计算机毕业设计:招聘推荐系统 协同过滤推荐算法 (源码+文档)?
毕业设计:2023-2024年计算机专业毕业设计选题汇总(建议收藏)
毕业设计:2023-2024年最新最全计算机专业毕设选题推荐汇总
🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业?。🍅
1、项目介绍
技术栈: Python语言、MySQL数据库、Django框架、协同过滤推荐算法、网络爬虫技术、前程无忧51job网站数据、基于用户的协同过滤推荐算法实现-userCF
Django用户协同过滤算法的就业推荐系统是一种基于Django框架开发的推荐系统。它利用协同过滤算法,根据用户的行为和偏好,为用户提供个性化的工作岗位推荐。
2、项目界面
(1)数据可视化分析1
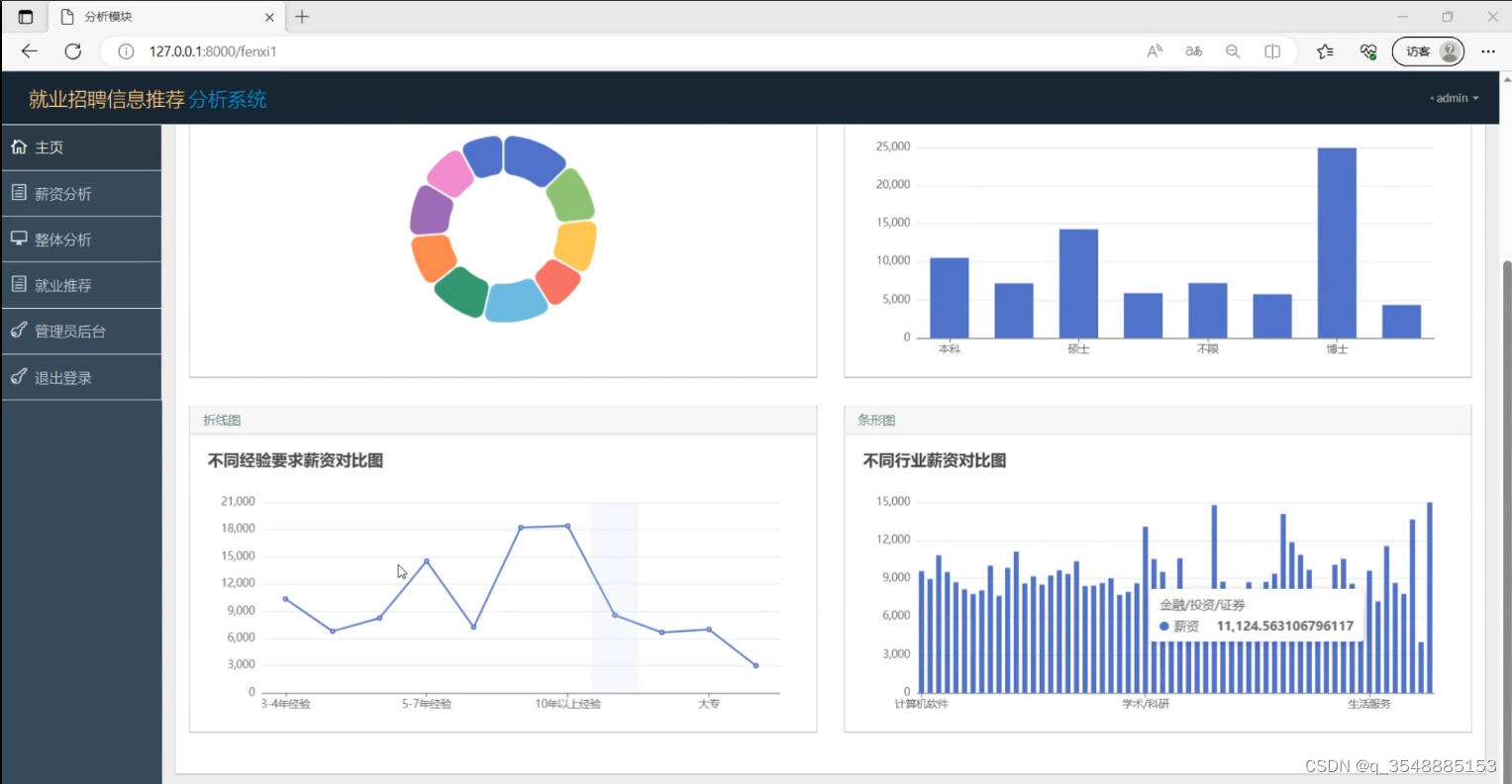
(2)数据可视化分析2
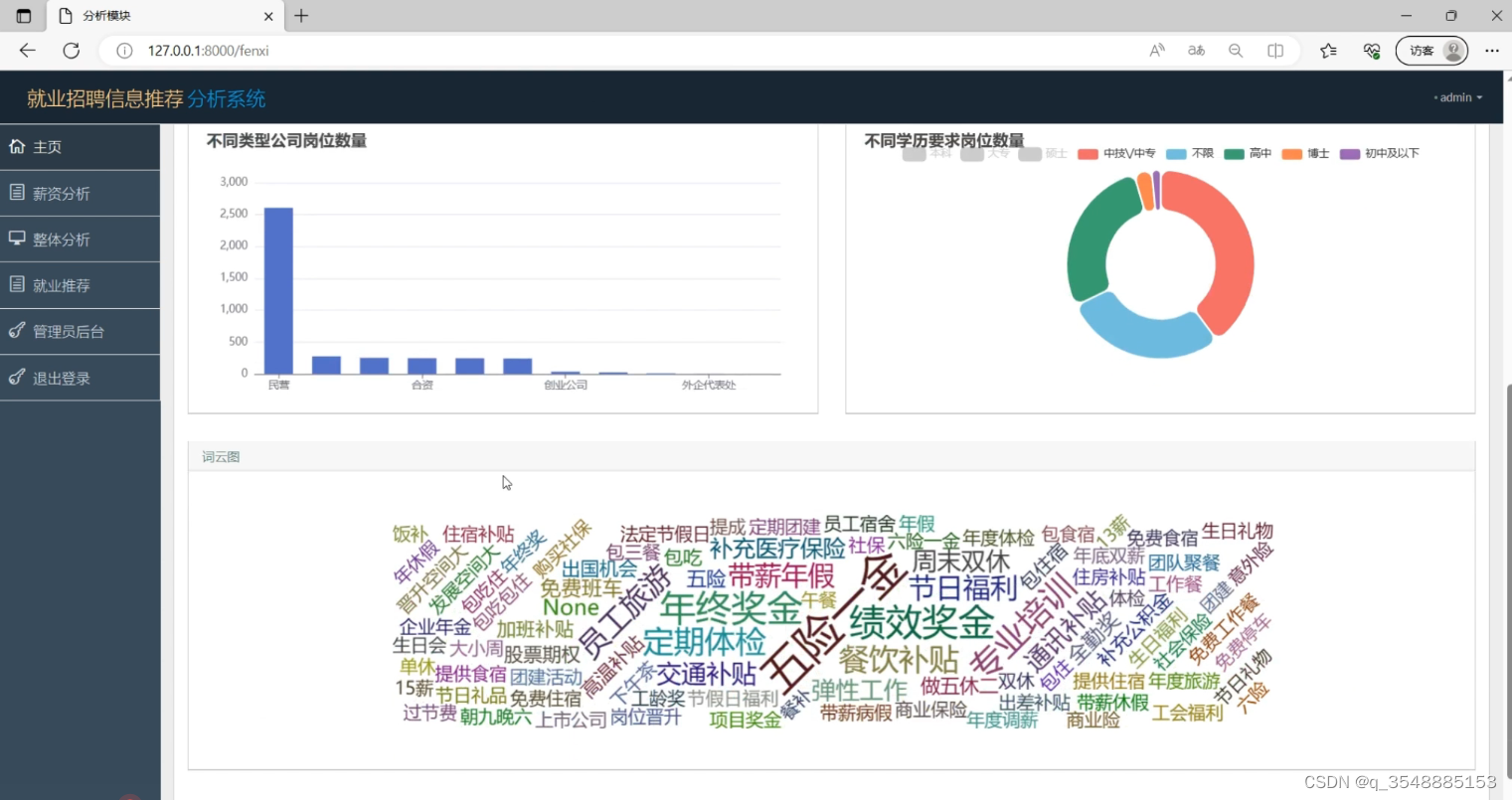
(3)招聘数据列表
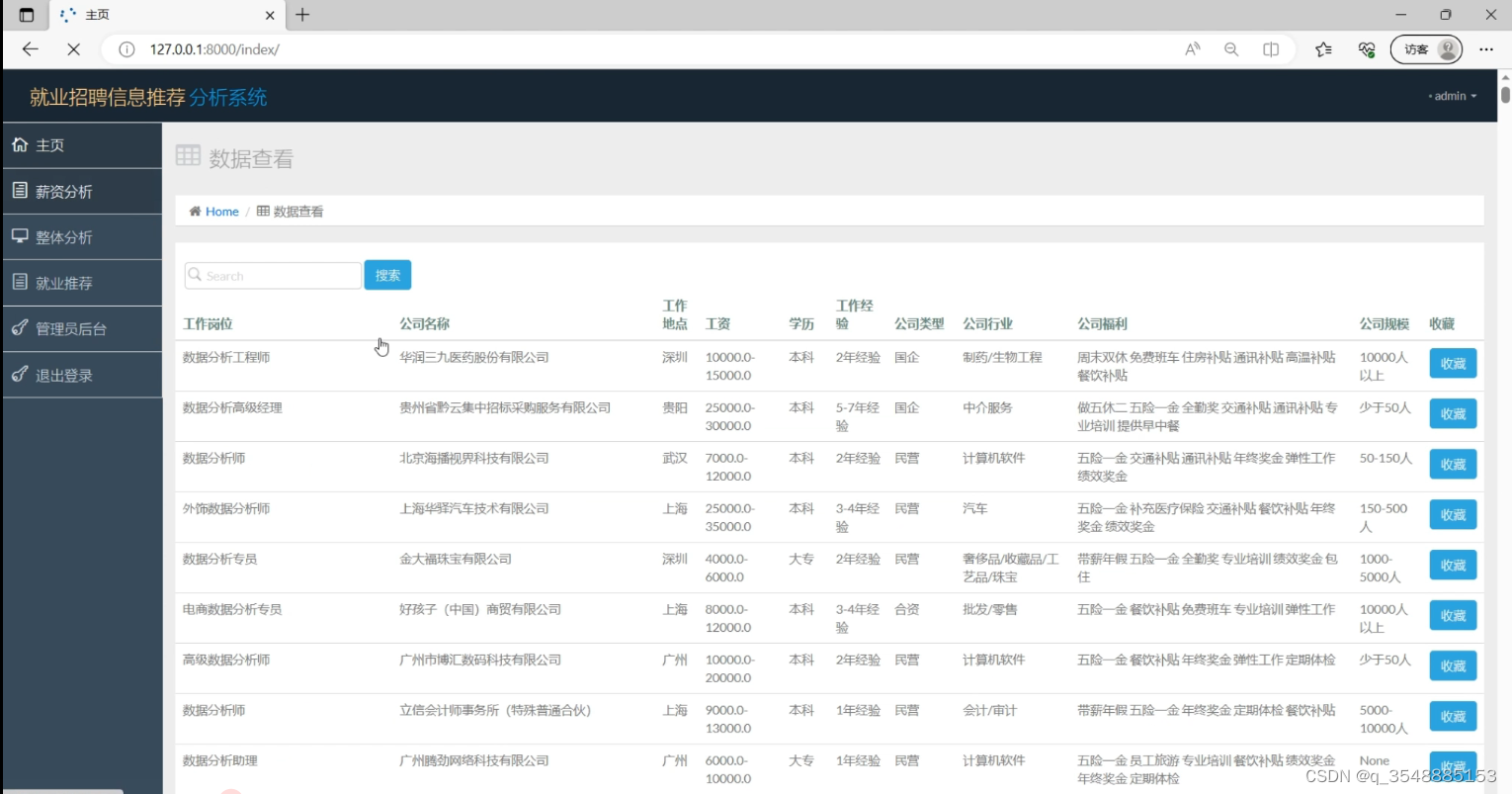
