使用AutoDL训练YOLOV8
917的服务器一直连接超时 所以租了个autoDL的3090?
一、数据准备
1.原始数据集
- 7581开源
- 工地数据集来自师兄

共14620张?
210000 到217999 一共8000张是工地的(李师兄打的) 有hat和person、head??
待解决:工地上的图片 hat和head基本都检测出来了,但是很多person没有检测出来 所以我需要再对这8000张 用李师兄的权重重新跑一边
还有6620张 来自开源
2.重构数据集(12.17版本)
old:
0:person
1:hat
2:head
new:
0:person
1:personNoHat
参考:
1.增加数据集的分类
?YOLOv5在建筑工地中安全帽佩戴检测的应用(已开源+数据集) - 知乎 (zhihu.com)
2.merge_data.py
Smart_Construction/data/gen_data/merge_data.py at master · PeterH0323/Smart_Construction · GitHub
3.? 炮哥? ?vocToYolo
目标检测---数据集格式转化及训练集和验证集划分_bndbox-CSDN博客
4. yoloToVoc
方法一
Yolo标准数据集格式转Voc数据集_数据集转化为voc格式-CSDN博客
步骤:
本地代码 :E:\object detection\helmet_project\yolov5-6.1?
数据:E:\object detection\dataset\helmet和E:\object detection\helmet_project\yolov5-6.1的VOCdevkit*
(注意 目前只做了images(useful)1中一部分 截止到12月19号)
1.检测person??
yolov5?会推理出所有的分类,并在?inference/output?中生成对应图片的?.txt?标签文件;
(注意VOC2008已经改动 原本是跑了1608张图片 ? ?来自images(useful)1中前半部分开源的)
python detect.py --save-txt --source "E:\object detection\dataset\helmet\VOC2008\JPEGImages" --weights yolov5x.pt
结果在:E:\object detection\helmet_project\yolov5-6.1\runs\detect\exp8\labels
2.? vocToYolo(为了merge)
E:\object detection\helmet_project\yolov5-6.1\voctoyolo.py
classes = ["person"]
# classes=["ball"]
TRAIN_RATIO = 100
将E:\object detection\helmet_project\yolov5-6.1\VOCdevkit(12.17)\VOC2007\Annotations下的xml转成了E:\object detection\helmet_project\yolov5-6.1\VOCdevkit(12.17)\VOC2007\YOLOLabels
3.merge
E:\object detection\helmet_project\yolov5-6.1\merge_data.py
将YOLOV5_LABEL_ROOT (步骤1得到的)的txt 和DATASET_LABEL_ROOT(步骤2得到的)的txt? merge? ?是原地merge到?DATASET_LABEL_ROOT

4. yoloToXMl(为了打标签 以及和工地的一起划分)
E:\object detection\helmet_project\yolov5-6.1\yoloToVocNew.py
把3中得到的txt转为xml

5 jump到打标签
6.再次vocToYolo(划分训练集和测试集)

注意 换了文件夹
- xml都放到如下文件夹
- 对应的image放进去

3.打标签-labelimg
(12.17打标签到210684)
目标检测---利用labelimg制作自己的深度学习目标检测数据集_目标检测利用labeling制作-CSDN博客
E:\object detection\dataset\helmet\VOC2008

labelimg装在bytetrack环境中? ,然后去指定文件夹下 执行命令
注意这个按钮
一些标注rule
- 注意 无法判断的person(只有一只手 没有头部露出 肉眼分不清 ) 默认是戴了的 重点是将没带的挑出来
- 有时候只有一张脸(没戴帽子) 也可认为是没戴的 而不用全身
- 而且 原本无法判断帽子帽子是否戴在头上(拿在手里?)、是否规范佩戴 现在都可以解决了
- 安全帽没有黑色 但是对于戴了黑色帽子的建议标注为person
- 骑行头盔 不算!
- 对各种姿势的人标注 弯腰 蹲下 躺下
- 对只有一个人脸 yolov5x能认出来他是个人 所以我也标注?
- 主要区分了 草帽、保安、军人/警察的帽子、自行车头盔、毛巾
- 密集的图片删掉了 我的场景绝对不会很密集?


