Modelscope Agent初体验与思考
2023-12-13 17:05:03
背景:LLM → \to → Agent
ChatGPT为代表的大语言模型就不用过多的介绍了,ChatGPT很强大,但是也有做不到的东西。
例如:
- 实时查询问题:实时的天气,地理位置,最新新闻报道,现实世界正在发生和刚结束的信息等
- 不能产生动作:你只能获得语言的回复,而不能让它执行动作。当然也有类似的工作(Reac、AutoGPT)
- 无法访问专有信息源。模型无法访问专有信息,例如公司数据库中的客户名册或在线游戏的状态。
- 缺乏推理能力。某些推理超出了神经方法的能力范围,需要专门的推理过程。我们在上面看到了算术推理的经典例子。 GPT-3 和 Jurassic-1 在 2 位加法上表现良好,令人印象深刻,但在 4 位加法上自信地给出了无意义的答案。随着训练时间的增加、更好的数据和更大的模型,LLM 的性能将会提高,但不会达到 20 世纪 70 年代 HP 计算器的鲁棒性。而数学推理只是冰山一角。
- 微调成本问题。微调和服务多个大型模型是不切实际的。我们也无法针对训练中未涵盖的新任务进一步调整经过多任务训练的 LLM ;由于灾难性遗忘,添加新任务需要对整个任务集进行重新训练。考虑到训练此类模型的成本,这显然是不可行的。
