doris基本操作,02-创建复合分区表
2023-12-24 18:43:13
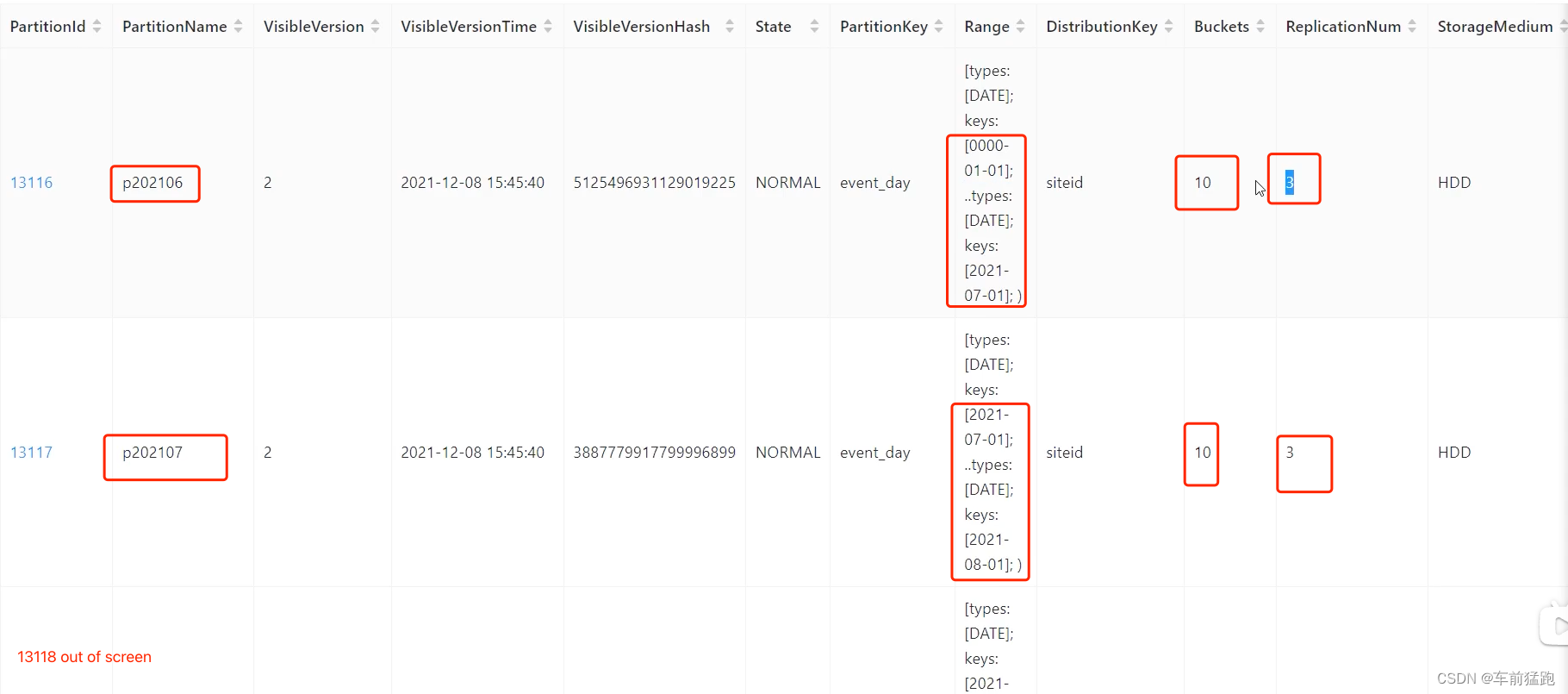
创建复合分区表
create table table2 (
event_day DATE,
siteid int defautl '10',
citycode smallint,
username varchar(32) defautl '',
pv bigint sum default '0'
)
aggregate key (event_day, siteid, citycode, username)
-- 按照event_day做range分区 --
paritition by range(event_day)
(
partition p202106 values less than ('2021-07-01'),
partition p202107 values less than ('2021-08-01'),
partition p202108 values less than ('2021-09-01')
)
distributed by hash(siteid) buckets 10
properties("replication_num" = "3");
导入数据
数据文件table2_data内容如下,分隔符是竖线(|)
2021-06-03|9|1|jack|3
2021-06-10|10|2|rose|2
2021-07-03|11|1|jim|2
2021-07-05|12|1|grace|2
2021-07-12|13|2|tom|2
2021-08-15|14|3|bush|2
2021-08-12|15|4|helen|3
curl --location-trusted -u root:123456 -H “label:table2_20210707” -H “column_separator: |” -T table2_data http://node01:8030/api/test_db/table2/_stream_load

使用场景
- 有时间维度或者类似带有有序值的维度,可以已这类维度作为分区列。分区粒度可以根据导入频次,分区数据量等进行评估。
- 历史数据删除需求:如有删除历史数据的需求(比如,仅仅保留最近N天的数据)。使用复合分区,可以通过删除历史分区来达到目的。也可以通过在制定分区内发送delete语句进行数据删除。
- 解决数据倾斜问题:每个分区可以单独制定分桶数量。如按天分区,当每天的数据量差异很大时,可以通过制定分区的分桶数,合理划分不同分区的数据,分桶列建议选择区别度大的列。
文章来源:https://blog.csdn.net/cin_ie/article/details/135183501
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!