NLP论文阅读记录 - 02 | 2022 自动文本摘要方法:综合回顾
文章目录
前言

Automatic Text Summarization Methods: A Comprehensive Review
0、论文摘要
由于互联网的快速发展而出现的最紧迫的问题之一是信息过载。以摘要的形式简化相关信息将对很多人有所帮助,因为任何主题的材料在互联网上都很丰富。手动总结大量文本对人类来说相当具有挑战性。因此,它增加了对更复杂和更强大的摘要器的需求。自 20 世纪 50 年代以来,研究人员一直在尝试改进创建摘要的方法,以使机器生成的摘要与人类创建的摘要相匹配。本研究对文本摘要概念进行了详细的最新分析,例如摘要方法、使用的技术、标准数据集、评估指标和未来的研究范围。最普遍接受的方法是提取和抽象,在这项工作中进行了详细研究。评估摘要并增加可重复使用资源和基础设施的开发有助于比较和复制研究结果,增加竞争以改善结果。本研究还讨论了生成摘要的不同评估方法。最后,在本研究的结尾,提到了与文本摘要研究相关的几个挑战和研究机会,这可能对该领域的潜在研究人员有用。
关键词: 自动文本摘要、自然语言处理、文本摘要系统分类、抽象文本摘要、抽取式文本摘要、混合文本摘要、文本摘要系统评估
一、Introduction
将一段文本压缩为较短版本、最小化原始文本的大小同时保留关键信息方面和内容含义的任务称为摘要。图1以简单的方式展示了总结任务。摘要是通过提取或生成将源文本还原为摘要文本(Radev 等,2004)。根据另一个定义,“自动摘要是由软件生成的文本,该文本是连贯的,并且包含来自源文本的大量相关信息。其压缩率 τ 小于原始文档长度的三分之一(Hovy & Lin,1996)。摘要的长度与源文档的长度之比由压缩率τ计算,如下所示:
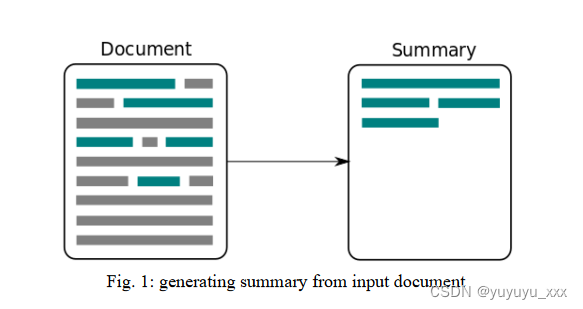
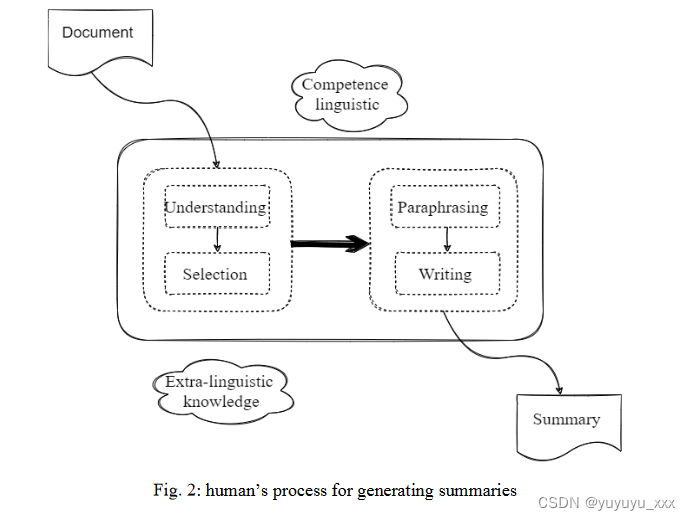
理解源文本并创建其简短的缩写版本是人类生成摘要的两个过程。图 2 显示了人类如何生成原始文本文档的摘要。理解材料和生成摘要都需要摘要者的语言和语言外能力和知识。尽管人们可以写出更好的摘要(在可读性、内容、形式和简洁性方面)。自动文本摘要是对手动摘要的有用补充而不是替代。
1.1文本摘要的要求
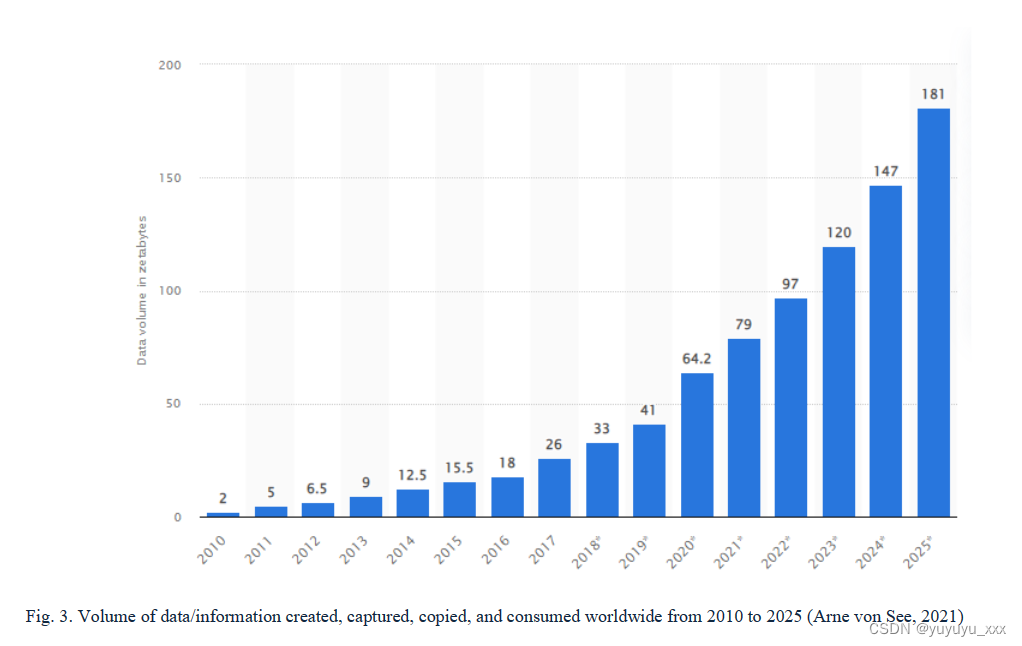
“太多的信息会杀死信息”这句格言在今天和以往一样具有现实意义。事实上,互联网有多种语言可供使用,这一事实只会增加上述文档分析的挑战。自动文本摘要有助于有效处理人类无法处理的不断增加的数据量。让我们看看 Arne von See (2021) 提供的关于数据世界的一些令人大开眼界的事实,如图 1 所示。 3. 一些事实是:在过去的两年里,世界上 90% 的数据已经被创建。大多数企业只查看 12% 的数据。每年,不良数据给美国造成 3.1 万亿美元的损失。到 2025 年,创建的数据量将超过 180 ZB。现在要从互联网上下载所有材料,人类需要大约 1.81 亿年的时间。
有几个支持文档自动摘要的正当理由。这里只列出了一些(Ab 和 Sunitha,2013 年)
总结可以节省阅读时间。
二.摘要有助于在进行研究时选择文件。
三.使用自动摘要时索引会更成功。
四.与人类摘要者相比,自动摘要系统的偏见较小。
v. 因为它们提供个性化信息,所以个性化摘要在问答系统中非常重要。
六.商业摘要服务可以通过使用自动或半自动摘要技术来提高可以处理的文本数量。
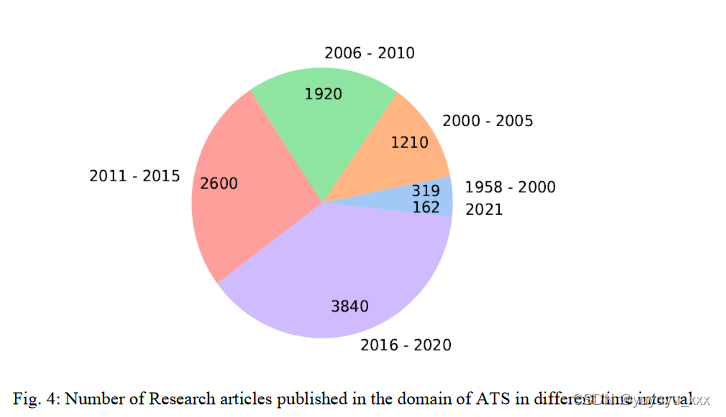
自动文本摘要(ATS)是一个相对较新的学习问题,引起了人们的广泛兴趣。随着研究的进展,我们希望看到一项突破,通过及时提供总结大文本的技术来帮助实现这一目标。我们对这项工作中的文本摘要技术进行了概述,以强调它们在处理大量数据方面的有用性,并帮助研究人员使用它们来应对挑战。图。图4显示了从1958年开始的特定时间间隔内文本摘要领域发表的研究论文数量。
1.2主要研究贡献
这项工作为文本摘要领域提供了简洁、当前和易于理解的观点。
本研究的主要贡献如下:
从地面开始,让读者熟悉 ATS 系统以及为什么我们需要 ATS 系统。提供了文献中针对每种应用提出的 ATS 系统示例,并说明了 ATS 系统的分类。
b.详细分析了提取式、抽象式和混合式三种 ATS 方法。此外,审查表是根据数据集、方法、性能、优点和缺点等因素构建的。
C。概述了标准数据集,并提供了有关 ATS 系统可用评估方法的完整详细信息。 d.详细分析文本摘要的挑战和未来范围。
本文分为六个部分。第 1 节讨论自动文本摘要系统的介绍及其要求和应用。自动文本摘要分为许多类别,将在第 2 节中详细讨论。接下来,第 3 节重点介绍提取式、抽象式和混合式文本摘要。第4节讨论了系统生成的摘要的评估方法。随后第5节列出了摘要任务中常用的数据集。最后,第6节给出了结论。
二.ATS的分类
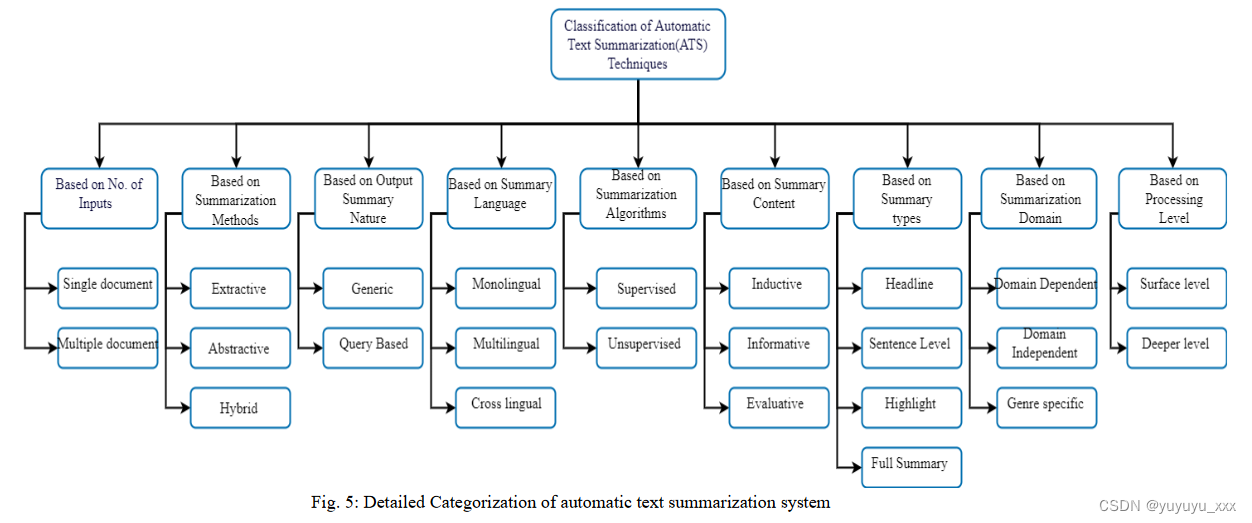
自动文本摘要 (ATS) 系统根据其输入、输出、用途、长度、算法、领域和语言有不同的分类。在讨论摘要的分类时,还可以考虑许多其他因素。不同的研究人员考虑了不同的因素。根据我们的调查,ATS 系统的详细分类如图 1 所示。 5. 对特定类别的详细解释将在以下小节中讨论:
2.1基于没有。输入文档的数量
根据用于生成摘要的输入源文档的大小,摘要可分为两种类型:
? 单文档:单文档文本摘要是对单个文档信息的自动摘要(Garner,1982)
? 多文档:多文档文档文本摘要是对多个文档信息的自动摘要(Ferreira et al., 2014)。
多文档摘要非常重要,我们必须将不同类型的观点放在一起,并且每个想法都以多个视角写在单个文档中。单文档文本摘要很容易实现,但多文档摘要是一项复杂的任务。冗余是汇总多个文档时最大的问题之一。 Carbonell & Goldstein (1998)给出了MMR(最大边际相关性)方法,这有助于减少冗余。多文档摘要的另一个主要问题是大量文档中的异质性。在现实世界中存在如此多的冲突和偏见的情况下,用提取方法总结多个文档是非常复杂的。对于多个文档,抽象摘要的表现要好得多。然而,多文档摘要也带来了诸如在处理大量文档时输出摘要冗余等问题。单文档文本摘要用于有限的领域,例如阅读给定的理解并给出适当的标题或摘要。相比之下,多文档文本摘要可用于不同站点的新闻摘要、不同供应商的客户产品评论、问答系统等领域。
