【halcon深度学习之那些封装好的库函数】split_dl_dataset
前言
在上两篇文章中,我们讲到了两个函数。
read_dl_dataset_classification 用于获取一个数据集,对于halcon来说就是一个字典:

halcon获取数据集的函数不止这一个方式,我还知道两个函数:
其一就是:read_dl_dataset_from_coco
这个函数,读取的是一个深度学习中通用的一种数据集,coco数据集
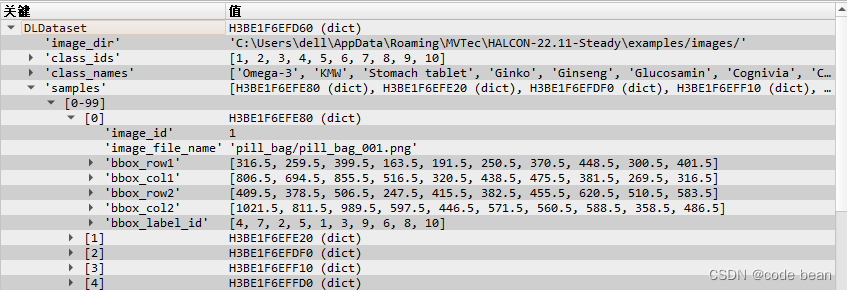
得到的也是一个结构相同的字典,唯一不同的是,samples里面多了一些标注框的信息!
其二,就是read_dict() 读取一个现成的halcon字典。但是这种符合深度学习的现成的字典那里来?这个可以通过halcon的一个深度学习工具进行导出!
接下来我们回归正题,得到了这个字典之后,我们需要干嘛?
其实之前的文章中以及指出了。

没错就是这个,split_dl_dataset,接下来我们就来分析这个函数的作用!
split_dl_dataset
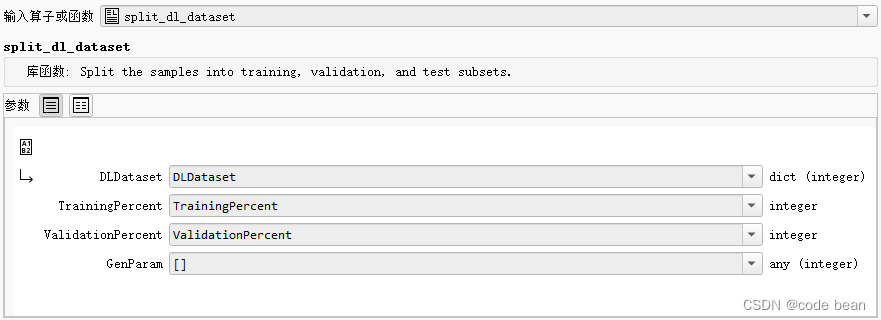
该过程会将每个样本分配到 ‘train’、‘validation’ 或 ‘test’ 中,并在每个样本中添加一个新的键 ‘split’,其值为 ‘train’、‘validation’ 或 ‘test’。
这里有个注意的地方,输出算子参数的时候 只需输入 ‘train’、‘validation’ 也就是训练和验证的比例。剩下的就是 ‘test’ 测试的比例。所以填写的时候 ‘train’ + ‘validation’ 要小于100% , 不如你就没有测试 'test’的比例了!
具体参数说明
split_dl_dataset 是一个用于将数据集分割成训练、验证和测试集的过程。以下是该过程的主要参数的解释:
-
DLDataset (input_control):
- 描述:包含关于数据集的信息的字典。
-
TrainingPercent (input_control):
- 描述:分配给训练数据集的样本的百分比。
- 默认值:60(表示60%的样本用于训练)。
- 取值范围:0.000000 ≤ TrainingPercent ≤ 100.000000。
-
ValidationPercent (input_control):
- 描述:分配给验证数据集的样本的百分比。
- 默认值:20(表示20%的样本用于验证)。
- 取值范围:0.000000 ≤ ValidationPercent ≤ 100.000000。
-
GenParam (input_control):
- 描述:用于指定非默认分割参数的字典。
- 默认值:[]。
GenParam字典可能包含以下键:-
‘overwrite_split’ (string):
- 描述:如果样本中已经包含 ‘split’ 键,是否覆盖它而不是返回警告。
- 默认值:‘false’。
-
‘model_type’ (string):
- 描述:指定数据集用于哪种模型,包括 ‘classification’、‘detection’、‘segmentation’、‘anomaly_detection’ 或 ‘gc_anomaly_detection’。
- 默认值:根据 DLDataset 中是否可能存在某些键来猜测模型类型。可能的键包括:
- ‘anomaly_label’:猜测为 ‘anomaly_detection’ 和 ‘gc_anomaly_detection’。
- ‘bbox_label_id’:猜测为 ‘detection’。
- ‘image_label_id’:猜测为 ‘classification’。
- ‘segmentation_dir’:猜测为 ‘segmentation’。
该过程会将每个样本分配到 ‘train’、‘validation’ 或 ‘test’ 中,并在每个样本中添加一个新的键 ‘split’,其值为 ‘train’、‘validation’ 或 ‘test’。如果样本已经包含 ‘split’ 键,过程会返回警告,但可以使用 GenParam 覆盖。
分析总结
* Preprocess the data in DLDataset.
split_dl_dataset (DLDataset, 60, 20, [])
在运行了这句之后,就会发现每个sample中就会多一个"split"标签, 来表明这个对象是属于 ‘train’、‘validation’ 还是 'test’的。
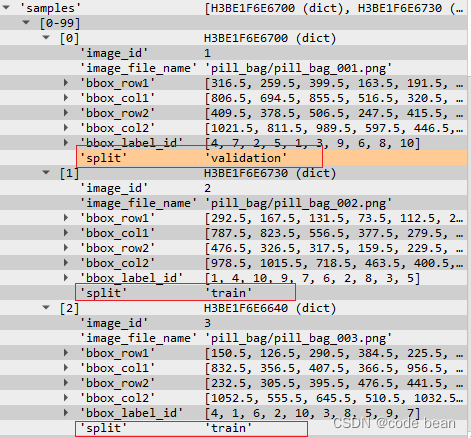
GenParam 就是分配时有自己的一套逻辑,这个GenParam 参数会影响分配的逻辑。
对字典进行拆分(split_dl_dataset)之后才是 determine_dl_model_detection_param
所以,目前的流程为,读取样本字典,然后对样本拆分,然后根据已拆分的字典。生成一些高级参数。以供后续训练等步骤使用。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!