那么Agent又是什么?
agent用来调用外部 API 来获取模型权重中缺失的额外信息(通常在预训练后很难更改),包括当前信息、代码执行能力、对专有信息源的访问等。
对于agent的定义:
将 Agents 定义为LLM + memory + planning skills + tool use,即大语言模型、记忆、任务规划、工具使用的集合。
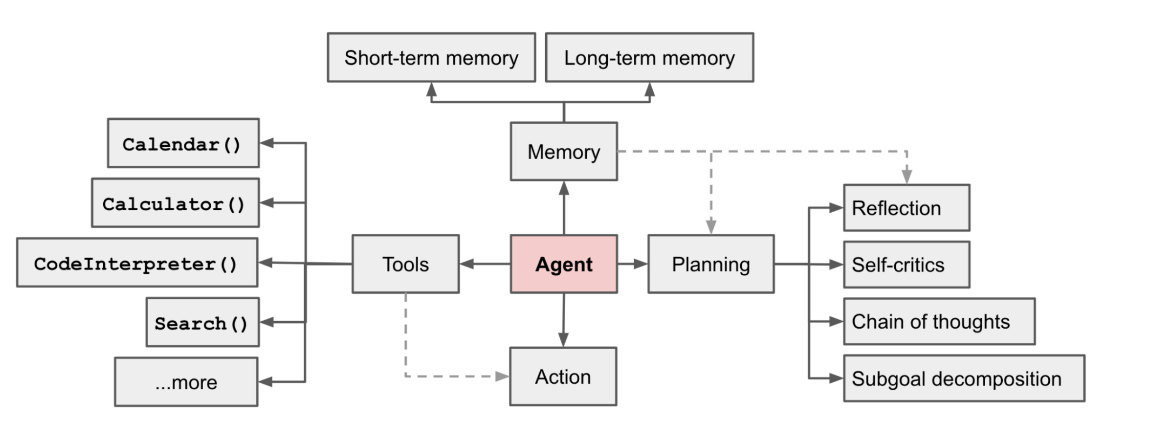
生成式Agent
这个方向非常的火,效果也非常的惊人。例如大名鼎鼎的斯坦福小镇项目:
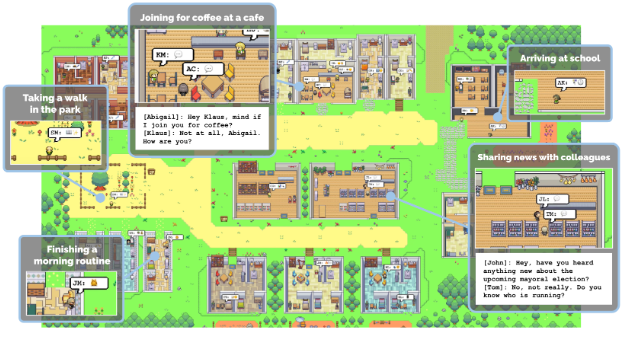
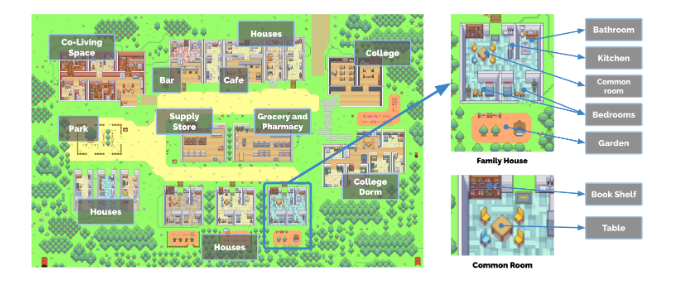
- 核心构建原理如下图:

- 生成Agent的设计将 LLM 与记忆、规划和反射机制相结合,使代理能够根据过去的经验进行行为,并与其他代理进行交互。
更多关于LLM-Agent可以阅读一下这篇blog:LLM-Based Agent
Agent调用流程
结合背景调研,我简单的猜想一下魔塔Agent构建的实际流程:
