极市平台|100+深度学习各方向数据集资源大盘点
本文来源公众号“极市平台”,侵权删,干货满满。部分数据集可能重复出现,问题不大。
原文链接:100+深度学习各方向数据集资源大盘点
本文汇总了图像增强/分割/识别/检测、工业检测、医学图像、目标跟踪、异常检测等方向数据集资源,均附有下载链接。
一、图像增强
对比度增强评估数据库(CEED2016)
数据集下载地址:http://suo.nz/2JfsSf
该CEED2016是新开发的图像数据库,专门用于对比度增强评估。该数据库包含 30 张原始彩色图像和 180 张使用六种不同 CE 方法获得的增强图像。

NILUT三维LUT数据集
数据集下载地址:http://suo.nz/2QLFVk
内窥镜真实图像
数据集下载地址:http://suo.nz/2YdgQ5
在内窥镜检查中,由于中空器官内壁的光反射而出现曝光误差是很常见的。例如,当内窥镜的尖端(有光)指向褶皱时,这些结构会反射光线,引起过度曝光,而镜框另一端可能会出现曝光不足的区域。目前,增强曝光误差的方法需要配对数据,即损坏的帧及其各自的地面实况(即未损坏或干净的图像)。例如,对于自然图像,已经提出了包含常见现实生活图像的LOL或MIT-Adobe FiveK数据集。这些配对数据集允许研究人员利用标准化的地面实况图像来训练和评估他们的模型。我们的工作旨在通过使用GANs创建一个没有任何曝光误差的真实图像和具有曝光误差的相同图像的配对数据集。
真实世界模糊图像数据集
下载链接:http://suo.nz/2nk7w2
训练集:182 个不同场景的 3,758 个图像对。
测试集:50 个不同场景的 980 个图像对。

I-HAZE图像去雾数据集
下载链接:http://suo.nz/2fNUrl
该数据集中包含 35 个有雾图像对和相应的无雾(地面实况)室内图像。与大多数现有的去雾数据库不同,雾霾图像是使用专业雾霾机产生的真实雾霾生成的。为了简化颜色校准并改进去雾算法的评估,每个场景都包含一个 MacBeth 颜色检查器。此外,由于图像是在受控环境中捕获的,因此无雾和有雾图像都是在相同的照明条件下捕获的。

UIEB水下图像增强数据集
下载链接:http://suo.nz/3dY13O
该数据集包括 950 张真实水下图像,其中 890 张具有相应的参考图像。并将其余60幅无法获得满意参考图像的水下图像视为具有挑战性的数据。

GoPro去模糊数据集
下载链接:http://suo.nz/36rNZ7
用于去模糊的 GoPro 数据集由 3,214 张模糊图像组成,大小为 1,280×720,分为 2,103 张训练图像和 1,111 张测试图像。该数据集由成对的真实模糊图像和高速摄像机获得的相应地面实况图像组成。

NH-HAZE
下载地址:http://m6z.cn/5tyN0D
这是一个非均匀的真实数据集,具有成对的真实雾度和相应的无雾度图像。这是第一个非齐次图像去模糊数据集,包含55个室外场景。在场景中引入了非均匀雾,使用专业雾发生器模拟雾场景的真实条件。

ExDark图像数据集
下载地址:http://suo.nz/2lidoI
Exclusively Dark (ExDARK) 数据集是 7,363 张从极低光环境到黄昏(即 10 种不同条件)的低光图像的集合,具有 12 个对象类(类似于 PASCAL VOC),在图像类级别和局部对象边界上进行了注释盒子。

WoodScape自动驾驶鱼眼数据集
下载地址:http://suo.nz/2HMEtL
WoodScape 包含四个环视摄像头和九项任务,包括分割、深度估计、3D 边界框检测和新型污染检测。为超过 10,000 张图像提供实例级别的 40 个类的语义注释。
PolyU数据集
数据集下载地址:https://sourl.cn/rMsdE8
大多数以前的图像去噪方法都集中在加性高斯白噪声(AWGN)上。然而,随着计算机视觉技术的进步,现实世界中的噪声图像去噪问题也随之而来。为了在实现并发真实世界图像去噪数据集的同时促进对该问题的研究,作者们构建了一个新的基准数据集,其中包含不同自然场景的综合真实世界噪声图像。这些图像是由不同的相机在不同的相机设置下拍摄的。

二、实例分割
细胞实例分割数据集
数据集下载链接:http://suo.nz/3bokV6
引入了新的大型细胞实例分割数据集 (CISD)。它包括3911个样品,其中包含至少两个接触或重叠的尿路上皮细胞。细胞实例由训练有素的细胞技术人员手动注释。所有样品均从 30 张数字细胞学载玻片中提取,这些载玻片用 9 种不同的 Papanicolaou 染色染色。细胞学载玻片使用豪洛捷 ThinPrep?5000 处理器从健康患者的尿液样本中制备,并常规使用安捷伦 Dako 盖染色仪?进行染色。最终使用具有21个焦平面的Hamamatsu NanoZoomer?S360对载玻片进行数字化,并以扫描仪自动对焦确定的最佳焦平面为中心。
非模态实例分割数据集
数据集下载链接:http://suo.nz/33S7Qp
这是遥感领域的非模态实例分割数据集。数据集目前仅包含 9 张图片,其余 1000+ 张图片将在稍后发布。屋顶、建筑物和遮挡类别在数据集中进行了标记,分别表示建筑物的屋顶、建筑物的整个区域和建筑物的遮挡部分。

Embrapa酿酒葡萄实例分割数据集
数据集下载链接:http://suo.nz/337vkW
本数据集用于研究葡萄栽培中基于图像的监测和现场机器人的对象检测和实例分割。它提供了在田间采集的五种不同葡萄品种的实例。这些实例显示了葡萄姿势、光照和焦点的差异,包括遗传和物候变化,如形状、颜色和紧凑度。

树上芒果实例分割数据集
数据集下载链接:http://suo.nz/2VBigf
使用带有多边形区域注释的VGG图像注释工具(Dutta & Zisserman 2019)对图像进行注释。两个文件夹包含用于训练和文本图像集的 COCO 注释格式的图像和 JSON 注释文件。
实例分割计算机视觉项目
数据集下载链接:http://suo.nz/2O5vcs
以下是此项目的一些用例:
1.杂货库存管理:洋葱检测器可用于超市和杂货店,通过准确识别和计数存储区域或展示架上的洋葱,自动监控和管理洋葱的库存和库存。
2.洋葱收获自动化:使用洋葱检测器模型开发收获自动化设备可以帮助农民和农业公司检测和分离除草植物或土壤中的洋葱,显着提高洋葱收获过程的速度和效率。
3.食品工业质量控制:洋葱检测仪可以集成到食品加工厂的生产线中,使系统能够自动检测各个加工阶段的洋葱 - 例如分类,清洁和分级 - 以确保最终产品的质量一致。
4.减少洋葱浪费:该模型可用于零售、餐厅或家庭环境,以识别可能开始变质的洋葱,使消费者或餐饮服务经营者能够在需要丢弃之前优先使用这些洋葱,最终限制食物浪费。
5.智能厨房辅助:通过将洋葱检测器集成到智能厨房电器中,用户可以根据可用成分(包括洋葱)接收自动食谱建议,从而更轻松地确定膳食选项,而无需手动搜索食谱数据库。

三、目标跟踪
用于低空交通监控的多模态无人机数据集
数据集下载链接:http://suo.nz/2RX507
AU-AIR 数据集是第一个用于目标检测的多模态无人机数据集。
AU-AIR具有以下几个特点:
-
航空图像中的物体检测
-
大于2 小时原始视频
-
32,823 个标记帧
-
132,034 个对象实例
-
与交通监控相关的8个对象类别
-
帧上还标注了无人机的时间、GPS、IMU、高度、线速度

KITTI目标跟踪
数据集下载链接:http://suo.nz/2KqSby

ALOV300++跟踪数据集
数据集下载链接:http://suo.nz/2dKDTl
ALOV++,Amsterdam Library of Ordinary Videos for tracking 是一个物体追踪视频数据,旨在对不同的光线、通透度、泛着条件、背景杂乱程度、焦距下的相似物体的追踪。

PathTrack 数据集
数据集下载链接:http://suo.nz/2OFhXy
用于多目标跟踪 (MOT)。PathTrack 数据集包含 720 个视频序列中的 15,000 多个人的轨迹。

VOT2020
数据集下载链接:http://suo.nz/2W7iD5
NfS高帧率视频数据集
数据集下载链接:http://suo.nz/34o8df
第一个更高帧率的视频数据集(称为极品飞车 - NfS)和视觉对象跟踪基准。该数据集包含 100 个视频(380K 帧),这些视频是使用现在常见的更高帧率 (240 FPS) 摄像机从现实世界场景中捕获的。所有帧都用轴对齐的边界框进行注释,所有序列都用九个视觉属性手动标记——例如遮挡、快速运动、背景杂乱等。
Temple Color 128
Temple Color 128 数据集下载链接:http://suo.nz/2dKEEL
本数据集包含一大组 128 种颜色序列,带有基本事实和挑战因素注释(例如,遮挡)

四、少样本/零样本学习
FSOD少样本目标检测数据集
数据集下载链接:http://suo.nz/3d6H0E
少样本目标检测数据集(FSOD)是一个高度多样化的数据集,专门为少样本目标检测而设计,本质上是为了评估模型在新类别上的通用性。

UT Zappos50K鞋类数据集
数据集下载链接:http://suo.nz/35EG4Z
UT Zappos50K ( UT-Zap50K ) 是一个大型鞋类数据集,包含从Zappos.com收集的50,025 个目录图像。这些图像分为 4 个主要类别——鞋子、凉鞋、拖鞋和靴子——其次是功能类型和个人品牌。鞋子以白色背景为中心,并以相同方向进行拍照,以便于分析。

Animals with Attributes数据集
数据集下载链接:http://suo.nz/2Y8tgq
该数据集提供了一个基准迁移学习算法的平台,特别是属性基分类和 零样本学习[1]。它可以作为原始Animals with Attributes (AwA)数据集 [2,3]的直接替代品,因为它具有相同的类结构和几乎相同的特征。它由 50 个动物类别的 37322 张图像组成,每张图像都有预先提取的特征表示。这些类与 Osherson 的经典类/属性矩阵 [3,4] 对齐,从而为每个类提供 85 个数字属性值。使用共享属性,可以在不同类之间传输信息。

原始矿物物种识别基准
数据集下载链接:http://suo.nz/2RidE3
该数据集包含 5,000 多种不同的矿物物种,并包含零样本和少样本学习的子集。除了样本本身之外,数据集中的一些条目还附有补充的自然语言描述、大小测量和分割掩码。

RareAct异常动作视频数据集
数据集下载链接:http://suo.nz/2JM0zm
RareAct是一个异常动作的视频数据集,包括“混合手机”、“切键盘”和“微波炉鞋”等动作。它的目的是评估动作识别模型的零样本和少样本组合性,以识别常见动作动词和宾语名词的不太可能的组合。它包含 122 个不同的动作,这些动作是通过组合在 HowTo100M 的大规模文本语料库中很少同时出现但经常单独出现的动词和名词来获得的。

