在killercoda中的一次apiserver异常追查思路
笔者:
最近在准备cks考试, 然后又发现了killercoda这个能够提供模拟考试环境的平台。它提供了很棒的引导,教你一步步追查问题,形成一整套追查思路,我觉得很不错,特此分享。
准备工作
首先还是需要养成配置文件备份的习惯, 避免因为修改出错导致的无法回滚。
-
apiserver 默认端口6443, 在apiserver异常(无法启动)之后, 我们尝试执行的任何kubectl 命令都会提示
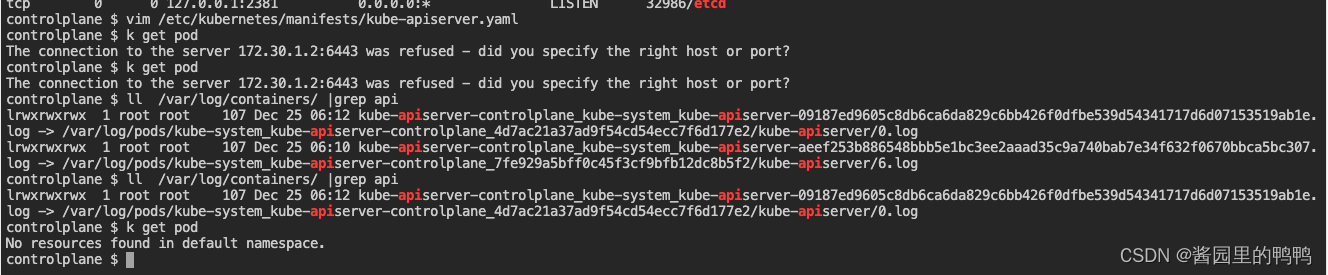
The connection to the server 172.30.1.2:6443 was refused - did you specify the right host or port?
-
查看日志的方法
/var/log/pods/

