。但是我们可以借助这个思想。只不过这次我们的这个文件不会将数据往磁盘上去做刷新,因为并没有人规定一定要将将文件中的数据写到磁盘上。我们只使用内存也能够完成使用管道通信。

在上图中的那个|我们就称之为管道,将who打印出的信息交给wc -l命令,这是我在刚开始学习指令的时候就使用过的管道。上面的这个命令能够查看我们当前的这个系统正在被多少人使用 。
我们通过下面的几个步骤来学习管道这个东西。
下面我们来学习管道的原理:

管道的原理
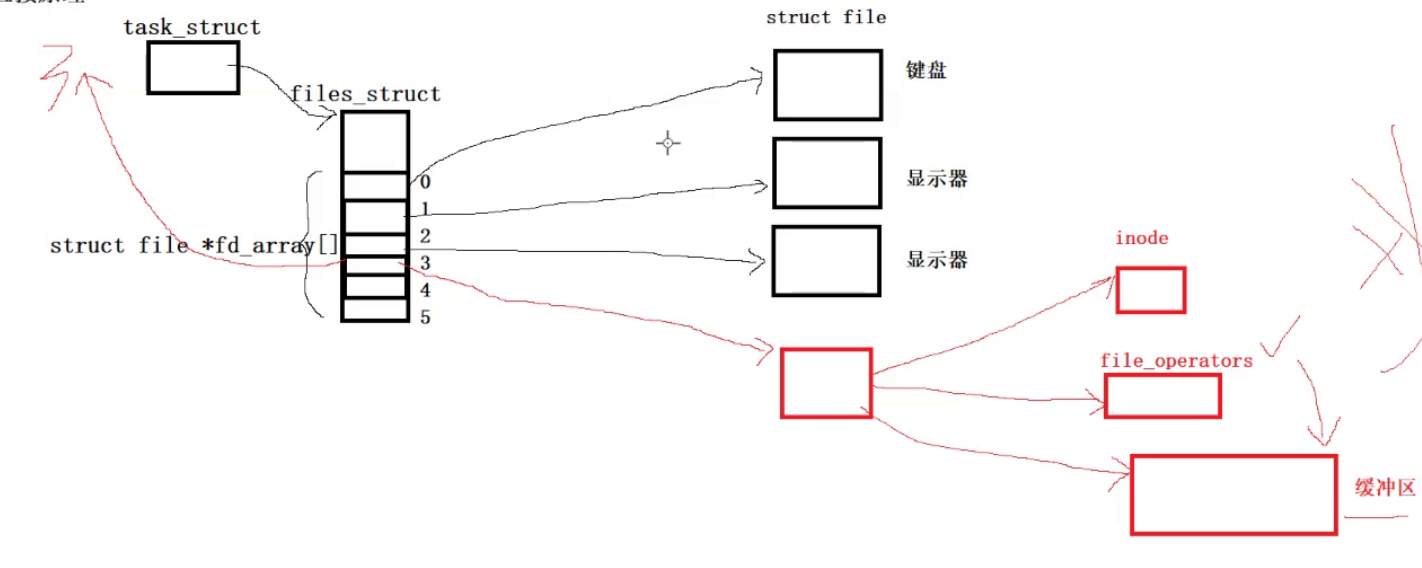
首先每一个进程都会存在自己的task_struct 对象然后会存在一个文件描述符表,这个表中保存的就是一个一个的的file文件指针。因为是在数组中这些文件指针就自然有了下标,进程每打开一个文件,被打开的文件就会创建一个struct file对象。而默认打开的文件存在三个分别是stdin(标准输入){终端},stdout(标准输出){终端 },stderr(标准错误)分别对应数组的0,1,2下标。而通过改变0,1下标中的内容就能完成输入和输出重定向。
在某一个pcb对象打开一个文件的时候,会在数组的3号下标中(0 1 2中已经有值了,文件描述符的分配是从最小的未被使用的优先被使用)储存这个新打开文件的文件指针,同时将这个下标返回到上层。此时的上层就得到了一个新打开的文件。
而一个文件需要提供自己详细的属性。然后就是对应的操作这个文件的对应的方法集。然后就是每一个文件都需要有自己的文件页缓冲区。如果这个被打开的文件在磁盘中是存在的,那么就会根据磁盘中储存的这个文件的属性和数据去预加载对应的inode对象和文件页缓冲区。以供打开文件的进程来进行读写数据。在你完成写入之后,文件缓冲区中的数据和磁盘中这个文件的数据不一致,我们称之为“脏数据”(Dirty Data)。然后将这个脏数据刷新到磁盘中去,就完成了对这个文件的写入(落盘的过程)。如果你是要读取这个文件在磁盘中的数据,os也需要先将磁盘中这个文件的数据加载到内存中再进行读取。也就是无论是读还是写,磁盘中的文件一定需要首先将数据写到内存中去。
图:

那么这里我们设想一下能否让一个文件,不需要去打开磁盘呢?即让这个文件真正的成为一个内存级文件。在技术上是有可行性的。即这种文件并不需要在磁盘中是存在的,只需要我们能够将其运用起来就可以了。当然这种文件自然也能挂接到文件系统上,让用户能够看到这个文件,但是我们需要记住的是这个文件并不存在于磁盘中只存在于内存中。以上是内存级文件的特性。
假设这里一个进程以读的方式打开这个内存级文件。
然后这个进程再创建自己的子进程。
那么对于这个子进程我们之前打开的一批文件(键盘,显示器,显示器,内存级别文件)需不需要重新拷贝一份给这个子进程呢?首先创建子进程的时候pcb对象和files_struct对象肯定是要进行拷贝的,因为files_struct表明的是一个进程所打开的文件的列表。所以如果创建了子进程那么files_struct肯定是需要被拷贝的。但是那一批文件是不需要拷贝的。因为文件系统就那个和对应的进程管理系统是同级别的关系。因此在创建了进程之后,(因为files_struct中的内容是一样的)子进程的files_struct也会指向父进程指向的那张表。

此时父子进程就会看到同一份资源(类似于浅拷贝)。
这就是为什么我们在创建了一个子进程(fork)然后在子进程中往显示器打印信息,和父进程往显示器打印信息,都会打印在同一个终端中而不是打印到其它的终端中(因为父子进程指向的就是这一个终端)。
而我们的进程间进行通信的前提条件就是:

如果这个条件都不能满足就不能进行进程间通信。
此时父子进程看到的这个内存级别的文件就是同一份资源。并且这个文件还存在自己对应的文件缓冲区。如果父进程往这个文件中写入,那么子进程就能够通过这个文件完成对数据的读取。此时的双方就完成了进程间的通信,当然这只是原理还是存在漏洞的。
所以结论:管道的本质就是内存级文件。
这里我们再思考一下如果我们的两个进程在通信的期间其中一方将这个管道文件关闭了,会不会影响另外一方呢?从我们刚刚讲解的原理来看大概率是存在这个问题的,但是os肯定也是考虑了这个问题的。如何解决呢?在一个文件的struct file对象中存在有一个int cnt的引用计数,这个计数的功能就是记录存在多少进程是打开这个文件的。此时如果我们的父进程关闭这个内存级别文件,因为cnt--之后并不为0,所以这里的这个内存级别文件是不会关闭的。
但是我们之前所提到过的那个情景时存在错误的,在上面的那个场景中,因为父进程是以读的方式打开的这个文件,那么由父进程创建的子进程自然也只能以读的方式打开这个内存级文件。如果是这样的话,是无法完成两个进程的通信的。那如果让进程在打开文件的时候以读写的方式打开呢?但是管道在设计的时候就不允许同时读写。
那么管道要如何进行通信呢?
那么此时我们就需要让父进程在打开共享文件的时候不能这么草率。我们的父进程在打开这个文件的时候,即以读的方式打开,又以写的方式打开。
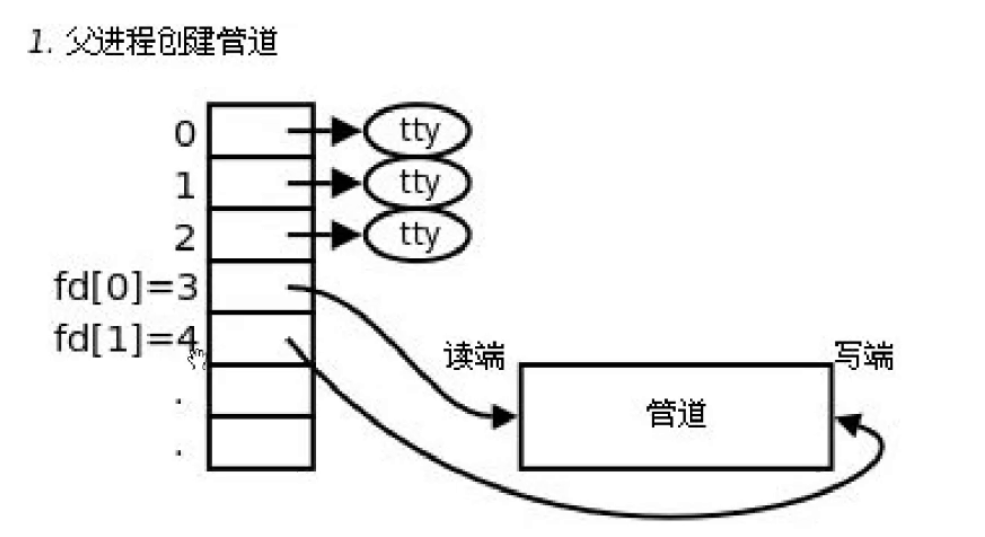
那么由此创建出来的子进程也是这样的。