Generix 对象零样本学习 ( GOZ ) 数据集
数据集下载链接:http://suo.nz/2J1o3T
Generix 对象零样本学习 ( GOZ ) 数据集是零样本学习的基准数据集。

五、异常检测
AeBAD航空发动机叶片异常检测数据集
数据集下载链接:http://suo.nz/2IU48P
真实世界的航空发动机叶片异常检测(AeBAD)数据集,由两个子数据集组成:单叶片数据集(AeBAD-S)和叶片视频异常检测数据集(AeBAD-V)。与现有数据集相比,AeBAD具有以下两个特点:1.)目标样本未对齐且处于不同的尺度。2.) 测试集和训练集中正态样本的分布存在域偏移,其中域偏移主要是由光照和视图的变化引起的。

BeanTech 异常检测数据集
数据集下载链接:http://suo.nz/2JEGEi
BTAD (beanTech 异常检测)数据集是真实世界的工业异常数据集。该数据集包含 3 种工业产品的总共 2830 张真实世界图像。

LAD视频序列异常检测
数据集下载链接:http://suo.nz/35AL1Z
Large-scale Anomaly Detection (LAD) 是一个用于对视频序列中的异常检测进行基准测试的数据库,它具有两个方面的特点。1) 包含正常和异常视频片段2000个视频序列,碰撞、火灾、暴力等14个异常类别,场景种类繁多,是目前最大的异常分析数据库。2)提供标注数据,包括视频级标签(异常/正常视频、异常类型)和帧级标签(异常/正常视频帧),方便异常检测。

RoadAnomaly21
数据集下载链接:http://suo.nz/2Y8MHC
RoadAnomaly21是一个用于异常分割的数据集,其任务是识别包含训练期间从未见过的对象的图像区域。它由 100 张带有像素级注释的图像的评估数据集组成。每张图片至少包含一个异常物体,例如动物或未知车辆。异常可以出现在图像的任何地方,并且大小差异很大,覆盖图像的 0.5% 到 40%。

UBnormal数据集
数据集下载链接:http://suo.nz/2Rix5f
UBnormal 是一种新的监督开放集基准测试,由多个虚拟场景组成,用于视频异常检测。与现有数据集不同,该数据集在训练时引入了像素级注释的异常事件,首次实现了使用全监督学习方法进行异常事件检测。为了保留典型的开放集公式,数据集在视频的训练和测试集合中包含不相交的异常类型集。

VisA异常数据集
数据集下载链接:http://suo.nz/2JMk0y
VisA 数据集包含 12 个子集,对应 12 个不同的对象。共有 10,821 张图像,其中包含 9,621 个正常样本和 1,200 个异常样本。四个子集是不同类型的印刷电路板 (PCB),具有相对复杂的结构,包括晶体管、电容器、芯片等。对于视图中多个实例的情况,我们收集了四个子集:Capsules、Candles、Macaroni1 和 Macaroni2。Capsules 和 Macaroni2 中的实例在位置和姿势上有很大不同。

六、医学影像
CT 医学图像
下载链接:http://suo.nz/2tQehH
该数据集旨在允许测试不同的方法来检查与使用对比度和患者年龄相关的 CT 图像数据的趋势。基本思想是识别与这些特征密切相关的图像纹理、统计模式和特征,并可能构建简单的工具,在这些图像被错误分类时自动对其进行分类(或查找可能是可疑情况、错误测量或校准不良机器的异常值)
MedMNIST医学图像分割评估
下载链接:http://suo.nz/2Bmrmo
MedMNIST,这是 10 个预处理的医学开放数据集的集合。MedMNIST 经过标准化处理,可在轻量级 28x28 图像上执行分类任务,无需背景知识。它涵盖了医学图像分析中的主要数据模式,在数据规模(从 100 到 100,000)和任务(二元/多类、序数回归和多标签)上具有多样性。MedMNIST 可用于教育目的、快速原型设计、多模式机器学习或医学图像分析中的 AutoML。此外,MedMNIST Classification Decathlon 旨在对所有 10 个数据集上的?AutoML?算法进行基准测试

多标签视网膜疾病 (MuReD) 数据集
下载链接:http://suo.nz/2ISEr5
多标签视网膜疾病(MuReD)数据集,使用从三个不同的最先进来源(即 ARIA、STARE 和 RFMiD 数据集)收集的图像,并执行一系列后处理确保图像质量的处理步骤、要分类的广泛疾病以及每个疾病标签有足够数量的样本。MuReD 数据集由 2208 张图像组成,具有 20 个不同的标签,图像质量和分辨率各不相同。同时,确保数据的最低质量,每个标签有足够数量的样本。

疟疾细胞图像数据集
下载链接:http://suo.nz/2VQTUt

皮肤癌 MNIST:HAM10000
下载链接:http://suo.nz/33n6Xy
该数据集收集了来自不同人群的皮肤镜图像,通过不同的方式获取和存储。最终数据集包含 10015 张皮肤镜图像,可用作学术机器学习目的的训练集。案例包括色素病变领域所有重要诊断类别的代表性集合:光化性角化病和上皮内癌/鲍温氏病 (akiec)、基底细胞癌 (bcc),超过50%的病变是通过组织病理学(histo)证实的,其余病例的ground truth要么是后续检查(follow_up),要么是专家共识(consensus),要么是活体共聚焦显微镜(confocal)证实. 数据集包括具有多个图像的病变,可以通过 HAM10000_metadata 文件中的 lesion_id 列进行跟踪。

乳房组织病理学图像
下载链接:http://suo.nz/347Jt1
原始数据集包含以 40 倍扫描的 162 个完整的乳腺癌 (BCa) 标本幻灯片图像。从中提取了 277,524 个大小为 50 x 50 的补丁(198,738 个 IDC 负值和 78,786 个 IDC 正值)。每个补丁的文件名格式为:u_xX_yY_classC.png — > example 10253_idx5_x1351_y1101_class0.png。其中 u 是患者 ID (10253_idx5),X 是裁剪此补丁的 x 坐标,Y 是裁剪此补丁的 y 坐标,C 表示类,其中 0 是非 IDC 和1 是数据中心。
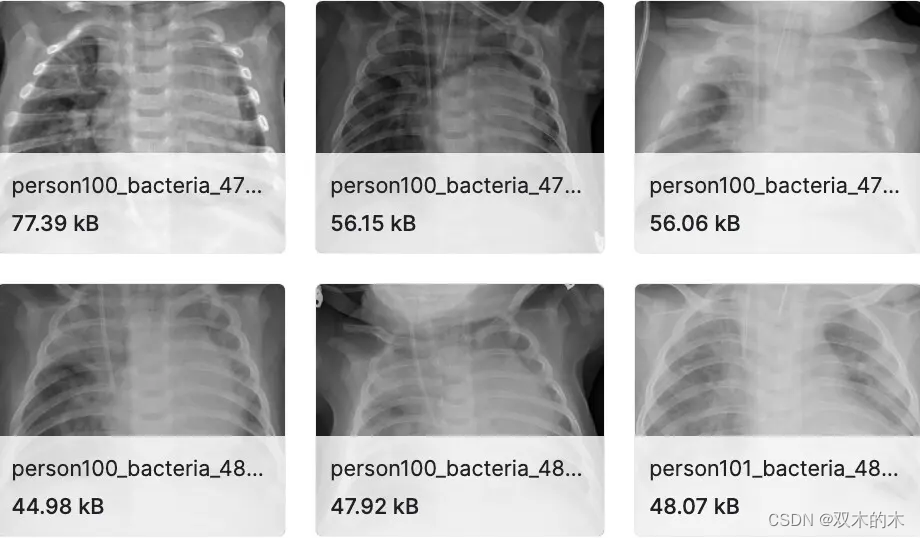
胸部 X 光图像(肺炎)
下载链接:http://suo.nz/3aXYPg
数据集分为 3 个文件夹(train、test、val)并包含每个图像类别(肺炎/正常)的子文件夹。有 5,863 张 X 射线图像 (JPEG) 和 2 个类别(肺炎/正常)。胸部 X 光图像(前后位)选自广州市妇女儿童医疗中心 1 至 5 岁儿科患者的回顾性队列。
白内障数据集
下载链接:http://suo.nz/2cOidH
用于白内障检测的白内障和正常眼睛图像数据集。
恶性与良性皮肤癌
下载链接:http://suo.nz/2kkvio
该数据集包含良性皮肤痣和恶性皮肤痣图像的平衡数据集。数据由两个文件夹组成,每个文件夹包含两种痣的 1800 张图片 (224x244)。
七、面部表情识别
FePh面部表情数据集
数据集下载链接:http://suo.nz/2zIouL
手语背景下带注释的序列化面部表情数据集,其中包含从公共电视台 PHOENIX 的每日新闻和天气预报中提取的 3000 多张面部图像。与大多数当前现有的面部表情数据集不同,FePh 提供具有不同头部姿势、方向和运动的序列化半模糊面部图像。

不平衡面部表情数据集
数据集下载链接:http://suo.nz/2OKM2R
图像大小保持 96x96,并使用改进后的标签。源数据集被分成两个子集——训练和测试。train.csv 和 test.csv 文件分别包含训练和测试子集的标签到文件名的映射。类别有:愤怒、蔑视、厌恶、恐惧、快乐、中性、悲伤和惊讶。
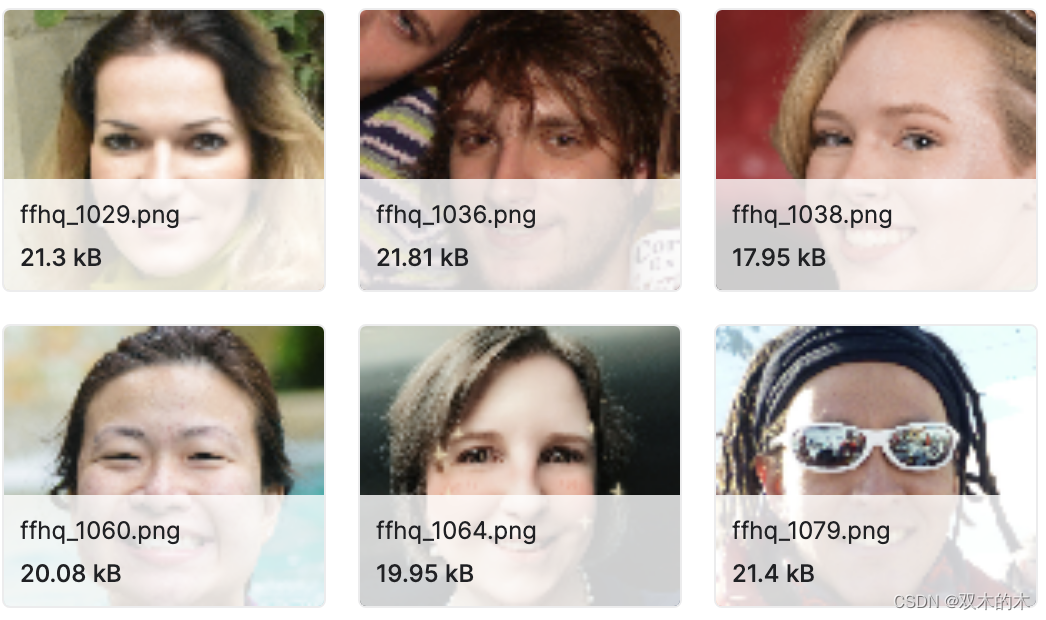
FER-2013
数据集下载链接:http://suo.nz/2WgZ7y
数据由 48x48 像素的人脸灰度图像组成。人脸已自动注册,因此人脸或多或少居中,并且在每张图像中占据大致相同的空间训练集包含 28,709 个示例,公共测试集包含 3,589 个示例。