/var/log/containers
此路径下的日志其实做了一个链接,直接指向了/var/log/pods下面的日志

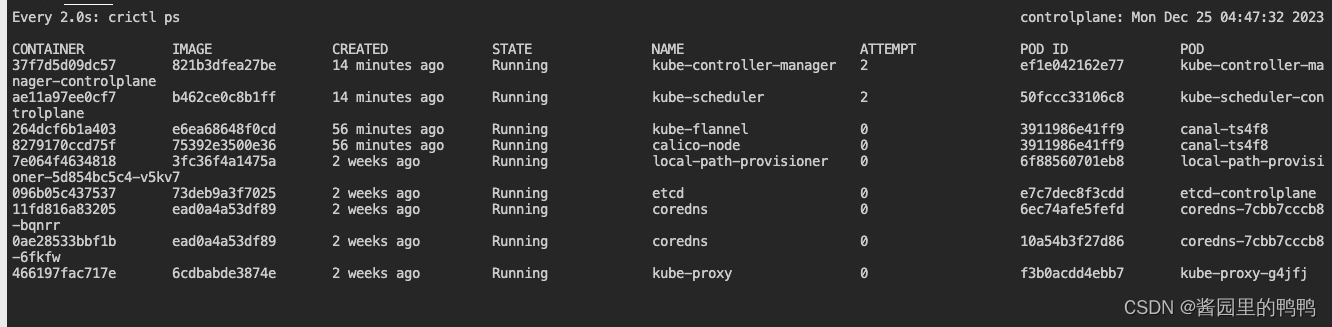
watch crictl ps
此命令可以帮助查看实时的k8s系统组件的容器运行状态
 docker ps 或者docker logs
docker ps 或者docker logs
/var/log/syslog 或者/var/log/messages或者 journalctl -u kubelet
ubuntu会将日志记录在syslog下,而centos系列会将日记存在/var/log/messages下
journalctl -u kubelet
3. 配置文件的路径
在killercoda提供的环境里,配置文件存储路径结构如下
| k8s基础组件 | 配置路径 |
|---|---|
| etcd | /etc/kubernetes/manifests/etcd.conf |
| kube-apiserver | /etc/kubernetes/manifests/kube-apiserver.yaml |
| kube-controller-manager | /etc/kubernetes/manifests/kube-controller-manager.yaml |
| kube-scheduler | /etc/kubernetes/manifests/kube-scheduler.yaml |
| kubelet | /var/lib/kubelet/config.yaml |
Apiserver Crash
1. 要求你修改apiserver配置,加入一个错误参数。
The idea here is to misconfigure the Apiserver in different ways, then check possible log locations for errors.
You should be very comfortable with situations where the Apiserver is not coming back up.
Configure the Apiserver manifest with a new argument **--this-is-very-wrong**.
Check if the Pod comes back up and what logs this causes.
Fix the Apiserver again.
- 在apiserver配置文件中加入–this-is-very-wrong参数保存后,检查发现kube-apiserver在一段时间后消失了。
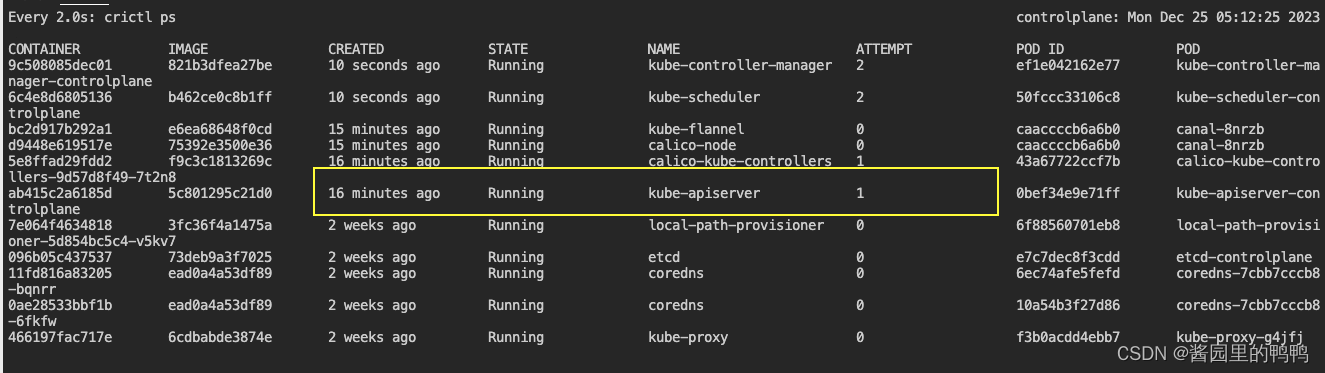
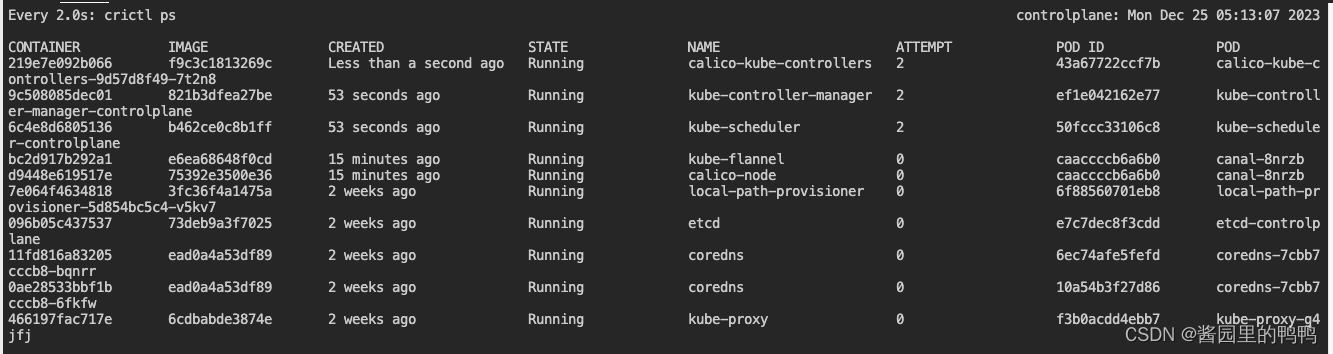
- 随后执行kubectl 相关的任何命令都出现了这样的报错
The connection to the server 172.30.1.2:6443 was refused - did you specify the right host or port? - 开始逐一检查日志
在**/var/log/containers**下面找到APIserver日志, 打开发现已经提示有异常的参数。