然后再根据具体的场景你是需要让父进程写文件,子进程读文件(反之),来关闭两个进程打开的文件,这里我以父进程写,子进程读为例子。
那么父进程就会关闭fd[0](读取),而子进程就会关闭fd[1](写入)。达到上面的父进程写,而子进程读的效果。

此时就建立了一个通信信道。
以上也还只是理论而已。我们来看一下实际的管道是如何实现这个理论的。
首先是父进程以读的方式打开了这个文件:
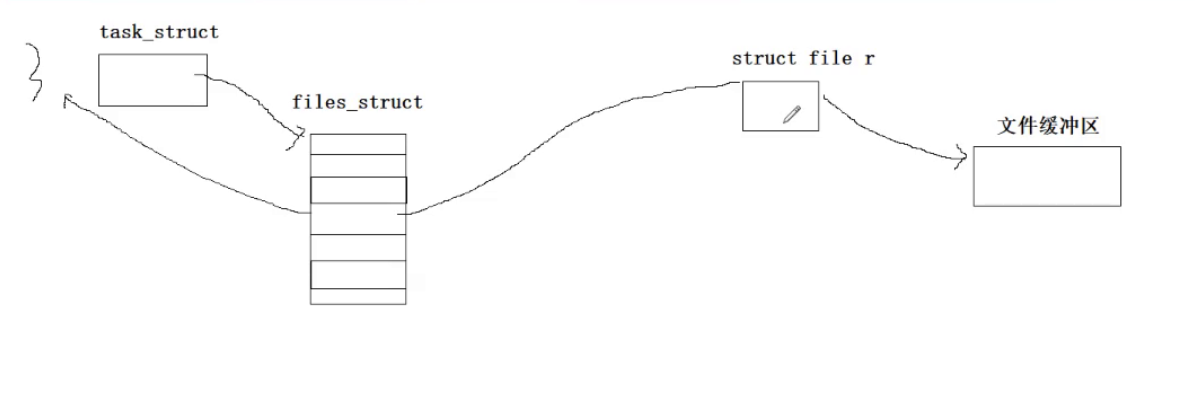
因为上面我们也看到了父进程是以读端和写端的方式打开的这个文件,现在读端已经就绪了,下面我们就需要再次打开这个文件,只不过是以写的方式打开。如果某一个进程再一次打开一个已经被自己打开的文件的时候,os还是会为这个文件再创建一个file对象的。 只不过这两个file对象指向的是同一个文件的inode对象,操作方法集,文件缓冲区。
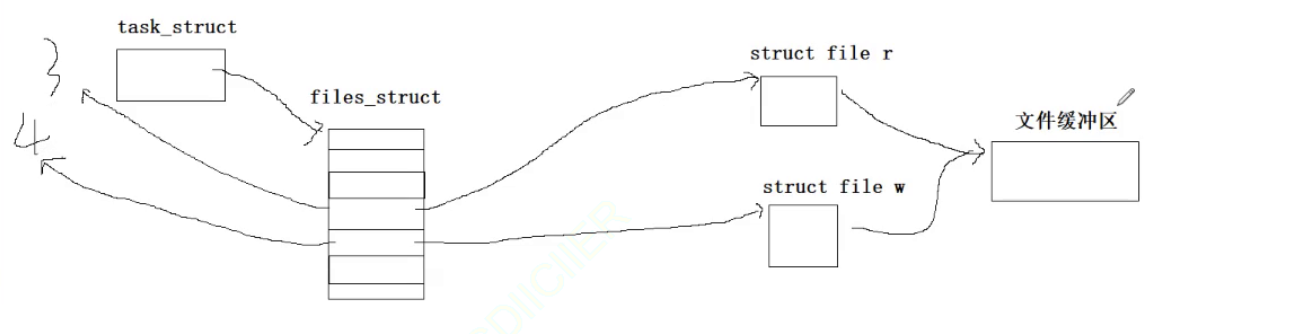
我们就这么理解(朴素性理解)。
此时我们再去创建对应的子进程。

