pandas之DataFrame使用详解——看完不会用你打我
2023-12-22 18:05:32
DataFrame是Pandas中的一个表格型数据结构,包含一组有序的列,每列值的类型都可不同(整型、浮点型、布尔型、字符串等),DataFrame既有行索引也有列索引,行标签index默认是序号 0,1,2我们也可以手动对其赋值,示例如下:
| index(隐式列) | Chinese | Math | English |
|---|---|---|---|
| 查良镛 | 11 | 12 | 13 |
| 熊耀华 | 21 | 22 | 23 |
| 陈文统 | 31 | 32 | 33 |
一、DataFrame实例化
DateFrame可以使用字典、列表等进行实例化,后面根据增删改查功能分类进行代码展示,示例代码均已通过测试并添加了相关注释,看官可放心使用。增删改查功能代码中使用的变量就是本步骤中所创建的df01、df02变量。
import pandas as pd, numpy as np
df01 = pd.DataFrame(data=[[11,12,13],[21,22,23],[31,32,33],[41,None,None]],
columns=['Chinese','Math','English'],
index=['小王','小李','小张','小空'])
df02 = pd.DataFrame({"Fruit":["apple","pear","banana","banana"],
"Producer":["beijing","shanghai","taiwan","taiguo"],
"Price":[1.0,2.0,3.0,4.0],
"Weight":[100,200,300,400]})
print(df01)
print(df02)
if __name__ == "__main__":
filter_dataFrame()
#update_dataFrame()
#insert_dataFrame()
#delete_dataFrame()二、过滤查询
def filter_dataFrame():
#不指定会返回所有列(写法1)
df02_split01 = df02.loc[df02.Fruit=="banana"][df02.Producer=="taiwan"]
#有多个条件且要指定列时,列必须放在第一个条件中或放在最后(写法1)
df02_split02 = df02.loc[df02.Fruit=="banana",["Fruit","Producer","Weight"]][df02.Producer=="taiwan"]
df02_split03 = df02.loc[df02.Fruit=="banana"][df02.Producer=="taiwan"][["Fruit","Producer","Weight"]]
#可以不设置过滤条件,仅指定需要保留的列
df02_split04 = df02[["Fruit","Producer"]]
print('\r\n df02_split01 as below:')
