吐血整理,接口自动化测试实战(超详细)
作为测试,你可能会对以下场景感到似曾相识:开发改好的 BUG 反复横跳;版本兼容逻辑多,修复一个 BUG 触发了更多 BUG;上线时系统监控毫无异常,过段时间用户投诉某个页面无数据;改动祖传代码时如履薄冰,心智负担极重。为此本文提出一个自动化测试系统,它能够低成本实现100%的测试用例覆盖率,极大减轻管理自动化测试用例的工作量并提高测试效率,保障后台服务平稳变更。欢迎阅读~
一、背景
1.1 接口自动化测试介绍
顾名思义,接口测试就是对系统或者组件之间的接口进行测试,主要校验数据的交换、传递以及系统间的相互依赖关系等。根据测试金字塔的模型理论,测试分为三层,分别是单元测试(Unit Tests)、服务测试(Service Tests)、UI 测试(UI Tests),而我们的接口自动化测试就是服务测试层。
单元测试会导致工作量大幅提升,在需求快速迭代和人力紧张的背景下,很难持续推进,本文暂不讨论。而接口自动化测试容易实现、维护成本低,且收益更高,有着更高的投入产出比。
1.2 现状及痛点
实际上我们有一个叫 WeJestAPITest 的自动化测试平台,它是基于 Facebook 开源的 Jest 测试框架搭建的,用于校验后台的接口返回是否符合预期。在这个平台此前运行了数年的测试,一定程度上保障了后台服务的平稳运行。
但在长期使用中我们也发现了一些痛点:
- 遇到失败用例习惯性申请跳过测试,自动化测试形同虚设;
- 版本需求迭代速度飞快,用例落后于需求变更,用例迭代成本高;
- 开发同学很难参与到用例维护中,而测试同学对接口逻辑了解不深,编写的用例过于简单、僵硬,导致覆盖率低、用例质量差,开发上线心理负担重。
我们需要的不只是一个自动化测试系统,而是一个更好用的、管理成本更低的自动化测试系统。
1.3 为什么要自研
提到接口自动化测试工具,开源有 JMeter、Postman 等,司内也有成熟的 WeTest、ITEST 等,这些都是开箱即用的,但经过调研和评估,我们还是决定自己造一个轮子。考虑的点如下:
- 测试工具的实现原理并不复杂,实现成本不高,维护难度不大;
- 现有工具并不符合业务要求,例如自定义的调度方案,以及支持内部 RPC 框架;
- 我们需要把自动化测试与现有的系统连接起来,比如上线系统,用例失败告警系统,流量分析系统等;
- 当我们需要一些非标准能力的时候,外部工具很难快速,甚至无法支持,拓展性弱;
- 这个系统主要是为了覆盖后台接口测试,使用体验上要更贴近后台同学的使用习惯,降低用例管理成本。
1.4 目标
结合我们遇到的痛点以及业务需求,自研的自动化测试系统应该具备以下的能力:
- 它应该是跟实现语言无关的,甚至是无代码的,消除不同编程语言和框架带来的隔阂;
- 编写用例应该是纯粹的,用例跟测试服务分离,变更用例不需要变更自动化测试服务;
- 能够支持场景测试(多个用例组成场景),且能支持用例间的变量引用;
- 提供多种调度方案,可以按全量调度、按业务模块调度、按用例组调度、按单个用例调度,充分满足业务和调试需求;
- 这个系统要支持同时管理 HTTP 和 RPC 用例,可以覆盖请求的上下游链路;
- 尽最大可能降低后台同学编写用例的成本。
?同时,在这我也准备了一份软件测试视频教程(含接口、自动化、性能等),需要的可以直接在下方观看就行,希望对你有所帮助!【公众号:互联网杂货铺】免费领取软件测试资料!
2024年Python自动化测试全套保姆级教程,70个项目实战,3天练完,永久白嫖...