那么如果管道支持一个进程既能读又能写,就可能会出现下面的这种情况,在父进程写好了数据之后,再去读数据发现读到的任然是自己的数据,这种情况是存在的。并且对于文件缓冲区中的数据,也不好区分这是谁写的数据,应该让谁来读取(因为管道就是为了完成通信啊)。当然要解决也是可以的,但是很麻烦。所以设计管道进行通信的设计者就做了一个规定。

这就是为什么进程间通信的时候,直接将文件这一套拿过来就进行了通信,设计者其实是可以创造一个新的专门的模块来进行进程间通信的。
最后就是为了简单才这么设计的。既然只能单向通信究竟是让父进程读还是写,就由用户来决定了。
这里假设我们想让子进程写,而父进程进行读取。

但是此时对应的父子进程其实不关闭对应的另外一个不需要的文件描述符其实也是可以的(只要两个进程都保证不会使用另外一个文件描述符即可)。但是可能难免会出现误操作,所以最好还是将另外一个不需要使用的文件描述符关闭比较好。
再关闭了之后我们就建立了一个管道:

并且因为我们将父子进程中的那个不需要使用的文件描述符关闭了,对应的file r和file w中的引用计数都成为了1,也就不会存在进程通信受到影响了。
而这才是管道真正的原理。
而正是因为这种单向通信的原因,所以才将这种实现进程通信的方式称之为管道。
这里需要注意是因为这种单向通信的性质我们才将这种方式命名为管道。为什么只能单向通信的呢?第一这是基于文件实现的进程通信,第二本来设计者就是图简单才设计的这种通信方式。然后才有了管道的名字。
那么如果我们需要进行双向通信呢?其中的一种方式就是建立多个管道。
这里我们在思考一下如果两个想要通信的进程没有任何的关系,可以使用我们在上面说的这个原理进行通信吗?不能
即管道通信必须是父子关系。

那么如果一个父进程创建了多个子进程,然后某一个子进程能否和自己的兄弟进程进行通信吗?当然可以。
由此能够得出结论使用管道进行通信的进程必须要具有血缘关系。那么这个内存级文件有名字吗?当然没有,因为这个文件并没有存在于磁盘中自然就不需要路径来标识它,也不需要inode编号。进行通信的进程是通过继承的方式来得到这一个内存级文件的。而这种管道我们就称之为匿名管道。
到这里通信了吗?没有因为还没有发送信息,我们所做的这些事情都是在建立通信信道。

以上我们就介绍了基本的理论。
下面我们来进行对应的接口介绍和编写代码验证上面的理论。
接口以及代码编写
下面我们就来介绍一个非常重要的接口函数。
pipe函数

这里的问题就是为什么这里是pipefd[2]呢?
因为这个是一个输出型参数这个函数会将某个进程的读写端创建好(对管道文件的读写端)包括管道文件file对象的传创建,然后将读写端对应的fd下标放到数组之后将这个数组返回到上层。