- 用户意图识别:在每个用户语句之后,模型需要确定是否需要 API 调用来访问外部服务,这需要能够了解其知识的边界或是否需要外部操作。
- 找到合适的API:每次特定 API 调用之前都需要进行 API 搜索。当执行API搜索时,模型应该将用户的需求总结为几个关键词。 API搜索引擎将查找API池中最符合的API。
- API调用:API调用后回复完成API调用并获得返回结果
关于API:
最简单实用的就是实时信息的API调用。可以找一些常见的API,例如Google/百度的引擎、日历查询、航班信息查询、酒店预订和生活联系紧密的API等。
关于模型:
其实对于调用的模型除了LLM之外还可以涉及其他的一些小的AI模型,例如专门做ImageCaption、SpeechRecognition、Translate和DocumentQA的模型。将它们视为API接口,LLM不需要了解它们的模型细节或端到端联合训练。他们只需要知道它们的目的和输入/输出格式,然后就可以使用这些人工智能模型来增强特定方面的能力。
实战练习
-
Agent创建专用链接:https://modelscope.cn/studios/modelscope/AgentFabric/summary
-
聊天框框中输入你想构建的Agent,描述功能需求,可以多轮对话追加详细信息
例如:构建一个天气查询的Agent:Angel
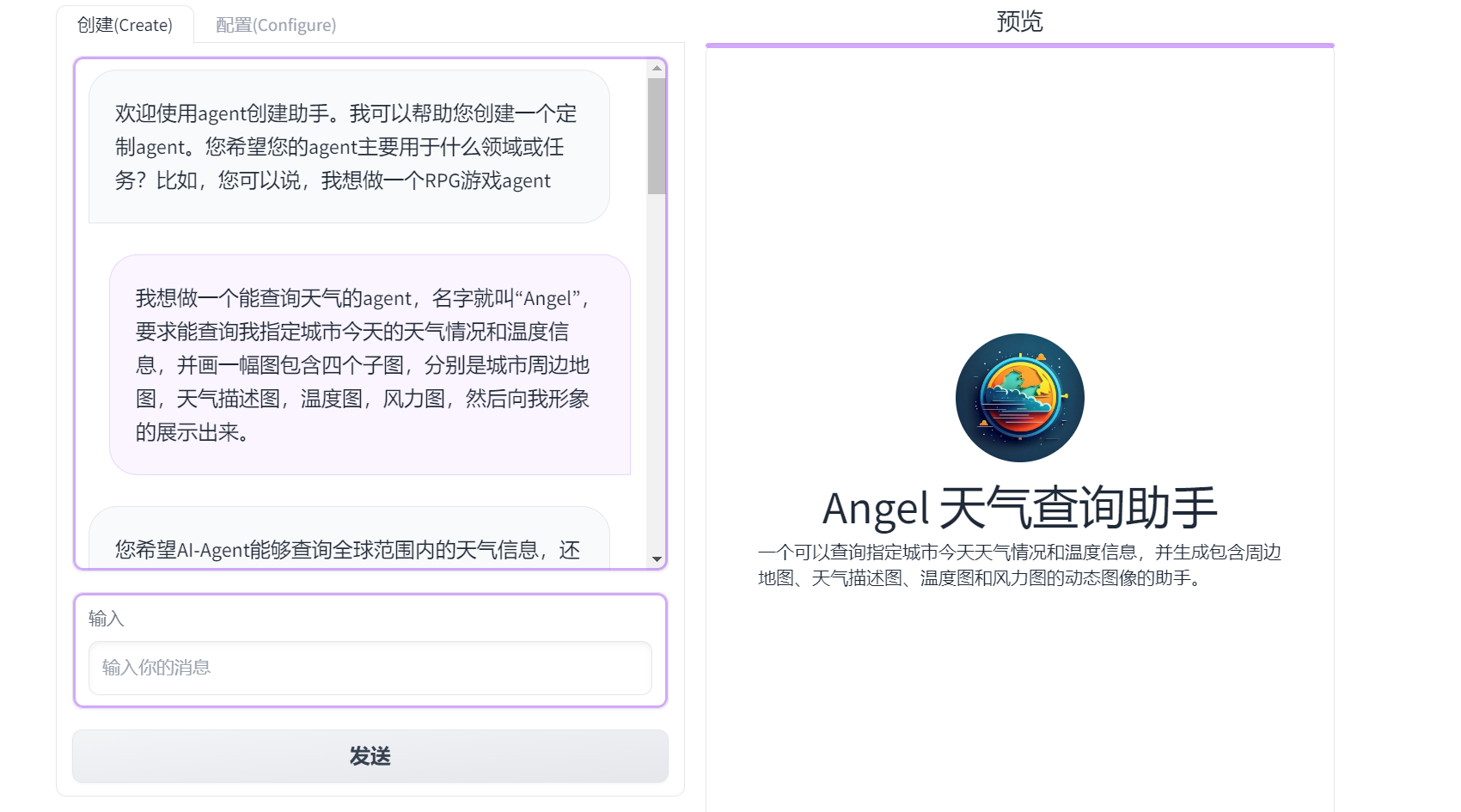
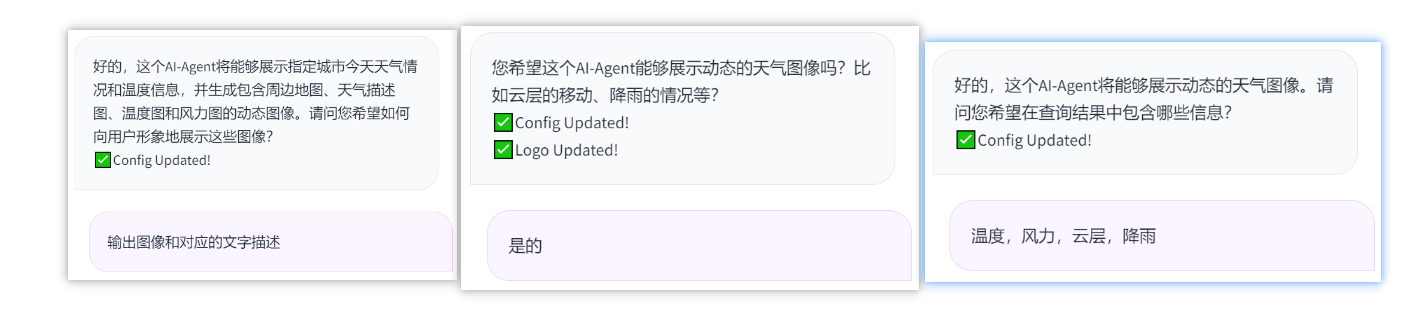
- 完善一下Agent的详细需求,看一下最后收集的关于Agent的详细功能描述
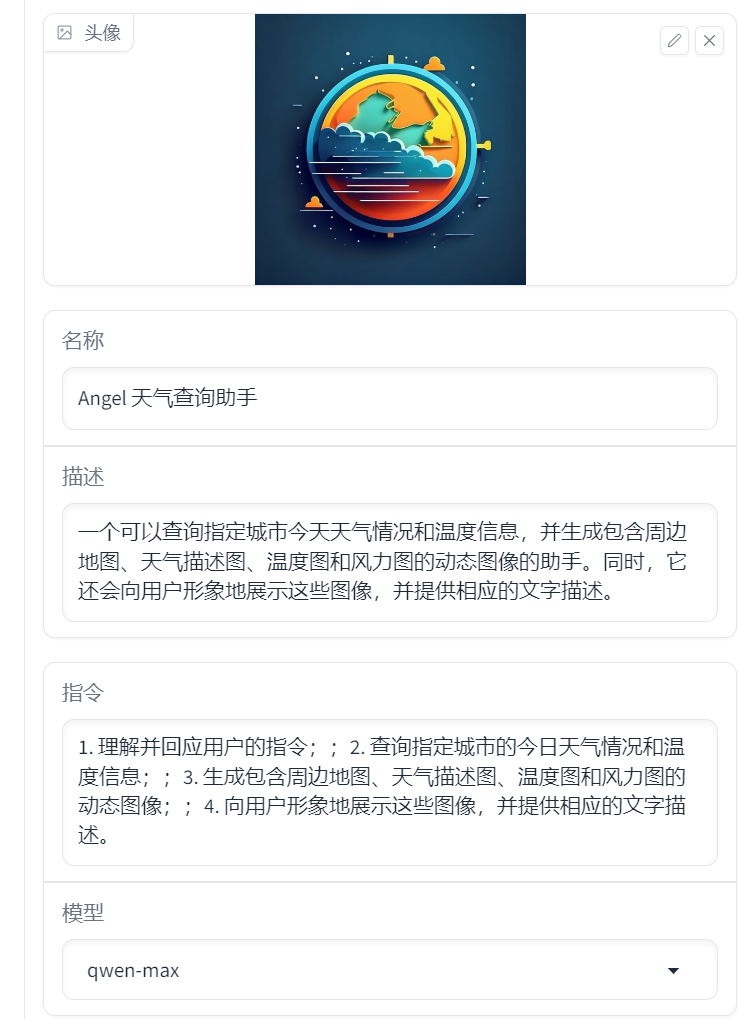
理想中的效果:
试一下调用Agent的效果

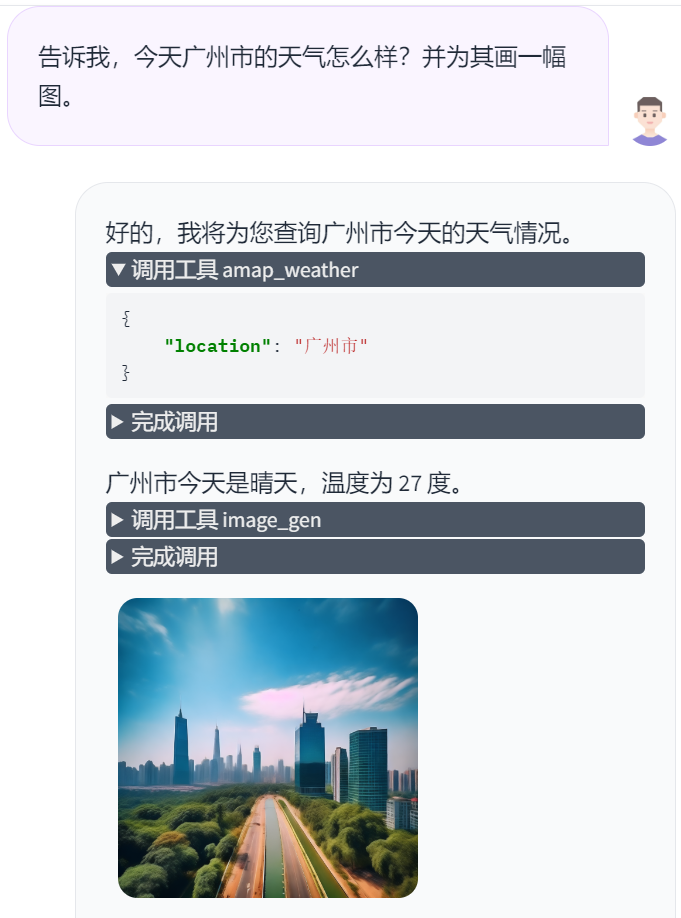
- 天气API调用很稳定,还得是高德!
- 图像生成API就有些差强人意,可能是给出的Prompt信息有点少,生成不出来上面理想的效果,各位Prompt Engineers 可以试一试!
文章来源:https://blog.csdn.net/RandyHan/article/details/134907516
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!