(4)招聘信息推荐(协同过滤推荐算法)
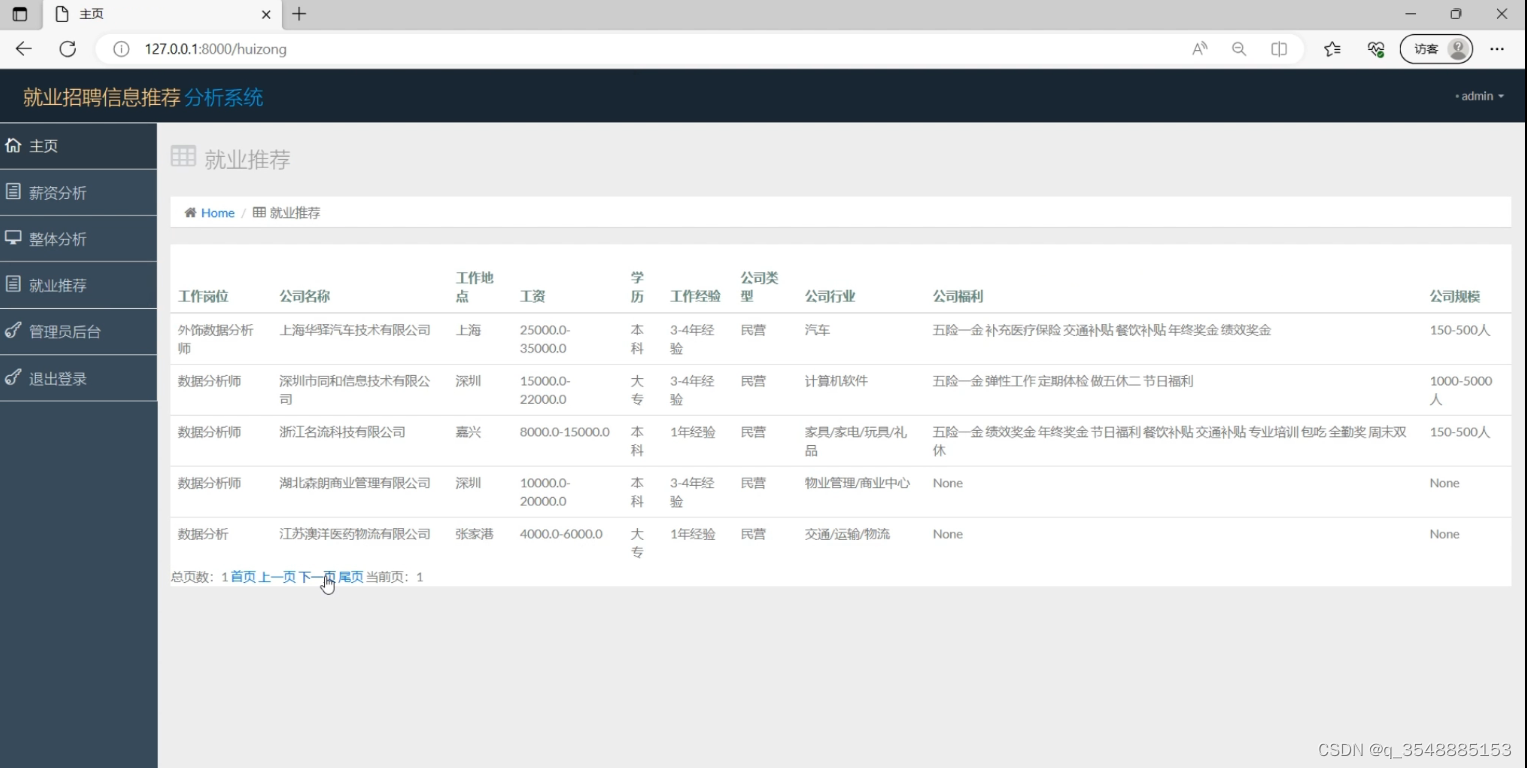
(5)注册登录界面
(6)后台数据管理
3、项目说明
Django用户协同过滤算法的就业推荐系统是一种基于Django框架开发的推荐系统。它利用协同过滤算法,根据用户的行为和偏好,为用户提供个性化的工作岗位推荐。
该系统的核心是协同过滤算法,它通过分析用户的历史行为和偏好,找到与其兴趣相似的其他用户,并将这些用户的喜好和行为应用到目标用户身上。通过比较用户之间的相似度,系统可以为每个用户生成个性化的工作岗位推荐列表。
在系统的实现过程中,Django框架提供了强大的功能和易于使用的工具,使开发者可以轻松构建用户界面、管理用户数据和实现推荐算法。同时,Django的模块化设计和灵活的扩展性,也为系统的优化和升级提供了便利。
为了保证系统的准确性和稳定性,该系统还可以利用用户的反馈信息进行实时调整和优化。用户可以对推荐结果进行评价和反馈,系统会根据这些反馈信息进行相应的调整,提供更符合用户需求的推荐结果。
