分库分表之Mycat应用学习三
1 MySQL 主从复制
1.1 主从复制的含义
在 MySQL 多服务器的架构中,至少要有一个主节点(master),跟主节点相对的,我们把它叫做从节点(slave)。主从复制,就是把主节点的数据复制到一个或者多个从节点。主服务器和从服务器可以在不同的 IP 上,通过远程连接来同步数据,这个是异步的过程。
1.2 主从复制的形式
一主一从/一主多从
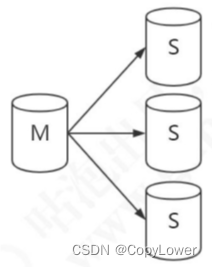
多主一从
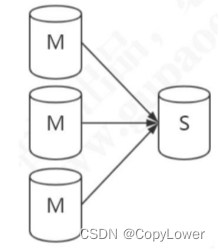
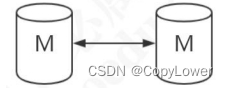
双主复制
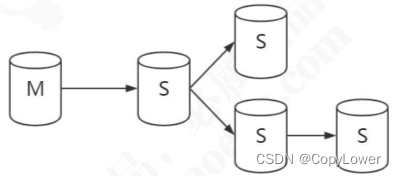
级联复制
1.3 主从复制的用途
数据备份:把数据复制到不同的机器上,以免单台服务器发生故障时数据丢失。
读写分离:让主库负责写,从库负责读,从而提高读写的并发度。
高可用 HA:当节点故障时,自动转移到其他节点,提高可用性。
扩展:结合负载的机制,均摊所有的应用访问请求,降低单机 IO
1.4 binlog
客户端对 MySQL 数据库进行操作的时候,包括 DDL 和 DML 语句,服务端会在日志文件中用事件的形式记录所有的操作记录,这个文件就是 binlog 文件(属于逻辑日志,跟 Redis 的 AOF 文件类似)
基于 binlog,我们可以实现主从复制和数据恢复。
Binlog 默认是不开启的,需要在服务端手动配置。注意有一定的性能损耗。
1.4.1 binlog 配置
编辑 /etc/my.cn
log-bin=/var/lib/mysql/mysql-bin
server-id=1
重启 MySQL 服务
service mysqld stop
service mysqld start
## 如果出错查看日志
vi /var/log/mysqld.log
cd /var/lib/mysql
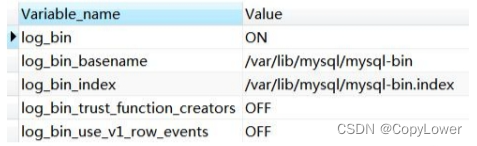
是否开启 binlog
show variables
1.4.2 binlog 格式
STATEMENT:记录每一条修改数据的 SQL 语句(减少日志量,节约 IO)。
ROW:记录哪条数据被修改了,修改成什么样子了(5.7 以后默认)。
MIXED:结合两种方式,一般的语句用 STATEMENT,函数之类的用 ROW。
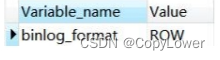
查看 binlog 格式:
show global variables like
查看 binlog 列表
show binary logs;
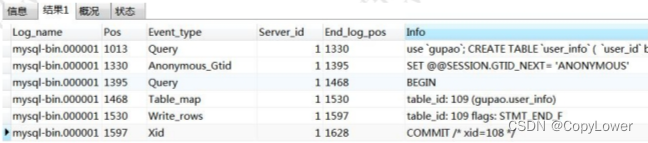
查看 binlog 内容
show binlog events in 'mysql-bin.000001';
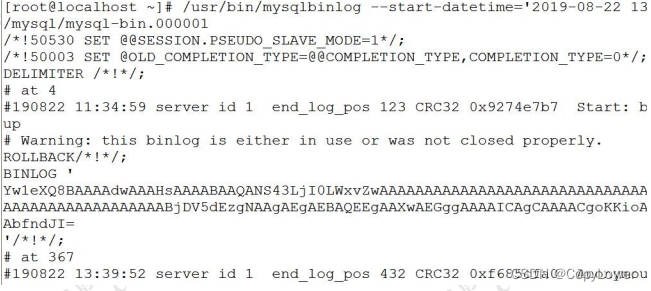
用 mysqlbinlog 工具,基于时间查看 binlog
(注意这个是 Linux 命令, 不是 SQL)
/usr/bin/mysqlbinlog --start-datetime='2019-08-22 13:30:00' --stop-datetime='2019-08-22 14:01:01' -d gupao
/var/lib/mysql/mysql-bin.000001
1.5 主从复制原理
1.5.1 主从复制配置
1、主库开启 binlog,设置 server-id
2、在主库创建具有复制权限的用户,允许从库连接
GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'repl'@'192.168.8.147' IDENTIFIED BY
'123456';
FLUSH PRIVILEGES;
3、从库/etc/my.cnf 配置,重启数据库
server-id=2
log-bin=mysql-bin
relay-log=mysql-relay-bin
read-only=1
log-slave-updates=1
log-slave-updates 决定了在从 binlog 读取数据时,是否记录 binlog,实现双主和
级联的关键。
4、在从库执行
stop slave;
change master to
master_host='192.168.8.146',master_user='repl',master_password='123456',master_log_file='mysql-bin.000001', master_log_pos=4;
start slave;
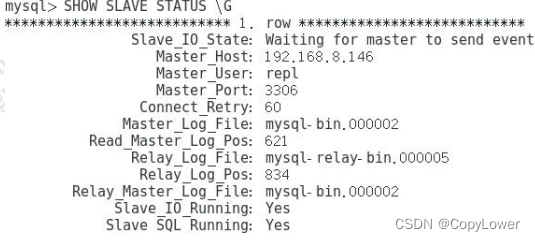
5、查看同步状态
SHOW SLAVE STATUS \G
以下为正常:
1.5.2 主从复制原理
这里面涉及到几个线程:
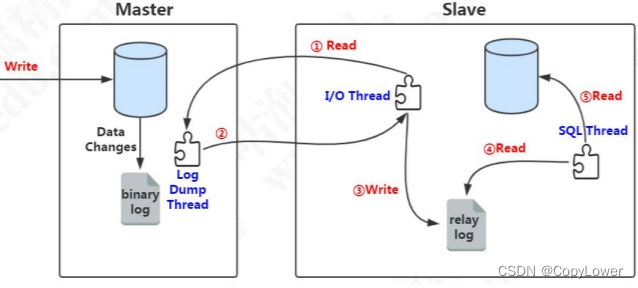
1、slave 服务器执行 start slave,开启主从复制开关, slave 服务器的 IO 线程请求从 master 服务器读取 binlog(如果该线程追赶上了主库,会进入睡眠状态)。
2、master 服务器创建 Log Dump 线程,把 binlog 发送给 slave 服务器。slave 服务器把读取到的 binlog 日志内容写入中继日志 relay log(会记录位置信息,以便下次继续读取)。
3、slave 服务器的 SQL 线程会实时检测 relay log 中新增的日志内容,把 relay log解析成 SQL 语句,并执行。
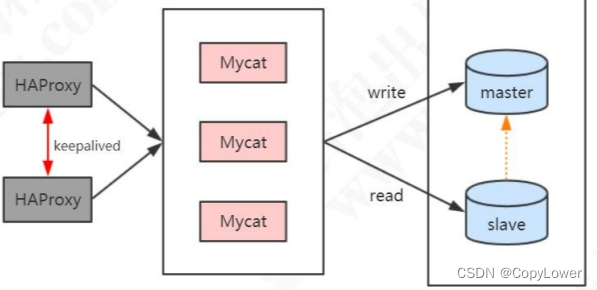
2 Mycat 高可用
目前 Mycat 没有实现对多 Mycat 集群的支持,可以暂时使用 HAProxy 来做负载
思路:HAProxy 对 Mycat 进行负载。Keepalive
3 Mycat 注解
3.1 注解的作用
当关联的数据不在同一个节点的时候,Mycat 是无法实现跨库 join 的。
举例:
如果直接在 150 插入主表数据,151 插入明细表数据,此时关联查询无法查询出来。
-- 150 节点插入
INSERT INTO `order_info` (`order_id`, `uid`, `nums`, `state`, `create_time`, `update_time`) VALUES (9, 1000003, 2673, 1, '2019-9-25 11:35:49', '2019-9-25 11:35:49'); -- 151 节点插入
INSERT INTO `order_detail` (`order_id`, `id`, `goods_id`, `price`, `is_pay`, `is_ship`, `status`) VALUES (9, 20180001, 2673, 19.99, 1,
在 mycat 数据库查询,直接查询没有结果。
select a.order_id,b.price from order_info a, order_detail b where a.nums = b.goods_id;
Mycat 作为一个中间件,有很多自身不支持的 SQL 语句,比如存储过程,但是这些语句在实际的数据库节点上是可以执行的。有没有办法让 Mycat 做一层透明的代理转发,直接找到目标数据节点去执行这些 SQL 语句呢?