二、自动化测试系统实现
2.1 整体架构
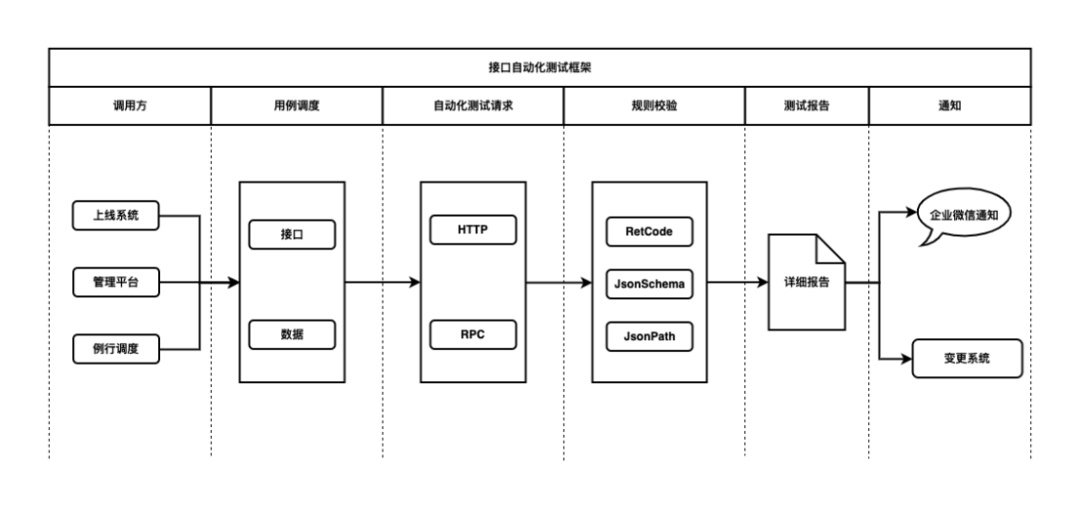
2.2 统一 HTTP 和 RPC 访问形式
HTTP 和 RPC 请求在形式上可以被统一起来,其描述形式如下:
HTTP访问方式:http://host:port/urlpath + reqbody
RPC访问方式:rpc://ip:port/method + reqbody
通过这种统一的描述形式,再结合我们的业务架构,就可以设计一种通用的访问方式。后台的系统架构如下图所示:
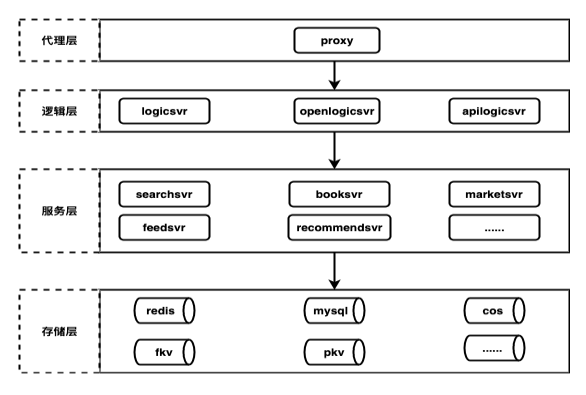
从 proxy 层往下,所有的调用都是一个个后台服务模块,HTTP 访问的是逻辑层,RPC 访问的是服务层。那么只需要配置用例的归属模块,通过模块名 + Client 配置就可以对 HTTP 和 RPC 请求进行区分以及寻址。
从变更系统的角度来看,我们的上线变更也是按模块来的。因此把用例归属到一个个具体的模块,是最符合后台同学认知的做法。
因此我们通过配置模块名这种统一的形式,为使用者提供了统一的管理方式,只需要指定模块名就可以任意访问 HTTP 或者 RPC 请求,其流程如下:
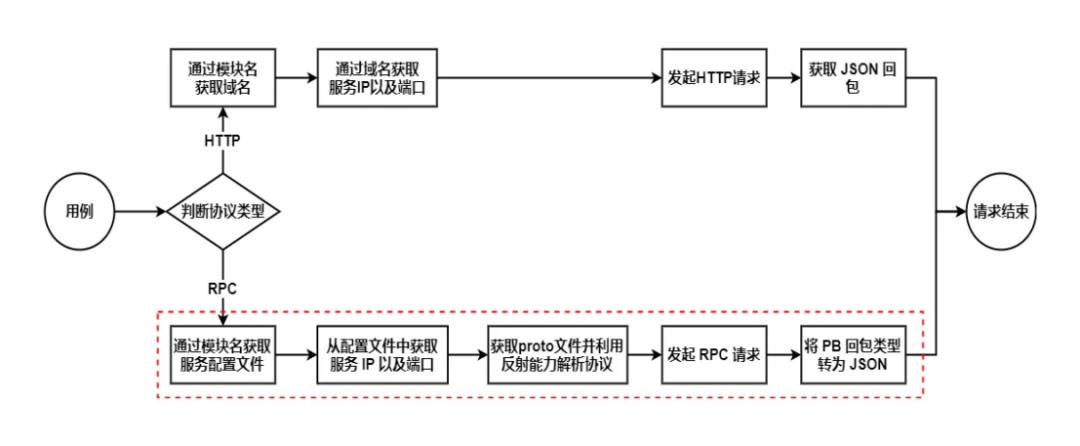
在红色虚线框的流程中,只需要配置模块名,就可以通过模块名获取到 RPC 服务的所有信息,包括其接口定义、请求包定义、回包定义,这不是一种通用能力,需要业务基于系统架构以及线上环境去拓展,但这带来了以下便利:
可以支持任意的业务 RPC 框架,拓展性强;
只需要配置模块名就可以访问所有的 RPC 请求,无需逐个手动上传解析 proto 文件,减少操作步骤;
不需要关心 proto 的更新,实时拉取线上 proto 的信息,协议永远是最新版本。
这里的统一包含两部分:第一部分是访问形式的统一(模块),降低了配置用例的成本;第二部分是数据的统一(JSON),它统一了对回包方式的校验,降低了校验成本。
2.3 接口参数传递(参数池构造)
很多业务场景的完成都是由多个接口组成的一条链路实现,而且这种链路型的自动化测试,通常会存在参数依赖关系,一个用例的入参,可能要依赖上游响应回包的某个字段值,因此需要提取出来并传递给下一个接口。如下图:

其解决方案是,通过正则或者 JSON Extracor 等提取的结果作为变量,然后再传递给下游用例使用,这也是很多测试工具使用的方式,但是维护起来不够方便,仍有进一步优化的空间。
于是我们提出了参数池的概念,将每个用例可能用到的字段都放入一个池子里,这个池子的元素是一个个 key-value。key 是我们要使用的变量,value 则是 key 对应的取值,值得注意的是,value 既可以是一个字面值,也可以是一个 JSONPointer 的路径,这个路径可以从响应回包中提取变量值。