SummCoder(Joshi 等人,2019)是一种用于通用提取单文档文本摘要的新方法。该方法根据他们制定的三个标准创建摘要:句子内容相关性、??句子新颖性和句子位置相关性。新颖性度量是通过利用分布式语义空间中嵌入表示的句子之间的相似性来产生的,并且使用深度自动编码器网络来评估句子内容相关性。句子位置相关性度量是一项自定义功能,由于由文档长度控制的动态权重计算方法,它赋予最初的几个短语更多的权重。在提取式多文档文本摘要领域,Sanchez-Gomez 等人。 (2021)表明,最流行的术语加权方案和相似性度量的所有可行组合都已得到实施、比较和评估。使用DUC数据集进行实验,并使用八个ROUGE指标和执行时间评估模型的性能。 TF-IDF 加权方案和余弦相似度的组合给出了 87.5% ROUGE 分数的最佳结果。
2.2 基于总结方法
根据生成摘要的方法,即从源文本中提取句子或在阅读源文本后生成新句子或两者的结合,摘要可以分为三种类型:
? 抽取式自动文本摘要:抽取式文本摘要是从给定语料库中连接提取摘要的策略(Rau et al., 1989)。
? 抽象自动文本摘要:抽象文本摘要涉及对给定语料库进行释义并生成新句子(Zhang 等人,2019)。
? 混合自动文本摘要:它结合了提取和抽象方法。这意味着从给定的语料库中提取一些句子并生成一个新的句子(Binwahlan et al., 2010)。
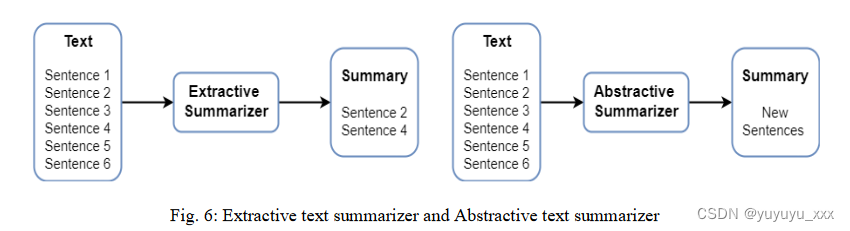
想象一下用来指出书中重要句子的荧光笔。这是提取文本摘要的一个示例。现在想想我们用自己的话从书中准备的笔记。这是抽象文本摘要的一个例子。提取文本摘要就像从源文本中复制粘贴一些重要的句子,而抽象文本摘要选择一些有意义的句子并从先前选择的句子生成新句子。请参阅图 6 以更好地理解提取和抽象摘要。混合文本摘要结合了一种有效生成摘要的方法。提取式和抽象式文本摘要都属于机器学习和 NLP 领域。此外,抽象文本摘要涵盖了 NLG。本文的后面部分显示了对这两种方法的调查。应用提取文本摘要的关键领域是新闻、医学、书籍、法律文档、抽象文本摘要、客户评论、博客、推文摘要等。
提取文本摘要模型的优点是摘要中的句子必须遵守句法结构的约束。然而,该模型的缺点是摘要的句子可能没有语义意义。出现这个缺点是因为摘要中的相邻句子在原文中并不总是连续的。由于ATS模型学习单词之间的搭配,并在训练后根据单词之间的搭配构建关键词序列,因此具有包容性语义的优势。 ATS 模型的缺点是很难满足此关键字序列的句法结构标准。生僻词是传统 ATS 模型的另一个主要缺陷。一个生僻词出现的次数及其搭配将定义它的重要性,但人类会使用其他元素来评估一个词是否是必要的。因此,在某些情况下,一些不经常出现的单词可能被认为不重要,尽管从人类的角度来看,这些单词的一部分对于摘要构建至关重要(Song et al., 2019b)。
2.3 基于输出摘要性质:
根据输出摘要的特征,ATS 系统可分为两种类型:
? 通用:通用文本摘要器从一个或多个文档中获取重要信息,以提供给定文档的简明含义(Aone 等人,1997)
?基于查询:构建基于查询的摘要器来处理多文档,并根据用户的查询提供解决方案(Van Lierde & Chow,2019)。每个文档中句子的分数基于基于查询的文本摘要中单词或短语的频率计数。包含查询短语的句子比包含单个查询词的句子获得更高的分数。提取得分最高的句子及其结构上下文以用于输出摘要(Kiyani & Tas,2017)。
基于查询的句子提取算法如下(Pembe & Güng?r,2007):
根据得分对所有句子进行排名。
二.将文档的主标题添加到摘要中。
三.将第一个 1 级标题添加到摘要中。
四.同时(未超出摘要大小限制)
v. 添加下一个得分最高的句子。
六.添加句子的结构上下文:(如果有且尚未包含在摘要中)
vii。在提取的文本上方添加最高级别的标题(将此标题称为 h)。
八.在同一级别的 h 之前添加标题。
九.在同一级别的 h 之后添加标题。
X。对后续最高级别标题重复步骤 7、8 和 9。 xi.结束时
通用摘要中不使用查询。由于他们没有全面评估原始文档,因此基于查询的摘要存在偏见。它们对于内容概述来说并不理想,因为它们只处理用户查询。通用摘要对于指定文档的类别和描述文档的要点是必要的。文件的关键主题在最佳总体摘要中得到考虑,力求尽可能减少冗余(Kiyani & Tas,2017)。
2.4 基于摘要语言
根据ATS系统输入和输出的语言,可以分为以下3类:
? 单语:在单语文本摘要器中,输入文档和输出摘要的语言是相同的(Kutlu等人, 2010)。
? 多语言:在多语言文本摘要生成器中,输入以多种语言(印地语、英语和古吉拉特语)编写,输出摘要同样以这些语言生成(Hovy & Lin,1996)。
? 跨语言:在跨语言文本摘要器中,输入文档采用一种语言(例如英语),输出摘要采用另一种语言(例如印地语)(Linhares Pontes 等人,2020)。
本文研究的大多数研究论文都是基于单语文本摘要。与单语相比,多语言和跨语言实施起来具有挑战性。在不止一种语言结构上训练机器需要付出更多的努力。 SUMMARIST (Hovy & Lin, 1996) 是一个基于提取策略的多语言文本摘要系统,可从英语、印度尼西亚语、西班牙语、德语、日语、韩语和法语来源生成摘要。跨语言文本摘要 (CLTS)(Linhares Pontes 等人,2020)根据源语言材料生成目标语言的摘要。它需要文本摘要和机器翻译方法的结合。不幸的是,这种组合会导致错误,从而降低摘要的质量。 CLTS系统可以通过联合分析从源语言和目标语言中提取相关信息,从而改进提取式跨语言摘要的开发。最近的 CLTS 方法提供了压缩和抽象方法;然而,这些方法依赖于仅在几种语言中可用的框架或工具,限制了它们对其他语言的适用性。
2.4.1 基于摘要算法
根据用于生成摘要的实际算法,ATS 系统分为以下两种类型:
? 监督式:监督式摘要器需要通过人工标记输入文本文档来训练样本数据(内托等人,2002)。
? 无监督:在无监督摘要训练阶段不需要(Alami 等人,2019)。
为了从受监督系统的文档中选择重要内容,需要训练数据。训练数据是学习技术所需的大量标记或注释数据。这些系统被视为句子级别的二类分类问题,正样本是属于摘要的句子,负样本是不属于摘要的句子。另一方面,无监督系统不需要任何训练数据。他们只需查看他们想要查看摘要的文档即可创建摘要。因此,它们可以与任何新观察到的数据一起使用,而不需要额外的调整。这些系统使用启发式方法来提取相关句子并构建摘要。聚类用于无监督系统(Gambhir & Gupta,2017)。