那我们必须要有一种方式告诉 Mycat 应该在哪个节点上执行。这个就是 Mycat 的注解。我们在需要执行的 SQL 语句前面加上一段代码,帮助 Mycat 找到我们的目标节点。
3.2 注解的用法
注解的形式是 :
/!mycat: sql=注解 SQL 语句/
注解的使用方式是 :
/!mycat: sql=注解 SQL 语句/ 真正执行的 SQL
使用时将 = 号后的 “注解 SQL 语句” 替换为需要的 SQL 语句即可。
使用注解有一些限制,或者注意的地方:
| 原始SQL | 注解SQL |
|---|---|
| select | 如果需要确定分片,则使用能确定分片的注解,比如/!mycat: sql=select * from users where user_id=1/如果要在所有分片上执行则可以不加能确定分片的条件 |
| insert | 使用 insert 的表作为注解 SQL,必须能确定到某个分片原始 SQL 插入的字段必须包括分片字段非分片表(只在某个节点上):必须能确定到某个分片 |
| delete | 使用 delete 的表作为注解 SQL |
| update | 使用 update |
使用注解并不额外增加 MyCat 的执行时间;从解析复杂度以及性能考虑,注解SQL 应尽量简单,因为它只是用来做路由的。
3.3 注解使用示例
3.3.1 创建表或存储过程
customer.id=1 全部路由到 146
-- 存储过程
/*!mycat: sql=select * from customer where id =1 */ CREATE PROCEDURE test_proc() BEGIN END ; -- 表
/*!mycat: sql=select * from customer where id =1 */ CREATE TABLE test2(id INT
3.3.2 特殊语句自定义分片
Mycat 本身不支持 insert select,通过注解支持
/*!mycat: sql=select * from customer where id =1 */ INSERT INTO test2(id) SELECT id FROM order
3.3.3 多表 ShareJoin
/*!mycat:catlet=io.mycat.catlets.ShareJoin */
select a.order_id,b.price from order_info a, order_detail b where a.nums = b.goods_id;
读写分离
读写分离 : 配置 Mycat 读写分离后,默认查询都会从读节点获取数据,但是有些场景需要获取实时数据,如果从读节点获取数据可能因延时而无法实现实时,Mycat 支持通过注解 /balance/ 来强制从写节点(write host)查询数据
/*balance*/ select a.* from customer a where
3.3.4 读写分离数据库选择(1.6 版本之后)
/*!mycat: db_type=master */ select * from customer;
/*!mycat: db_type=slave */ select * from customer;
/*#mycat: db_type=master */ select * from customer;
/*#mycat: db_type=slave */ select * from customer;
注解支持的’! ‘不被 mysql 单库兼容
注解支持的’#'不被 MyBatis 兼容
随着 Mycat 的开发,更多的新功能正在加入
3.4 注解原理
Mycat 在执行 SQL 之前会先解析 SQL 语句,在获得分片信息后再到对应的物理节点上执行。如果 SQL 语句无法解析,则不能被执行。如果语句中有注解,则会先解析注解的内容获得分片信息,再把真正需要执行的 SQL 语句发送对对应的物理节点上。
所以我们在使用主机的时候,应该清楚地知道目标 SQL 应该在哪个节点上执行,注解的 SQL 也指向这个分片,这样才能使用。如果注解没有使用正确的条件,会导致原始SQL 被发送到所有的节点上执行,造成数据错误
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!