在这种方式下,不同用例间的参数依赖不再是从上一个“传递”到下一个,而变成了一个随取随用的池子,因此我们把它称为参数池。同时我们通过自定义的语法,实现了一个简单的模板引擎,将我们引用的变量替换为池子里的 value 值。参数池构造以及使用图示如下:

2.4 JSON Schema 组件
下面贴一段代码看看现有 WeJestAPITest 框架是如何对返回值做校验的,并分析一下它可能存在的问题:
function bookInfoBaseCases(bookInfoObject) {
it('预期 bookInfo.bookId 非空,且为字符串,且等于12345', () => {
expect(bookInfo.bookId).not.toBeNull();
expect(typeof bookInfo.bookId).toEqual('string');
expect(bookInfo.bookId).toEqual('12345');
});
}这种校验方式存在以下几个问题:
这是针对单个字段进行校验,如果一个回包里有几十上百个字段,这种手工方式不可能实现全量字段校验;
编写一个用例需要有 js 基础,对其他编程语言的使用者不友好;
断言规则都是一条条散落在代码文件中,展示和管理有难度;
调试需要变更测试服务,调试成本高。
现有框架的不便导致了用例管理上的种种问题,而我们根据这些不便之处去反向思考,我们到底需要什么样的校验方式,这种情况下我们找到了 JSON Schema。
JSON Schema 是描述 JSON 数据格式的工具,Schema 可以理解为模式或者规则,它可以约束 JSON 数据应该符合哪些模式、有哪些字段、其值是如何表现的。JSON Schema 本身用 JSON 编写,且需要遵循 JSON 本身的语法规范。
下面以bookInfo的校验为例,写一份 JSON Schema 的校验规则:
// bookInfo信息
{
"bookId":"123456",
"title":"书名123",
"author":"作者123",
"cover":"https://abc.com/cover/123456.jpg",
"format":"epub",
"price":100
}
// 对应的JsonSchema校验规则
{
"type": "object",
"required": ["bookId", "title", "author", "cover", "format", "price"],
"properties": {
"bookId": {
"type": "string",
"const": "123456"
},
"title": {
"type": "string",
"minLength": 1
},
"author": {
"type": "string",
"minLength": 1
},
"cover": {
"type": "string",
"format": "uri"
},
"format": {
"type": "string",
"enum": ["epub", "txt", "pdf", "mobi"]
