selenium 元素定位总结篇
一、By类单一属性定位
| 元素名称 | 描述 | Webdriver API |
|---|---|---|
| id | id属性 | driver.find_element(By.ID, "id属性值") |
| name | name属性 | driver.find_element(By.NAME, "name属性值") |
| class_name | class属性 | driver.find_element(By.CLASS_NAME, "class_name属性值") |
| tag_name | 标签名 | driver.find_element(By.TAG_NAME, "标签名") |
| link_text | a元素的文本内容-精准匹配 | driver.find_element(By.LINK_TEXT, "超链接全部文本值") |
| partial_link_text | a元素的文本内容-模糊匹配 | driver.find_element(By.PARTIAL_LINK_TEXT, "超链接部分文本值") |
- id定位
- 特点:
id定位 是通过元素的id属性来定位元素的;在整个HTML文档中id属性必须是唯一的。(APP中id属性不唯一) - 前提:元素有
id属性 - 说明:当目标元素存在
id属性值时,优先使用id方法定位元素,前提id不是动态变化的。
- name定位
- 特点:
name定位是根据元素name属性来定位的;在HTML文档中name的属性值是可以重复的
注意:当页面内有多个元素的特征值是相同的时候,定位元素的方法执行时,默认只会获取第一个符合要求的特征对应的元素。
因此,定位元素时需要尽量保证使用的特征值能够代表目标元素在当前页面的唯一性。
- class name 定位
- 特点:
class_name定位是根据元素class属性值来定位元素;HTML通过使用class来定义元素的样式,class属性值可以有多个。 - 前提:元素有
class属性
- 注意:在使用
class name方法时,如果**class**有多个属性值,只能使用其中的一个。
比如:class="panel-body has-table scrollbar-hover",只能使用其中一个值panel-body或者has-table或者scrollbar-hover,中间的空格代表间隔符,表示class有多个属性。
- tag name 定位
- 特点:
tag_name定位是通过**标签名**来定位的;HTML本质就是由不同的tag组成,每一种标签一般在页面中存在多个,所以不方便进行精确定位,一般很少使用。 - 说明:如果存在多个相同的标签,则返回符合条件的 第一个标签 。
- 由于标签名的重复性过高,一般做精确定位时,都不会选择
tag_name
- link test 定位
- 特点:
link_text定位是只针对超链接元素(< a>标签</a >,精确匹配),通过超链接的文本内容来定位元素的(超链接文本必须是唯一,不能有空格),并且需要输入超链接的全部文本信息。 - 案例:
element = driver.find_elementt("link test", '访问新浪网站')
- partial link text定位
- 特点:只针对超链接元素,需要输入超链接的部分文本信息。
- 案例:
element = driver.find_element("partial link text", '访问新浪') - 说明:
partial link text:a标签通过【模糊匹配】超链接文本,定位元素超链接文本必须是唯一。
二、xpath定位表达式汇总
2.1 xpath术语
2.1.1 节点
- XPath中的节点主要有以下几种类型:
- 元素节点 - 表示XML或HTML中的一个元素(也就是标签),如
<book>。 - 属性节点 - 表示元素的一个属性,如
<book category="computer">中的category属性。 - 文本节点 - 表示元素或属性中的文本内容,如
<book>Java</book>中的Java。 - 文档节点 - 表示整个文档,作为文档树的根节点。
- 命名空间节点 - 表示XML命名空间,通常是文档的子节点。
- 元素节点 - 表示XML或HTML中的一个元素(也就是标签),如
- 定位节点的方式:
- 通过路径表达式,如
book节点://book - 通过节点关系,如
parent、child等 - 通过顺序关系,如
following-sibling等
- 通过路径表达式,如
2.1.2 基本值
基本值(Atomic Value)指的是不能再分解的单个值,XML中的一些基本值包括:
- 字符串(String)
- 整数(Integer)
- 小数(Decimal)
- 布尔值(Boolean)
- 日期时间(Date/Time)
基本值就是XML文档中的终端节点,不再包含子元素。
例如:
<person> <name>John</name> <age>30</age> </person>
上述XML中:
- name和age元素中的"John"和"30"就是基本值
- 而person不是基本值,因为它还包含子元素
基本值有以下特点:
- 不可再分解为更小单元
- 没有属性或子元素
- 包含实际数据
2.2 节点关系
2.2.1 父(Parent)
每个元素以及属性都有一个父。
在下面的例子中,book 元素是 title、author、year 以及 price 元素的父:
<book> <title>Harry Potter</title> <author>J K. Rowling</author> <year>2005</year> <price>29.99</price> </book>
2.2.2 子(Children)
元素节点可有零个、一个或多个子。
在下面的例子中,title、author、year 以及 price 元素都是 book 元素的子:
<book> <title>Harry Potter</title> <author>J K. Rowling</author> <year>2005</year> <price>29.99</price> </book>
