(详细版)Vary: Scaling up the Vision Vocabulary for Large Vision-Language Models
Haoran Wei1?, Lingyu Kong2?, Jinyue Chen2, Liang Zhao1, Zheng Ge1?, Jinrong Yang3, Jianjian Sun1, Chunrui Han1, Xiangyu Zhang1
1MEGVII Technology 2University of Chinese Academy of Sciences 3Huazhong University of Science and Technology
arXiv 2023.12.11
背景:
随着大规模视觉-语言模型(LVLMs)的兴起,它们在多个领域展现出了卓越的性能。LVLMs通常使用一个通用的视觉词汇(如CLIP)来覆盖大部分常见的视觉任务。
研究动机:
目前的多模态大模型几乎都是用CLIP作为vision encoder,虽然CLIP有很强的视觉文本对齐能力并且能覆盖大多数日常任务,但是对于密集和细粒度感知的任务,例如高分辨率感知、非英语OCR以及文档/图表理解等,CLIP表现出了编码低效和out of vocabulary的问题。
主要贡献:
Vary方法为LVLMs的视觉感知能力提供了一个更高效和准确的视觉词汇扩展方案。通过生成新的视觉词汇并与原始词汇融合,该方法在特定视觉任务上表现出色,并在性能评估中取得了良好的结果。
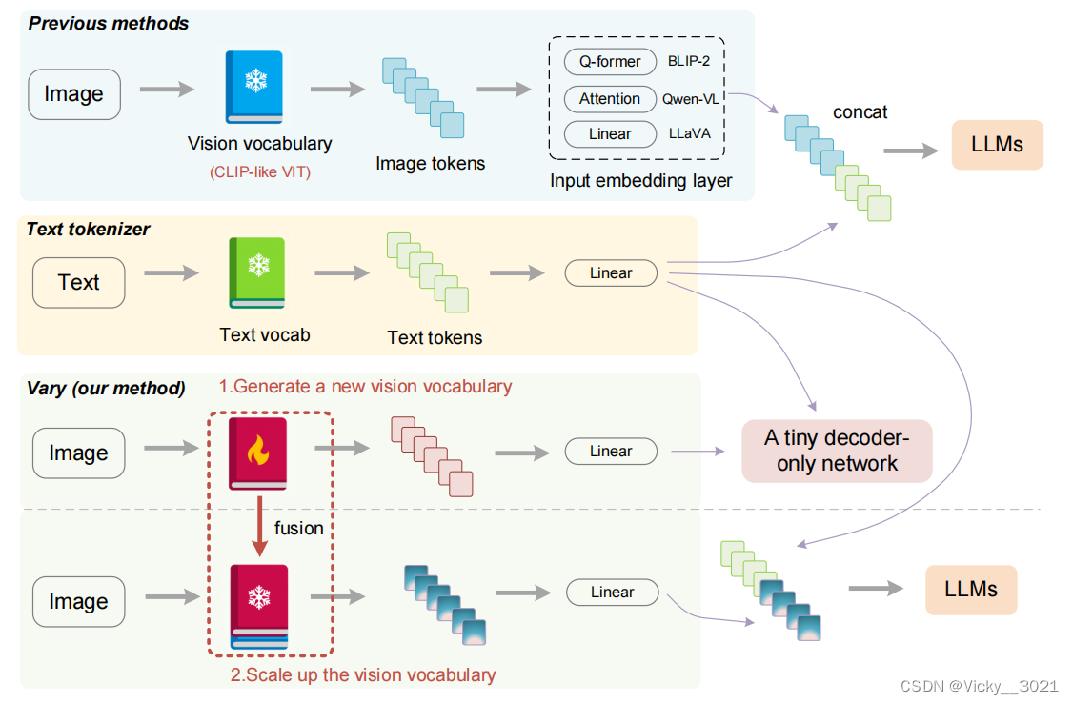
这篇论文的灵感是来源于大型语言模型中的文本词汇扩展方式,不同于其他使用现成视觉词汇的模型,Vary的过程可以分为视觉词汇的生成和融合两个阶段。在第一阶段,我们使用一个“词汇网络”和一个微小的解码器网络,通过自动回归产生一个强大的新视觉词汇。在第二阶段,我们将视觉词汇表与原始词汇表融合,为lvlm有效地提供新的特征。
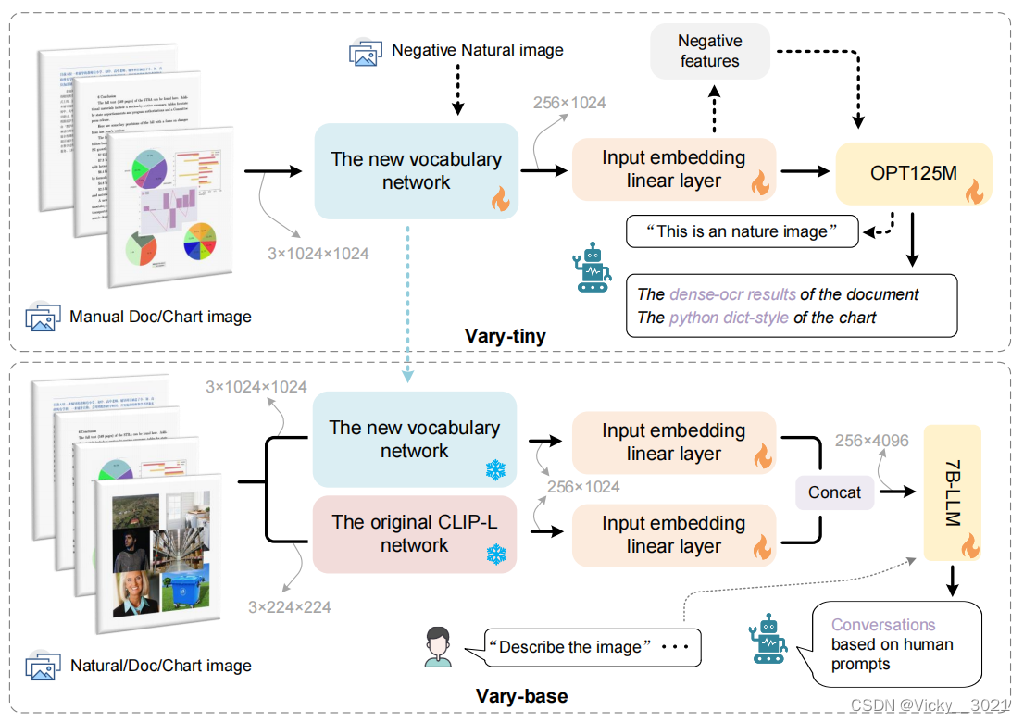
这个是Vary的训练方法和模型结构图,跟现有方法直接用现成的CLIP词表不同的是,Vary 分两个阶段:第一阶段先用一个很小的 Decoder-only 网络用自回归方式帮助产生一个强大的新视觉词表,此阶段为 Vary-tiny;具体来说,Vary-tiny主要由一个词汇网络和一个微小的 OPT-125M 组成。在两个模块之间,使用一个线性层来对齐通道尺寸。在Vary-tiny 中没有文本输入分支,因为它主要关注细粒度感知。希望新的视觉词汇网络能够在处理人工图像,即文档和图表方面表现出色,以弥补CLIP的不足。同时,也期望在输入自然图像时,它不会成为CLIP的噪声。