Nikita (2016) 给出了一种基于单文档监督机器学习的印地语方法。这些句子分为四类:最有影响力、重要、不太重要和无关紧要。然后使用 SVM 监督机器学习算法训练摘要器,以根据特征向量提取重要句子。然后根据所需的压缩率将句子包含在最终摘要中。该实验针对宝莱坞、政治、体育等不同类别的新闻报道进行,结果显示,压缩比为 50% 时准确率为 72%,压缩比为 25% 时准确率为 60%。最近,Meknassi 等人研究了一种无监督神经网络方法。 (2021) 用于阿拉伯语文本摘要。提出了一种使用文档聚类、主题建模和无监督神经网络的新方法来构建有效的文档表示模型,以克服阿拉伯文本文档带来的问题。所提出的方法在埃塞克斯阿拉伯文摘要语料库上进行了评估,并与使用 ROUGE 度量的其他阿拉伯文本摘要方法进行了比较。
2.5 基于摘要内容
根据输出摘要内容的类型,系统分为两部分:
? 归纳式:指示性摘要仅包含有关源文档的一般概念(Bhat 等人,2018)。
? 信息性:信息性摘要包含有关原始文档的所有主要主题(Bhat 等人,2018)。
? 评价性或批判性:它从作者的角度对给定主题进行总结(Jezek & Steinberger,2008)。
归纳总结用于指示文档的全部内容,旨在让用户了解是否阅读该原始文档。此摘要的长度约为原始内容的 5%。信息摘要系统简洁地总结了原文。有用的摘要大约占整个文本长度的 20%(Kiyani & Tas,2017)。评价性摘要的一个典型例子是评论,但它们远远超出了当今摘要者的范围。应该强调的是,上述三组并不是相互排斥的,而是具有信息性和指示性作用的共同摘要。信息性摘要经常被用作指示性摘要的子集(Jezek & Steinberger,2008)。
2.6 基于摘要类型
根据生成摘要的长度,ATS 系统分为以下四种类型:
? 标题:从源文档生成的标题通常比句子短(Barzilay & Mckeown,2005)。
? 句子级别:句子级别摘要生成器从原始文本生成单个句子(Y. H. Hu 等人,2017)。
? 突出显示:突出显示是以要点形式书写的原始文本的压缩形式生成的(Tomek,1998)。
? 完整摘要:根据用户的压缩率或用户要求生成完整摘要(Koupaee & Wang,2018)标题、亮点和句子级别类型的摘要通常用于新闻数据库或意见挖掘或社交媒体数据集,而完整摘要通常用于所有领域。
2.7 基于概括域
根据ATS系统的输入输出领域,分为以下3类:
? 特定类型:它仅接受特殊类型的输入文本格式(Hovy & Lin,1996)。
? 领域相关:领域相关摘要特定于一个领域(Farzindar & Lapalme,2004)。
? 领域无关:领域无关摘要系统独立于源文档的领域。
在特定类型的摘要中,对文本模板有限制。提供报纸文章、科学论文、故事、说明和其他类型的模板。摘要是由系统使用这些模板的结构生成的。另一方面,独立系统没有预定义的限制,并且可以采用多种文本类型。此外,一些技术仅总结其主题可以在系统领域中表征的文本;这些系统是领域相关的。这些系统对文档的主题施加了一些限制。这样的系统知道有关特定主题的所有信息,并使用这些知识进行总结。一般来说,基于图的技术被用于领域相关的摘要,因为它们具有良好的潜力。 (Moradi et al., 2020) 的作者给出了一种有效的解决方案来应对基于图的方法中的挑战。为了捕获句子之间的语言、语义和上下文关系,他们通过连续词表示模型来训练模型。即 Word2vec 的 Skiagrams 和连续词袋 (CBOW) 模型(Mikolov 等人,2013)和用于词表示的全局向量(GloVe)(Mutlu 等人,2020)(Hanson Er,1971)在大型生物医学语料库上文本。为了解决对图中最重要的节点进行排名的挑战,他们采用了无向和加权图排名技术,例如 PageRank 算法(Brin & Page,2012)。报纸故事和科学文本与法律文本相比具有独特的品质。例如,在新闻类型的综合文档中,几乎没有结构。同一术语出现在层次结构的不同级别将产生不同的效果。判决中文字的相关性取决于判决的来源(无论是来自地方法院、州法院、最高法院还是联邦法院)。在总结内容时,我们通常可以忽略参考文献/引文;然而,这在法律著作中可能是不可能的(Kanapala et al., 2019)。
2.8 基于加工水平
根据输入文档的处理级别,系统分为两种类型:
? 表层方法:在这种情况下,数据由浅层特征思想及其组合来表示。统计显着术语、位置显着术语、提示短语、特定领域或用户的查询术语是浅层特征的示例。结果以摘录的形式呈现(Je?ek et al., 2007)。
? 更深层次的方法:摘录或摘要可以通过更深层次的技术产生。在后一种情况下,合成用于生成自然语言。它需要一些语义分析。例如,实体技术可以构建文本实体(文本单元)及其关系的表示,以识别显着区域。实体关系包括词表关系、句法关系和语义关系等。他们还可以使用话语方法来表示文本结构,例如超文本标记或修辞结构(Je?ek et al., 2007)。
三.关于 ETS、ABS 和 HTS 的详细信息
在自动文本摘要系统的所有分类中,最普遍接受或使用的类别是提取式摘要、抽象式摘要和混合摘要。因此,本文主要关注这两种方法。现在让我们看看对这些方法的详细调查:
3.1 提取文本摘要
从第一次自动文本摘要出现的时代开始(Luhn,1958),文本处理任务主要通过使用基于 IR(信息检索)度量的特征来执行,即词频(TF)、逆术语频率 (TF-IDF)。表1显示了对研究论文的抽取式文本摘要、使用的数据集、系统的准确性及其优缺点的详细调查。之前,摘要的效率是通过数量的比例来准备的。判定重要点总数摘要中的文字(Garner,1982)。该研究分析了即时总结结果以及与详细理解和回忆结果的关系。缺乏语言知识是从大量数据中提取有用信息的弱点。为了克服这两个限制:(i)一种处理未知单词和语言信息空白的机制。 (ii) 为了自动从文本中提取语言信息,Rau 等人开发了 SCISOR(概念信息总结、组织和检索系统)。 (1989)。 1990 年之前进行的摘要实验主要集中于从原始文本中提取(复制)摘要,而不是抽象(新生成)。 SUMMRIST系统(Hovy&Lin,1996)是在NLP技术的帮助下开发的,其中可以通过修改部分结构来创建多语言摘要器。
