行人重识别优化:Pose-Guided Feature Alignment for Occluded Person Re-Identification
文章记录了ICCV2019的一篇优化遮挡行人重识别论文的知识点:Pose-Guided Feature Alignment for Occluded Person Re-Identification
论文地址:
https://yu-wu.net/pdf/ICCV2019_Occluded-reID.pdf
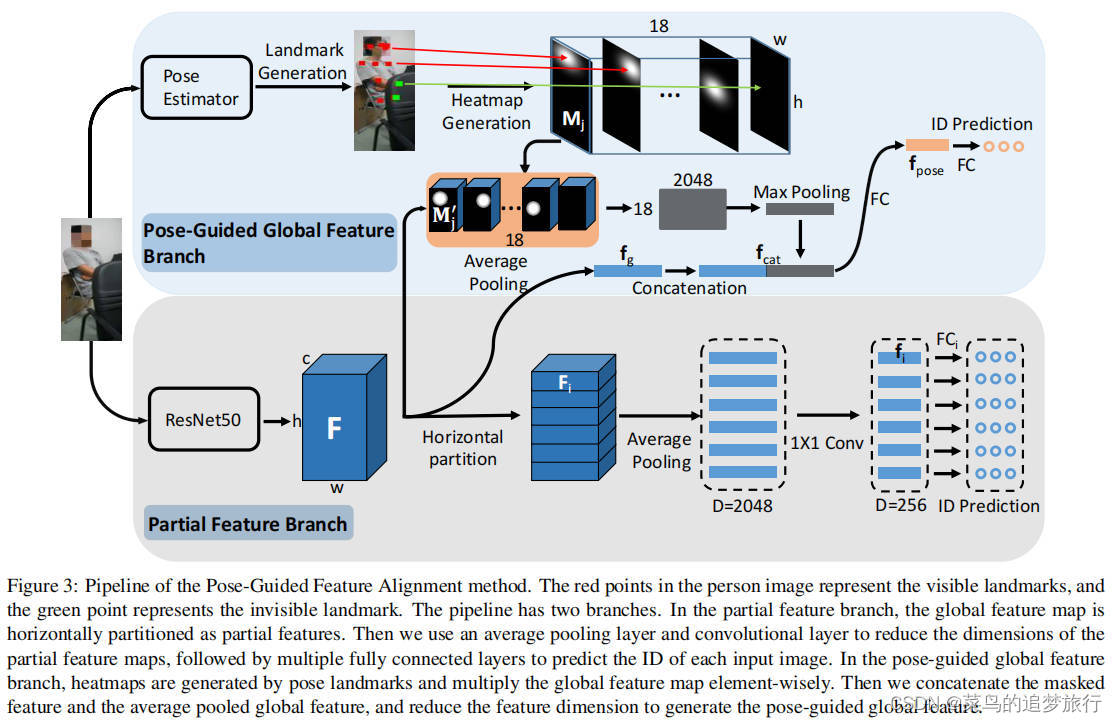
Partial Feature Branch分支:
PCB结构,将特征图F按照垂直方向水平划分为6个part,每个part引入一个分类损失。
从全局特征中提取局部(未遮挡)人体的特征。将input(输入图像的shape为3x384x128)经过Resnet50 之后的feature map直接做horizontal partition,再average pooling以及1*1 conv之后,将每一个part都预测一个id(id表示每个局部部分的身份标识。它用于将每个局部特征映射到相应的身份。
细节点:
1.代码中用的Resnet50模型去掉了中global average pooling及以后的部分。
2.将最后一层feature map 分成 p个horizontal stripes。分别对p个horizontal stripes做global average pooling就得到了p个局部特征。(horizontal stripes 的个数 p 取6。)
3.因为 Resnet50 最后一层feature map的通道数为2048,作者又用1x1 conv将其降到256维.