print(df02_split01)
print('\r\n df02_split02 as below:')
print(df02_split02)
print('\r\n df02_split03 as below:')
print(df02_split03)
print('\r\n df02_split04 as below:')
print(df02_split04)
#不指定会返回所有列(写法2)
df02_split05 = df02.loc[df02["Fruit"]=="banana"][df02["Producer"]=="taiwan"]
#有多个条件且要指定列时,列必须放在第一个条件中或放在最后(写法2)
df02_split06 = df02.loc[df02["Fruit"]=="banana",["Fruit","Producer","Weight"]][df02["Producer"]=="taiwan"]
df02_split07 = df02.loc[df02["Fruit"]=="banana"][df02["Producer"]=="taiwan"][["Fruit","Producer","Weight"]]
print('\r\n df02_split05 as below:')
print(df02_split05)
print('\r\n df02_split06 as below:')
print(df02_split06)
print('\r\n df02_split07 as below:')
print(df02_split07)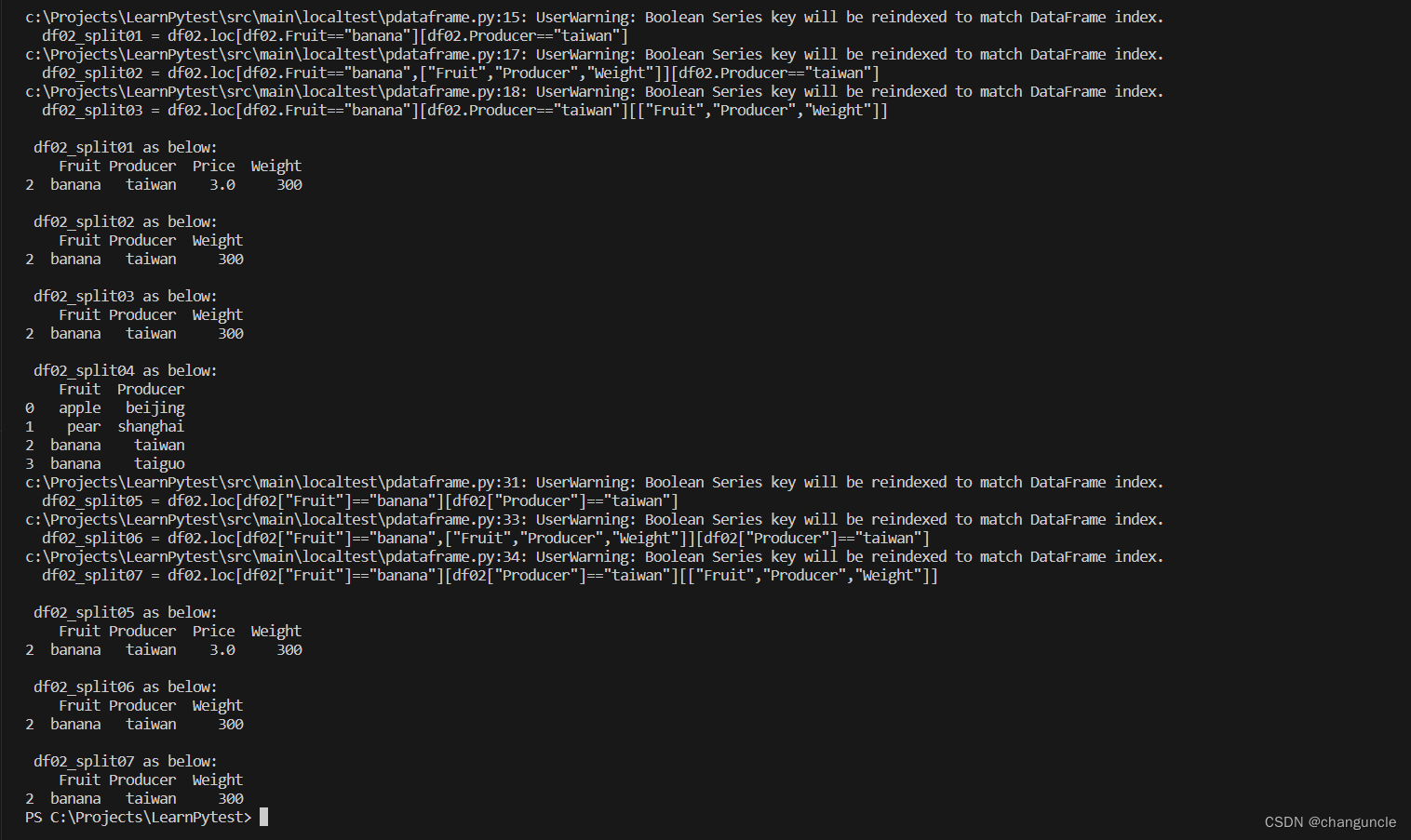
三、更新数据
def update_dataFrame():
df02.loc[df02["Fruit"]=="banana", "Price"] += 0.1
print('\r\n df02 as below:')
print(df02)
df02_split01 = df02.loc[df02["Fruit"]=="banana", ["Price", "Weight"]] = [9.0, 900]
print('\r\n df02 as below:')
print(df02)
col_index = df02.loc[df02["Fruit"]=="banana"][df02["Producer"]=="taiwan"].index
df02.loc[col_index, "Price"] = 10.0
print('\r\n df02 as below:')
print(df02)
col_index = df02.loc[df02["Fruit"]=="banana"][df02["Producer"]=="taiwan"].index
df02.loc[col_index, ["Price", "Weight"]] = [11.0, 1100]
print('\r\n df02 as below:')
print(df02)
四、插入数据?
