AntiFake: Using Adversarial Audio to Prevent Unauthorized Speech Synthesis
AntiFake: Using Adversarial Audio to Prevent Unauthorized Speech Synthesis
CCS 2023

笔记
后续的研究方向
摘要
深度神经网络和生成人工智能的快速发展促进了现实语音合成的发展。虽然这项技术在改善生活方面有着巨大的潜力,但它也导致了“DeepFake”的出现,在这种技术中,合成语音可以被滥用来欺骗人类和机器,达到邪恶的目的。为了应对这种不断演变的威胁,人们对通过DeepFake检测来减轻这种威胁非常感兴趣。
作为对现有工作的补充,我们建议采取预防性方法,并引入AntiFake,这是一种依靠对抗性示例来防止未经授权的语音合成的防御机制。为了确保对攻击者未知合成模型的可转移性,采用了集成学习方法来提高优化过程的可推广性。为了验证所提出的系统的有效性,我们使用真实世界的DeepFake语音样本,针对五个最先进的合成器评估了AntiFake。实验表明,AntiFake即使对未知的黑匣子模型也能达到95%以上的保护率。我们还对24名人类参与者进行了可用性测试,以确保该解决方案可供不同人群使用。
引言
语音合成,通常称为文本到语音(TTS),是指从文本输入中生成人工语音。多年来,这项技术在广泛的应用范围广泛,从语音或听力障碍患者的无障碍辅助设备到智能设备中的语音助手。最近深度神经网络(DNN)的出现进一步推动了该领域的发展,导致了被称为“DeepFake”音频的高度逼真的合成语音的出现。然而,尽管这些强大的系统彻底改变了人机交互,旨在改善生活,但由于其潜在的邪恶应用,它们也带来了重大的安全风险。
DeepFake的现实威胁
在恶意攻击中使用DeepFake语音的可能性并不遥远。据报道,骗子使用DeepFake技术冒充首席执行官的声音,通过一个电话成功诈骗了243000多美元[47]。最近在2023年,DeepFake音频被用来通过令人信服地冒充账户持有人来入侵银行账户[15],并以有影响力的名人的声音为幌子产生错误信息和仇恨言论[56,65],导致广泛的负面社会影响。这些事件表明,当代语音合成技术已经能够欺骗数字认证系统和人类听觉,这突出了迫切需要有效的对策。
现有防御和固有限制
为了应对这些新出现的威胁,现有的研究工作大多致力于开发防御检测方法。更具体地说,这些方法主要侧重于活跃度检测[44,46,66]和声学信号分析[3,5],建立在对人类发声系统物理特性(例如,声带振动[44]和发音手势[66])以及低维信号特征(例如,MFCC和信号功率线性度[3])的深入了解之上。尽管这些方法在发现合成音频作为攻击后缓解工具方面取得了显著成功,但AntiFake偏离了现有的路线研究的重点是防止攻击,以建立多层防御。
AntiFake-通过防止未经授权的合成而形成的补充防御层
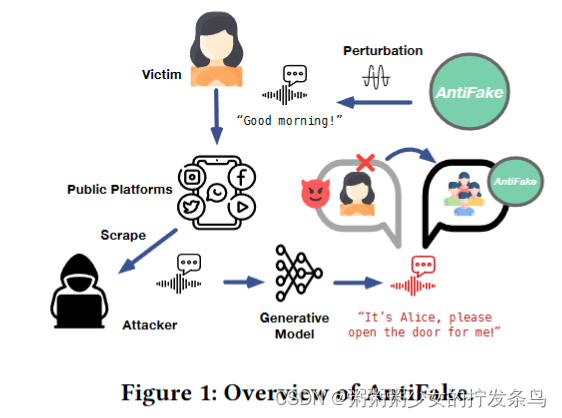
受这一差距的启发,以及攻击者必须依赖用户的语音样本来生成DeepFake语音的观察结果,我们提出了AntiFake,以防止使用隐蔽的对抗性扰动进行未经授权的语音合成。AntiFake采取了一种积极主动的方法,其关键思想是通过偏离条件语音合成中用于说话人身份控制的说话人嵌入来破坏合成过程。使用AntiFake,用户或平台可以在与公众共享语音样本之前对其进行保护。虽然处理后的样本听起来仍然像人类的受害者,但当攻击者将其用于语音合成时,生成的合成语音将类似于他人的声音,而不是受害者的声音。因此,生成的DeepFake音频不太可能出于邪恶目的欺骗人类或机器。