传统的基于频率、基于知识和基于话语的摘要所面临的挑战导致使用强大的 NLP 技术(例如基于语料库的统计 NLP)遇到这些挑战(Aone 等人,1997)。摘要系统DimSum由摘要服务器和摘要客户端组成。这些强大的 NLP 算法产生的功能也被用来以创新的方式为用户提供大量的摘要视图。通过四个参数评估人类和系统的总结;乐观评估、悲观评估、交集评估、并集评估(Salton et al., 1997)并证明两个人对同一篇文章生成的摘要是不同的,而自动方法在这里更有利。 Tomek (1998) 在在线新闻《纽约时报》上实际实现了强大的摘要,它可以非常快速地提供摘要,并且包含的??原始冗长文本的部分明显减少。标题对文本摘要影响的研究证明(Lorch 等人,2001)读者在很大程度上依赖于组织信号来构建主题结构。机器学习方法(Neto 等人,2002)将自动文本摘要视为二类分类问题,其中如果句子出现在提取参考摘要中,则该句子被视为“正确”,否则被视为“不正确”。在这里,他们使用了两种著名的 ML 分类方法:朴素贝叶斯和 C4.5。词典是蚂蚁文本数据的重要组成部分。专注于在线性时间内有效地构建词汇链的算法(Silber & McCoy,2002)是文本摘要的可行中间表示。
正如先前的研究表明,监督方法是人为摘要帮助我们找到摘要算法的参数或特征的地方。尽管如此,具有多样性功能的无监督方法(Nomoto & Matsumoto,2003)在没有任何人为摘要帮助的情况下定义了相关特征。 (Yeh 等人,2005b)提出了一种可训练的摘要生成器,它根据位置、肯定关键字、否定关键字、中心性以及与标题的相似性等众多因素生成摘要。它使用遗传算法(GA)来训练评分函数,以找到特征权重的良好组合。之后,它采用潜在语义分析(LSA)来导出文档或语料库的语义矩阵和语义句子表示,以构建语义文本关系图。结合三种方法:基于多样性的方法、模糊逻辑和基于群的方法(Binwahlan 等,2010),可以生成良好的摘要。基于多样性的方法用于找出相似的句子并获得最多样化的句子并专注于减少冗余,而基于群体的方法用于区分最重要和不太重要的句子,然后使用模糊逻辑来容忍冗余,近似值和不确定性,这种组合集中于句子的评分技术。比较两种方法时,基于群体模糊的方法比基于多样性的方法表现得更好。
测量SAS(自动摘要系统)功能效率的方法的构建是自动摘要理论和实践中的一个重要领域。 Yatsko & Vishnyakov (2007) 基于主题提供的模型词汇表,对自动文本摘要的四种技术(ESSENCE (ESS)、主题搜索摘要器 (SSS)、COPERNIC (COP)、开放文本摘要器 (OTS))进行了评估。将源文本中词汇术语的分布与系统生成的各种长度的摘要中词汇术语的分布进行比较。 (Ye 等人(2007b)认为,摘要的质量可以通过摘要后保留源文档中的概念数量来判断。因此,摘要生成可以被视为一项优化任务,涉及选择一组答案损失最少的句子。所提出的文档概念格(DCL)是一种独特的文档模型,它根据重叠概念的覆盖范围对句子进行索引。(Ko&Seo,2008)的作者建议的方法将两个连续的句子合并为一个双句子-gram伪句子,允许统计句子提取工具使用上下文信息。统计句子提取方法首先选择显着的bi-gram伪句子,然后将每个选定的bi-gram伪句子分成两个单独的句子。第二次句子提取完成对分离的单个句子的操作以创建最终的文本摘要。
CN-Summ(基于复杂网络的摘要)由(Antiqueira et al., 2009)提出。节点与图表或网络中代表一段文本的句子相关,而边则连接共享共同重要名词的句子。 CN-Summ 包含 4 个步骤:1)前置(词形还原)。 2) 根据 n*n 阶的辅助性和权重度量将生成的文本映射到网络表示(n 是句子/节点的数量) .3) 计算不同的网络测量 4) 前 m 个句子被选择为摘要句子,具体取决于根据压缩率。 Alguliev & Aliguliyev (2009) 给出了一种新的无监督文本摘要方法。该方法专注于句子聚类,其中聚类是通过基于某些相似性度量建立自然分组或聚类来检测多维数据中有趣的分布和模式的技术。在这里,研究人员提出了一种新的测量相似度的方法,称为归一化谷歌距离(NGD),并提出了优化准则函数的离散差分进化算法,称为MDDE(改进的离散差分进化)算法。
群体智能(SI)是由(不复杂的)个体在本地及其与环境交互的集体行为产生的集体智能,导致出现连贯的功能性全局模式。群体智能的主要计算部分是粒子群优化(PSO)和蚁群优化(ACO),前者受到鸟群或鱼群的社会行为的启发,后者受到蚂蚁行为的启发。宾瓦兰等人。 (2009a) 提出了一种基于 PSO 的模型,其主要目标是对句子进行评分,同时专注于根据文本元素的值平等处理文本元素。结合三种方法:基于多样性的方法、模糊逻辑和基于群的方法(Binwahlan 等人,2010)可以生成良好的摘要。基于多样性的方法用于找出相似的句子并获得最多样化的句子并集中于减少冗余,而
基于群体的方法用于区分最重要和不太重要的句子,然后使用模糊逻辑来容忍冗余、不精确的值和不确定性,这种组合集中于句子的评分技术。比较两种方法时,基于群体模糊的方法比基于多样性的方法表现得更好。
在(Mashechkin et al., 2011)中,研究人员使用LSA(潜在语义分析)进行文本摘要。原始文本被复制为术语和句子的矩阵。文本句子在术语空间中表示为向量,矩阵列表示每个句子。然后对所得矩阵进行潜在语义分析,以构建主题空间中文本句子的表示,这是通过将矩阵分解之一(奇异值分解 (SVD))应用于文本矩阵来执行的。 (Alguliev 等人,2011b)将文本摘要问题视为整数线性规划问题,同时假设摘要是从原始文本中查找句子子集以表示原始文本的重要细节的任务。该研究关注三个特征(相关性、冗余性和长度),并尝试通过粒子群优化算法(PSO)和分支定界优化算法对其进行优化。在抽取文本摘要中,句子评分是最常用的技术。该研究(Ferreira 等人,2013)基于定量和定性评估评估了 15 种可用于句子评分的算法。结合基于图表的排名摘要器,维基百科由(Sankarasubramaniam 等人,2014a)给出。它通过引入增量摘要属性给出了独特的概念,其中单文档和多文档都可以实时提供附加内容。因此,用户可以首先看到最初的摘要,如果愿意查看其他内容,他们可以提出请求。
使用深度自动编码器 (AE) 从词频 (tf) 输入计算特征空间,(Yousefi-Azar & Hamey,2017b)提供了面向提取查询的单文档摘要的方法。实验中同时考虑了本地和全局词汇。该研究展示了向局部 TF 添加轻微随机噪声作为 AE 的输入表示的效果,并提出了 Ensemble Noisy Auto-Encoder 作为此类噪声 AE (ENAE) 的集合。尽管英语和其他语言有很多关于基于领域的摘要的研究,但由于缺乏知识基础,阿拉伯语的研究并不多。 (Al-Radaideh & Bataineh, 2018a) 论文 (ASDKGA) 中提出了一种混合单文档文本摘要方法。该方法使用领域专业知识、统计特征和遗传算法从阿拉伯政治文件中提取要点。对于特定领域或特定类型的摘要(例如医疗报告或特定新闻文章),基于特征工程的模型已被证明要成功得多,因为可以教会分类器识别特定形式的信息。对于一般的文本摘要,这些算法产生的结果很差。为了克服这个问题,(Sinha 等人,2018)给出了一种完全数据驱动的自动文本摘要方法