总的来说,Django用户协同过滤算法的就业推荐系统是一种基于Django框架开发的个性化推荐系统,它利用协同过滤算法和用户反馈信息,为用户提供准确、个性化的工作岗位推荐。这个系统可以帮助用户更好地匹配就业需求,提高就业效率。
4、部分代码
# coding = utf-8
# 基于用户的协同过滤推荐算法实现
import csv
import random
import pymysql
import math
from operator import itemgetter
class UserBasedCF():
# 初始化相关参数
def __init__(self):
# 找到与目标用户兴趣相似的3个用户,为其推荐3部岗位
self.n_sim_user = 3
self.n_rec_job = 5
# 将数据集划分为训练集和测试集
self.trainSet = {}
self.testSet = {}
# 用户相似度矩阵
self.user_sim_matrix = {}
self.job_count = 0
print('Similar user number = %d' % self.n_sim_user)
print('Recommneded job number = %d' % self.n_rec_job)
# 读文件得到“用户-岗位”数据
def get_dataset(self, filename, pivot=0.75):
trainSet_len = 0
testSet_len = 0
for line in self.load_file(filename):
user, job, rating = line.split(',')
# if random.random() < pivot:
self.trainSet.setdefault(user, {})
self.trainSet[user][job] = rating
trainSet_len += 1
# else:
# self.testSet.setdefault(user, {})
# self.testSet[user][job] = rating
# testSet_len += 1
print('Split trainingSet and testSet success!')
print('TrainSet = %s' % trainSet_len)
print('TestSet = %s' % testSet_len)
# 读文件,返回文件的每一行
def load_file(self, filename):
with open(filename, 'r') as f:
for i, line in enumerate(f):
if i == 0: # 去掉文件第一行的title
continue
yield line.strip('\r\n')
print('Load %s success!' % filename)
# 计算用户之间的相似度
def calc_user_sim(self):
# 构建“岗位-用户”倒排索引
# key = jobID, value = list of userIDs who have seen this job
print('Building job-user table ...')