485.JPG
二、使用AutoDL训练
1.参考
1.yolov8官方文档??
2. 主要步骤
我使用的base环境
在AutoDL中使用YOLOV8训练自己的数据集-CSDN博客
配置:??
1.train.py? (或者使用命令
2.data.yaml
3. yolov8.yaml? ? 作者说“同时将yolov8n.yaml文件中的nc?改为nc=2,我的类别是两个” 但是现在版本
/root/autodl-tmp/ultralytics/ultralytics/cfg/models/v8/yolov8.yaml? ? ? 没有之前yolov8n.yaml
包含了 n s m l x? 后面改模型的时候再自己改吧

3. 其它
使用自定义数据集训练YOLOv8模型(基于AutoDL算力云平台,内附免费的源码、数据集和PYQT-GUI界面)-CSDN博客
手把手教你使用AutoDL云服务器训练yolov5模型-CSDN博客
云服务器训练YOLOv8-新手教程 - 哔哩哔哩 (bilibili.com)? ?迪菲赫尔曼 (没看)
4.YOLOv8
YOLOv8训练参数详解(全面详细、重点突出、大白话阐述小白也能看懂)-CSDN博客
三种训练模式
手把手实现 | 使用Yolov8训练自己的数据集【环境配置-准备数据集(采集&标注&划分)-模型训练(多种方式)-模型预测-模型导出】-CSDN博客
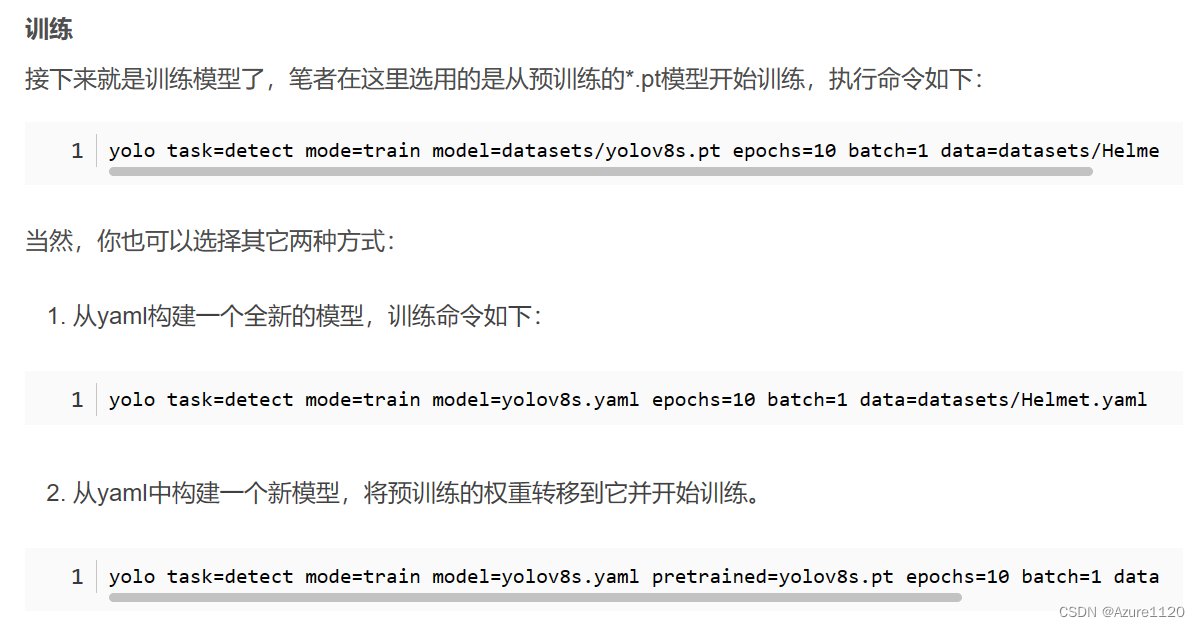
yolov8的train.py
第一个model没有用到预训练
第二个 就是pt
第三个 改了backbone以后用它!
from ultralytics import YOLO
# 加载一个模型
model = YOLO('yolov8n.yaml') # 从YAML建立一个新模型
model = YOLO('yolov8n.pt') # 加载预训练模型(推荐用于训练)
model = YOLO('yolov8n.yaml').load('yolov8n.pt') # 从YAML建立并转移权重
# (另一种解读) 从YAML加载 然后再加载权重
# 训练模型
results = model.train(data='coco128.yaml', epochs=100, imgsz=640)model: 模型文件的路径。这个参数指定了所使用的模型文件的位置,例如 yolov8n.pt 或 yolov8n.yaml。
选择.pt和.yaml的区别
.pt类型的文件是从预训练模型的基础上进行训练。若我们选择 yolov8n.pt这种.pt类型的文件,其实里面是包含了模型的结构和训练好的参数的,也就是说拿来就可以用,就已经具备了检测目标的能力了,yolov8n.pt能检测coco中的80个类别。假设你要检测不同种类的狗,那么yolov8n.pt原本可以检测狗的能力对你训练应该是有帮助的,你只需要在此基础上提升其对不同狗的鉴别能力即可。但如果你需要检测的类别不在其中,例如口罩检测,那么就帮助不大。
.yaml文件是从零开始训练。采用yolov8n.yaml这种.yaml文件的形式,在文件中指定类别,以及一些别的参数。
2.上传文件
最开始使用jupyterLab踩了大坑 、还可以使用网盘
最终使用Xshell?
3.解决RuntimeError
yolov8训练自己数据集遇到找不到yaml中路径问题-CSDN博客