最具挑战性的困难是涵盖广泛的主题并提供摘要的多样性。基于聚类、优化和进化算法的新研究在文本摘要方面取得了有希望的结果。 Alguliyev 等人提出了一种基于聚类和优化技术的两阶段句子选择模型,称为 COSUM。 (2019b)。在第一阶段使用 k 均值算法对句子集进行聚类,以发现文本中的所有主题。第二步提出了一种优化方法,用于从簇中选择重要的句子。缺乏领域转移方法的最关键原因可能是理解文本摘要中不同的领域定义。对于文本摘要任务,(Wang et al., 2019)将域的传统定义从类别扩展到数据源。然后使用多域摘要数据集来查看不同域之间的距离如何影响神经摘要模型性能。传统应用程序有一个主要缺陷:它们使用高维、稀疏数据,导致无法收集相关信息。词嵌入是一种神经网络技术,它产生的词表示比经典的词袋 (BOW) 方法要小得多。 (Alami et al., 2019) 创建了一个基于词嵌入的文本摘要系统,结果表明 Word2Vec 表示优于经典的 BOW 表示。 (Mohd et al., 2020) 给出了另一种使用词嵌入的摘要方法。本研究还使用 Word2Vec 作为捕获语义的分布式语义模型。
当前最先进的系统生成与用户的偏好和期望无关的通用摘要。 CTRLsum(He, Kryscinski, et al., 2020)是一种独特的受控总结框架,旨在解决这一限制。该系统允许用户通过关键短语集合中的文本输入或描述性提示与摘要系统交互,以影响生成的摘要的多个特征。最近的大多数神经网络摘要算法都是基于选择的提取或基于生成的抽象。 (Xu & Durrett, 2020) 引入了一种基于联合提取和句法压缩的神经模型,用于单文档摘要。该模型从文档中选择短语,根据成分解析识别合理的压缩,并使用神经模型对这些压缩进行评级以构建最终摘要。 (El-Kassas et al., 2020) 提出了四种算法。第一个算法使用输入文档创建新的文本图模型表示。第二个和第三个算法寻找要包含在构建的文本图中的候选摘要中的句子。当生成的候选摘要超过用户指定的限制时,第四种算法会选择最重要的句子。对于印地语等资源匮乏的语言来说,自动文本摘要是一项艰巨的工作,而且仍然是一个尚未解决的话题。此类语言的另一个问题是缺乏语料库和不足的处理工具。对于印地语小说和故事,(Rani & Lobiyal,2021)在本研究中开发了一种提取词汇知识丰富的主题建模文本摘要方法。标准的基于单词的相似性度量为大多数基于图形的文本摘要技术赋予了权重。贝尔瓦尔等人。 (2021) 提供了一种新的基于图的摘要技术,该技术考虑单个单词、句子以及整个输入文本之间的相似性。
3.2 抽象文本摘要
DUC-22003 和 DUC-2004 竞赛标准化了抽象文本摘要任务,其中使用人类生成的来自各个领域的新闻文章(每篇文章有多个参考摘要)作为数据集。 TOPIARY 系统(Zajic 等,2004)是表现最好的技术。 Banko 等人提交了一些值得注意的工作。 (2000) 使用基于短语表的机器翻译技术和 (Woodsend et al., 2010) 使用准同步语法技术。表 2 显示了对抽象文本摘要的详细调查,其中包括一篇特定的研究论文、所使用的数据集、系统的准确性及其优缺点。此后,深度学习被引入作为许多 NLP 问题的可行替代方案。文本是单词序列,其中序列到序列模型可以接受输入和输出序列。由于明显的相似性,机器翻译(MT)问题可以映射到文本摘要,尽管抽象摘要与它有很大不同。机器翻译是无损的,而摘要是有损的,机器翻译是源和目标之间一对一的词级映射,但摘要中这种映射较少。
在(Rush et al., 2015)中,研究人员使用卷积模型对输入和具有注意力机制的上下文敏感前馈网络进行编码,并在 Gigaword 和 DUC 数据集上显示出更好的结果。 (Chen,2015)生成了一个相当大的中文短文本摘要数据集(LCSTS),在编码器和解码器端都使用 RNN 架构时,该数据集在数据集上取得了良好的结果。除了编码器和解码器端的 RNN 架构之外,(Nallapati 等人,2016)捕获了关键字,对未见过的或罕见的单词进行建模,并使用分层注意机制捕获了文档的层次结构。作者还尝试分析输出摘要的质量。在这种情况下,与其他模型相比,某些模型表现良好,而某些模型表现较差。人类的摘要自然更加抽象,因为他们在编写摘要时使用了一些固有的结构。 Nallapati 等人使用的判别模型(RNN)中的确定性变换。 (2016)限制了潜在结构信息的表示。之后,Miao & Blunsom (2016) 给出了一个生成模型来捕获潜在结构,但他们没有在生成模型中考虑循环依赖。 (Li et al., 2017) 的作者试图从源头上找到一些常见的结构,例如“什么”、“发生了什么”、“谁做了什么”,并提出了一种用于建模潜在结构的深度循环生成模型。
AMR(Abstract Meaning Representation)由Banarescu等人首先提出。 (2013)。 AMR 的目标是通过为源文本提供特殊的含义表示来获取文本的含义。 AMR 试图捕捉“谁对谁做了什么”。刘等人的工作。 (2015)。 s 包括 AMR,但他们没有在抽象级别使用它,因此他们的工作仅限于提取摘要。此外,该方法旨在从故事中生成摘要。生成单个图假设可以从单个子图中提取所有重要的句子。当信息分散到各处时就会出现困难。因此,多哈等人。 (2017a) 研究了多个摘要图,并在进行抽象摘要时探讨了现有评估方法和数据集的问题。
