深入理解 Hadoop (三)HDFS文件系统设计实现
HDFS FileSystem NameNode 端抽象实现
HDFS 磁盘元数据文件解读
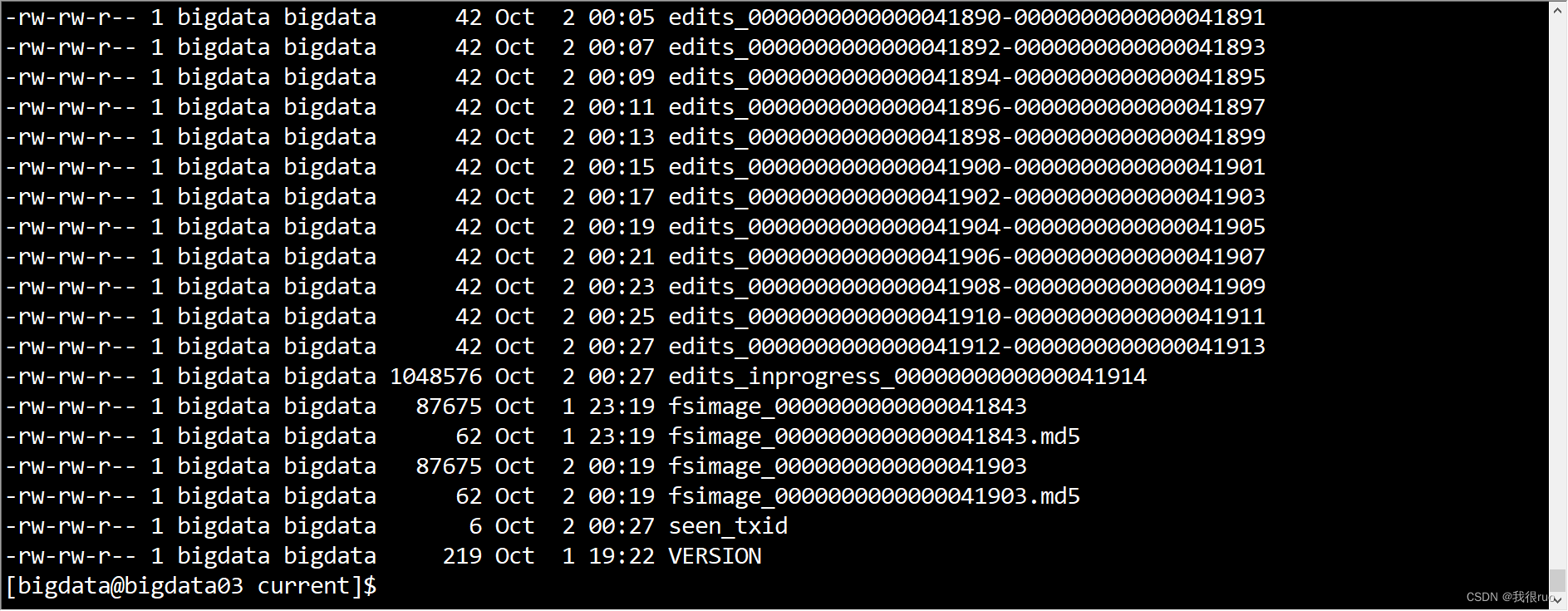
共有五种格式的文件:
edits_0000000000000041912-0000000000000041913:该 LogSegment 记录了 transaction id 在 41912-41913 之间的事务日志。(最多保留 50 个)
edits_inprogress_0000000000000041914:正在使用的 编辑日志文件,从 transaction id = 41914 开始,之后的事务都往这个文件中进行记录,直到进行了 rollLog 操作:生成一个新的 edits_inprogress_start_transaction_id 文件,把旧的 edits_inprogress_start_transaction_id 改名成 edits_(start_transaction_id)_(end_transaction_id) 。
fsimage_0000000000000041843 和 fsimage_0000000000000041843.md5:transaction id = 41843 以前的事务,都合并到了这个 fsimage 文件中了,.md5 文件存储了它的校验信息(最多保留 2 个)
seen_txid:存储最新的 fsimage 文件的 最新的 transaction id
VERSION:版本信息
HDFS FileSystem NameNode 内部结构
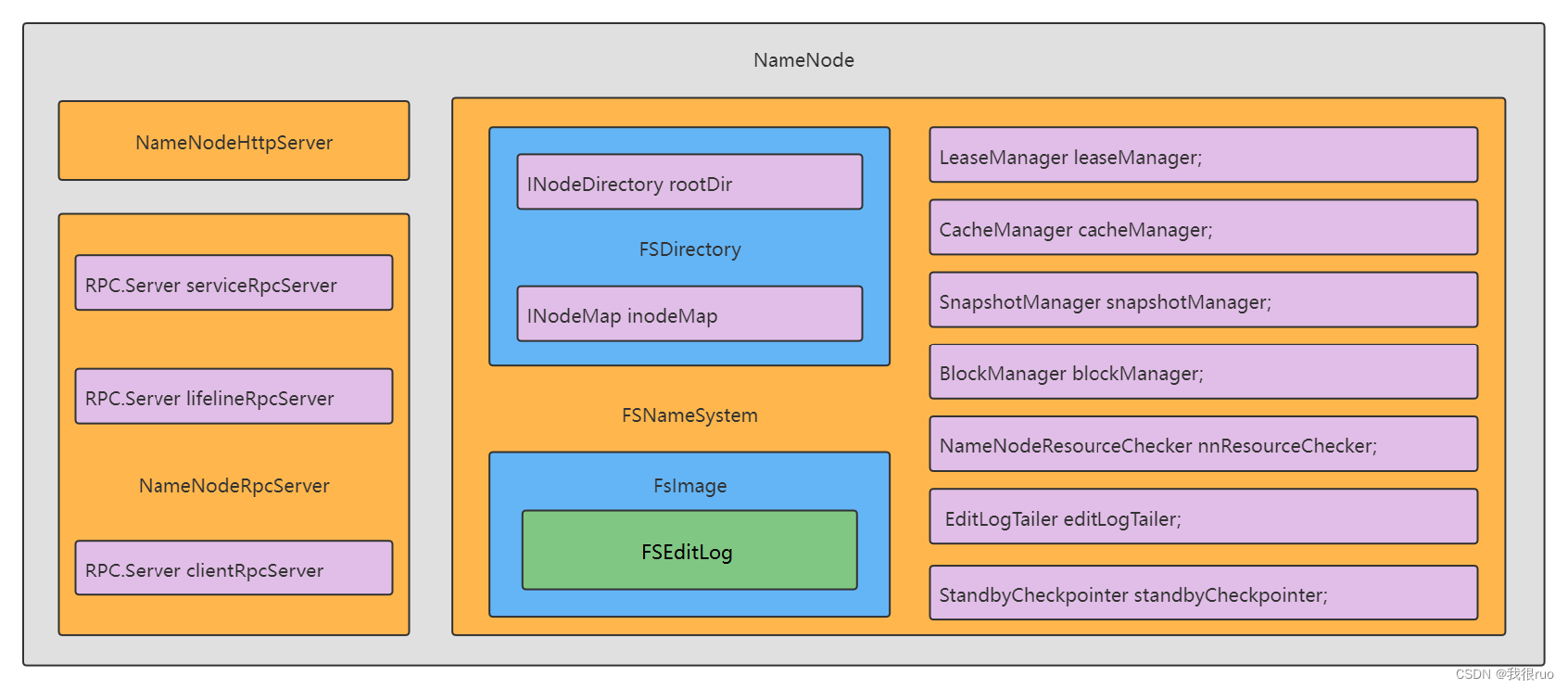
类比 ZooKeeper 存储模型中的 DataTree + DataNode,NameNode 内存树抽象为 FSDirectory + INode(两个实现类:INodeDirectory: 内部有一个集合 List< INodeDirectory> 或 INodeFile + 文件内部 List< Block>),每个 INode 内部有维护有一个 INode parent。
NameNode 元数据内存部分
也即 FSDirectory 维护的名称空间
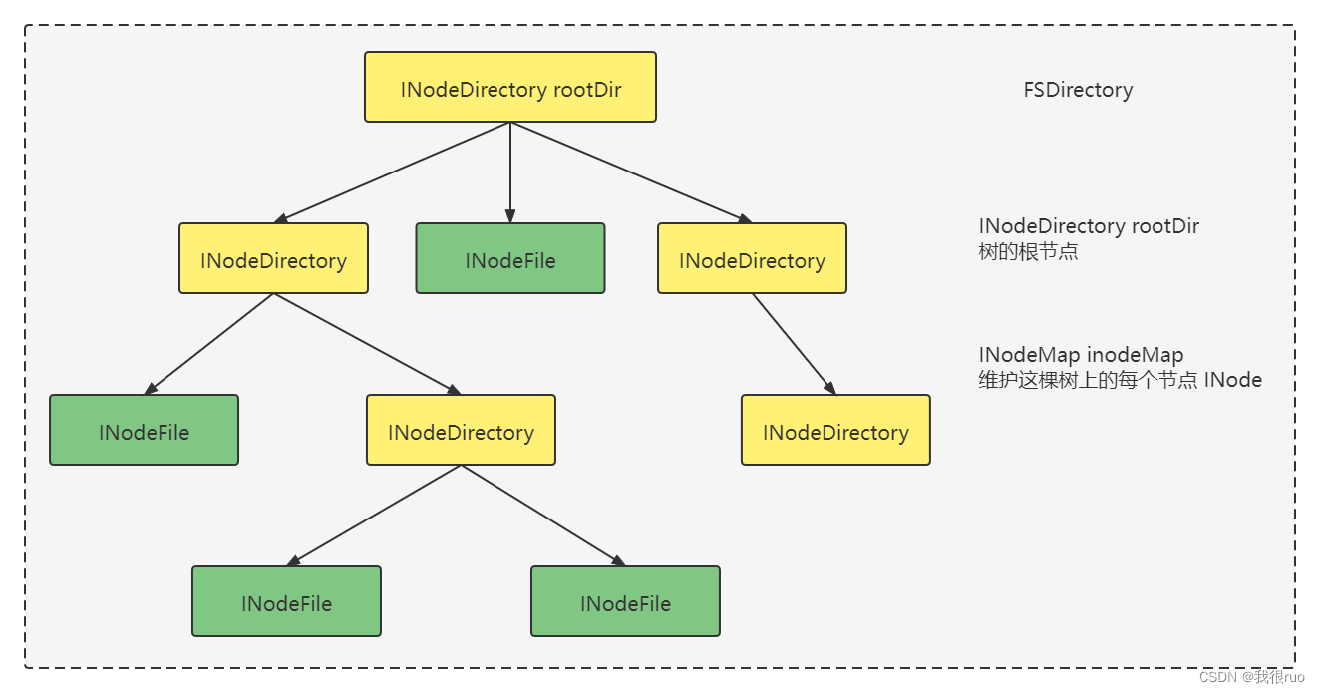
上图涉及到的核心抽象:
- FileSystem:具体实现: DistributedFileSystem、LocalFileSystem、FSNameSystem