def insert_dataFrame():
#若存在index=9的行就更新本行的值,不存在就在最后添加一行
df02.loc[9] = ["new01","new01",9.0,9.0]
print('\r\n df02 as below:')
print(df02)
df02.loc[len(df02)] = ["new02","new02",9.0,9.0]
print('\r\n df02 as below:')
print(df02)
#默认新列的所有值都是None
df02['newCol'] = None
print('\r\n df02 as below:')
print(df02)
#如果需要为所有新列手动赋值时,数组元素的个数与DataFrame数据行的个数必须一致
df02['newCo2'] = [1,1,1,1,1,1]
print('\r\n df02 as below:')
print(df02)
五、删除数据
def delete_dataFrame():
'''
drop()方法可用于删除DataFrame中的行或列,它有两个重要的参数:labels、axis、inplace
-labels参数用于指定要删除的行或列的标签。可以传递单个标签,也可以传递一个标签列表
-axis参数用于指定删除行还是列。默认值0表示删除行,1表示删除列
-inplace参数用于指定是否在原始DataFrame上进行修改。值为True会在原始DataFrame上进行修改,值为False或不传此参数将返回一个新的DataFrame,而不修改原始DataFrame
'''
#删除行
df02_split01 = df02.drop(0, axis=0, inplace=False)
print('\r\n inplace=False, drop 0 df02 as below:')
print(df02)
print('\r\n inplace=False, drop 0 df02_split01 as below:')
print(df02_split01)
df02.drop(3, axis=0, inplace=True)
print('\r\n inplace=True, drop 3 df02 as below:')
print(df02)
df02.drop([1,2], axis=0, inplace=True)
print('\r\n inplace=True, drop 1、2 df02 as below:')
print(df02)
#删除列
df02_split02 = df02.drop("Price", axis=1, inplace=False)
print('\r\n inplace=False, drop Price df02 as below:')
print(df02)
print('\r\n inplace=False, drop Price df02_split01 as below:')
print(df02_split02)
df02.drop(["Producer","Weight"], axis=1, inplace=True)
print('\r\n inplace=True, drop Producer、Weight df02 as below:')
print(df02)
'''
del()方法可用于删除DataFrame中的列
'''
del df02["Price"]
print('\r\n after del Price df02 as below:')
print(df02)
'''
使用布尔索引删除行/过滤行
'''
#过滤出"Chinese"列值大于11的行,原始DataFrame不变
df01_split01 = df01[df01["Chinese"]>11]
print('\r\n filter Chinese>11, df01 as below:')
print(df01)
print('\r\n filter Chinese>11, df01_split01 as below:')
print(df01_split01)
#过滤出"Chinese"列值小于等于11的行,原始DataFrame不变
df01_split02 = df01[~(df01["Chinese"]>11)]
print('\r\n filter Chinese<=11, df01 as below:')
print(df01)
print('\r\n filter Chinese<=11, df01_split02 as below:')
print(df01_split02)
'''
使用query()删除行/过滤行
'''
df01_split03 = df01.query("Chinese>11 & Math>22")
df01_split04 = df01.query("Chinese>11 and Math>22")
print('\r\n query Chinese>11 &/and Math>22, df01 as below:')
print(df01)
print('\r\n query Chinese>11 & Math>22, df01_split03 as below:')
print(df01_split03)
print('\r\n query Chinese>11 and Math>22, df01_split04 as below:')
print(df01_split04)
'''
使用dropna()删除DataFrame中包含缺失值的行或列
'''
#删除包含缺失值的行
df01_split05 = df01.dropna(axis=0, inplace=False)
print('\r\n df01_split05 as below:')
print(df01_split05)
#删除包含缺失值的列
df01_split06 = df01.dropna(axis=1, inplace=False)
print('\r\n df01_split06 as below:')
print(df01_split06)
'''
使用fillna()填充DataFrame中的缺失值
'''
df01_split07 = df01.fillna(0, inplace=False)
print('\r\n df01_split07 as below:')
print(df01_split07)
文章来源:https://blog.csdn.net/xiaouncle/article/details/135154590
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!