1.使用绝对路径??
这个方法其实没问题? 而且会把settings.yaml中的ignore掉
但是lnb把datasets拼成了datesets 所以一直报错?
2.相对路径??
Yolov8训练自己数据集时出现的RuntimeError:DataSet ......error-CSDN博客
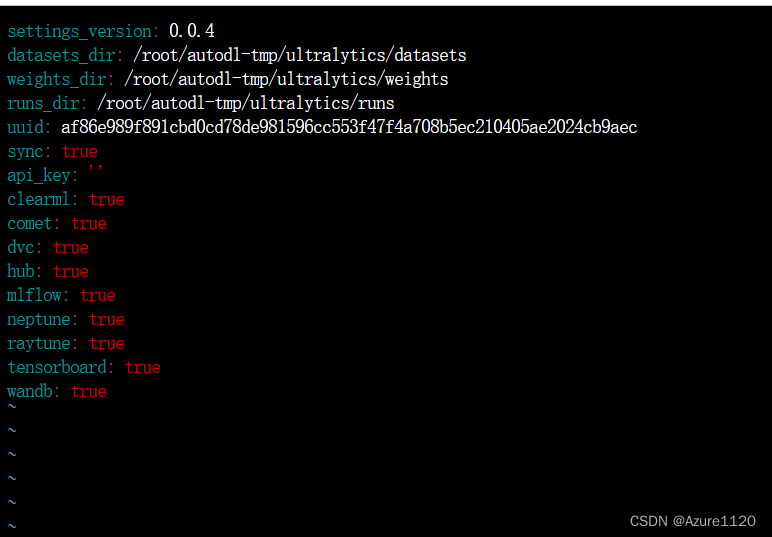
?vim ?/root/.config/Ultralytics/settings.yaml? 查看如下这样一个配置文件
其中datasets_dir 我修改了? 它会去这个地方去找数据集?然后拼上data.yaml中的train和val

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!