- FSDirectory
- INode(INodeDirectory + INodeFile)
- FSImage
- FSEditlog
NameNode 磁盘部分核心抽象
public class FSImage implements Closeable {
// 管理磁盘编辑日志
protected FSEditLog editLog = null;
// 管理存储目录
protected NNStorage storage;
// 元数据存储目录格式化
void format(...) throws IOException {}
// 加载磁盘编辑日志恢复到内存
long loadEdits(...) throws IOException {}
// 加载磁盘 fsimage 镜像文件恢复到内存
void loadFSImage(....) throws IOException {}
// 生成 fsimage 镜像文件
void saveFSImage(...) throws IOException {}
// 保存命名空间
void saveNamespace(...) throws IOException {}
// 接收到 SecondaryNameNode 发送的要进行 checkpoint 的请求之后执行的操作
NamenodeCommand startCheckpoint(...) throws IOException {
CheckpointSignature sig = rollEditLog(layoutVersion);
return new CheckpointCommand(sig, needToReturnImg);
}
}
public class FSEditLog implements LogsPurgeable {
// dfs.namenode.shared.edits.dir 目录 = qjournal://bigdata02:8485;bigdata03:8485;bigdata04:8485/hadoop330ha
private final List<URI> editsDirs;
// dfs.namenode.shared.edits.dir 目录 = qjournal://bigdata02:8485;bigdata03:8485;bigdata04:8485/hadoop330ha
private final List<URI> sharedEditsDirs;