FANE:面部表情和情绪数据集
数据集下载链接:http://suo.nz/2X1BD1
FANE 是一个图像数据集,用于对野外图像中的面部表情和情绪进行分类。数据集中有九个类别。总共有16,913 张图片。图像是从多个来源收集的,包括其他面部表情数据集,以及主要通过网络抓取的互联网。使用手动注释和预训练模型对图像进行标记。

小鼠面部表情数据集
数据集下载链接:http://suo.nz/34xOHI
老鼠在三种情绪状态(中性、疼痛和发痒)下的面部图像。

八、口罩识别检测
SF-MASK数据集
数据集下载链接:http://suo.nz/2E6ADA
从监控录像中对有面具和无面具的人脸进行分类是最困难的任务之一,数据集SF-MASK来解决这些问题,该数据集适用于小尺寸人脸、部分隐藏的人脸、各种人脸方向和各种面具类型等。SF-MASK是通过收集已经发布的面具相关数据集而构建的。同时,通过分析现有数据集中缺失的数据和补充缺失的数据,使其更加完整。

口罩检测视频数据集
数据集下载链接:http://suo.nz/2wAnAv
一个实时视频/图像数据集,其中包含在大学环境中行走的多个主题(带/不带面具)。每个带注释的帧都包含多个具有唯一标识、边界框和类/标签信息的实例(即人)。数据集和注释可用于训练、验证和测试基于深度学习和计算机视觉的口罩检测算法。以下是数据集的详细信息:视频总帧数:4357 边界框总数:21941 带遮罩的盒子 (MW):8306 不带遮罩的盒子 (NM):13635 图像帧:此文件夹包含 4357 个视频帧 (.png)。
口罩佩戴数据集
数据集下载链接:http://suo.nz/2p4avO
该Mask Wearing数据集是戴各种口罩的人和不戴口罩的人的物体检测数据集。这些图像最初由台湾伊甸社会福利基金会的 Cheng Hsun Teng 收集,并由 Roboflow 团队重新标记。

口罩检测数据集
数据集下载链接:http://suo.nz/2ojy0l
数据集由 2 个文件夹中的 7553 张 RGB 图像组成,分别是 with_mask 和 without_mask。图像被命名为标签 with_mask 和 without_mask。戴口罩的人脸图像为3725张,不戴口罩的人脸图像为3828张。

MDMFR口罩数据集
数据集下载链接:http://suo.nz/2gNkVE
MDMFR 数据集由两个主要集合组成,1) 面罩检测和 2) 蒙面面部识别。我们的 MDMFR 数据集中有 6006 张图像。面罩检测集合包含两类人脸图像,即蒙面和未蒙面。检测数据库包含 3174 个带掩码和 2832 个不带掩码(未掩码)的图像。
RMFD口罩遮挡人脸数据集
数据集下载链接:http://suo.nz/2ojy0v

九、打架识别
监控摄像头下的打架检测
数据集下载链接:http://suo.nz/39IbxQ
该数据集是从包含打架实例的 Youtube 视频中收集的。此外,还包括一些来自常规监控摄像机视频的非打架序列。
-
总共有300个视频,150个打架+150个非打架
-
视频时长 2 秒
-
示例中仅包含与打架相关的部分
此外,由于任务是通过监控摄像头检测打斗,因此首选没有背景运动的视频作为样本。此外,还包括各种打斗场景,例如用物体撞击、踢打、拳击、摔跤。示例中的环境也各不相同,例如咖啡馆、街道、公共汽车等。

UBI-Fight异常事件检测数据集
数据集下载链接:http://suo.nz/3aoBUh
UBI-Fights 数据集是一个独特的全新大型数据集,涉及特定的异常检测并仍然在打斗场景中提供广泛的多样性,该数据集包含 80 小时的视频,在帧级别进行了完全注释。由 1000 个视频组成,其中 216 个视频包含打斗事件,784 个是正常的日常生活场景。删除所有可能干扰学习过程的不必要的视频片段(例如,视频介绍、新闻等) 。

曲棍球比赛检测数据集
数据集下载链接:http://suo.nz/2ceViI
该数据集中包含 1000 个序列,分为两组:打斗和非打斗。

打架识别图像数据集
数据集下载链接:http://suo.nz/2jL8np
该数据集是为“打斗探测器”项目创建的,该项目检测静止图像中的打斗,然后将打斗探测器移动到上下文中具有时间维度的下一级视频检测。打斗数据集是从视频数据集 HMDB51 数据集创建的。
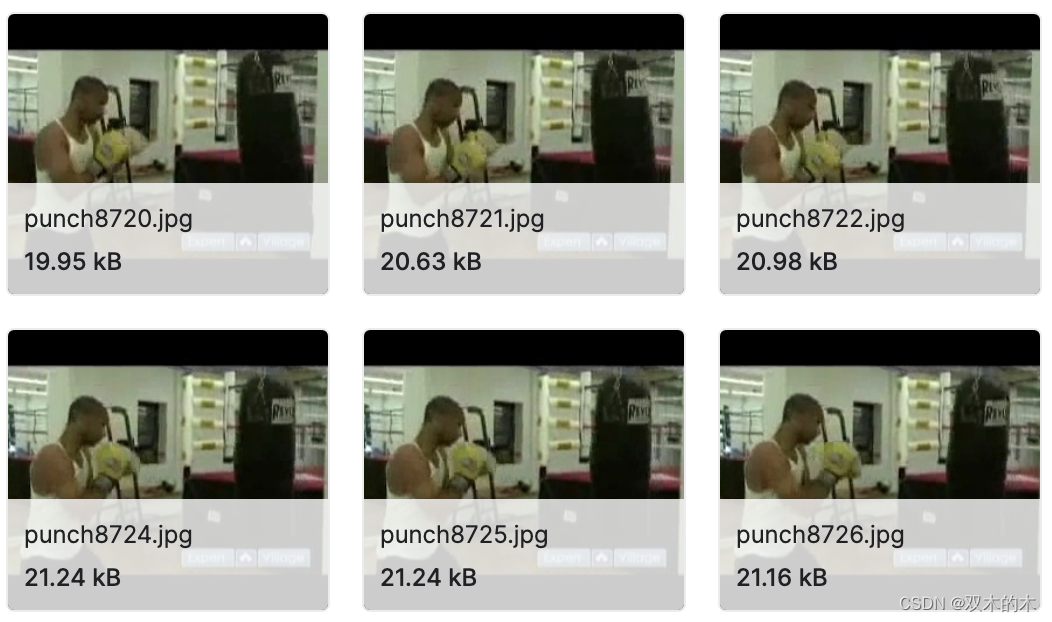
真实街头斗殴视频数据集
数据集下载链接:http://suo.nz/2rhiQO
该数据集包含从 youtube 视频中收集的 1000 个暴力视频和 1000 个非暴力视频,数据集中的暴力视频包含多种环境和条件下的许多真实街头斗殴情况。数据集中的非暴力视频也是从许多不同的人类行为中收集的,如运动、饮食、步行等。

十、垃圾检测分类
AquaTrash垃圾识别数据集
数据集下载链接:http://suo.nz/2CdMGi
该数据集包含 369 张用于深度学习的垃圾图像。总共有 470 个边界框。共有 4 类 {(0: glass), (1:paper), (2:metal), (3:plastic)}

口罩垃圾检测
数据集下载链接:http://suo.nz/2CYpbL
这个数据集是一个极具挑战性的集合,包含从 1200 多个城市和农村地区捕获和众包的 7000 多张原始 Masks 图像,其中每张图像都由DC Labs 的计算机视觉专业人员手动审查和验证。
数据集大小:7000+ 捕获者:超过 1200 多个众包贡献者 分辨率:99% 图像高清及以上(1920x1080 及以上) 地点:拍摄于印度 900 多个城市 多样性:各种照明条件,如白天、夜晚、不同的距离、观察点等 使用设备:2020-2021 年使用手机拍摄 用途:口罩检测、口罩隔离、垃圾口罩检测等

烟头垃圾数据集
数据集下载链接:http://suo.nz/2KuC0k
该数据集由一组 2200 张合成合成的地面香烟图像组成。它专为训练 CNN(卷积神经网络)而设计。
注释:带有自定义类别的分段对象检测 COCO 格式。合成:图像由自定义代码自动合成,利用 Python 图像库将随机比例、旋转、亮度等应用到前景切口 地点:地上和烟头的照片是在得克萨斯州奥斯汀拍摄的 相机:iPhone 8,原始像素分辨率 3024 x 4032。

水下垃圾检测数据集
数据集下载链接:http://suo.nz/2RkRCH
该数据来自 J-EDI 海洋垃圾数据集。构成该数据集的视频在质量、深度、场景中的对象和使用的相机方面差异很大。它们包含许多不同类型的海洋垃圾的图像,这些图像是从现实世界环境中捕获的,提供了处于不同衰减、遮挡和过度生长状态的各种物体。此外,水的清晰度和光的质量因视频而异。这些视频经过处理以提取 5,700 张图像,这些图像构成了该数据集,所有图像都在垃圾实例、植物和动物等生物对象以及 ROV 上标有边界框。

垃圾分类数据集
数据集下载链接:http://suo.nz/2YR4Ho
该数据集包含来自 12 个不同类别的生活垃圾的 15,150 张图像;纸、纸板、生物、金属、塑料、绿色玻璃、棕色玻璃、白色玻璃、衣服、鞋子、电池和垃圾。
Kaggle 垃圾分类图片数据集
数据集下载链接:http://suo.nz/36mRLb
该数据集是图片数据,分为训练集85%(Train)和测试集15%(Test)。其中O代表Organic(有机垃圾),R代表Recycle(可回收)

生活垃圾数据集
数据集下载链接:http://suo.nz/3dT4PS
大约9000多张独特的图片。该数据集由印度国内常见垃圾对象的图像组成。图像是在各种照明条件、天气、室内和室外条件下拍摄的。该数据集可用于制作垃圾/垃圾检测模型、环保替代建议、碳足迹生成等。

垃圾溢出数据集
数据集下载链接:http://suo.nz/2fJocH

SpotGarbage垃圾识别数据集
数据集下载链接:http://suo.nz/2nfBho
图像中的垃圾(GINI)数据集是SpotGarbage引入的一个数据集,包含2561张图像,956张图像包含垃圾,其余的是在各种视觉属性方面与垃圾非常相似的非垃圾图像。

十一、自动驾驶
ExDark图像数据集
下载地址:http://suo.nz/2lidoI
Exclusively Dark (ExDARK) 数据集是 7,363 张从极低光环境到黄昏(即 10 种不同条件)的低光图像的集合,具有 12 个对象类(类似于 PASCAL VOC),在图像类级别和局部对象边界上进行了注释盒子。