而返回的pipefd数组中的两个位置的内容就是下面的:

下面我们就来写代码。虽然我们下面使用的代码是c++的代码,但是在调用系统接口的时候,还是需要使用c的代码,所以我们需要训练好c和c++混编的技能。
下面我们就来完善makefile文件和检查初步使用一些pipe函数。
makefile文件

下面是我们要运行的代码:

运行的结果:

我们一定要记住在这个数组中1是写端,而0是读端。
下面我们需要进行进程间的通信就需要创建子进程了。
代码的大体框架如下:

除此之外,如果你要在c++代码中使用c的库函数那么需要增加类似下面这样的头文件。

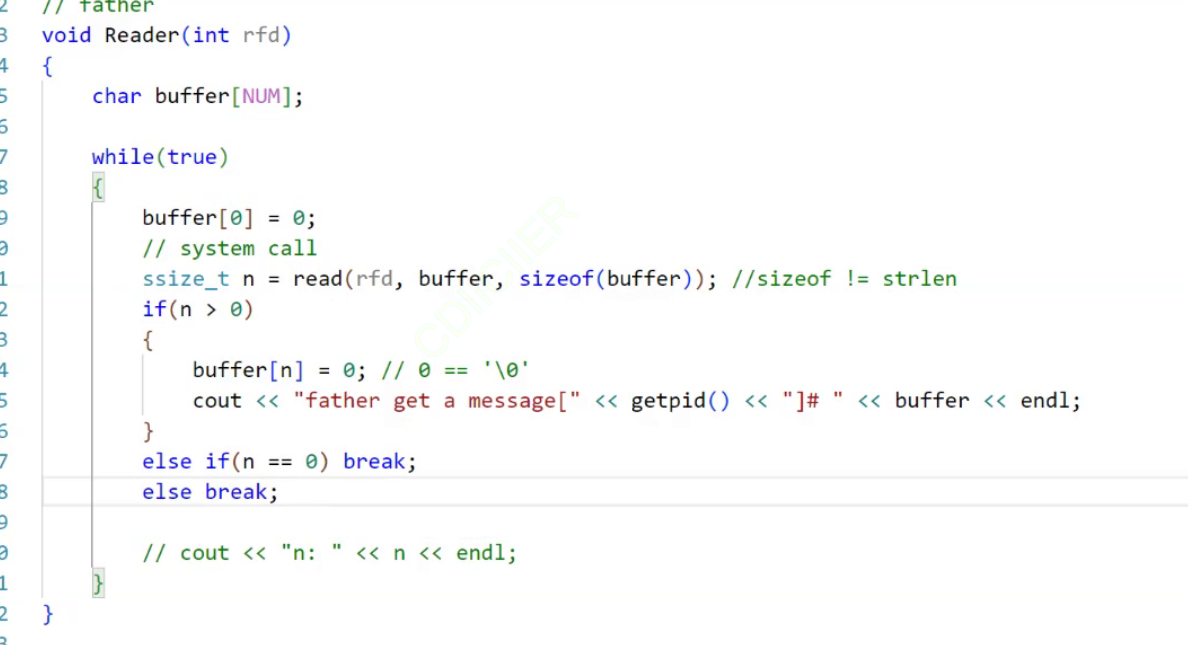
我们下面的目标就是完成Write和Read函数了。
Write函数
NUM是define定义的1024


然后我们编译运行一下是否运行成功了

这证明了在buff数组中确实是存在了这个信息,下面我们就会将这个信息写到管道文件中,最后我们的父进程就会读到上面的信息。
如何写呢?将buff发送到管道文件中,这也是Linux中一切皆是文件的好处,无论你要往磁盘写,还是往什么地方写,在Linux看来都是往一个文件中写,那么就可以使用write系统调用直接写。所以这里我们只需要使用write调用函数接口就可以了。
??write?? 函数的返回值,如果写入成功,返回值是写入的字节数。还有其它的可能我们暂时这里先不关心,后面再学习网络的时候再去研究