},
"price": {
"type": "number",
"exclusiveMinimum": 0
}
}
}通过对比,JSON Schema 的优点非常显而易见:
可读性高,其结构跟 JSON 数据完全对应;
所有规则都处在一个 Schema 中,管理和展示清晰易懂;
它本身是一个 JSON,对于任何编程语言的使用者都没有额外学习成本;
此外,我们可以通过一个现有的 JSON 反向生成 JSON Schema,然后在这个 JSON Schema 的基础上进行简单的修改,就能得到最终的校验规则,极大降低了我们编辑用例的工作量和时间成本。
2.5 JSON Path 组件
有了 JSON Schema 之后,我们校验方式看似已经非常完美了。它既可以低成本的覆盖全量字段校验,还可以很方便的进行字段类型、数值的校验。
但实际使用中我们发现有些测试场景是 JSON Schema 覆盖不到的,比如:一条用户评论有 createtime 和 updatetime 两个字段,需要校验 updatetime >= createtime。这是 JSON Schema 的短板,它可以约束 JSON 的字段,但是它没办法对两个字段进行对比;同时 JSON Schema 跟 JSON 是一对一的,如果我们需要比较两个不同 JSON 的同一个字段,它同样无能为力。这就引出了我们需要的第二个工具 —— JSONPath。
JSONPath 是一个 JSON 的信息抽取工具,可以从 JSON 数据中抽取指定特定的值、对象或者数组,以及进行过滤、排序和聚合等操作。而 JSONPath 只是一个 JSON 字段的提取工具,要利用它来实现一个断言判断还需要进一步封装。
在这里我们用一个 JSONPath 表达式来表示一个断言,下面是一些简单的使用示例:
// 校验updateTime > createTime
$.updateTime > $.createTime
// 返回的bookId必须为某个固定值
$.bookId == ["123456"]
// datas数组不能为空
$.datas.length > [0]
// datas数组中必须包含某本书,且价格要大于0
$.datas[?(@.bookId=='123456')] > [0]值得注意的是,JSON Schema 和 JSON Path 断言校验并非二选一,既可以同时校验,也可以根据场景选择任意一种校验方式。与此同时,如果项目前后端交互的协议是 XML、 proto 或者其他协议,可以将其统一转为 JSON 格式,JSON 更容易理解且工具链更多更成熟,否则我们将要为每一种序列化的协议都开发一套类似的工具,重复劳动。
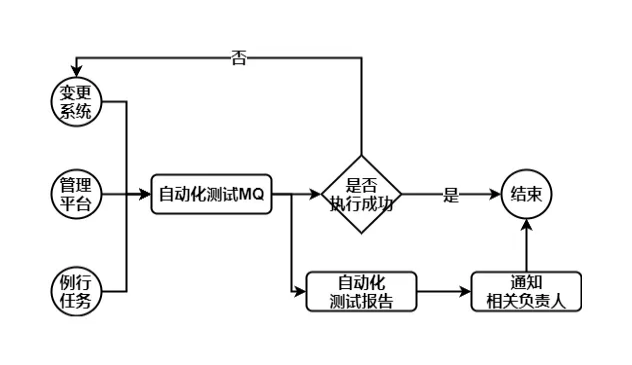
2.6 变更系统接入与调度
在这里,我们使用异步 MQ 去调度测试任务,它有三个主要的特点:

三、自动化测试系统实现
在拥有了一个接口自动化测试平台之后,我们面临一个新的问题:如何快速提升自动化测试的覆盖率?