Nexet车辆检测数据集
下载地址:http://suo.nz/2sKekn
-
50000张带标注的训练图片
-
41190张测试图片
-
图片来自77个国家

Udacity 自动驾驶汽车数据集
下载地址:http://suo.nz/2Agrp4
该数据集包含 11 个类别的 97,942 个标签和 15,000 张图像。有 1,720 个空样本(没有标签的图像)。
所有图像均为 1920x1200(下载大小约为 3.1 GB)。我们还提供了一个降采样到 512x512(下载大小约 580 MB)的版本,适用于大多数常见的机器学习模型(包括 YOLO v3、Mask R-CNN、SSD 和 mobilenet)。

WoodScape
下载地址:http://suo.nz/2HMEtL
WoodScape 包含四个环视摄像头和九项任务,包括分割、深度估计、3D 边界框检测和新型污染检测。为超过 10,000 张图像提供实例级别的 40 个类的语义注释。

BDD100K
下载地址:http://suo.nz/2OCU68
UCB的全天候全光照大型数据集,包含1,100小时的HD录像、GPS/IMU、时间戳信息,100,000张图片的2D bounding box标注,10,000张图片的语义分割和实例分割标注、驾驶决策标注和路况标注。官方推荐使用此数据集的十个自动驾驶任务:图像标注、道路检测、可行驶区域分割、交通参与物检测、语义分割、实例分割、多物体检测追踪、多物体分割追踪、域适应和模仿学习。

Linkopings交通标志数据集
下载地址:http://suo.nz/2W97aP
-
超过 20,000 张图像 ,其中 20% 已标记。
-
包含 3488个 交通标志。
-
从超过 350 公里的瑞典道路上 记录的公路和城市序列。
非洲地区交通标志数据集
下载地址:http://suo.nz/2WTJGi
该数据集已特别针对非洲地区进行了改进。两个开源数据集仅用于提取非洲地区使用的交通标志。该数据集包含来自所有类别的 76 个类,例如 监管、警告、指南和信息标志。该数据集总共包含 19,346 张图像和每个类别至少 200 个实例。
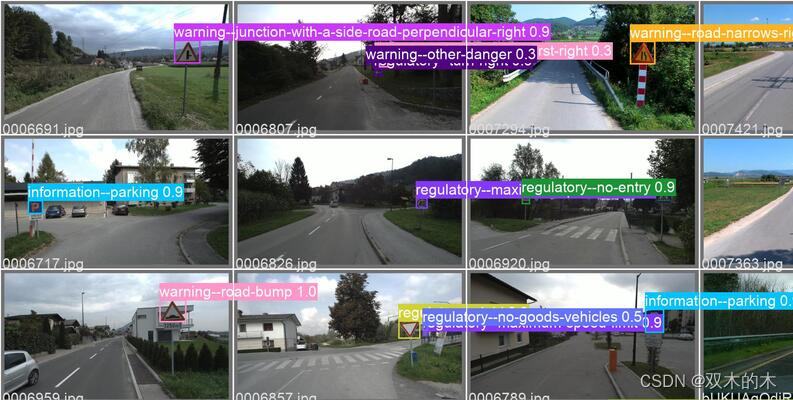
十二、卫星图像
水体卫星图像的图像
数据集下载地址:http://suo.nz/2ksvWY
Sentinel-2 卫星拍摄的水体图像集。每张图片都带有一个黑白mask,其中白色代表水,黑色代表除水之外的其他东西。这些掩模是通过计算 NWDI(归一化水差指数)生成的,该指数经常用于检测和测量卫星图像中的植被,但使用更大的阈值来检测水体。

城市航拍图像分割数据集
数据集下载地址:http://suo.nz/2cWiSh
此数据集包含用于检查和准备航空影像分割数据集的脚本。该数据集包含一组不同的卫星图像,这些图像用目标城市的建筑物、道路和背景标签进行了注释。

游泳池和汽车卫星图像检测
数据集下载地址:http://suo.nz/3b5ZtQ

人工月球景观数据集
数据集下载地址:http://suo.nz/33zMp9
由于月球图像的稀缺性和缺乏注释,通常很难对其进行任何类型的机器学习实验。该数据集的目标是为公众提供人造而逼真的月球景观样本,可用于训练岩石检测算法。这些经过训练的算法可以在实际的月球图片或其他岩石地形图片上进行测试。该数据集目前包含 9,766 个岩石月球景观的真实渲染图,以及它们的分段等价物(3 类是天空、较小的岩石和较大的岩石)。还提供了所有较大岩石和经过处理、清理后的地面实况图像的边界框表。

马萨诸塞州道路数据集
数据集下载地址:http://suo.nz/32Pa9O
马萨诸塞州道路数据集由1171幅马萨诸塞州的航空图像组成。与建筑数据一样,每个图像的大小为1500×1500像素,占地2.25平方公里。

十三、工业检测
MIO-TCD车辆分类数据集
数据集下载链接:http://suo.nz/2wf2fh
该数据集包含总共 786,702 张图像,其中分类数据集中有 648,959 张图像,定位数据集中有 137,743 张图像,这些图像是在一天中的不同时间和一年中的不同时期由部署在加拿大和美国的数千个交通摄像头采集的。这些图像已被选中以涵盖广泛的挑战,并且代表了当今在城市交通场景中捕获的典型视觉数据。每个运动物体都经过近200人的仔细识别,可以对各种算法进行定量比较和排名。该数据集旨在提供严格的基准测试工具,用于训练和测试现有算法和新算法,用于交通场景中移动车辆的分类和定位。数据集分为两部分:“分类挑战数据集”和“定位挑战数据集”。

时尚产品图片数据集
数据集下载链接:http://suo.nz/2DKP2W
每个产品都由类似42431的ID标识。可以在styles.csv中找到所有产品的映射,从images/42431.jpg获取该产品的图像,并从styles/42431.json获取完整的元数据。

水稻病害数据集
数据集下载链接:http://suo.nz/2KB4Fj
用于检测不同的水稻病害,2K+ 图像主要涵盖 3 种疾病——褐斑病、Hispa 和叶瘟病。

火灾检测数据集
数据集下载链接:http://suo.nz/2S7hIo
检测图像中是否存在火灾,含有来自不同场景的 500 多张图像。

天气和日光类型分类数据集
数据集下载链接:http://suo.nz/2ZziE3
用于图像分类的多类天气数据集 (MWD) 是题为“使用异构集成方法从静态图像进行多类天气识别”的研究论文,中使用的一个有价值的数据集。该数据集通过提取用于识别不同天气条件的各种特征,为室外天气分析提供了一个平台。1000 多张图像,具有 5 种以上的不同类别——日出、雨天、多云、傍晚、夜晚等。

天池铝型材表面缺陷数据集
数据集下载地址:http://m6z.cn/61EksR
大赛数据集里有1万份来自实际生产中有瑕疵的铝型材监测影像数据,每个影像包含一个或多种瑕疵。供机器学习的样图会明确标识影像中所包含的瑕疵类型。

Kylberg 纹理数据集
数据集下载地址:http://m6z.cn/61Ekw5
在布匹的实际生产过程中,由于各方面因素的影响,会产生污渍、破洞、毛粒等瑕疵,为保证产品质量,需要对布匹进行瑕疵检测。布匹疵点检验是纺织行业生产和质量管理的重要环节,目前人工检测易受主观因素影响,缺乏一致性;并且检测人员在强光下长时间工作对视力影响极大。由于布匹疵点种类繁多、形态变化多样、观察识别难道大,导致布匹疵点智能检测是困扰行业多年的技术瓶颈。本数据涵盖了纺织业中布匹的各类重要瑕疵,每张图片含一个或多种瑕疵。数据包括包括素色布和花色布两类,其中,素色布数据约8000张;花色布数据约12000张。
东北大学带钢表面缺陷数据集
数据集下载地址:http://m6z.cn/5U87us
数据集收集了夹杂、划痕、压入氧化皮、裂纹、麻点和斑块6种缺陷,每种缺陷300张,图像尺寸为200×200。数据集包括分类和目标检测两部分,不过目标检测的标注中有少量错误,需要注意。

Severstal 带钢缺陷数据集
数据集下载地址:http://m6z.cn/61EkBp
该数据集中提供了四种类型的带钢表面缺陷。训练集共有12568张,测试集5506张。图像尺寸为1600×256。
UCI 带钢缺陷数据集
数据集下载地址:http://m6z.cn/61EkUh
该数据集包含了7种带钢缺陷类型。这个数据集不是图像数据,而是带钢缺陷的28种特征数据,可用于机器学习项目。钢板故障的7种类型:装饰、Z_划痕、K_划痕、污渍、肮脏、颠簸、其他故障。
DAGM 2007数据集
数据集下载地址:http://m6z.cn/5F5eQV
该数据集主要针对纹理背景上的杂项缺陷,为较弱监督的训练数据。包含十个数据集,前六个为训练数据集,后四个为测试数据集。每个数据集均包含以灰度8位PNG格式保存的1000个“无缺陷”图像和150个“有缺陷”图像,每个数据集由不同的纹理模型和缺陷模型生成。“无缺陷”图像显示的背景纹理没有缺陷,“无缺陷”图像的背景纹理上恰好有一个标记的缺陷。所有数据集已随机分为大小相等的训练和测试子数据集。弱标签以椭圆形表示,大致表示缺陷区域。
磁瓦缺陷数据集
数据集下载地址:http://m6z.cn/5F5eSd
中国科学院自动所一个课题组收集的数据集,是“Saliency of magnetic tile surface defects”这篇论文的数据集。收集了6种常见磁瓦缺陷的图像,并做了语义分割的标注。
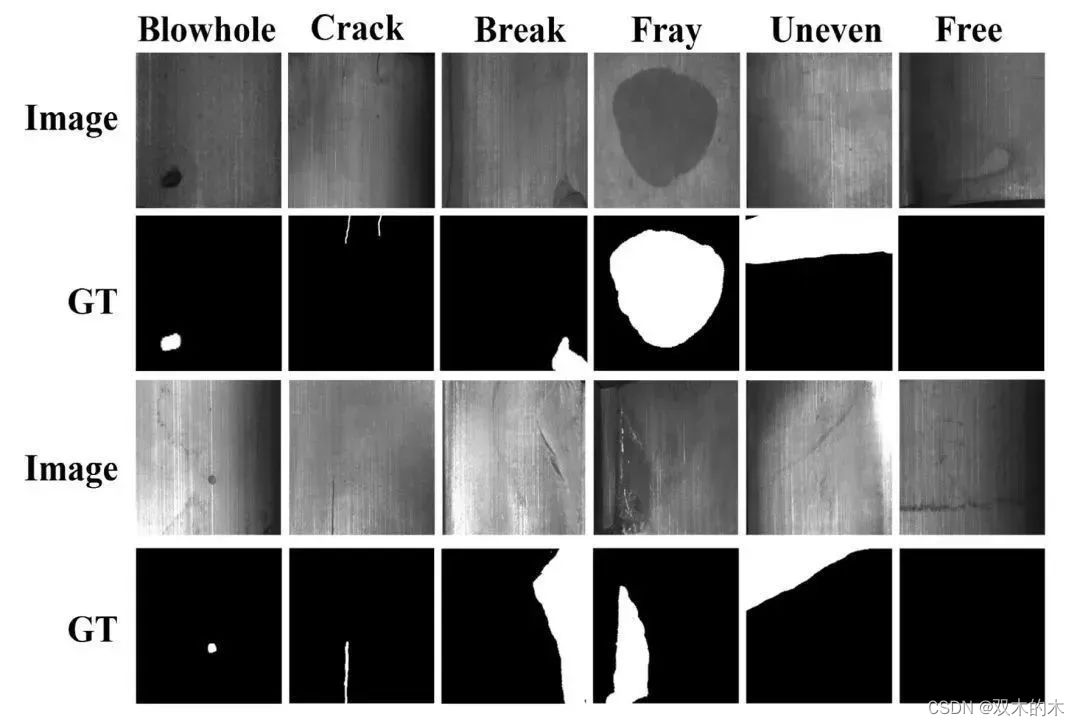
RSDDs铁轨表面缺陷数据集
数据集下载地址:http://m6z.cn/61EkKL
RSDDs数据集包含两种类型的数据集:第一种是从快车道捕获的I型RSDDs数据集,其中包含67个具有挑战性的图像。第二个是从普通/重型运输轨道捕获的II型RSDDs数据集,其中包含128个具有挑战性的图像。
两个数据集的每幅图像至少包含一个缺陷,并且背景复杂且噪声很大。
RSDDs数据集中的这些缺陷已由一些专业的人类观察员在轨道表面检查领域进行了标记。
KTH-TIPS 纹理图像数据集
数据集下载地址:http://m6z.cn/61EkMH
KTH-TIPS 是一个纹理图像数据集,在不同的光照、角度和尺度下拍摄的不同材质表面纹理图片。类型包括砂纸、铝箔、发泡胶、海绵、灯芯绒、亚麻、棉、黑面包、橙皮和饼干共10类。