private JournalSet journalSet = null;
EditLogOutputStream editLogStream = null;
// 事务控制
private long beginTransaction() {}
private void endTransaction(long start) {}
// 记录日志操作, 记录一条日志到 edit_inprogress 文件里面
void logEdit(final FSEditLogOp op) {}
synchronized void logEdit(final int length, final byte[] data) {}
// 开启一个新的编辑日志 LogSegment
void startLogSegment() throws IOException {}
}
HDFS FileSystem DataNode 端抽象实现
HDFS DataNode 磁盘数据文件解读
HDFS DataNode 支持多磁盘存储,通过以下配置生效:
<property>
<name>dfs.datanode.data.dir</name>
<value>dir1,dir2,dir3</value>
</property>
数据目录下的目录结构如下:
- dir1
- blockpool 1
- current
- finalized 已写成功的数据块的存储目录
- 还会划分两级存储目录,然后再存数据块
- rbw 正在执行写操作的数据块
- layzpresistent:懒持久化,可以配置,写入数据块的时候,先写到内存中,然后到某了合适的时间,再持久化到磁盘
- finalized 已写成功的数据块的存储目录
- tmp
- current
- blockpool 2
- blockpool 1
- dir2
- blockpool 1
- blockpool 2
- dir3
- blockpool 1
- blockpool 2
注意:每个 blockpool 对应联邦集群中的一个 NameService
DataNode 的每个数据存储目录结构示例如下:
// 这个 current 就表示是某一个 配置的存储目录(dir1, dir2, dir3 的其中之一)
├── current
// 块池目录
├── BP-2052521754-192.168.123.102-1614493867466
├── BP-2052521754-192.168.123.102-1614493867477