job_user = {}
for user, jobs in self.trainSet.items():
for job in jobs:
if job not in job_user:
job_user[job] = set()
job_user[job].add(user)
print('Build job-user table success!')
self.job_count = len(job_user)
print('Total job number = %d' % self.job_count)
print('Build user co-rated jobs matrix ...')
for job, users in job_user.items():
for u in users:
for v in users:
if u == v:
continue
self.user_sim_matrix.setdefault(u, {})
self.user_sim_matrix[u].setdefault(v, 0)
self.user_sim_matrix[u][v] += 1
print('Build user co-rated jobs matrix success!')
# 计算相似性
print('Calculating user similarity matrix ...')
for u, related_users in self.user_sim_matrix.items():
for v, count in related_users.items():
self.user_sim_matrix[u][v] = count / math.sqrt(len(self.trainSet[u]) * len(self.trainSet[v]))
print('Calculate user similarity matrix success!')
# 针对目标用户U,找到其最相似的K个用户,产生N个推荐
def recommend(self, user):
K = self.n_sim_user
N = self.n_rec_job
rank = {}
watched_jobs = self.trainSet[user]
# v=similar user, wuv=similar factor
for v, wuv in sorted(self.user_sim_matrix[user].items(), key=itemgetter(1), reverse=True)[0:K]:
for job in self.trainSet[v]:
if job in watched_jobs:
continue
rank.setdefault(job, 0)
rank[job] += wuv
return sorted(rank.items(), key=itemgetter(1), reverse=True)[0:N]
# 产生推荐并通过准确率、召回率和覆盖率进行评估
def evaluate(self):
print("Evaluation start ...")
N = self.n_rec_job
# 准确率和召回率
hit = 0
rec_count = 0
test_count = 0
# 覆盖率
all_rec_jobs = set()
# 打开数据库连接
db = pymysql.connect(host='localhost', user='root', password='123456', database='django_zhaopin', charset='utf8')
cursor = db.cursor()
# 使用 execute() 方法执行 SQL 查询
sql1 = "truncate table web_rec;"
cursor.execute(sql1)
db.commit()
sql = "insert into web_rec(user_id,job_id,score ) values (%s,%s,%s)"
for i, user, in enumerate(self.trainSet):
test_jobs = self.testSet.get(user, {})
rec_jobs = self.recommend(user)
print(user,rec_jobs)
for item in rec_jobs:
data=(user,item[0],item[1])
cursor.execute(sql, data)
db.commit()
#rec_jobs 是推荐后的数据
#把user-rec-rating 存到数据库
for job, w in rec_jobs:
if job in test_jobs:
hit += 1
all_rec_jobs.add(job)
rec_count += N
test_count += len(test_jobs)
cursor.close()
db.close()
# precision = hit / (1.0 * rec_count)
# recall = hit / (1.0 * test_count)
# coverage = len(all_rec_jobs) / (1.0 * self.job_count)
# print('precisioin=%.4f\trecall=%.4f\tcoverage=%.4f' % (precision, recall, coverage))
if __name__ == '__main__':
db = pymysql.connect(host='localhost', user='root', password='123456', database='django_zhaopin', charset='utf8')
cursor = db.cursor()
# 使用 execute() 方法执行 SQL 查询
sql = "select * from web_collect"
cursor.execute(sql)
data = cursor.fetchall()
cursor.close()
db.close()
with open('rating.csv','w',encoding='utf-8',newline='') as f:
writer = csv.writer(f)
writer.writerow(['userId','jobId','rating'])
for item in data:
writer.writerow([item[2], item[1],1])
rating_file = 'rating.csv'
userCF = UserBasedCF()
userCF.get_dataset(rating_file)
userCF.calc_user_sim()
userCF.evaluate()
5、源码获取
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!