印刷电路板(PCB)瑕疵数据集
数据集下载地址:http://m6z.cn/5U87Ji
这是一个公共的合成PCB数据集,由北京大学发布,其中包含1386张图像以及6种缺陷(缺失孔,鼠咬坏,开路,短路,杂散,伪铜),用于检测,分类和配准任务。

十三、安全帽、头盔、反光衣分类识别
安全帽佩戴数据集
数据集下载链接:http://suo.nz/2M6i3r
该数据集中有 5000 张图像和 5000 个注释。原始数据集包含三个类别(人、头部和头盔),共有 2501 个标签。此外,原始数据集没有完全标记。我们在结果中的数据集上添加了三个新标签,新标签由六个类别(头盔、带头盔的头部、带头盔的人、头部、不带头盔的人和面部)组成,共有 75578 个标签。

SHWD安全帽佩戴检测数据集
数据集下载链接:http://suo.nz/2TCswQ
SHWD 提供了用于安全头盔佩戴和人头检测的数据集。它包括7581张图像,其中9044个人体安全头盔佩戴对象(正面)和111514个正常头部对象(未佩戴或负面)。

摩托车头盔检测数据集
数据集下载链接:http://suo.nz/318FBx
HELMET 数据集包含 2016 年在缅甸 12 个观测点录制的 910 个摩托车交通视频剪辑。每个视频剪辑的持续时间为 10 秒,以 10fps 的帧速率和 1920x1080 的分辨率记录。该数据集包含 10,006 辆摩托车,超过了现有数据集中可用的摩托车数量。数据集中的 91,000 个带注释帧中的每辆摩托车都用边界框进行注释,并且提供每辆摩托车的骑手人数以及特定位置的头盔使用数据。

安全帽和安全背心(反光衣)图像数据集
数据集下载链接:http://suo.nz/38ESGe
数据集中只有一个文件夹。
文件名以 pos 开头:图像包含安全帽或安全背心。文件名以 neg 开头:图像既不包含安全帽也不包含安全背心。

YOLO格式的头盔/头部检测数据集
数据集下载链接:http://suo.nz/2pChfA

十三、图像分割
天空图像数据集
数据集下载链接:http://suo.nz/1ykW0L
Sky 数据集包含 60 张带有地面实况的图像,用于天空分割。它基于 R. Fergus 15/02/03 的 Caltech Airplanes Side 数据集。选择数据集中包含天空区域的那些图像,并为它们创建地面实况。原始数据集图像名称保持不变。

CO-SKEL数据集
数据集下载链接:http://suo.nz/1FR95s
该数据集由分类骨架和分割掩码组成,用于评估协同骨架化方法。

CAD-120 affordance数据集
数据集下载链接:http://suo.nz/1NnlU1
包含9916个对象实例的3090幅图像的逐像素注释。

Intrinsic Images in the Wild
数据集下载链接:http://suo.nz/1UTwnq
“Intrinsic Images in the Wild”,这是一个用于评估室内场景固有图像分解的大规模公共数据集。作者们通过数百万个众包注释创建了这个基准,这些注释对每个场景中的点对的材料属性进行了相对比较。

具有细长部分的鸟类昆虫数据集
数据集下载链接:http://suo.nz/22pJs7
这些数据库由 280 张具有ground truth的鸟类和昆虫的公共图像组成。

多品种果花检测数据集
数据集下载链接:http://suo.nz/29RKnM
该数据集包含四组花卉图像,来自三种不同的树种:苹果、桃和梨,以及随附的地面实况图像。

OpenSurfaces数据集
数据集下载链接:http://suo.nz/1bI3Md
包含从消费者内部照片中分割出来的数千个表面示例,并使用材料参数(反射率、材料名称)、纹理信息(表面法线、校正纹理)进行注释和上下文信息(场景类别和对象名称)。

阴影检测/纹理分析数据集
数据集下载链接:http://suo.nz/1iyjoA
一个用于阴影检测和纹理分析的简单计算机视觉数据集,专门用于帮助测试移动机器人的阴影检测算法(和纹理分割算法)——即使用 活动(移动)相机进行阴影检测。
该数据集专注于纹理分析,因此每个图像序列都包含在许多不同纹理表面前移动的阴影。

十四、人群计数、行人检测
SCUT FIR行人检测数据集
数据集下载地址:https://sourl.cn/4VK3Bn
SCUT FIR Pedestrian Datasets 是一个大型远红外行人检测数据集。它由大约 11 小时长的图像序列( 帧)组成,速度为 25 Hz,以低于 80 km/h 的速度在不同的交通场景中行驶。图像序列来自中国广州市中心、郊区、高速公路和校园 4 种场景下的 11 个路段。该数据集注释了 211,011 帧,总共 477,907 个边界框,围绕 7,659 个独特的行人。

JHU-CROWD++
数据集下载地址:https://sourl.cn/mgxHEY
包含 4,372 张图像和 151 万条注释的综合数据集。与现有数据集相比,所提出的数据集是在各种不同的场景和环境条件下收集的。此外,该数据集提供了相对丰富的注释集,如点、近似边界框、模糊级别等。

CIHP人体解析数据集
数据集下载地址:https://sourl.cn/W3Tm2J
Crowd Instance-level Human Parsing (CIHP) 数据集包含 38,280 张多人图像,这些图像具有精细的注释、高外观可变性和复杂性。该数据集可用于人体部分分割任务。

AHU-Crowd人群数据集
数据集下载地址:https://sourl.cn/XFJDCh
人群数据集是从各种来源获得的,例如 UCF 和数据驱动的人群数据集,以评估所提出的框架。序列多样,代表了朝圣、车站、马拉松、集会和体育场等各种场景中公共空间的密集人群。此外,这些序列具有不同的视野、分辨率,并表现出多种运动行为,涵盖了明显和微妙的不稳定性。

AudioVisual 人群计数
数据集下载地址:https://sourl.cn/wfd7wD
一个用于人群计数的新数据集,该数据集由中国不同位置的大约 2000 个带注释的图像令牌组成,每个图像对应一个 1 秒的音频剪辑和一个密度图。图像处于不同的照明条件下。

UCF-CC-50
数据集下载地址:http://c.nxw.so/9LYoK
该数据集包含极其密集人群的图像。图像主要是从 FLICKR 收集的。

北京BRT数据集
数据集下载地址:http://c.nxw.so/c1PV9
该数据集包含 1,280 张图像和 16,795 个标记的行人,常常用于人群分析。该数据集使用 720 张图像进行训练,使用 560 张图像进行测试。
-
名为 frame 的文件夹包含人群图像。
-
名为 ground_truth 的文件夹包含ground_truth。例如,'1-20170325134657.jpg'对应于'1-20170325134657.mat',以及这张图片中第i个人的真实位置,其中每一行是位置[x,y]

十五、图像去噪
PolyU数据集
数据集下载地址:https://sourl.cn/rMsdE8
大多数以前的图像去噪方法都集中在加性高斯白噪声(AWGN)上。然而,随着计算机视觉技术的进步,现实世界中的噪声图像去噪问题也随之而来。为了在实现并发真实世界图像去噪数据集的同时促进对该问题的研究,作者们构建了一个新的基准数据集,其中包含不同自然场景的综合真实世界噪声图像。这些图像是由不同的相机在不同的相机设置下拍摄的。

FMD(荧光显微镜去噪)数据集
数据集下载地址:https://sourl.cn/Wyqrui
荧光显微镜使现代生物学取得了巨大的发展。由于其固有的微弱信号,荧光显微镜不仅比摄影噪声大得多,而且还呈现出泊松-高斯噪声,其中泊松噪声或散粒噪声是主要的噪声源。为了获得干净的荧光显微镜图像,非常需要有专门设计用于对荧光显微镜图像进行降噪的有效降噪算法和数据集。虽然存在这样的算法,但没有这样的数据集可用。在本文中,我们通过构建专用于泊松-高斯去噪的数据集 - 荧光显微镜去噪 (FMD) 数据集来填补这一空白。该数据集由 12,000 个真实荧光显微镜图像组成,这些图像使用商业共焦、双光子、宽视野显微镜和代表性生物样本,如细胞、斑马鱼和小鼠脑组织。

SIDD智能手机图像去噪数据集
数据集下载地址:https://sourl.cn/jdpJZ6
该数据集包含以下智能手机在不同光照条件下拍摄的 160 对噪声/真实图像:
GP: Google Pixel
IP: iPhone 7
S6: Samsung Galaxy S6
Edge N6: Motorola Nexus 6
G4: LG G4

SIDD-small数据集
数据集下载地址:https://sourl.cn/kaYGxd
一个小型版本的数据集,它由代表 160 个场景实例的160 个图像对(噪声和ground-truth)组成。

Super Resolution Benchmarks
数据集下载地址:https://sourl.cn/Bp6QZs
来自于AIM 2022 压缩图像和视频超分辨率挑战赛”中的前 5 名解决方案工作:Swin2SR: SwinV2 Transformer for Compressed Image Super-Resolution and Restoration

十六、RGB-T
HFUT-Lytro数据集
数据集下载地址:https://sourl.cn/xGKqau
一个光场显著性分析基准数据集,名为HFUT Lytro,由255个光场组成,每个光场图像生成的图像范围从53到64个,其中跨越了多个显著性检测挑战,如遮挡、杂乱背景和外观变化。

DUTLF-V2
数据集下载地址:http://u3v.cn/65oL0y
由于具有强大的三维信息捕捉能力,光场数据为显著性检测算法提供了更为有力的支持。但算法的能力取决于数据集构建的全面性、有效性、规模化和多样性,同时也取决于灵活高效的模型设计。为了促进这一领域的发展,来自大连理工的研究人员构建了大规模的多功能数据集,其中包含了102类目标、共4202个样本,可以有效支持基于RGB、RGB-D和光场数据的显著性检测算法。