此时子进程就会每一秒往父进程写一段字符串。
下面我们就来完善父进程的Read函数

当然在有时候是存在buff被写满的情况的,但是我们这里暂时不考虑。我们就假设这个buff不会被写满。
最后我们运行一下:
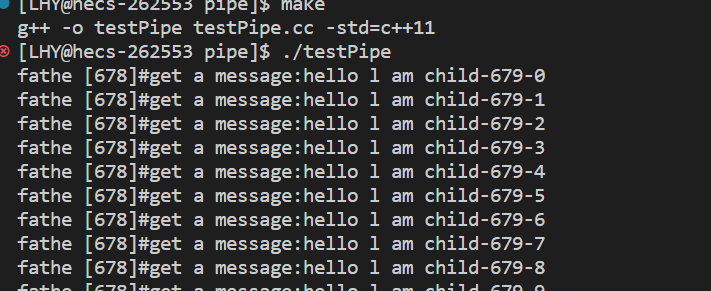
但是要让父进程和子进程都得到一个字符串还有一个方法那就是直接将这个字符串设置为全局的,不就让这个字符串既能让父进程得到又能让子进程得到了吗?但是这个方法只能传输静态的信息,如果我们这里传输的是一个动态的信息呢?正如我们上面将number加上了。如果使用的是全局的方法,其中一个进程对字符串进行了写入,就会发生写时拷贝,此时的另一个进程就得不到写入后的信息了。使用全局的那种方法只是单纯的将数据继承了下来,而不是达到了通讯的目的。
因为管道文件本质来说是操作系统的内核文件(资源由系统提供,而系统不相信父子进程),这个内核文件肯定是不会允许父子进程随意进行访问的。所以父进程在进行访问的时候需要使用系统调用read和write。防止父子进程对内核数据造成破坏。
那么父子进程在进行通讯的时候,通讯的信息经历了哪些次的拷贝呢?
首先在Write中将buff(用户层缓冲区中的数据)使用系统调用拷贝到了管道文件对应的文件缓冲区中。而Read函数中则是父进程将管道文件中的数据,使用系统调用将信息拷贝到了父进程的用户缓冲区中(这里没有考虑语言的缓冲区)。
所以答案是两次。从应用到内核再到用户。
也就是让管道文件充当了一个传话使的工作。
那么现在代码已经写了,我们就需要通过代码来得到管道的特征。
管道的特征
在讲解管道特征的同时我们会去伴生的了解一下管道通信的四种情况。
现在我们已经知道了两个管道通信的两个特征。

第三个我们回到上面写的代码可以看到在子进程的写端是具有sleep的但是在父进程的读端是没有sleep的。但是在运行的时候我们发现我们只是让我们的子进程每隔一秒打印一次,父进程为什么也是隔1秒才打印一次呢?父进程没有sleep。
原因1:如果父进程不关心缓冲区中是否是自己可以读取的信息就会发生读取到垃圾信息的情况。
因为缓冲区中是一定会存在二进制信息的,但是这个二进制信息不一定是父进程需要的信息。如果父进程会不断的读取缓冲区中的信息,就可能读取到垃圾信息。那么就会打印出乱码(上面的代码)。并且因为父进程不会去等待子进程,那么父进程会疯狂的打印。而子进程只会每隔一秒写入一条信息。但是事实上没有这个现象,也就是我的父进程是在
照顾子进程,如果父进程发现在缓冲区中没有自己需要的信息,那么父进程就会等到子进程写入。
下面我们将等待的时间改为50秒。再去编译运行一下。


可以看到在很长的时间里面父进程都是处于没有打印的情况的。说明父进程一直在等待子进程写入。
这说明了父子进程是会进行协同的。并不是各运行各自的。
在这里我们就能得到一个特征:首先我们得进程进行通讯的前提是需要让不同的进程看到同一份资源,那么这一份资源就是被多执行流共享的,那么就难免会出现冲突的情况。正如可能会出现你正在读的时候,又来写了,就可能出现将别人的数据覆盖的情况。这个问题也就是临界资源竞争的问题。后面会说明。这个问题导致的现象就是我们的父进程在前半段读了一个信息,但是在刚读取到的前半段的时候,后半段的信息已经被新的信息写入了,导致父进程读取的信息出错。
但是我们刚刚的实验证明了这个情况已经在os底层解决了原因就是我们黑体字说的
![]()
我们先记住这个结论就可以了。
总结下来我们的代码就是虽然子进程写的慢,但是父进程是会等待子进程的。父进程在没有数据的时候,是不会去进行读的。
那么反过来呢?如果我们的子进程在不停的写,而我们的父进程相隔很久才会读取又会发生什么呢?
在这里临时插入一个点,当我们的进程在读取管道中的数据的时候,对于读取完成的数据是会清理的,但是并不是使用0/什么其它的树去覆盖,而是代表这个被读取完的数据可以被覆盖了。
回到刚刚的那个代码,对于管道一共具有四种情况:
第一种情况我们刚刚已经演示了。