结合提取和抽象的优点并克服缺点(Song et al., 2019b),实现了名为 ATSDL(ATS using DL)的模型。该模型使用一种称为 MOSP 的短语提取方法从原文中提取关键短语,然后学习短语的搭配。训练后,模型将生成满足句法结构标准的短语序列。此外,我们利用短语位置信息来克服 (He, Kry?ciński, et al., 2020) CTRLsum: Towards Generic Controllable Text Summarization 提取文本摘要(基于关键词的模型) CNN/DailyMail arXiv 科学论文 BIGPATENT 专利文章 CNN/DailyMail: ROUGE -1: 48.75 ROUGE-2: 25.98 ROUGE-L: 45.42 arXiv: ROUGE-1: 47.58 ROUGE-2: 18.33 ROUGE-L: 42.79 成功率: 97.6 事实正确性: 99.0 提出了一个通用框架来执行多方面可控摘要。在训练过程中,模型以关键字为条件来预测摘要,但一个关键字可能属于多个方面。 (El-Kassas 等人,2020) EdgeSumm:基于图形的自动文本摘要框架 使用基于图形的方法 DUC2001 和 DUC2002 进行提取单文档文本摘要 对于 DUC2002 数据集,ROUGE-1 和 ROUGE-L 分别提高了 1.2% 和 4.7%。 -EdgeSumm 集成了多种提取式 ATS 方法(基于图的、基于统计的、基于语义的和基于中心性的方法),以利用它们的优点,同时最大限度地减少它们的缺点。 - 研究了连字符删除和同义词替换任务对生成摘要性能的影响。 - 结果非常有希望,但无法扩展用于多文档摘要 - 不是特定于领域的系统 - 依赖于语言(Rani & Lobiyal,2021) 使用基于标记 LDA 的主题建模的提取文本摘要方法 基于 LDA 模型的提取文本摘要 114 部印地语小说,包括短篇小说来自“Munshi Premchand 的故事”博客 在 10% - 30% 的压缩率和给定的评估指标下,性能优于基准算法 - 由于没有印地语小说和故事的语料库,因此它构建了一个语料库。 -通过操纵所提出的系统导出四种不同的基于句子权重方案的变体 -未考虑语义特征 -与不同压缩率的基线系统相比,结果在某些地方有所改进,在某些地方有所下降(Belwal 等人,2021) ) 使用关键字或主题建模的新的基于图形的提取文本摘要 使用基于图形和基于主题的技术进行提取摘要 Opinosis 数据集 CNN/ DailyMail CNN/DailyMail: ROUGE-1: 0.428 ROUGE-2: 0.201 ROUGE-L: 0.392 Opinosis 数据集: ROUGE-1: 0.271 ROUGE-2:0.084 ROUGE-L:0.161 添加了一个额外的参数,用于计算节点与整个内容的相似度。使用主题建模来解决与现有摘要方法相关的冗余问题 (Alami, Mallahi, et al., 2021) 基于统计和语义处理的文本摘要混合方法 提取文本摘要(统计和语义方法) 数据集由 153 个组成阿拉伯语文章取自两种阿拉伯语报纸和阿拉伯语版维基百科。数据集 1:F1 测量:59.47,40% 压缩率 数据集 2:F1 测量:60.79 40% 压缩率 使用 MMR(最大边际相关性)消除冗余 通过其他统计特征提高句子得分 语言相关问题几乎所有抽象模型都会面临的不寻常术语。对于sequence-to-sequence模型,RNN用得不多,因为它在训练时依赖于前一步,容易出现效率低下的问题,而且必须保留整个过去的隐藏状态,因此无法进行并行操作。为了克服这些问题,Zhang 等人。 (2019) 提出了一种基于 CNN 的序列到序列模型来创建源文本的表示。众所周知,传统的 CNN 只能使用固定大小的输入上下文进行编码,但在这项研究中,它们通过将 CNN 层相互堆叠来增加引人注目的文本。因此,可以容易地调节所考虑的序列的长度,并且可以并行计算序列的每个分量。更常见的是,抽象摘要问题是生成的摘要在语义方面经常与源内容不兼容。魏等人。 (2018)在本研究中为序列到序列模型提供了正则化策略,我们使用模型学到的知识来正则化学习目标,以减轻该问题的影响。
到目前为止,所讨论的模型并未考虑摘要是否与源文档事实上一致。克雷辛斯基等人。 (2019a) 提出了一种基于模型的技术,用于评估事实一致性并检测源文档和输出摘要(弱监督模型)之间的冲突。这些模型的步骤是:
? 确定句子在转换后是否实际上一致,
? 在源文档中查找一个范围以验证一致性预测,
以及 ? 在摘要短语中查找不一致的范围(如果存在)。
另一项值得注意的工作是 Kry?ciński 等人在序列到序列编码器和解码器方法中完成的。 (2020)。该研究做出了两个主要贡献。首先,在解码器部分分离提取和生成。上下文网络是独立的提取,并且语言模型生成释义。其次,优化 n 元语法重叠,同时鼓励使用真实摘要进行抽象。
王等人。 (2020)在本研究中提供了一种独特的具有多任务约束的抽象文本摘要生成对抗网络(GAN)(PGAN-ATSMT)。通过对抗性学习,该模型同时训练生成器 G 和鉴别器 D。序列到序列架构是生成模型 G 的支柱,它以源文档作为输入并生成摘要。该模型使用语言模型来实现D而不是二元分类器作为判别模型D,并且语言模型的输出用作引导生成模型的奖励。使用极小极大两人游戏来优化生成模型 G 和判别模型 D。Yang 等人对 GAN 网络进行了扩展工作。 (2021)。他们提出了一种新的 ATS 分层类人深度神经网络 (HH-ATS),该网络受到人类解释文章和生成摘要的方式的影响。 HHATS 由三个主要组成部分(即知识感知分层注意力模块、多任务学习模块和双判别器生成对抗网络)组成,反映了人类阅读认知的三个阶段(即粗读、主动阅读和后阅读)。编辑)。
3.3 Hybrid text summarization
在讨论非常宝贵的自动文本摘要方法(提取式和抽象式)时,两者都有其优点和缺点。提取式摘要比抽象式摘要更容易实现,但提取式摘要不如用户感知那么有效。通过加强这些方法的优点并削弱它们的缺点来组合这些方法,从而产生文本摘要的混合方法。
直到 1990 年,关于摘要的实验都集中在从原始文本中提取(复制)摘要,而不是摘要(新生成)。SUMMRIST 系统(Hovy & Lin,1996)是在 NLP 技术的帮助下开发的。我们可以通过修改部分结构来开发多语言摘要器。
语义和统计特征结合了提取和抽象。 Bhat 等人的作者。 (2018)使用文本的情感作为语义特征。情感在定义用户的情感亲和力方面发挥着重要作用,因此具有隐含情感内容的台词对作者至关重要,应包含在摘要中。然后将提取的摘要放入 Novel 语言生成器,这是一种混合摘要生成器,结合了 WordNet、Lesk 算法和 POS,将提取摘要转换为抽象摘要。表 3 显示了对混合文本摘要的详细调查,其中包括特定研究论文、所使用的数据集、系统的准确性及其优缺点。
四 ATS 系统评估和评估计划
过去二十年来,人们为解决总结评价问题做出了许多努力。 NIST(美国国家标准与技术研究所)通过组织 DUC 和 TAC 挑战来领导这项工作。 (Huang 等人,2010)给出了生成摘要时应考虑的四个支柱:? 信息覆盖范围 ? 信息重要性 ? 信息冗余 ? 文本连贯性
