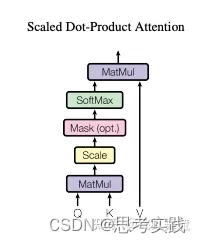
深度学习有意思的探讨系列——Self-Attention那么为什么要进行缩放呢? 为什么很大的值,不利于梯度的传播?为什么使用维度的根号来进行缩放?
2023-12-21 02:16:42
我自己做了一个视频,欢迎大家一起探讨:
深度学习有意思的探讨系列——Self-Attention那么为什么要进行缩放呢? 为什么很大的值,不利于梯度的传播?为什么使用维度的根号来进行缩放?_哔哩哔哩_bilibili
softmax又称归一化指数函数。它是二分类函数sigmoid在多分类上的推广,目的是将多分类的结果以概率的形式展现出来。它将多个神经元的输出,映射到(0,1)区间内,可以看成概率来理解,从而来进行多分类!假设我们有一个数组,V,Vi表示V中的第i个元素,那么这个元素的softmax值就是
 ?
?
参考资料:(很详细,能看懂)
transformer中的缩放点积注意力为什么要除以根号d_transformer 根号d-CSDN博客
大模型面试系列-基础面试问题(1) - 知乎 (zhihu.com)
为什么在进行softmax之前需要对attention进行scaled(为什么除以 d_k的平方根)_attention为什么要除以根号d-CSDN博客
文章来源:https://blog.csdn.net/weixin_43332715/article/details/135107756
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!