2.2.3 同胞(Sibling)
拥有相同的父的节点
在下面的例子中,title、author、year 以及 price 元素都是同胞:
<book> <title>Harry Potter</title> <author>J K. Rowling</author> <year>2005</year> <price>29.99</price> </book>
2.2.4 先辈(Ancestor)
某节点的父、父的父,等等。
在下面的例子中,title 元素的先辈是 book 元素和 bookstore 元素:
<bookstore> <book> <title>Harry Potter</title> <author>J K. Rowling</author> <year>2005</year> <price>29.99</price> </book> </bookstore>
2.2.5 后代(Descendant)
某个节点的子,子的子,等等。
在下面的例子中,bookstore 的后代是 book、title、author、year 以及 price 元素:
<bookstore> <book> <title>Harry Potter</title> <author>J K. Rowling</author> <year>2005</year> <price>29.99</price> </book> </bookstore>
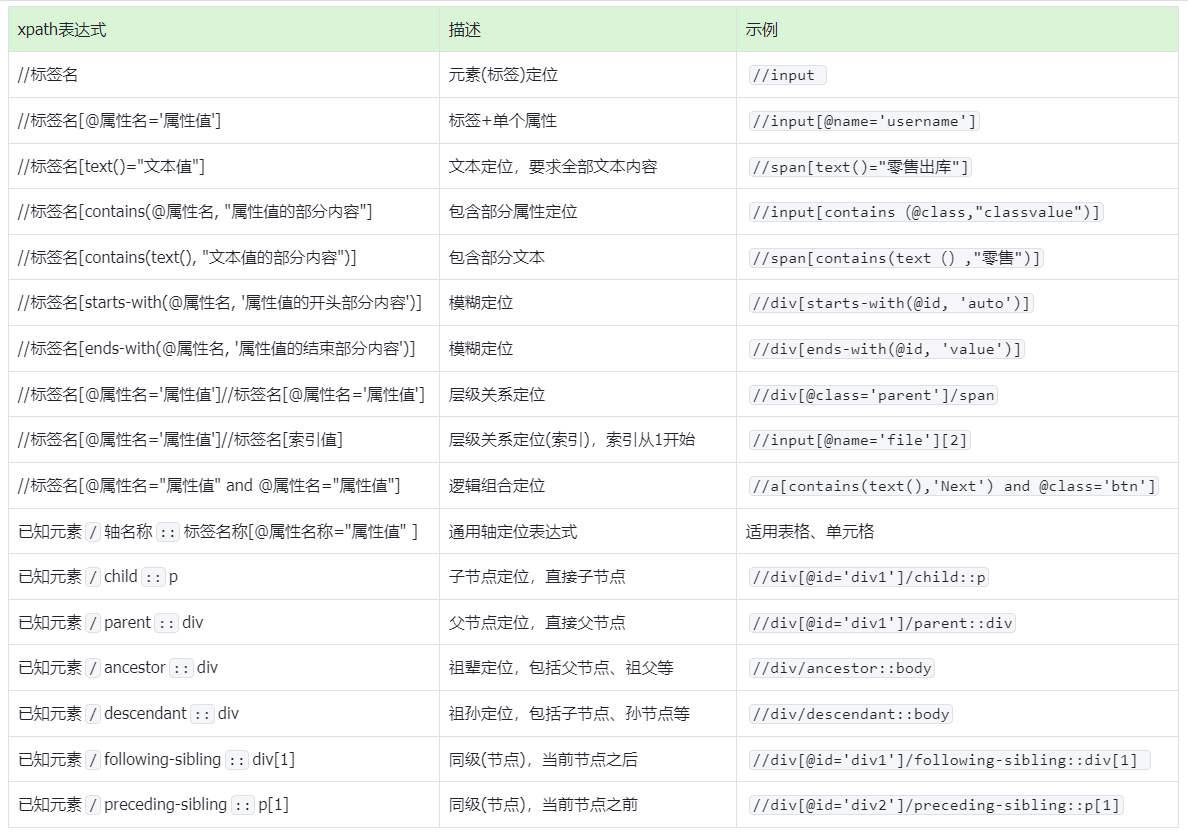
2.3 xpath定位表达式汇总
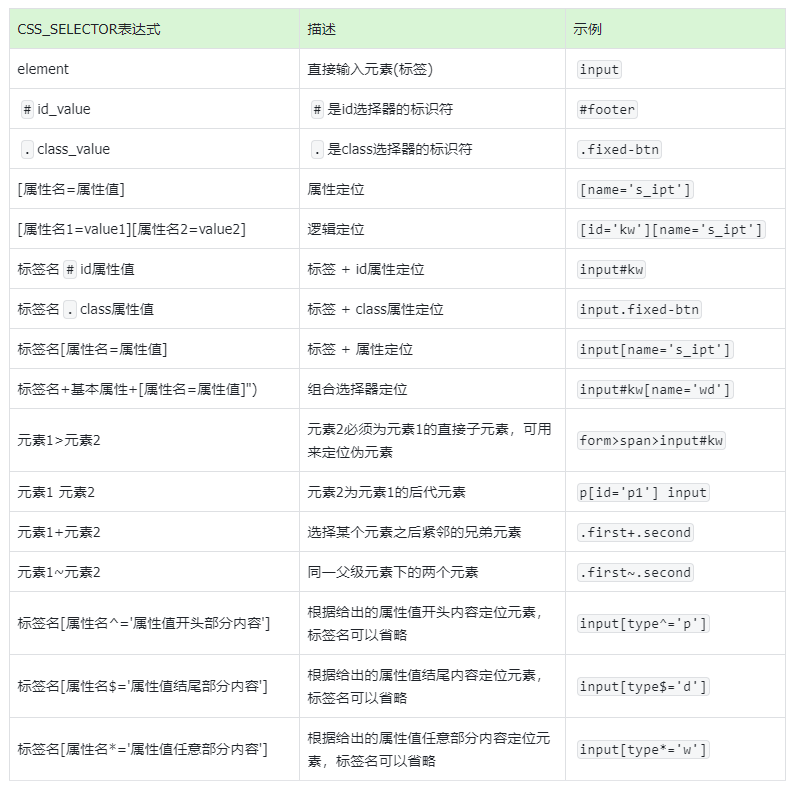
三、CSS选择器策略汇总
基本介绍:
- CSS(Cascading Style Sheets)是一种语言,它用来描述HTML元素的显示样式;
- 在CSS中,选择器是一种模式,用于选择需要添加样式的元素;
- 在Selenium中也可以使用这种选择器来定位元素。
- 在Selenium中推荐使用CSS定位(前提得会😂),因为它比XPath定位速度要快。
四、元素定位策略总结
- 如果元素有明确
id,name,class属性时,使用对应的基本定位方法。 - 如果没有
id,name,class属性时,或id,name,class属性是动态/不唯一的时候,使用XPath和css_selector定位。 - 定位页面超链接使用
link_text和partial_link_text定位 - 可使用
XPath和css_selector定位的时候,优先使用css_selector。css_selector定位的速度和效率比Xpath高。 - 没有最好的,只有最精简的,怎么简单怎么来。
五、selenium相关总结脑图大全


附带捎上一份selenium相关总结脑图
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!