Lytro Illum
数据集下载地址:http://u3v.cn/6kr8yE
我们收集了 640 个在大小、纹理、背景杂波和照明等方面具有显着变化的光场。我们生成微透镜图像阵列和中心观察图像,并生成相应的地面实况图。

DUTLF-MV
数据集下载地址:http://u3v.cn/6lbl3d
DUTLF-MV 是 DUTLF 的一部分,由 1580 个真实场景组成。该数据集的每个场景都由全焦点图像、多视图图像和相应的地面实况组成。

光场 (Lytro) 和立体声 (Project Tango) 数据集
数据集下载地址:http://u3v.cn/6s1AFA
数据来自 Lytro Illum,捕获为 40MP 图像,然后转换为 5MP RGB+D 图像。提供了几个测试图像所需的所有数据。第二个数据集来自 Lenovo Phab2(Project Tango),它利用双图像传感器重新创建大型 3D 结构的点云。这些以 .ply 和 .obj 数据集的形式提供。

RGB-D 人群数据集
数据集下载地址:http://u3v.cn/5tNHTn
该数据集包含在大学礼堂中从三个垂直安装的 Kinect 传感器获取的 3000 多个 RGB-D 帧。数据主要包含从不同方向和不同遮挡程度看到的直立行走和站立的人。

ReDWeb-S
数据集下载地址:http://u3v.cn/5BjUY4
它共有 3179 张图像,具有各种真实世界场景和高质量的深度图。我们将数据集分成包含 2179 个 RGB-D 图像对的训练集和包含剩余 1000 个图像对的测试集。

NLPR
数据集下载地址:http://u3v.cn/5IQ82L
NJU2K是一个包含 1,985 个图像对的大型 RGB-D 数据集。立体图像是从互联网和 3D 电影中收集的,而照片是由富士 W3 相机拍摄的。

十七、图像去雾
D-HAZY
下载地址:http://m6z.cn/5IBatp
D-HAZY建立在Middelbury 和NYU深度数据集上,这些数据集提供各种场景的图像及其相应的深度图。包含1400多对图像的数据集,其中包括同一场景的地面真实参考图像和模糊图像。

RESIDE
下载地址:http://m6z.cn/5IBauH
RESIDE数据集包括合成和真实世界的模糊图像,称为REalistic Single Image Dehazing,RESIDE突出显示了各种数据源和图像内容,并分为五个子集,每个子集用于不同的训练或评估目的。提供了各种各样的去雾算法评估标准,从完整参考度量,无参考度量,到主观评估和任务驱动评估。

Middlebury Stereo双目立体匹配测试数据集
下载地址:http://m6z.cn/5Prq8G
这24个数据集是由潘广汉、孙天生、托比·威德和丹尼尔·沙尔斯坦在2019-2021期间创建的。数据集包括11个场景,在许多不同的照明条件和曝光(包括移动设备的闪光灯和“手电筒”照明)下,从1-3个不同的观看方向成像。

NH-HAZE
下载地址:http://m6z.cn/5tyN0D
这是一个非均匀的真实数据集,具有成对的真实雾度和相应的无雾度图像。这是第一个非齐次图像去模糊数据集,包含55个室外场景。在场景中引入了非均匀雾,使用专业雾发生器模拟雾场景的真实条件。

DENSE-HAZE
下载地址:http://m6z.cn/5tyMZP
单图像去叠是一个不适定问题,最近引起了重要关注。尽管在过去几年中,人们对去雾的兴趣显著增加,但由于缺乏真实的雾度和相应的无雾度参考图像对,去雾方法的验证在很大程度上仍然不令人满意。为了解决这一局限性,我们引入了一种新的去雾数据集稠密雾。《DENSE-HAZE》以浓密均匀的朦胧场景为特征,包含33对真实的朦胧图像和各种室外场景的相应无霾图像。通过引入由专业雾霾机器生成的真实雾霾来记录雾霾场景。朦胧和无朦胧的对应场景包含在相同照明参数下捕获的相同视觉内容。

REVIDE视频去雾数据集
下载地址:http://m6z.cn/6bVqYX
现有的深度学习去雾方法多采用单帧去雾数据集进行训练和评测,从而使得去雾网络只能利用当前有雾图像的信息恢复清晰图像。另外一方面,理想中的视频去雾算法却可以使用相邻的有雾帧来获取更多的时空冗余信息,从而得到更好的去雾效果,但由于视频去雾数据集的缺失,视频去雾算法鲜有研究。为了实现视频去雾算法的监督训练,我们首次提出了一组真实的视频去雾数据集(REVIDE)。使用精心设计的视频采集系统,成功地在同一场景进行两次采集,从而同时记录下真实世界中成对且完美对齐的有雾和无雾视频。

十七、小目标检测
AI-TOD航空图像数据集
数据集下载地址:http://m6z.cn/5MjlYk
AI-TOD 在 28,036 张航拍图像中包含 8 个类别的 700,621 个对象实例。与现有航拍图像中的目标检测数据集相比,AI-TOD 中目标的平均大小约为 12.8 像素,远小于其他数据集。

iSAID航空图像大规模数据集
数据集下载地址:http://m6z.cn/6nUrYe
现有的 Earth Vision 数据集要么适用于语义分割,要么适用于对象检测。iSAID 是第一个用于航空图像实例分割的基准数据集。这个大规模和密集注释的数据集包含 2,806 张高分辨率图像的 15 个类别的 655,451 个对象实例。iSAID 的显着特征如下:(a) 大量具有高空间分辨率的图像,(b) 十五个重要且常见的类别,(c) 每个类别的大量实例,(d) 每个类别的大量标记实例图像,这可能有助于学习上下文信息,(e) 巨大的对象尺度变化,通常在同一图像内包含小、中和大对象,(f) 图像内具有不同方向的对象的不平衡和不均匀分布,描绘真实-生活空中条件,(g)几个小尺寸物体,外观模糊,只能通过上下文推理来解决,(h)由专业注释者执行的精确实例级注释,由符合良好规范的专家注释者交叉检查和验证定义的指导方针。

TinyPerson数据集
数据集下载地址:http://m6z.cn/6vqF3T
在 TinyPerson 中有 1610 个标记图像和 759 个未标记图像(两者主要来自同一视频集),总共有 72651 个注释。

Deepscores 数据集
数据集下载地址:http://m6z.cn/5xgYdY
DeepScores 数据集的目标是推进小物体识别的最新技术,并将物体识别问题置于场景理解的背景下。DeepScores 包含高质量的乐谱图像,分为 300 0 000 张书面音乐,其中包含不同形状和大小的符号。拥有近一亿个小对象,这使得我们的数据集不仅独一无二,而且是最大的公共数据集。DeepScores 带有用于对象分类、检测和语义分割的基本事实。因此,DeepScores 总体上对计算机视觉提出了相关挑战,超出了光学音乐识别 (OMR) 研究的范围。

密集行人检测数据集
数据集下载地址:http://m6z.cn/6nUs1C
WiderPerson 数据集是野外行人检测基准数据集,其图像选自广泛的场景,不再局限于交通场景。我们选择了 13,382 张图像并标记了大约 400K 带有各种遮挡的注释。我们随机选择 8000/1000/4382 图像作为训练、验证和测试子集。与 CityPersons 和 WIDER FACE 数据集类似,我们不发布测试图像的边界框基本事实。用户需要提交最终的预测文件,我们将进行评估。

加州理工学院行人检测数据集
数据集下载地址:http://m6z.cn/5N3Yk7
加州理工学院行人数据集由大约 10 小时的 640x480 30Hz 视频组成,该视频取自在城市环境中通过常规交通行驶的车辆。注释了大约 250,000 帧(在 137 个大约分钟长的片段中),总共 350,000 个边界框和 2300 个独特的行人。注释包括边界框和详细的遮挡标签之间的时间对应关系。

NWPU VHR-10卫星图像数据集
数据集下载地址:http://m6z.cn/5UAbEW
NWPU VHR-10 Dataset 是一个用于空间物体检测的 10 级地理遥感数据集,其拥有 650 张包含目标的图像和 150 张背景图像,共计 800 张,目标种类包括飞机、舰船、油罐、棒球场、网球场、篮球场、田径场、港口、桥梁和汽车共计 10 个类别。
该数据集由西北工业大学于 2014 年发布,相关论文有《Multi-class geospatial object detection and geographic imageclassification based on collection of part detectors》、《A survey on objectdetection in optical remote sensing images》和《Learningrotation-invariant convolutional neural networks for object detection in VHRoptical remote sensing images》。

Inria 航空影像数据集
数据集下载地址:http://m6z.cn/6nUs6s
Inria 航空影像标注解决了遥感中的一个核心主题:航空影像的自动像素级标注(论文链接)。
数据集特点:
-
覆盖面积 810 平方公里(405 平方公里用于训练,405 平方公里用于测试)
-
空间分辨率为 0.3 m 的航空正射校正彩色图像
-
两个语义类的地面实况数据:构建和非构建(仅针对训练子集公开披露)
-
这些图像涵盖了不同的城市住区,从人口稠密的地区(例如,旧金山的金融区)到高山城镇(例如,奥地利蒂罗尔的 Lienz)。

RSOD遥感图像数据集
数据集下载地址:http://m6z.cn/5EN96H
它是一个开放的遥感图像目标检测数据集。数据集包括飞机、油箱、游乐场和立交桥。此数据集的格式为PASCAL VOC。数据集包括4个文件,每个文件用于一种对象。
-
飞机数据集,446张图片中有4993架飞机。
-
操场,189张图片中的191个操场。
-
天桥,176张图片中的180座天桥。
-
油箱,165张图片中的1586个油箱。
小目标检测数据集
数据集下载地址:http://m6z.cn/616t6R
从Internet(例如YouTube或Google)上的图像/视频收集的四个小物体数据集,包括4种类型的图像,可用于小物体目标检测的研究。
数据集包含四类:
-
fly:飞行数据集,包含600个视频帧,平均每帧86±39个物体(648×72 @ 30 fps)。32张图像用于训练(1:6:187),50张图像用于测试(301:6:600)。
-
honeybee:蜜蜂数据集,包含118张图像,每张图像平均有28±6个蜜蜂(640×480)。数据集被平均分配用于训练和测试集。仅前32张图像用于训练。
-
seagull:海鸥数据集,包含三个高分辨率图像(624×964),每个图像平均有866±107个海鸥。第一张图片用于训练,其余图片用于测试。
-
fish:鱼数据集,包含387帧视频数据,平均每帧56±9条鱼(300×410 @ 30 fps)。32张图像进行训练(1:3:94),65张图像进行测试(193:3:387)。

十八、目标检测
COCO2017数据集
COCO2017是2017年发布的COCO数据集的一个版本,主要用于COCO在2017年后持有的物体检测任务、关键点检测任务和全景分割任务。

火焰和烟雾图像数据集
数据集链接:http://m6z.cn/6fzn0f
该数据集由早期火灾和烟雾的图像数据集组成。数据集由在真实场景中使用手机拍摄的早期火灾和烟雾图像组成。大约有7000张图像数据。图像是在各种照明条件(室内和室外场景)、天气等条件下拍摄的。该数据集非常适合早期火灾和烟雾探测。数据集可用于火灾和烟雾识别、检测、早期火灾和烟雾、异常检测等。数据集还包括典型的家庭场景,如垃圾焚烧、纸塑焚烧、田间作物焚烧、家庭烹饪等。本文仅含100张左右。