这个问题有一个隐含的前提,我们需要一个可以衡量覆盖率的指标,接下来将介绍我们如何构造这个指标,并分享一些提升覆盖率的方案。
3.1 变更系统接入与调度
要衡量覆盖率,第一反应必然是基于前后端约定的协议进行分析。但是沿着这条思路去分析我们遇到了以下几个难点:
- 协议管理不规范,散落在 git 文档、yapi、wiki 等多处地方,且格式不统一;
- 文档落后于实际接口协议,且可靠性有待考究;
- 协议参数并非都是正交的,使用协议计算出来的参数组合不符合实际情况;
因此,使用前后端协议进行分析这条路是行不通的。因此我们打算从线上流量入手,对流量的参数特征进行分析,并使用线上流量来生成自动化测试用例。
3.2 整体流程

3.3 流量特征分析
一个 HTTP 请求,我们通常需要分析的是以下部分:请求方法、URL、请求包、返回包。而结合我们的业务场景,我们还需要一些额外的信息:用户 ID、平台(安卓、IOS、网页等)、客户端版本号等。我们调研过一些流量采集分析并生成用例的系统,大多只能对通用信息进行分析,并不能很好的结合业务场景进行分析,拓展性不足。
我们有一个请求,其 url 参数为 listType=1&listMode=2、vid 为10000、平台为 android、版本号为7.2.0,其请求体如下:
{
"bookId":"12345",
"filterType":1,
"filterTags":["abc","def"],
"commOptions":{
"ops1":"testops1",
"ops2":"testops2"
}
}其中 url 和 header 里的参数都很容易解析,不再赘言,下面讲一下 JSON 请求中的参数提取方法。这里我们用 JSONPointer 来表示一个参数的路径,作为这个参数的 key 值,那么可以提取获得以下参数:
// url 和 header 中提取的参数
listType=1
listMode=2
vid=10000
platform=android
appver=7.2.0
// JSON 中提取的参数
/bookId=12345
/filterType=1
/filterTags=["abc", "def"]
/commOptions/opts1=testops1
/commOptions/opts2=testops2如此一来,参数的表现形式可以统一为 key-value 的形式,我们调研的工具也基本止步于此,接下来要么是用正交计算用例的方式辅助人工编辑用例,要么就是对大量流量生成的用例进行去重。
但这达不到我们预设的目标,我们不妨更进一步,通过大量的线上流量构造出接口参数的特征,在这里我们提出一个定义,接口参数的特征包括五部分:
- 参数个数;
- 参数类型;
- 参数取值范围;
- 参数可枚举性;
- 参数可组合性。
我们的工作主要集中在参数的可枚举性分析,这也是参数分析的突破点。假设我们从线上对某个接口进行采样,采样条数为 1W 条,将得到以下的参数:
listType=[1, 2, 3, 4]
listMode=[1, 2]
vid=[10000, 10001, 10002, 10003, ...] // 3000+
platform=[android, ios, web]
appver=[7.2.0, 7.1.0, 7.3.0, ...] // 20
/bookId=[12345, 23456, 34567, 56779, ...] // 4000+
/filterType=[1, 2]
/filterTags=[abc, def, efg]
/commOptions/opts1=[testops1, testops1_]
/commOptions/opts2=[testops2]有了以上提取到的参数枚举值,我们设定一个合理的阈值(比如30),就可以判断哪些参数是可枚举的,很明显 vid 和 /bookId 并不是可枚举的参数,在覆盖用例时不需要对这两个参数进行覆盖。
在实践中,我们发现固定阈值并不能精准识别到有效的枚举参数,阈值需要跟随采样的数据动态调整。不同接口请求量可能从几十到几十万不等,如果一个接口请求条数只有30条,每一个参数的枚举值都小于设定的阈值,所有参数都是有效参数,这不符合实际情况。因此阈值要随着采样条数的变化而变化,可以按请求数量阶梯变化,也可以按请求数量成比例变化。对于特定参数,还要提供人工配置快速介入,指定参数是否可枚举。
在我们知道哪些参数是可枚举的有效参数后,接下来可以对参数的可组合性进行分析。实际上我们并不需要分析任意两个参数两两是否可组合,基于线上流量去分析即可。我们简单给一个例子:
listType=1&listMode=1&platform=android&appver=7.2.0
listType=1&listMode=1&platform=ios&appver=7.2.0
listType=1&listMode=1&platform=web&appver=7.2.0
listType=2&listMode=1&platform=android&appver=7.2.0
listType=2&listMode=1&platform=ios&appver=7.2.0
listType=2&listMode=1&platform=web&appver=7.2.0
listType=3&listMode=2&platform=android&appver=7.2.0
listType=3&listMode=2&platform=ios&appver=7.2.0
listType=3&listMode=2&platform=web&appver=7.2.0那么在覆盖用例时我们需要覆盖这9个组合,通过组合分析我们甚至可以发现线上是否有错误使用的参数组合,需求是否发生了变更产生了新的组合参数。
要提升覆盖率,本质上就是覆盖所有可枚举参数的枚举类型以及组合,这就是我们在上面提到过的覆盖率指标。有了这个指标,我们就可以对覆盖率提出以下计算公式:
全局覆盖率 = 已覆盖的接口数 / 全部接口数 * 100%
?