而第二种情况就是子进程在不停的写,而父进程相隔一段时间才会去读。


现在编译运行一下。

这里因为写端在不停的写,所以一瞬间就将管道写满了。因为写端已经将管道写满了,所以对应的2554这个数字就不再往上增长了。
这里就存在了一个子问题那就是管道是具有固定大小的?但是这个大小是多少呢?存在固定大小因为子进程一瞬间就将管道写满了。然后写端就被阻塞了。
总结就是:如果管道为空读端就需要等待,相反如果管道为满那么写端就要等待。但是我们这里的问题是:父子进程不是越好了只会读取字符串吗?怎么一瞬间就将这么一大串字符圈读取进来了。为什么父进程一次性就将这么多的数据一次全读取进来了呢?
因为我们这里的代码就是,父进程一次直接将所有写入的数据全部读进来,之前因为子进程写的慢,所以没有出现这种情况。而这里子进程写的是很快的,所以这里就直接将这么多的数据一起都进来了。
因为父进程不知道你要的是字符串,在父进程看来,它读取到的都是一个一个的字符。就算是之前能够一条一条打印也是因为子进程写的慢,而父进程读的块导致的。父进程并不知道这里需要读取的是一个字符串,在他看来自己读取的都是字符。在父进程看来分离这些字符串的工作是交给用户的。
由此我们就能得到最后一个特征了。
管道是面向字节流的
这个字节流在之后的博客我会说明。

也就是无论你的写端写多少的数据我的读端是不会管的。有可能读端会将写端写了好几次的数据一次性全部读取进来。在读端看来他读取的都是一大串的字符,而这些字符也就是我们说明的字节流。读端不会做任何的处理,对于这个字节流的处理读端是直接交给了用户的。
而为了处理这样的情况,就需要定制某些关于协议的东西。协议我也会在后面的博客详细说明。这里我们可以简单理解成我们让父子进程约定好读取多大,写多大即可。
最后还有一个特点,当我们的上面的父子进程结束之后,管道文件会自动地被os回收。

当进程都没有了,管道自然没有存在地必要了。
情况:

这两个情况也证明了,进行通信地两个进程是会进行协同的。
那么管道是多大呢?

在centeros7.6中管道大小是64kb。
在这里我们再次提出一个名词PIPE_BUF
??PIPE_BUF?? 是一个常量,定义在 ??<limits.h>?? 头文件中。它表示在 POSIX 系统中管道(pipe)的原子写入操作的最大字节数。
??PIPE_BUF?? 的值是系统特定的,表示了在一个原子写入操作中,保证不会被其他进程的写入操作中断或交叉写入的最大字节数。这个值通常是比较小的,例如在大多数 POSIX 系统中,它的值是 4096 字节。
当使用管道进行进程间通信时,写入操作可以分为多个写入调用,每次写入的字节数可能不同。但是,如果要确保多个写入操作不会被其他进程的写入操作中断或交叉写入,可以使用 ??PIPE_BUF?? 来限制每次写入的字节数。
请注意,即使写入的字节数小于 ??PIPE_BUF??,仍然可能发生写入操作被中断或交叉写入的情况。因此,对于需要确保原子写入的场景,需要使用其他机制来进行同步或加锁操作,以保证数据的完整性和一致性。
这里做了解即可,在后面的博客中我会详细的说明。
最后我们来看下一种情况。

也就是会告诉读端你已经读取完成了。需要做一下处理
那么最后一种情况还有其它很多的我还没说明的事情。我会在下一篇博客中写出。
写的不好请见谅,如果发现了任何错误欢迎指出。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!