DOTA航拍图像数据集
数据集链接:http://m6z.cn/6vIKlJ
DOTA是用于航空图像中目标检测的大型数据集。它可以用于开发和评估航空图像中的目标探测器。这些图像是从不同的传感器和平台收集的。每个图像的大小在800×800到20000×20000像素之间,包含显示各种比例、方向和形状的对象。DOTA图像中的实例由航空图像解释专家通过任意(8 d.o.f.)四边形进行注释。

AITEX数据集
数据集链接:http://m6z.cn/5DdJL1
该数据库由七个不同织物结构的245张4096 x 256像素图像组成。数据库中有140个无缺陷图像,每种类型的织物20个,除此之外,有105幅纺织行业中常见的不同类型的织物缺陷(12种缺陷)图像。图像的大尺寸允许用户使用不同的窗口尺寸,从而增加了样本数量。

T-LESS数据集
数据集链接:http://m6z.cn/5wnucm
该数据集采集的目标为工业应用、纹理很少的目标,同时缺乏区别性的颜色,且目标具有对称性和互相关性,数据集由三个同步的传感器获得,一个结构光传感器,一个RGBD sensor,一个高分辨率RGBsensor,从每个传感器分别获得了3.9w训练集和1w测试集,此外为每个目标创建了2个3D model,一个是CAD手工制作的另一个是半自动重建的。训练集图片的背景大多是黑色的,而测试集的图片背景很多变,会包含不同光照、遮挡等等变换(之所以这么做作者说是为了使任务更具有挑战性)。
同时作者解释了本数据集的优势在于:1.大量跟工业相关的目标;2.训练集都是在可控的环境下抓取的;3.测试集有大量变换的视角;4.图片是由同步和校准的sensor抓取的;5.准确的6D pose标签;6.每个目标有两种3D模型;

H2O 行人交互检测数据集
数据集链接:http://m6z.cn/6fzmQf
H2O由V-COCO数据集中的10301张图像组成,其中添加了3635张图像,这些图像主要包含人与人之间的互动。所有的H2O图像都用一种新的动词分类法进行了注释,包括人与物和人与人之间的互动。该分类法由51个动词组成,分为5类:
-
描述主语一般姿势的动词
-
与主语移动方式有关的动词
-
与宾语互动的动词
-
描述人与人之间互动的动词
-
涉及力量或暴力的互动动词

SpotGarbage垃圾识别数据集
数据集链接:http://m6z.cn/5ZMmRG
图像中的垃圾(GINI)数据集是SpotGarbage引入的一个数据集,包含2561张图像,956张图像包含垃圾,其余的是在各种视觉属性方面与垃圾非常相似的非垃圾图像。

NAO自然界对抗样本数据集
数据集链接:http://m6z.cn/5KJWJA
NAO包含7934张图像和9943个对象,这些图像未经修改,代表了真实世界的场景,但会导致最先进的检测模型以高置信度错误分类。与标准MSCOCO验证集相比,在NAO上评估时,EfficientDet-D7的平均精度(mAP)下降了74.5%。

Labelme 图像数据集
数据集链接:http://m6z.cn/5Sg9NX
Labelme Dataset 是用于目标识别的图像数据集,涵盖 1000 多个完全注释和 2000 个部分注释的图像,其中部分注释图像可以被用于训练标记算法 ,测试集拥有来自于世界不同地方拍摄的图像,这可以保证图片在续联和测试之间会有较大的差异。该数据集由麻省理工学院 –计算机科学和人工智能实验室于 2007 年发布,相关论文有《LabelMe: a database and web-based tool for image annotation》。

印度车辆数据集
数据集链接:http://m6z.cn/6uxAIx
该数据集包括小众印度车辆的图像,如Autorikshaw、Tempo、卡车等。该数据集由用于分类和目标检测的小众印度车辆图像组成。据观察,这些小众车辆(如autorickshaw、tempo、trucks等)上几乎没有可用的数据集。这些图像是在白天、晚上和晚上的不同天气条件下拍摄的。该数据集具有各种各样的照明、距离、视点等变化。该数据集代表了一组非常具有挑战性的利基类车辆图像。该数据集可用于驾驶员辅助系统、自动驾驶等的图像识别和目标检测。

Seeing 3D chairs椅子检测模型
数据集链接:http://m6z.cn/5DdK0v
椅子数据集包含大约1000个不同三维椅子模型的渲染图像。

SUN09场景理解数据集
数据集链接:http://m6z.cn/60wX8r
SUN09数据集包含12000个带注释的图像,其中包含200多个对象类别。它由自然、室内和室外图像组成。每个图像平均包含7个不同的注释对象,每个对象的平均占用率为图像大小的5%。对象类别的频率遵循幂律分布。发布者使用 397 个采样良好的类别进行场景识别,并以此搭配最先进的算法建立新的性能界限。
该数据集由普林斯顿视觉与机器人实验室于 2014 年发布,相关论文有《SUN Database: Large-scale Scene Recognition from Abbey to Zoo》、《SUN Database: Exploring a Large Collection of Scene Categories》。
Unsplash图片检索数据集
数据集链接:http://m6z.cn/5wnuoM
使用迄今为止公开共享的全球最大的开放检索信息数据集。Unsplash数据集由250000多名贡献摄影师创建,并包含了数十亿次照片搜索的信息和对应的照片信息。由于Unsplash数据集中包含广泛的意图和语义,它为研究和学习提供了新的机会。

HICO-DET人物交互检测数据集
数据集链接:http://m6z.cn/5DdK6D
HICO-DET是一个用于检测图像中人-物交互(HOI)的数据集。它包含47776幅图像(列车组38118幅,测试组9658幅),600个HOI类别,由80个宾语类别和117个动词类别构成。HICO-DET提供了超过150k个带注释的人类对象对。V-COCO提供了10346张图像(2533张用于培训,2867张用于验证,4946张用于测试)和16199人的实例。

上海科技大学人群统计数据集
数据集链接:http://m6z.cn/5Sgafn
上海科技数据集是一个大规模的人群统计数据集。它由1198张带注释的群组图像组成。数据集分为两部分,A部分包含482张图像,B部分包含716张图像。A部分分为训练和测试子集,分别由300和182张图像组成。B部分分为400和316张图像组成的序列和测试子集。群组图像中的每个人都有一个靠近头部中心的点进行注释。总的来说,该数据集由33065名带注释的人组成。A部分的图像是从互联网上收集的,而B部分的图像是在上海繁忙的街道上收集的。

生活垃圾数据集
数据集链接:http://m6z.cn/6n5Adu
大约9000多张独特的图片。该数据集由印度国内常见垃圾对象的图像组成。图像是在各种照明条件、天气、室内和室外条件下拍摄的。该数据集可用于制作垃圾/垃圾检测模型、环保替代建议、碳足迹生成等。

RMFD口罩遮挡人脸数据集
数据集下载地址:http://m6z.cn/61z9Fv
当前大多数高级人脸识别方法都是基于深度学习而设计的,深度学习取决于大量人脸样本。但是,目前尚没有公开可用的口罩遮挡人脸识别数据集。为此,这项工作提出了三种类型的口罩遮挡人脸数据集,包括口罩遮挡人脸检测数据集(MFDD),真实口罩遮挡人脸识别数据集(RMFRD)和模拟口罩遮挡人脸识别数据集(SMFRD)。基于这些数据集,可以开发口罩遮挡人脸的各种应用。本项目开发的多粒度口罩遮挡人脸识别模型可达到95%的准确性,超过了行业报告的结果。

GTSRB德国交通标志数据集
数据集下载地址:http://m6z.cn/5wJJLA
德国交通标志基准测试是在 2011 年国际神经网络联合会议 (IJCNN) 上举办的多类单图像分类挑战赛。我们诚邀相关领域的研究人员参与:该比赛旨在参与者无需特殊领域知识。我们的基准测试具有以下属性:
-
单图像、多类分类问题
-
40多个分类
-
总共超过 50,000 张图片
-
逼真的大型数据库

VOC2005车辆数据集
数据集下载地址:http://m6z.cn/5U2X4u
该数据集中含有自行车、摩托车、汽车、货车的图像数据,可用于CNN模型以实现车辆识别和车辆分类,其中自行车、摩托车、汽车数据来自2005 PASCAL视觉类挑战赛(VOC2005)所使用的数据的筛选处理结果,货车图片来自网络收集,后期通过筛选处理得到。在本数据中,训练数据集与测试数据集占比约为5:1。

Winegrape检测数据集
数据集下载地址:http://m6z.cn/5TikF9
WGISD(Wine Grape Instance Segmentation Dataset)是为了提供图像和注释来研究对象检测和实例分割,用于葡萄栽培中基于图像的监测和现场机器人技术。它提供了来自五种不同葡萄品种的实地实例。这些实例显示了葡萄姿势、光照和焦点的变化,包括遗传和物候变化,如形状、颜色和紧实度。可能的用途包括放宽实例分割问题:分类(图像中是否有葡萄?)、语义分割(图像中的“葡萄像素”是什么?)、对象检测(图像中的葡萄在哪里?)、和计数(每个簇有多少浆果?)。
全球小麦检测数据集
数据集下载地址:http://m6z.cn/5wJK64
检测小麦穗是一项重要任务,可以估计相关性状,包括穗种群密度和穗特征,如卫生状况、大小、成熟阶段和芒的存在。本数据集包含 4,700 张高分辨率 RGB 图像和 190,000 个标记的小麦头,这些小麦头采集自世界各地不同生长阶段的不同基因型的多个国家。

Linkopings交通标志数据集
数据集下载地址:http://m6z.cn/68ldS0
通过记录超过 350 公里的瑞典高速公路和城市道路的序列,创建了一个数据集。一个 1.3 兆像素的彩色摄像机,一个点灰色变色龙,被放置在一辆汽车的仪表板上,从前窗向外看。摄像头略微指向右侧,以便尽可能多地覆盖相关标志。该镜头的焦距为 6.5 毫米,视野约为 41 度。高速公路上的典型速度标志大约为 90 cm 宽,如果要在大约 30 m 的距离处检测到它们,则对应于大约 50 像素的大小。总共记录了超过 20 000 帧,其中每五帧被手动标记。每个标志的标签包含标志类型(人行横道、指定车道右侧、禁止站立或停车、优先道路、让路、50 公里/小时或 30 公里/小时)、能见度状态(遮挡、模糊或可见)和道路状态(是否标志是在正在行驶的道路上或在小路上)。
防护装备-头盔和背心检测
数据集下载地址:http://m6z.cn/61zarT
包含 774 个众包图像和 698 个网络挖掘图像。众包和网络挖掘的图像分别包含 2,496 和 2,230 个工人实例。