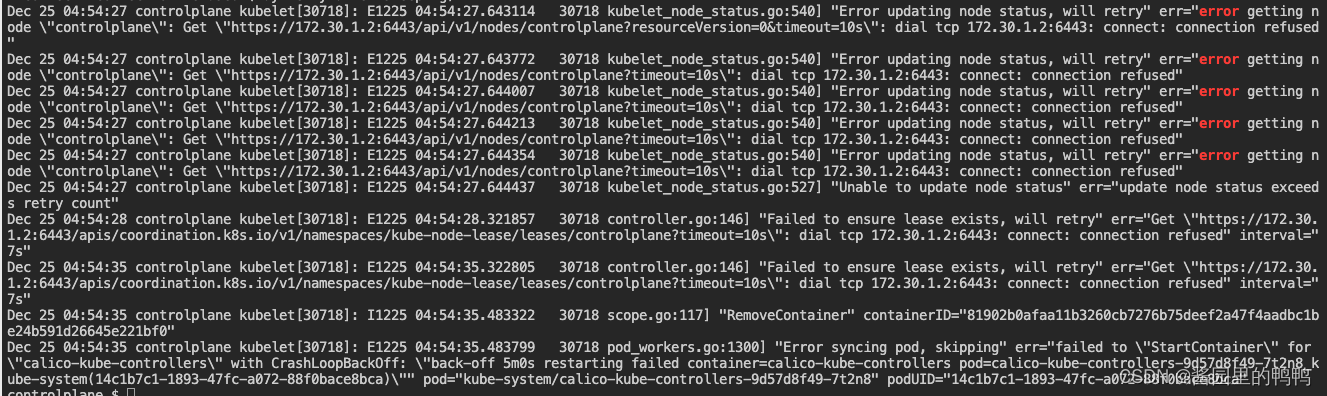
在journalctl -u kubelet |grep error 发现大段的无法连接apiserver端口的报错
Dec 25 05:18:24 controlplane kubelet[30718]: E1225 05:18:24.602540 30718 kubelet_node_status.go:540] "Error updating node status, will retry" err="error getting node \"controlplane\": Get \"https://172.30.1.2:6443/api/v1/nodes/controlplane?resourceVersion=0&timeout=10s\": dial tcp 172.30.1.2:6443: connect: connection refused"
Dec 25 05:18:24 controlplane kubelet[30718]: E1225 05:18:24.603081 30718 kubelet_node_status.go:540] "Error updating node status, will retry" err="error getting node \"controlplane\": Get \"https://172.30.1.2:6443/api/v1/nodes/controlplane?timeout=10s\": dial tcp 172.30.1.2:6443: connect: connection refused"
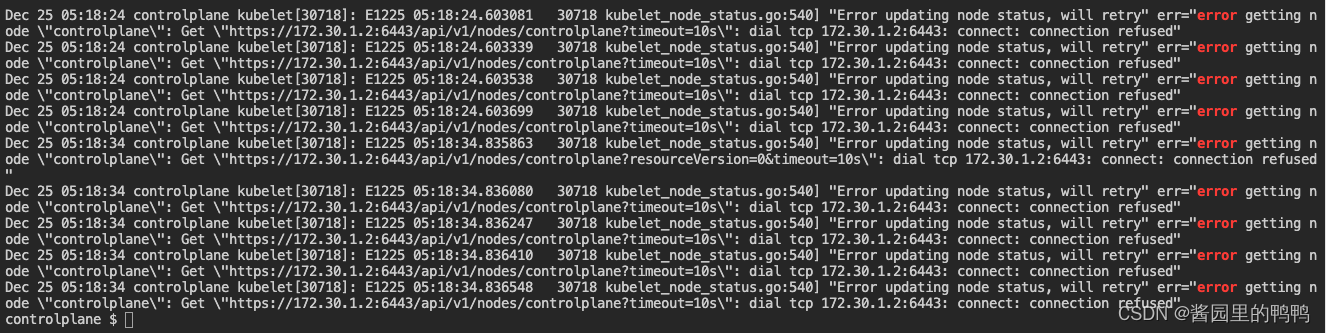
解决: 根据日志中给出的信息, 在APIserver配置文件里删除错误的参数设定 即可。
2. 给apiserver设定一个错误的值 --etcd-servers=this-is-very-wrong .
现象:同样是没有看到有apiserver的容器运行, 6443不通
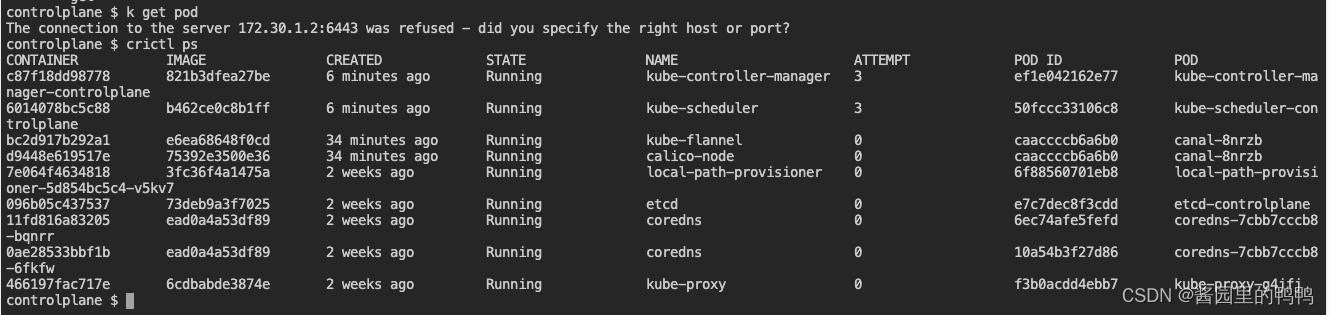
1. 查看containers下的日志