防伪的技术挑战
设计AntiFake提出了四个主要的技术挑战。首先,我们坚持一个实用的设置,即使用AntiFake的用户不知道攻击者使用的确切模型。因此,即使是优化有效扰动的黑盒查询也变得不可行,需要将对抗性示例转移到未知模型。为了解决这个问题,我们假设对抗性合成模型通常必须与其他鲁棒编码器共享相似性才能提高效率,并采用集成学习来导致这些特征的显著偏差。直观地说,这种方法确保了与原始扬声器相比,扰动嵌入总是更接近其他扬声器的嵌入。这一原理构成了两种优化机制的基础,这两种机制引导着对最大嵌入偏差的探索。
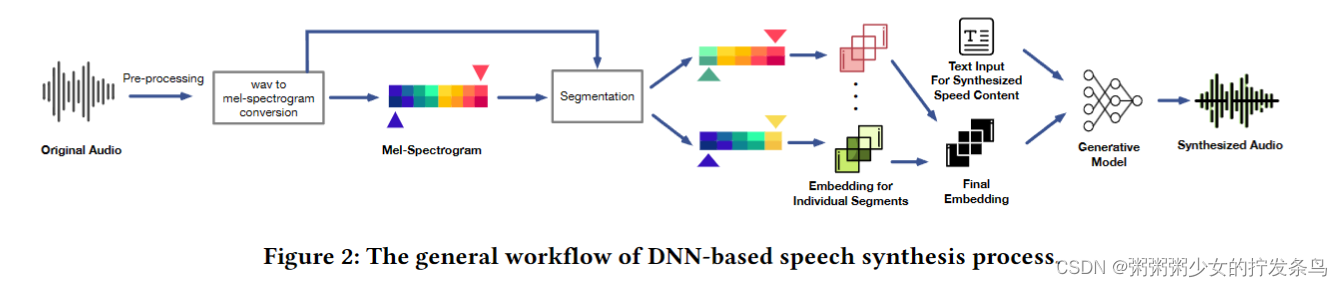
其次,我们对最先进的语音合成器的研究表明,它们通常使用多个音频片段来促进稳健的嵌入提取。这种特性使得直接计算最终嵌入的传统方法效率较低,这可能会将优化陷入局部最优。为了克服这个问题,我们采用了基于分段的优化策略,并引入了加权分段损失自适应机制。这种方法根据分段的贡献动态调整分段权重,通过优化单个分段实现更精细的扰动生成。
第三,保持扰动音频样本的质量对于确保可用性和防止引起攻击者的怀疑至关重要。传统的𝐿𝑝 -基于扰动的测量是不充分的,因为𝐿𝑝距离和人类听觉系统。因此,我们转向人类感知原理,特别是频带灵敏度和掩蔽效应。基于心理声学特性,我们设计了基于反向声压水平的频率惩罚,并结合了计算高效的SNR指标来增强不可感知性。
最后,AntiFake保护人类感知的主要目标需要人类参与判断说话者身份偏差,因为没有一个计算模型能完美地模拟听觉感知。然而,使用人类作为迭代损失反馈是不切实际的,并且可能会严重破坏可用性。为此,我们设计了一个人工在环工作流,该工作流将人工参与非技术任务的程度降至最低(即,仅对说话者身份),同时最大化优化的益处。为了进一步平衡计算嵌入偏差和人类判断,我们采用层次分析法[53]来全面平衡两者,并做出信息决策。
实验和发现
为了能够对AntiFake进行全面评估,我们对五种最先进的合成器进行了评估,其中包括一种商业产品(即ElevenLabs[18]),以及三种扬声器验证系统,包括一个商业平台(即Microsoft Azure)。此外,为了便于进行更现实的评估,我们根据恶意意图对真实世界的DeepFake句子进行了分类。我们的评估从不同合成器、说话者、话语和演讲内容的大规模合成开始。在60000个合成语音样本中,我们过滤了那些可以绕过说话者验证系统并且在感知上与受害者声音相似的样本,以形成一组高保真DeepFake语音数据集。在此基础上,AntiFake的评估实现了>95%的保护率,优化的对抗性示例被证明可以转移到黑匣子商业模型中。为了验证可用性,我们进一步基于系统可用性量表(SUS)问卷进行了可用性测试,涉及24名不同背景的人类参与者。
贡献
我们提出的AntiFake不仅增强了对DeepFake威胁的安全性,而且有助于持续打击虚假信息和假冒行为的传播。我们的贡献概述如下。
我们提出了AntiFake,这是一种主动防御方法,利用对抗性示例来破坏未经授权的语音合成,这样合成的DeepFake音频对人类和机器来说都不像受害者的声音。
我们开发了AntiFake的人工循环工作流程,使用户能够用最少的人力来定制语音。为了应对未知攻击者合成器的挑战,我们在一组最先进的编码器模型上采用了集成学习方法。
我们针对五种当代合成器(包括一种商业产品)和三种扬声器验证系统(包括一个商业平台)对AntiFake进行了评估。AntiFake即使面对看不见的商业合成器,也能达到95%以上的保护率。我们还对24名人类参与者进行了可用性测试。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!