加州理工学院相机陷阱数据集
数据集链接:https://beerys.github.io/CaltechCameraTraps/
该数据集包含来自美国西南部 140 个摄像头位置的 243,100 张图像,带有 21 个动物类别的标签(加上空白),主要是在物种级别(例如,最常见的标签是负鼠、浣熊和土狼),以及 大约 66,000 个边界框注释。大约 70% 的图像被标记为空。
水下垃圾检测数据集
数据集下载地址:http://m6z.cn/6nnDQK
该数据来自 J-EDI 海洋垃圾数据集。构成该数据集的视频在质量、深度、场景中的对象和使用的相机方面差异很大。它们包含许多不同类型的海洋垃圾的图像,这些图像是从现实世界环境中捕获的,提供了处于不同衰减、遮挡和过度生长状态的各种物体。此外,水的清晰度和光的质量因视频而异。这些视频经过处理以提取 5,700 张图像,这些图像构成了该数据集,所有图像都在垃圾实例、植物和动物等生物对象以及 ROV 上标有边界框。

十九、人体姿态估计
MPII人体模型数据集
数据集链接:http://m6z.cn/69aaIe
MPII Human Shape 人体模型数据是一系列人体轮廓和形状的3D模型及工具。模型是从平面扫描数据库 CAESAR 学习得到。

MPII人类姿态数据集
数据集链接:http://m6z.cn/6gGnPb
MPII 人体姿态数据集是用于评估人体关节姿势估计的最先进基准。该数据集包括大约 25,000 张图像,其中包含超过 40,000 个带有注释身体关节的人。这些图像是使用已建立的人类日常活动分类法系统收集的。总的来说,数据集涵盖了 410 项人类活动,每个图像都提供了一个活动标签。每张图像都是从 YouTube 视频中提取的,并提供前后未注释的帧。此外,测试集有更丰富的注释,包括身体部位遮挡和 3D 躯干和头部方向。

KTH 多视图足球数据集
数据集链接:http://m6z.cn/692agI
作者收集了一个带有注释关节的足球运动员数据集,可用于多视图重建。数据集包括:
-
771张足球运动员的照片
-
在 257 个时间实例中从 3 个视图中获取的图像
-
14 个带注释的身体关节

宾夕法尼亚动作数据集
数据集链接:http://m6z.cn/692akK
Penn Action Dataset(宾夕法尼亚大学)包含 15 个不同动作的 2326 个视频序列以及每个序列的人类联合注释。

BBC姿态数据集
数据集链接:http://m6z.cn/5xr6Xq
BBC Pose 包含 20 个视频(每个视频长度为 0.5 小时至 1.5 小时),由 BBC 录制,并配有手语翻译。这 20 个视频分为 10 个用于训练的视频、5 个用于验证的视频和 5 个用于测试的视频。

Poser 数据集
数据集链接:http://m6z.cn/6gynqz
Poser 数据集是用于姿态估计的数据集,由 1927 个训练图像和 418 个测试图像组成。这些图像是综合生成的,并调整为单峰预测。这些图像是使用 Poser 软件包生成的。
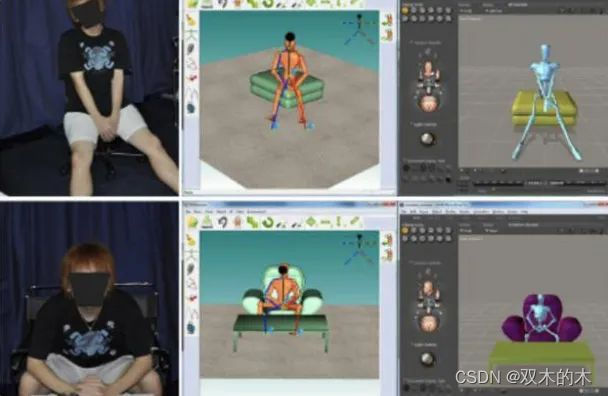
野外 3D 姿势数据集
数据集链接:http://m6z.cn/5xr6Z2
“野外 3D 姿势数据集”是野外第一个具有准确 3D 姿势用于评估的数据集。虽然存在户外其他数据集,但它们都仅限于较小的记录量。3DPW 是第一个包含从移动电话摄像头拍摄的视频片段的技术。
数据集包括:
-
60 个视频序列。
-
2D 姿势注释。
-
使用我们的方法获得的 3D 姿势。我们的方法利用了视频和 IMU,尽管场景很复杂,但姿势非常准确。
-
序列中每一帧的相机姿势。
-
3D 身体扫描和 3D 人物模型(可重新调整和重新塑造)。每个序列都包含其对应的模型。
-
18 个不同服装款式的 3D 模型。

V-COCO数据集
数据集链接:http://m6z.cn/5UGaii
V-COCO是一个基于 COCO 的数据集,用于人机交互检测。V-COCO 提供 10,346 张图像(2,533 张用于训练,2,867 张用于验证,4,946 张用于测试)和 16,199 个人物实例。每个人都有 29 个动作类别的注释,并且没有包括对象在内的交互标签。

宜家 ASM 数据集
数据集链接:http://m6z.cn/692aos
宜家 ASM 数据集是装配任务的多模式和多视图视频数据集,可对人类活动进行丰富的分析和理解。它包含 371 个家具组件样本及其真实注释。每个样本包括 3 个 RGB 视图、一个深度流、原子动作、人体姿势、对象片段、对象跟踪和外部相机校准。

立体人体姿势估计数据集
数据集链接:http://m6z.cn/62cnp5
这是一个立体图像对数据集,适用于上身人的立体人体姿态估计。SHPED 由 630 个立体图像对(即 1260 个图像)组成,分为 42 个视频片段,每个片段 15 帧。这些剪辑是从 26 个立体视频中提取的,这些视频是从 YouTube 获得的,标签为 yt3d:enable = true。此外,SHPED 包含 1470 条火柴人上身注释,对应于 49 个人根据这些条件:直立位置、所有上身部分几乎可见以及身体的非侧面视点。

AIST++ 舞蹈动作数据集
数据集链接:http://m6z.cn/5xr6M8
AIST++ 舞蹈动作数据集是从 AIST 舞蹈视频数据库构建的。对于多视图视频,设计了一个精心设计的管道来估计相机参数、3D 人体关键点和 3D 人体舞蹈动作序列:
它为 1010 万张图像提供 3D 人体关键点注释和相机参数,涵盖 9 个视图中的 30 个不同主题。这些属性使其成为具有 3D 人体关键点注释的最大和最丰富的现有数据集。它还包含 1,408 个 3D 人类舞蹈动作序列,表示为关节旋转以及根轨迹。舞蹈动作平均分布在 10 种舞蹈流派中,有数百种编舞。运动持续时间从 7.4 秒不等。至 48.0 秒。所有的舞蹈动作都有相应的音乐。

HiEve数据集
数据集链接:http://m6z.cn/6o4AAg
该数据集专注于在各种人群和复杂事件中进行非常具有挑战性和现实性的以人为中心的分析任务,包括地铁上下车、碰撞、战斗和地震逃生。并且具有大规模和密集注释的标签,涵盖了以人为中心的分析中的广泛任务。

二十、图像分类
宠物图像数据集
数据集下载地址:http://m6z.cn/5TAgdC
一个包含 37 个类别的宠物数据集,每个类别大约有 200 张图像。这些图像在比例、姿势和照明方面有很大的变化。所有图像都有相关的品种、头部 ROI 和像素级三元图分割的地面实况注释。

猫咪数据集
数据集下载地址:http://m6z.cn/5TAgbw
CAT 数据集包括超过 9,000 张猫图像。对于每张图像,猫的头部都有九个点的注释,眼睛两个,嘴巴一个,耳朵六个。

斯坦福狗狗数据集
数据集下载地址:http://m6z.cn/6nF6kM
斯坦福狗数据集包含来自世界各地的 120 种狗的图像。该数据集是使用 ImageNet 中的图像和注释构建的,用于细粒度图像分类任务。
该数据集的内容:
-
类别数:120
-
图片数量:20,580
-
注释:类标签、边界框

CBCL 街道场景数据
数据集下载地址:http://m6z.cn/5TAgeA
StreetScenes Challenge Framework 是用于对象检测的图像、注释、软件和性能测量的集合。每张图像都是从马萨诸塞州波士顿及其周边地区的 DSC-F717 相机拍摄的。然后用围绕 9 个对象类别的每个示例的多边形手动标记每个图像,包括 [汽车、行人、自行车、建筑物、树木、天空、道路、人行道和商店]。这些图像的标记是在仔细检查下完成的,以确保对象总是以相同的方式标记,关于遮挡和其他常见的图像变换。

Stanford 汽车图片数据
数据集下载地址:http://m6z.cn/616wop
Cars 数据集包含 196 类汽车的 16,185 张图像。数据分为 8,144 个训练图像和 8,041 个测试图像,其中每个类别大致按 50-50 分割。课程通常在品牌、型号、年份级别,例如 2012 Tesla Model S 或 2012 BMW M3 coupe。
MNIST 手写数字图像数据集
MNIST数据集是一个手写阿拉伯数字图像识别数据集,图片分辨率为 20x20 灰度图图片,包含‘0 - 9’ 十组手写手写阿拉伯数字的图片。其中,训练样本 60000 ,测试样本 10000,数据为图片的像素点值,作者已经对数据集进行了压缩。

Kaggle 垃圾分类图片数据集
该数据集是图片数据,分为训练集85%(Train)和测试集15%(Test)。其中O代表Organic(有机垃圾),R代表Recycle(可回收)

二十一、图像分割
天空图像数据集
数据集下载链接:http://suo.nz/1ykW0L
Sky 数据集包含 60 张带有地面实况的图像,用于天空分割。它基于 R. Fergus 15/02/03 的 Caltech Airplanes Side 数据集。选择数据集中包含天空区域的那些图像,并为它们创建地面实况。原始数据集图像名称保持不变。

CO-SKEL数据集
数据集下载链接:http://suo.nz/1FR95s
该数据集由分类骨架和分割掩码组成,用于评估协同骨架化方法。

CAD-120 affordance数据集
数据集下载链接:http://suo.nz/1NnlU1
包含9916个对象实例的3090幅图像的逐像素注释。

Intrinsic Images in the Wild
数据集下载链接:http://suo.nz/1UTwnq
“Intrinsic Images in the Wild”,这是一个用于评估室内场景固有图像分解的大规模公共数据集。作者们通过数百万个众包注释创建了这个基准,这些注释对每个场景中的点对的材料属性进行了相对比较。

具有细长部分的鸟类昆虫数据集
数据集下载链接:http://suo.nz/22pJs7
这些数据库由 280 张具有ground truth的鸟类和昆虫的公共图像组成。

多品种果花检测数据集
数据集下载链接:http://suo.nz/29RKnM
该数据集包含四组花卉图像,来自三种不同的树种:苹果、桃和梨,以及随附的地面实况图像。

OpenSurfaces数据集
数据集下载链接:http://suo.nz/1bI3Md
包含从消费者内部照片中分割出来的数千个表面示例,并使用材料参数(反射率、材料名称)、纹理信息(表面法线、校正纹理)进行注释和上下文信息(场景类别和对象名称)。

阴影检测/纹理分析数据集
数据集下载链接:http://suo.nz/1iyjoA
一个用于阴影检测和纹理分析的简单计算机视觉数据集,专门用于帮助测试移动机器人的阴影检测算法(和纹理分割算法)——即使用 活动(移动)相机进行阴影检测。
该数据集专注于纹理分析,因此每个图像序列都包含在许多不同纹理表面前移动的阴影。

文章结束,感谢阅读。大家有推荐的公众号可以评论区留言,共同学习,一起进步。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!