在自动文本摘要领域,评估摘要是一项关键任务。评估摘要并增加可重复使用资源和基础设施的开发有助于比较和复制研究结果,增加竞争以改善结果。然而,仔细评估许多文本以获得公正的观点是不可能的。因此,需要准确的自动评估措施来进行快速且一致的评估。人们很难认识到摘要中应该包含哪些信息;因此,评估它是很困难的。信息会根据摘要的目的而变化,机械地捕获这些信息是一项具有挑战性的任务(Gambhir & Gupta,2017)。 ATS系统的评估如下图7所示:
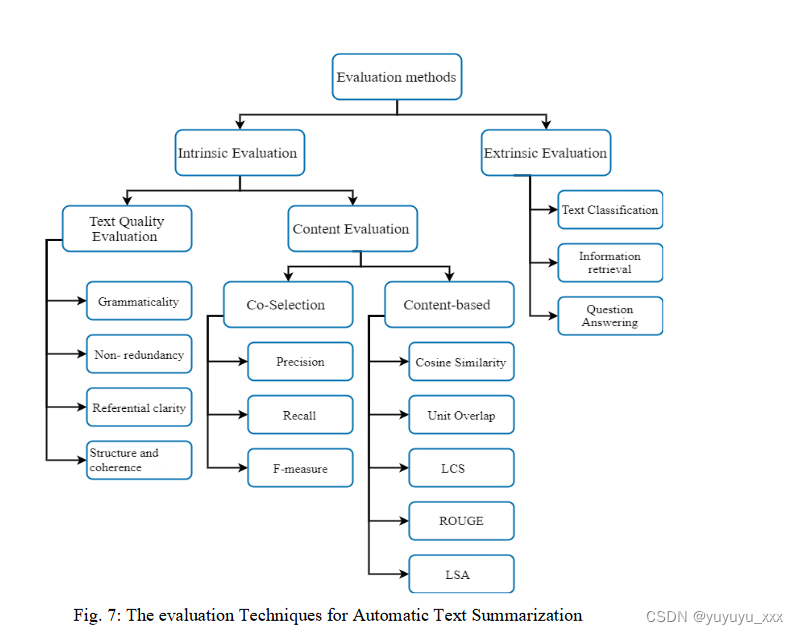
a) 外部评估:外部评估着眼于它如何影响另一项任务(文本分类、信息检索、问答)的完成。也就是说,如果摘要能为其他任务提供帮助,则该摘要被称为良好的摘要。外在评估着眼于摘要如何影响相关性评估、阅读理解等任务。 - 相关性评估:使用各种方法来分析摘要或原始材料中主题的相关性。 - 阅读理解:阅读摘要后,评估是否可以回答多项选择题的评估。
b) 内在评估:内在评估着眼于摘要系统本身。摘要的连贯性和信息性一直是内在评估的重点。基于与模型摘要/摘要比较的评估和基于与源文档比较的评估是两种类型的内在技术(Steinberger & Je?ek,2009)。
它通过比较机器生成的摘要和人工生成的摘要的覆盖范围来评估摘要的质量。判断摘要的两个最重要的方面是其质量和信息量。摘要的信息量通常通过将其与人造摘要(例如参考摘要)进行比较来评估。还有对源范例的忠实,它检查摘要是否包含与原始文档相同或相似的材料。这种方法有一个缺陷:如何确定文档中哪些概念相关、哪些概念不相关?
4.1内容评价
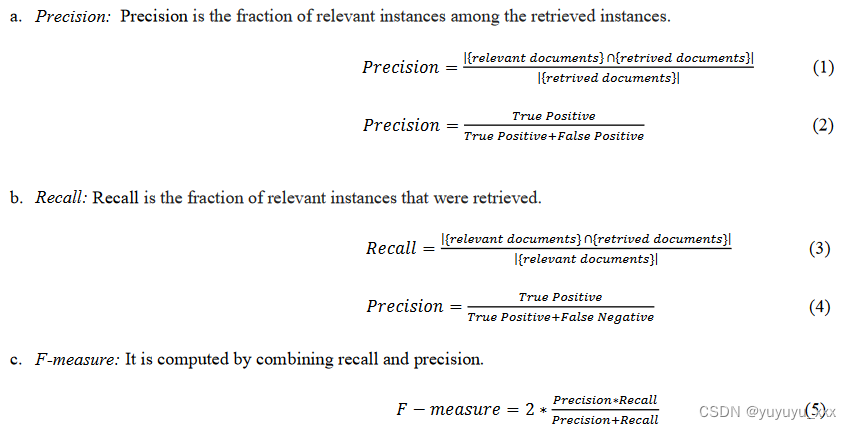
共同选择:只有相同的句子才能用于共同选择措施。它忽略了这样一个事实:即使两个句子的写法不同,它们也可以包含相同的信息。此外,两位不同作者提供的摘要很少包含相似的句子。协同选择可以通过精确率、召回率和F-measure来计算。
基于内容:基于内容的方法解决了共同选择方法的缺点。

其中,X和Y是基于单词或引理序列的表示,LCS(X,Y)是X和Y之间的最长公共子序列的长度,length(X)是字符串X的长度,editdi(X , Y) 是 X 和 Y 的编辑距离。
d. ROUGE(Recall-Oriented Understudy for Gisting Assessment):由 C. Lin & Rey (2001) 首次提出。它包含通过将摘要与人们生成的其他(理想)摘要进行比较来自动确定摘要质量的措施。这些度量计算待评估的计算机生成的摘要与人类编写的理想摘要之间的重叠单元(例如 n 元语法、单词序列和单词对)的数量。 ROUGE包括ROUGE-N、ROUGE-L、ROUGE-W、ROUGE-S和ROUGE-SU等五种措施。
? ROUGE-N 计算给定摘要和一组参考摘要共享的N-gram 单元的数量,其中N 是N-gram 的长度。即,ROUGE-1 表示一元语法,ROUGE-2 表示二元语法。
? ROUGE-L 计算LCS(最长公共子序列)统计量。 LCS 是两个给定序列 X 和 Y 的公共子序列的最大大小。ROUGE-L 估计两个摘要的 LCS 与参考摘要的 LCS 的比率。
? ROUGE-W 是加权最长公共子序列度量。这是相对濒海战斗舰基本战略向前迈出的一步。 ROUGE-W更喜欢具有连续公共单元的LCS。可以使用动态规划来有效地计算它。
? ROUGE-S(跳过二元组共现统计)计算单个摘要和一组参考摘要之间共享的跳过二元组的百分比。跳过二元组是句子顺序中带有随机间隙的单词对。
? ROUGE-SU 是ROUGE-S 和ROUGE-1 的加权平均值,它扩展了ROUGE-S 以包括一元计数单位。这是 ROUGE-S 的一个进步。
e.基于 LSA 的方法:该方法由 Steinberger & Je?ek (2009) 开发。如果文档中有 m 个术语和 n 个句子,我们将获得一个 mn 矩阵 A。下一步是将奇异值分解(SVD)应用于矩阵 A。mn 矩阵 A 的 SVD 定义为等式(9)给出:
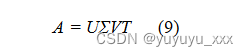
就 NLP 而言,SVD(奇异值分解)用于生成文档的潜在语义结构,用矩阵 A 表示:即将原始文档分解为 r 个线性无关的基本向量,这些向量表示文档的主要“主题” 。 SVD 可以记录术语之间的相互关系,允许概念和句子基于“语义”而不是“单词”进行聚类。
这里适当考虑了摘要的语言特征。非冗余、焦点、语法、参考清晰度、结构和连贯性是 DUC(文档理解会议)和 TAC(文本分析会议)会议中使用的基于语言质量的五个问题,用于评估不需要根据参考摘要进行审查的摘要。专家评估员根据摘要的质量对摘要进行手动评分,按照五分制对摘要进行评分(Gambhir & Gupta,2017)。
4.2 文本连贯性或质量评估:
A。语法:文本不应包含非文本项(即标记)、标点符号错误或不正确的单词。
b.非冗余:文本不应包含冗余信息。
C。参考清晰度:名词和代词应概括地提及。例如,代词 he 在摘要的上下文中必须表示某人。
d.连贯性和结构:摘要应具有良好的结构,句子应连贯。
这里适当考虑了摘要的语言特征。非冗余、焦点、语法、参考清晰度、结构和连贯性是 DUC(文档理解会议)和 TAC(文本分析会议)会议中使用的基于语言质量的五个问题,用于评估不需要根据参考摘要进行审查的摘要。专家评估员根据摘要的质量对摘要进行手动评分,按照五分制对摘要进行评分(Gambhir & Gupta,2017)。
摘要的文本质量也可以通过检查几个可读性变量来检查。使用词汇、语法和话语等各种标准来分析文本质量,以估计这些特征与先前获得的人类可读性评级之间的相关性。一元词代表词汇,而动词或名词的平均数量代表语法。
4.3 自动文本摘要评估程序
SUMMAC(TIPSTER 文本摘要评估)是第一个审查自动摘要系统的会议,该会议于 20 世纪 90 年代末举行,使用两个外部和内部标准对文本摘要进行评估。 DUC(文档理解会议)从 2001 年到 2007 年每年举行一次,是另一个著名的文本摘要会议。最初,DUC 2001 和 DUC 2002 等 DUC 会议的活动以单个和多个文档的通用摘要为特色,后来在 DUC 2003 中扩展到包括基于查询的多个文档摘要。基于主题的单文档和多文档跨语言DUC 2004 中评估了摘要。DUC 2005 和 DUC 2006 中审查了多文档、基于查询的摘要,而 DUC 2007 中评估了多文档、更新、基于查询的摘要。然而,在 2007 年,DUC 会议不再举行,因为它们被吸收到以总结会议为特色的文本分析会议(TAC)中。 TAC 是一系列评估研讨会,旨在促进自然语言处理及相关领域的研究。 TAC QA 计划源自 TREC QA 计划。摘要轨道有助于开发生成简洁、连贯的文本摘要的方法。自 2008 年以来,每年都会举办 TAC 研讨会。