│ ├── current
│ │ ├── dfsUsed
│ │ ├── finalized
│ │ │ └── subdir0
│ │ │ ├── subdir0
│ │ │ ├── subdir1
│ │ │ ├── subdir10
│ │ │ │ ├── blk_1073744394
│ │ │ │ ├── blk_1073744394_3617.meta
│ │ │ │ ├── blk_1073744618
│ │ │ │ └── blk_1073744618_3841.meta
│ │ │ ├── subdir11
│ │ │ │ ├── blk_1073744640
│ │ │ │ ├── blk_1073744640_3863.meta
│ │ │ │ ├── blk_1073744892
│ │ │ │ └── blk_1073744892_4115.meta
│ │ │ ├── subdir12
│ │ │ │ ├── blk_1073744948
│ │ │ │ ├── blk_1073744948_4171.meta
│ │ │ │ ├── blk_1073745141
│ │ │ │ └── blk_1073745141_4375.meta
│ │ │ ├── subdir2
│ │ │ ├── subdir3
│ │ │ ├── subdir4
│ │ │ ├── subdir5
│ │ │ ├── subdir6
│ │ │ ├── subdir7
│ │ │ ├── subdir8
│ │ │ │ ├── blk_1073744026
│ │ │ │ ├── blk_1073744026_3243.meta
│ │ │ │ ├── blk_1073744038
│ │ │ │ └── blk_1073744038_3261.meta
│ │ │ └── subdir9
│ │ │ ├── blk_1073744252
│ │ │ ├── blk_1073744252_3475.meta
│ │ │ ├── blk_1073744377
│ │ │ └── blk_1073744377_3600.meta
│ │ ├── rbw
│ │ └── VERSION
│ ├── scanner.cursor
│ └── tmp
└── VERSION
├── in_use.lock
上述目录结构的一些相关解释:
BP-2052521754-192.168.123.102-1614493867477:在 HDFS Fedaration 集群中,有多个NameSpace,对应多组 NameNode,每一组 NameNode 都有一个独立的 BlockPool 块池,一个 BlockPool 块池目录保存了 该 BlockPool 在当前存储目录中的所有数据块。
VERSION:版本文件,该文件是一个标准的 Properties 文件,可自行查看
finalized:数据块存储目录,保存的是写入成功的数据块,包含数据块文件和 .meta 校验文件
rbw:数据块存储目录,保存的是正在写入的数据块,包含数据块文件和 .meta 校验文件
tmp:数据块存储目录
scanner.cursor:DataNode 对数据块进行校验的一个遍历游标,用来记录此时遍历到的数据块的位置
in_use.lock:DataNode 线程持有的目录锁,防止多线程对该文件夹进行修改操作
DataStorage 抽象
DataStorage 管理与组织磁盘存储目录。
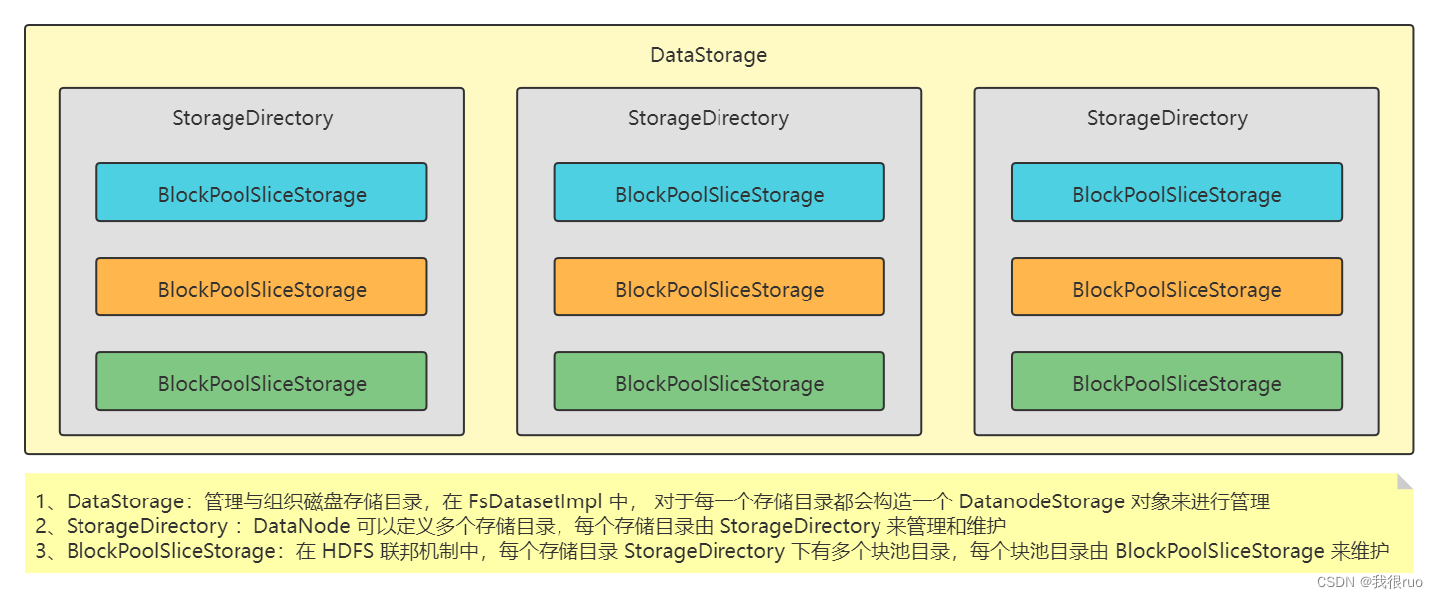
public abstract class Storage extends StorageInfo {
// 一个 DataNode 可以配置多个存储目录
private final List<StorageDirectory> storageDirs = new CopyOnWriteArrayList<>();
}
public class DataStorage extends Storage {
public final static String BLOCK_SUBDIR_PREFIX = "subdir";
final static String STORAGE_DIR_DETACHED = "detach";
public final static String STORAGE_DIR_RBW = "rbw";
public final static String STORAGE_DIR_FINALIZED = "finalized";
public final static String STORAGE_DIR_LAZY_PERSIST = "lazypersist";
public final static String STORAGE_DIR_TMP = "tmp";
// BlockPoolSliceStorage 负责管理块池目录
private final Map<String, BlockPoolSliceStorage> bpStorageMap = Collections.synchronizedMap(