发现apiserver已经有日志,但是提示了无法连接到etcd配置的地址
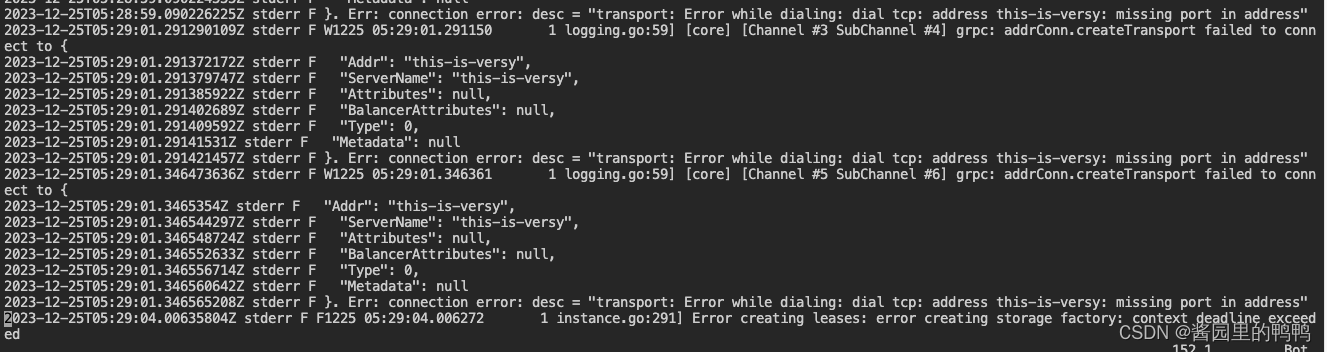
3. Invalid Apiserver Manifest YAML
尝试将apiserver的配置文件修改如下
apiVersionTHIS IS VERY ::::: WRONG v1
kind: Pod
metadata:
现象:apiserver容器不存在,且/var/log/containers下未见有apiserver日志

- 检查kubelet日志
发现报错 file.go:187] “Could not process manifest file” err="/etc/kubernetes/manifests/kube-apiserver.yaml: couldn’t parse as pod(Object ‘apiVersion’ is missing in '{“apiVersionthisisvery ::”:“wrong v1”,“kind”:“Pod”,"m。。。。。,“name”:“usr-share-ca-certificates”}]},“status”:{}}'), please check config file" path=“/etc/kubernetes/manifests/kube-apiserver.yaml””

Apiserver Misconfigured
试验地址:https://killercoda.com/killer-shell-cks/scenario/apiserver-misconfigured
基本思路:
通过日志,确认问题点,然后再去逐一解决。
追查过程01

在syslog日志中发现 kubeapiserver 第四行有错误。
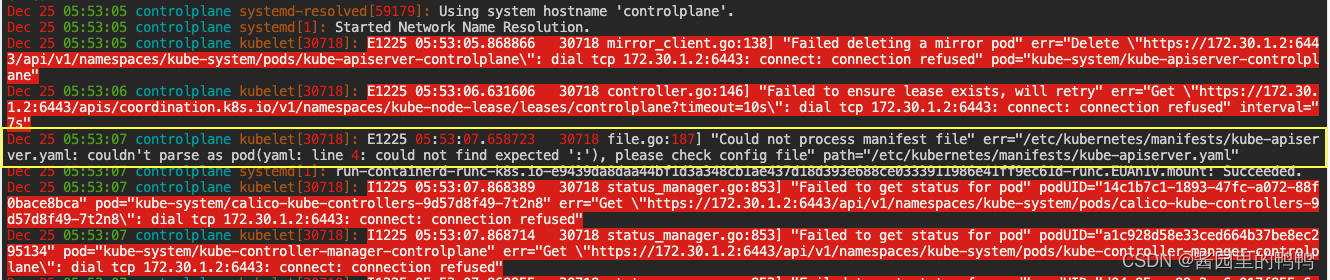

修复后查看服务是否恢复,发现container日志出现,但6443还是没起来。

提示有错误的参数名

再次尝试修正, 检查服务状态,报错如下:
Get “https://172.30.1.2:6443/api/v1/namespaces/default/pods?limit=500”: dial tcp 172.30.1.2:6443: connect: connection refused - error from a previous attempt: read tcp 172.30.1.2:60628->172.30.1.2:6443: read: connection reset by peer

分别查看两个容器日志

他在连接本机23000端口失败,需要确认是设定异常还是服务错误。

此处看到,apiserver设定的etcd地址端口是23000, 但是实际etcd运行在默认的2379端口


修复设定后, 再次观察, 最后apiserver正常运行。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!