五 ATS 常用数据集
ATS 系统的应用在全球范围内广泛传播,并了解全球可用数据。因此,执行文本摘要任务必不可少的就是数据。并非所有数据都可以直接输入系统。它需要预先处理和其他治疗。基于机器学习的方法需要一个巨大的训练数据集和理想的摘要来训练模型。此外,需要理想或样本数据集来评估特定的 ATS 系统。该样本数据是由人类研究人员手动生成或创建的。可用于 ATS 任务的数据集列表非常长。下面给出了极少数数据集:
? DUC:美国国家标准与技术研究院 (NIST) 提供这些数据集,它们是文本摘要研究中最流行且使用最广泛的数据集。 DUC 语料库作为 DUC 会议总结共享工作的一部分进行分发。最近的 DUC 挑战于 2007 年举行。DUC 2001 至 DUC 2007 的数据集可在 DUC 网站上获取。
? 文本分析会议(TAC) 数据集:DUC 于2008 年作为摘要轨道添加到TAC。要访问TAC 数据集,您必须首先填写TAC 网站上提供的申请表。
? Gigaword:由(Rush 等人,2015)创建,在 Gigaword 的文章对语料库上生成标题,其中包含约 400 万篇英语文章。 ? LCTCS:LCSTS 数据集由 Chen (2015) 创建,基于中国微博网站新浪微博构建。它由超过200万条真实的中文短文本组成,每条文本的作者都给出了简短的摘要。需要用中文申请。
? wikiHow:WikiHow 数据集由 Koupaee 和 Wang (2018) 创建,包含从不同人类作者用英语编写的在线知识库中提取和构建的文章和摘要对。有两个功能: - 文本:wikiHow 答案文本。 - 标题:粗体线作为摘要。
? CNN:CNN/DailyMail 非匿名摘要数据集。 CNN /《每日邮报》数据集是一个英语数据集,包含 CNN 和《每日邮报》记者撰写的超过 30 万篇独特的新闻文章。当前版本支持提取和抽象摘要,尽管原始版本是为机器阅读和理解以及抽象问答而创建的。
六. 应用、挑战和未来范围
6.1ATS的应用
自动文本摘要有多种用途。正如我们所看到的,文本摘要如何分为更多类别。所有这些类别进一步引导我们发现 ATS 应用程序的宝藏。本小节包括ATS系统的一些应用。表4为ATS系统应用研究概况。该表包括文章名称、特定文章中使用的方法和数据集、该特定研究中提出的系统的性能以及该文章的优点和缺点。
以下是一些示例:
? 提高经典 IR 和 IE 系统的性能(将摘要系统与问答 (QA) 系统结合使用); (De Tre 等人,2014) (S. Liu 等人,2012) (Perea-Ortega 等人,2013)
? 新闻摘要和新闻专线生成(Tomek,1998)(Bouras & Tsogkas,2010)
? 丰富站点摘要 (RSS) 摘要(Zhan 等人,2009)
? 博客摘要(Y. H. Hu 等人,2017)
? 推文摘要(Chakraborty 等人,2019)
? 网页摘要(Shen 等人,2007)
?电子邮件和电子邮件线程摘要(Muresan 等人,2001)
? 为商人、政治家、研究人员等提供的报告摘要(Lloret 等人,2013)
? 会议摘要。
? 传记摘录
? 法律文件摘要(Farzindar & Lapalme,2004)
? 书籍摘要(Mihalcea & Ceylan,2007)
? 摘要在医学领域的使用(Feblowitz 等人,2011)(Ramesh 等人,2015)
6.2 挑战和未来范围
在生成自动文本摘要时,人们面临着很多挑战。第一个挑战是定义什么构成了一个像样的摘要,或者更准确地说,如何构建摘要。我们对摘要的要求提供了关于摘要应该是什么的良好线索:提取的或抽象的、一般的或查询驱动的等。即使我们弄清楚人类通常如何进行摘要,将其付诸实践也会很困难。创建功能强大的自动文本摘要器需要许多资源,无论是工具还是语料库。另一个挑战是总结的形成性;在总结方面,机器如何模仿人类?长期存在的问题之一是摘要的连贯性。资源短缺是ATS面临的另一个最具挑战性的问题。
与过去相比,现在有许多强大的工具可用于词干提取、解析和其他任务。尽管如此,确定哪些适合特定的概括问题仍然是个问题。此外,ATS 的注释语料库可以被视为一个挑战。评估过程也是一个重大困难。这项工作探索了内在和外在评估方法。机器生成的参考摘要共享的语言通常是当前内在评估方法的焦点。直观评估可以创建新的方法来根据摘要包含的信息及其呈现方式来评估摘要。评估过程具有很强的主观性。首先,必须定义一个合理的标准来理解什么是重要的,什么是不重要的。目前还不清楚这个过程是否可以完全自动化。
文本摘要已经存在了五十多年,学术界对此非常感兴趣;因此,他们不断改进现有的文本摘要方法或发明新的摘要方法以提供更高质量的摘要。然而,文本摘要性能仍然一般,创建的摘要并不完美。因此,通过将该系统与其他系统合并,可以使其更加智能,从而使组合后的系统能够更好地运行。
结论
自动文本摘要可减少源文本的大小,同时保持其信息价值和整体含义。由于我们获得大量信息以及互联网技术的发展,自动文本摘要已成为分析文本信息的强大技术。文本自动摘要是自然语言处理(NLP)中一项蓬勃发展的已知任务。自动文本摘要是一个令人兴奋的研究领域,并且具有丰富的应用价值。本文旨在让读者从底层理解自动文本摘要,并熟悉 ATS 系统的所有详细类型。之后,本研究对所有不同类型进行了深入而清晰的区分。概括任务主要分为抽取式和抽象式。该研究展示了多种提取摘要技术,但提取摘要器生成的摘要与人工摘要相去甚远。另一方面,抽象摘要器接近人类摘要,但在实践中并没有高性能实现。抽取式和抽象式的结合就是混合文本摘要。本文包括对抽取式、抽象式和混合文本摘要的研究调查。此外,这篇调查文章试图涵盖ATS系统的所有主要应用领域,并对其进行了详细的调查。本文包含了许多评估摘要系统和生成摘要的方法。此外,它还简要介绍了自动文本摘要系统每年举行的常用数据集、会议和项目。 。
未来的研究是建立一个强大的、独立于领域和语言的提取文本摘要,可以很好地处理多文档。同样,由于摘要的质量评估是由经验丰富的评估人员手动完成的,因此具有很强的主观性。有特定的质量评估标准,例如语法性和连贯性,但当两个专家评估相同的摘要时,结果是不同的。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!