因此,在生成过程中,本文将人工文档和图表数据作为正样本,将自然图像作为负样本来训练 Vary-tiny。然后,第二阶段,冻结新旧视觉词汇网络的权值,解冻其他模块的权值。融合新词表和 CLIP 词表,从而高效的训练多模大模型拥有新 feature,此阶段为 Vary-base。
数据集:
自制中英文文档数据集。
文档数据:开源论文
图表数据:matplotlib、pyecharts渲染工具
负的自然图像:COCO数据集中提取
论文的数据集是作者自己创建的,提取了部分开放获取的论文收集pdf格式文档作为英文部分,然后经过多种处理成为文本数据集。图表数据主要借助matplotlib和pyecharts作为渲染工具进行构建的。负的自然图像数据是从COCO数据集中提取的。
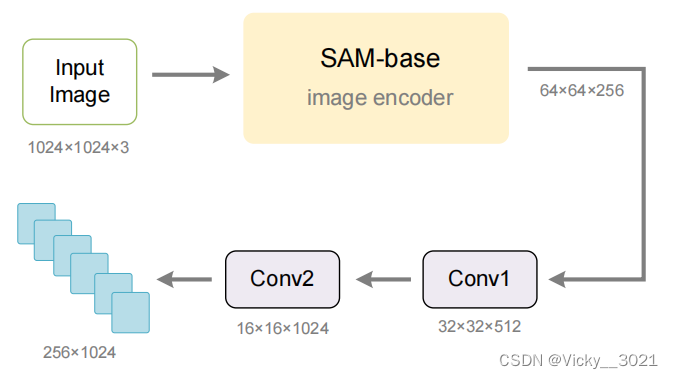
本文使用 SAM 预训练的 ViTDet 图像编码器作为 Vary 新词汇网络的主要部分。由于 SAM-base 的输入分辨率为(1024×1024),而输出步幅为 16,所以最后一层的特征维度的为(64×64×256),无法与 CLIP-L 的输出(N×C为256×1024)对齐。因此,本文在SAM 初始化网络的最后一层后面添加了两个卷积层,如下图所示。第一个卷积层的核大小为 3,目的是将特征变为 32×32×512。第二个卷积层的设置与第一个相同,可以进一步将输出变为 16×16×1024。之后,再将输出特征展平为 256×1024,以对齐 CLIP-VIT的图像 token 的维度。