接口有效用例 = 全部可枚举参数的可枚举值 + 全部可枚举参数的组合
?
接口覆盖率 = 已覆盖的有效用例数 / 接口有效用例数 * 100%
?
PS:当接口覆盖率达100%时视为接口已实现用例覆盖
3.4 用例生成
经过上面对流量的特征分析以及筛选,我们得到了一批有效流量,接下来就可以使用这些流量来自动化生成用例,其中最主要的工作是为用例生成校验的 JSON Schema 规则。其生成过程如下图所示:

如上图所示,任何 JSON Schema 的生成工具所生成的 Schema 都不可能百分百满足业务需求,我们仍然要根据业务场景对 Schema 进行微调。比如在搜索场景下,我们用一个 results 数组来承载返回结果,生成器生成的 Schema 只约定了 results 字段必须要存在,并且字段类型为数组类型。如果有一天返回了一个空的 results 数组,那么默认生成的 Schema 是检查不出这个问题的,我们可以为 results 数组增加 minItems = 1 的规则,要求 results 数组必须大于等于 1,下次校验时遇到空数组就能够告警出来。
同时,在用例执行时遇到校验不通过的情况,我们也设计了一套自动化 promote 用例的流程,不需要手工对用例进行改动。其流程如下:
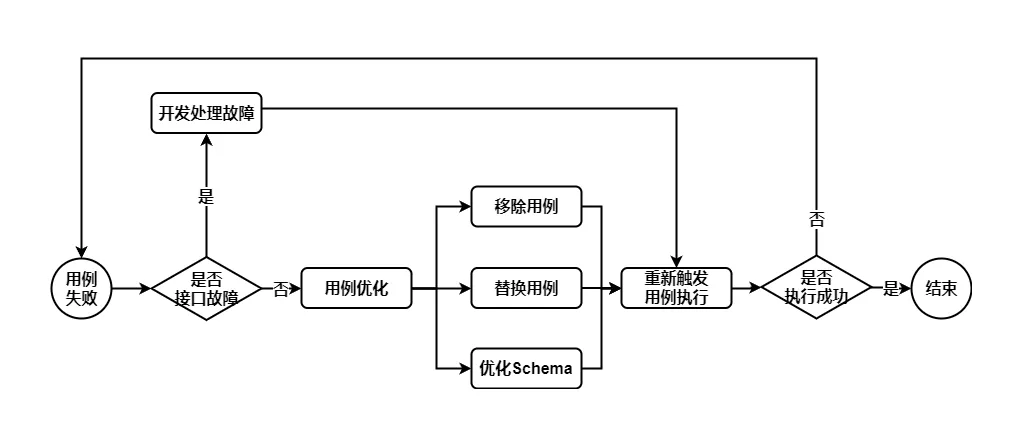
其中用例优化分为三种情况:
- 移除用例:用例已失效,直接删除用例;
- 替换用例:用例不符合预期,从线上根据同样的参数选取请求重新生成一个用例;
- 优化 Schema:用例中某些字段并非必需字段,或者属于预期内的变化(比如用户的未购变已购导致某些字段被替换)。

我们使用的 Schema 生成工具是 genson,它可以为一个 JSON 生成对应的 JSON Schema。这个工具有个很重要的特性:它是一个多输入的 JSON Schema 生成工具,可以接收多个 JSON 或者 Schema 作为输入参数,生成一个符合所有输入要求的 Schema,这一点正是我们自动化的关键,使得我们不需要手动编辑校验规则。下面简单展示一下我们现在的系统是如何优化失败用例的:

3.5 用例发现与补全
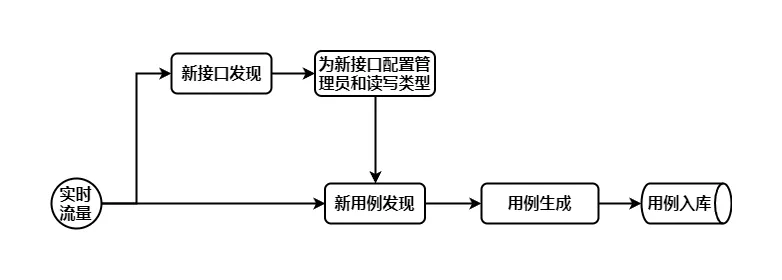
用例的自动化发现分为两个离线任务:一个是新接口的发现,一个是新用例的发现。
新接口是指我们有新的功能上线,当线上有流量访问时,我们应该及时发现这个新的请求,并将这个请求纳入我们的自动化测试管理范围。
新用例是指通过对流量分析,发现了新加的可枚举参数,或者之前用例未曾覆盖的参数组合,我们通过对比线上流量和已经采集落库的用例进行 diff 分析,得到并生成新的用例。
下图是对用例的自动化发现与补全的简单示例:
3.6 流量特征应用