new HashMap<String, BlockPoolSliceStorage>());
}
FsDatasetImpl 抽象
管理和组织 DataNode 上的数据块及其元数据。
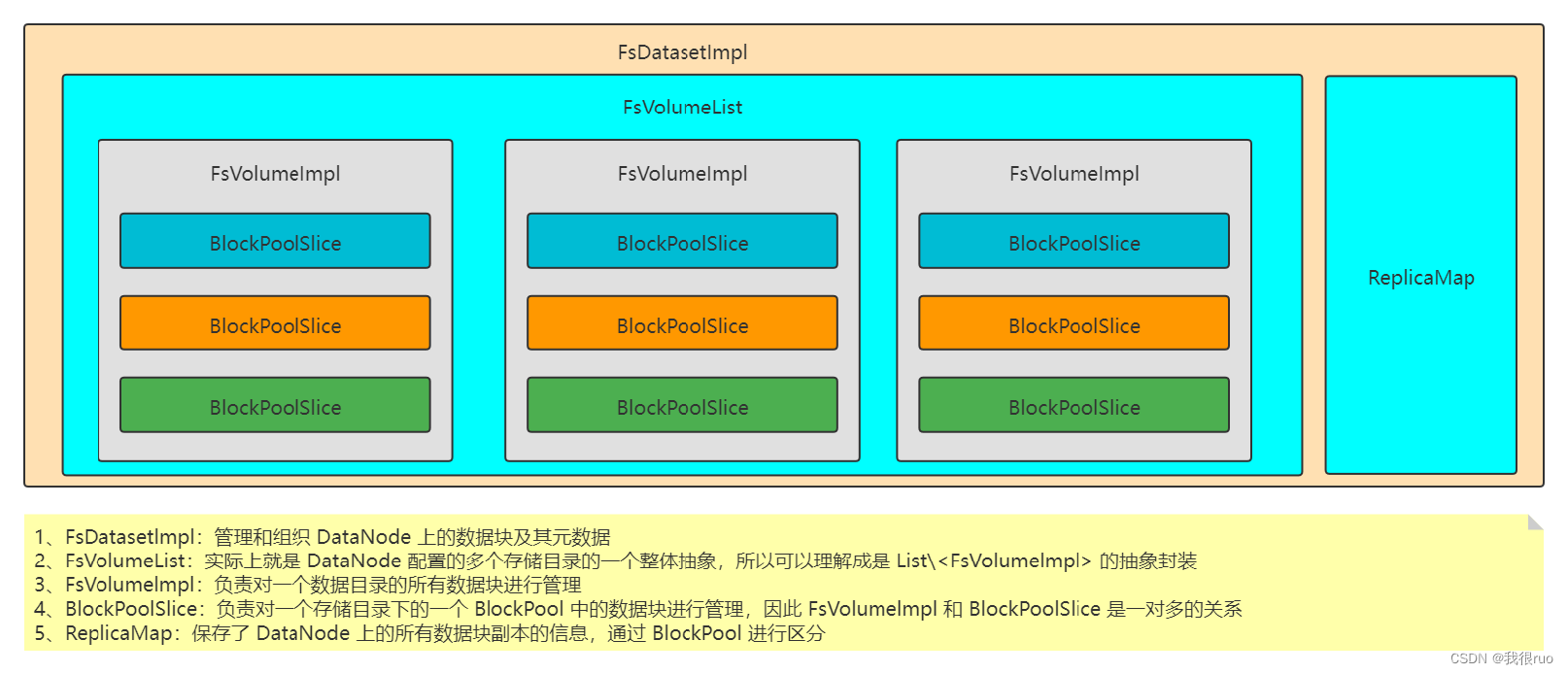
// FsDatasetImpl 负责为 DataNode 提供磁盘服务
class FsDatasetImpl implements FsDatasetSpi<FsVolumeImpl> {
// DataNode 上的所有数据块的一个管理载体
final ReplicaMap volumeMap;
// 存储目录管理组件
private final FsVolumeList volumes;
}
// FsVolumeList 就是对多个存储目录 FsVolumeImpl 的一个封装抽象
class FsVolumeList {
private final CopyOnWriteArrayList<FsVolumeImpl> volumes = new CopyOnWriteArrayList<>();
}
// 一个 FsVolumeImpl 负责管理一个存储目录下的所有数据块,一个存储目录下又有多个块池,所以映射到多个 BlockPoolSlice 来进行管理
public class FsVolumeImpl implements FsVolumeSpi {
// 记录存储位置信息
private final StorageLocation storageLocation;
// 对应的数据块管理组件
private final FsDatasetImpl dataset;
// 一个 FsVolumeImpl 映射到多个块池,BlockPoolSlice 负责管理一个块池
private final Map<String, BlockPoolSlice> bpSlices = new ConcurrentHashMap<String, BlockPoolSlice>();
}
class ReplicaMap {
// 一个 BlockPool 一个 TreeSet
private final Map<String, FoldedTreeSet<ReplicaInfo>> map = new HashMap<>();
}
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!