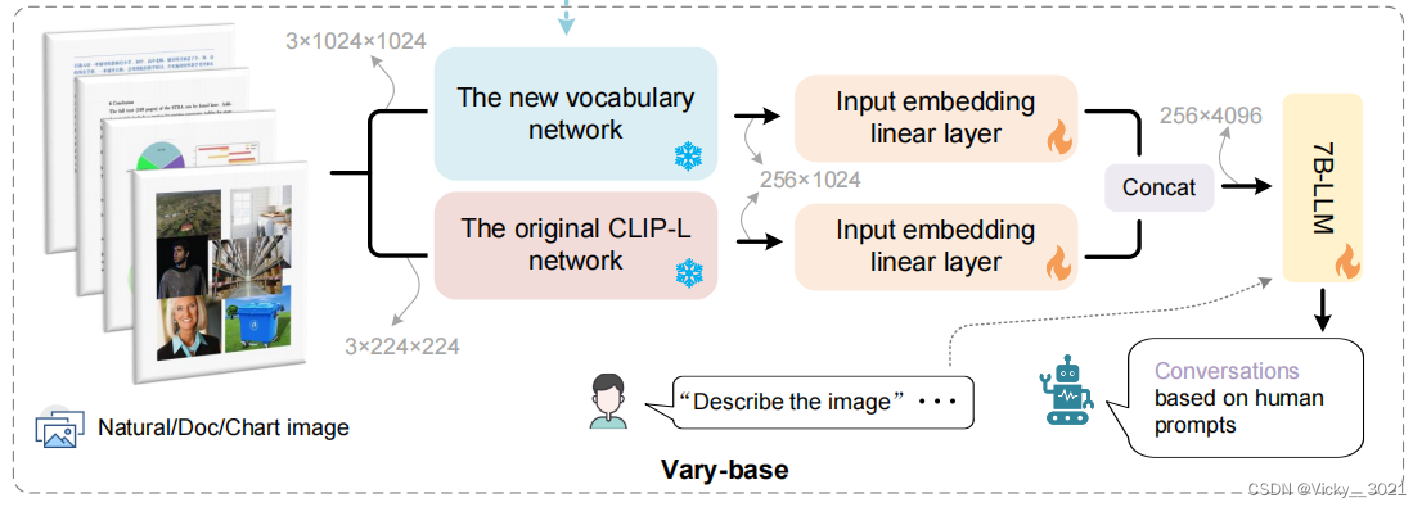
在完成词汇网络的训练后,将它用于 Vary -base中。具体来说,将新的视觉词汇表与原始的 CLIP-VIT 并行。这两个视觉词汇表都有一个单独的输入嵌入层,即一个简单的线性。线性的输入通道为 1024,输出通道为 2048,保证了拼接后的图像 token 通道为4096,这与LLM (Qwen-7B 或 Vicuna-7B )的输入完全一致。
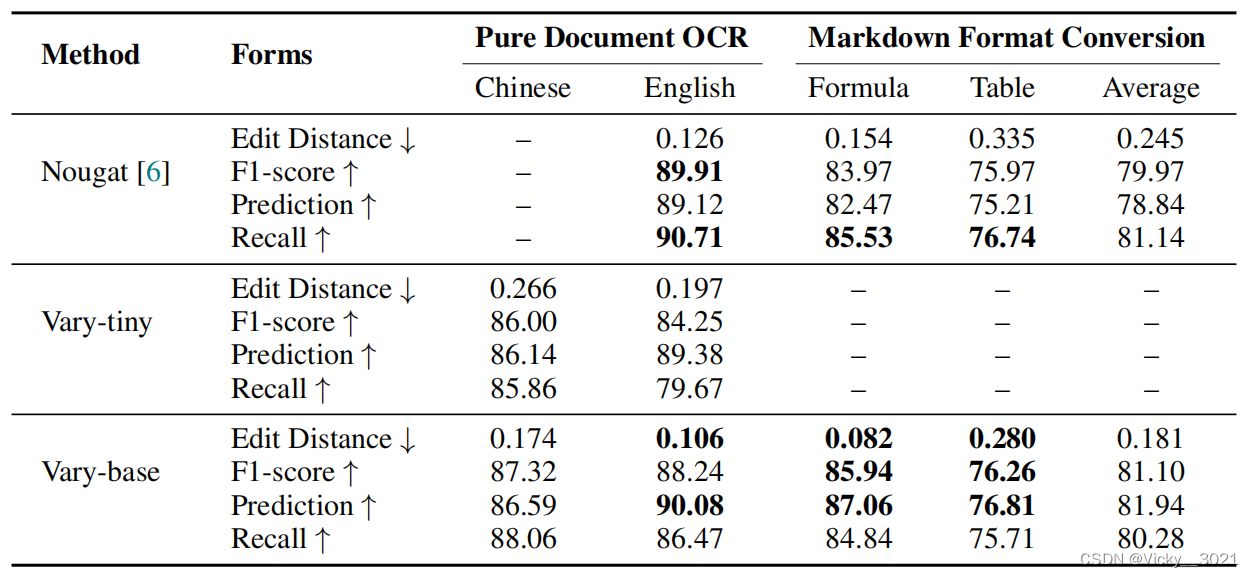
与Nougat相比,Vary具有细粒度的文本感知能力,他的edit distance、F1score和prediction都有所提升,但是召回率出现了下降,但是降得也并不是很低。
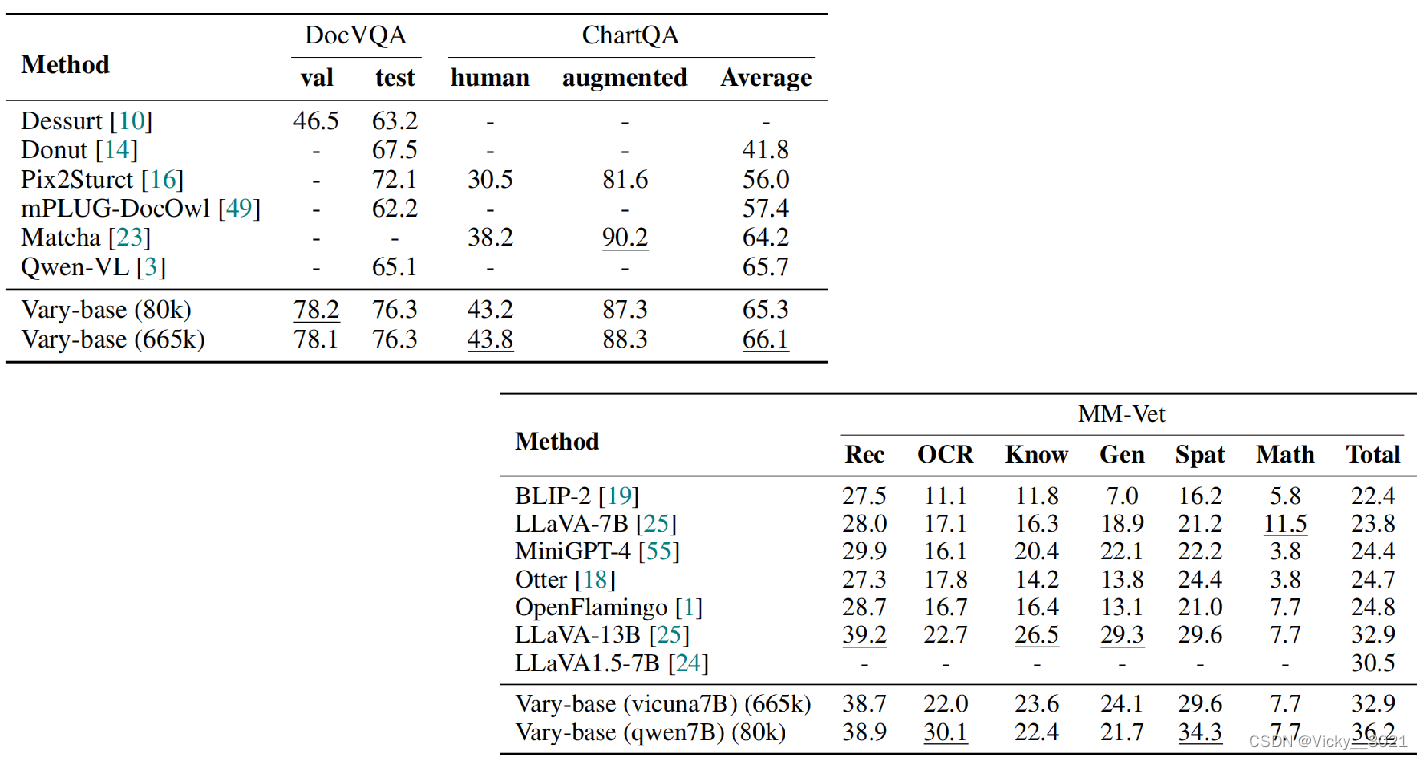
在下游任务中,与DocVQA和ChartQA上流行的方法的比较。Vary-base(以Qwen-7B为LLM)可以在DocVQA上实现78.2%(测试)和76.3%(验证)的ANLS,基于LLaVA-80k的SFT数据。使用LLaVA-665k数据进行SFT,Vary-base可以在ChartQA上达到66.1%的平均性能。这两个具有挑战性的下游任务的性能与Qwen-VL相当,甚至更好,这表明我们提出的视觉词汇扩大方法对下游也有前景。