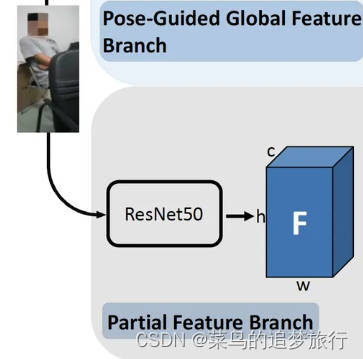
? 图1
图1中是全局特征提取,代码如下所示:
def extract_global_feature(model,input_):
output=model(input_)
return output
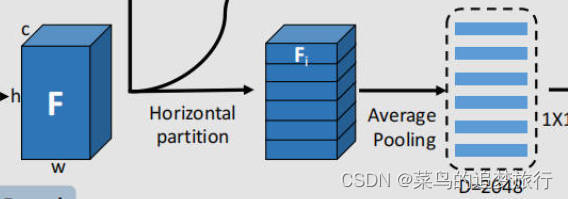
? 图2:partial特征
代码:
def extract_partial_feature(model,global_feature,part_num):
partial_feature=nn.AdaptiveAvgPool2d((part_num,1))(global_feature)
partial_feature=torch.squeeze(partial_feature,-1)
partial_feature=partial_feature.permute(0,2,1)
return partial_feature
partial_feature: torch.Size([32, 3, 2048]),表示一个批次中有32个样本,在每个样本中有3个局部部分(这里做说明,这个3就是part_num变量的值,源代码的权重中应该是设置为3了)的特征。每个局部部分的特征是一个长度为2048的向量。
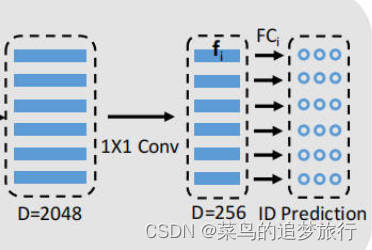
? 图3
这里用nn.Linear(线性层)将输入特征从 num_bottleneck (256维)维度映射到 class_num (应该是表示数据集中行人ID个数,源代码训练数据集中有702个ID)维度,线性层的输出可以被看作是一个概率分布,用于表示输入特征属于每个类别的可能性(这个输出并不是直接的概率分布,而是未经过归一化的原始分数)
具体代码:
# Defines the new fc layer and classification layer
# |--Linear--|--bn--|--relu--|--Linear--|
class ClassBlock(nn.Module):
def __init__(self, input_dim, class_num, relu=True, num_bottleneck=512):
super(ClassBlock, self).__init__()
add_block = []
add_block += [nn.Conv2d(input_dim, num_bottleneck, kernel_size=1, bias=False)]
add_block += [nn.BatchNorm2d(num_bottleneck)]
if relu:
#add_block += [nn.LeakyReLU(0.1)]
add_block += [nn.ReLU(inplace=True)]
add_block = nn.Sequential(*add_block)
add_block.apply(weights_init_kaiming)
classifier = []
classifier += [nn.Linear(num_bottleneck, class_num)]
classifier = nn.Sequential(*classifier)
classifier.apply(weights_init_classifier)
self.add_block = add_block
self.classifier = classifier
def forward(self, x):
x = self.add_block(x)
x = torch.squeeze(x)
x = self.classifier(x)
return x
Pose-Guided Global Feature Branch:
当一张query图像输入网络时候,预训练好的姿态估计模型会给出一个key points预测结果。然后对每个key point都生成一个heatmap。姿态估计模型预测时除了返回关键点的坐标之外还会返回一个置信度,对于置信度较低的关键点,可以认为该部分是处于遮挡状态中的。因此最后返回的heatmap,对于置信度很低的点,该点的heatmap应该是置0的。
将所有的heatmap叠加之后做max-pooling得到的feature vector和input经过resnet之后再max-pooling的feature vector 做concatenate,最后得到的feature vector即为该Pose-Guided分支的表征结果。用这个feature vector会得到一个id预测结果。
该分支具体代码:
def extract_pg_global_feature(model,global_feature,masks):
pg_global_feature_1=nn.AdaptiveAvgPool2d((1,1))(global_feature)
pg_global_feature_1=pg_global_feature_1.view(-1,2048)
pg_global_feature_2=[]
for i in range(18):
mask=masks[:,i,:,:]
mask= torch.unsqueeze(mask,1)
mask=mask.expand_as(global_feature)
pg_feature_=mask*global_feature
pg_feature_=nn.AdaptiveAvgPool2d((1,1))(pg_feature_)
pg_feature_=pg_feature_.view(-1,2048,1)
pg_global_feature_2.append(pg_feature_)
pg_global_feature_2=torch.cat((pg_global_feature_2),2)
pg_global_feature_2=nn.AdaptiveMaxPool1d(1)(pg_global_feature_2)
pg_global_feature_2=pg_global_feature_2.view(-1,2048)
pg_global_feature=torch.cat((pg_global_feature_1,pg_global_feature_2),1)
pg_global_feature=model(pg_global_feature)
return pg_global_feature
global_feature: torch.Size([32, 2048, 24, 8])
参考文章:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!