基于上面提到的流量特征分析以及用例生成,我们的用例个数从150+提升到8000+,实现了读接口100%用例覆盖,覆盖率有了一个质的飞跃。
对于写接口实现了覆盖率统计以及用例推荐,极大降低了在编辑用例时的心智负担,不需要自己去构造参数以及遍历所有的参数组合,跟随着推荐的用例去补全即可。
同时针对我们前面提到的前后端协议分散在各个地方,且接口与文档不一致的问题,我们通过线上流量对请求参数和请求回包的 Schema 进行持续的迭代,然后再将 Schema 反向生成 JSON, 就可以得到一份最全、最新的接口协议,同时这份协议还可以提供给客户端同学用来构造参数进行 mock 联调。
四、总结
至此,我们已经完成了整个后台接口自动化测试系统的搭建,并完成了预设的全部目标:
集成 JSON Schema 和 JSONPath 这两个组件,实现了一个无代码以及用例跟测试服务分离的自动化测试系统;
通过用例的组合以及参数池构造实现了场景测试和用例间变量引用;
支持了多种定制化的调度方案,并接入到上线系统流程中;
打通 HTTP 和 RPC 接口访问,结合业务架构极大降低了接入 RPC 用例的成本;
通过用例自动化生成进一步降低用例管理成本,快速提高了自动化测试的覆盖率。
对于旧用例系统上的数据,我们花费了将近两周,将数千行测试代码、将近一千条校验规则全部迁移到新的自动化测试平台上,得到了150+的新用例,并且校验的规则变成了150+的 JSON Schema,不需要维护任何一行代码,就得到了比之前更完善的全字段校验规则覆盖。
此外,我们通过用例发现和用例生成,生成了8000+的用例,实现了读接口100%用例覆盖,并多次辅助发现线上异常数据问题,在用户还未感知前就已经将问题扼杀在摇篮之中。
笔者认为,本文最重要的并不是对各种工具的集成和使用,100% 的用例覆盖也并非本文的最终目标。各种开源和付费工具数不胜数,只要舍得投入人力 100% 的用例覆盖也并非难事。本文真正重要的是提出了一种通用的测试框架架构,以及基于线上流量分析得到了一种测试覆盖率的度量方案。
秉持着这种思路,上文中我们提到的调度系统、用例执行 MQ、校验工具、测试告警系统、流量采集系统、用例生成系统,都可以基于业务灵活调整,低成本实现大规模用例覆盖。
最后感谢每一个认真阅读我文章的人,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:

这些资料,对于做【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴我走过了最艰难的路程,希望也能帮助到你!凡事要趁早,特别是技术行业,一定要提升技术功底。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!