通过MMVet基准测试监控Vary的一般性能。使用相同的LLM(Vicuna-7B)和SFT数据(LLaVA-CC665k),Vary比LLaVA-1.5提高了2.4%(32.9% vs. 30.5%)的总指标,证明我们的数据和训练策略不会损害模型的一般能力。此外,Vary配合Qwen-7B和LLaVA-80k可以实现36.2%的性能,进一步证明了我们的视觉词汇扩大方式的有效性。




本文强调了扩展LVLM视觉分支的词汇量是非常重要的,并成功地设计了一个简单的方法来证明这一说法。实验表明,所提供的模型Vary在多任务中取得了不错的成绩,这主要得益于我们生成的新词汇。尽管Vary的表现令人满意,但我们认为如何有效地扩大视觉词汇量仍有很大的改进空间,特别是与成熟且相对简单的扩展文本词汇量的方法相比。我们希望Vary有用而高效的设计能够吸引更多的研究关注这一方向。
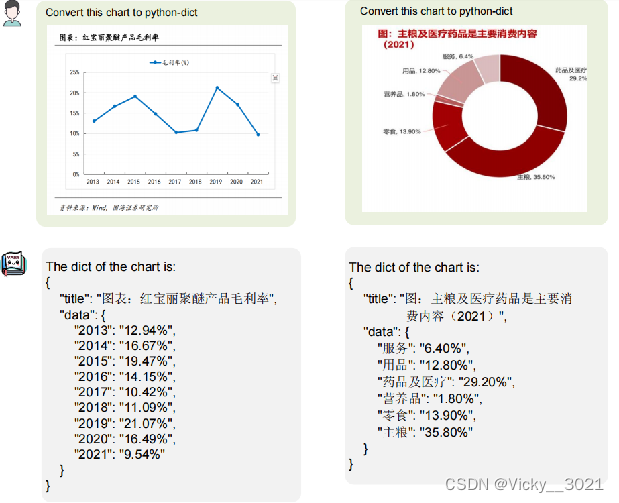
问题: 实际场景中的业务图片OCR效果一般,原因可能是模型训练过程中使用的数据大多数是论文或者是简单的文字图片等。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!