欠拟合与过拟合
2024-01-08 19:33:59
? ? ? ?在模型训练中,我们总是希望最终的模型在训练集上有很好的拟合即训练误差小,同时在测试集上也要有较好的拟合效果即泛化误差小,但往往不尽人意。
? ? ? ?总之,模型的训练是一个不断调整和优化的过程,我们需要根据实际情况选择合适的策略来解决欠拟合和过拟合问题,以提高模型的泛化能力和预测性能。
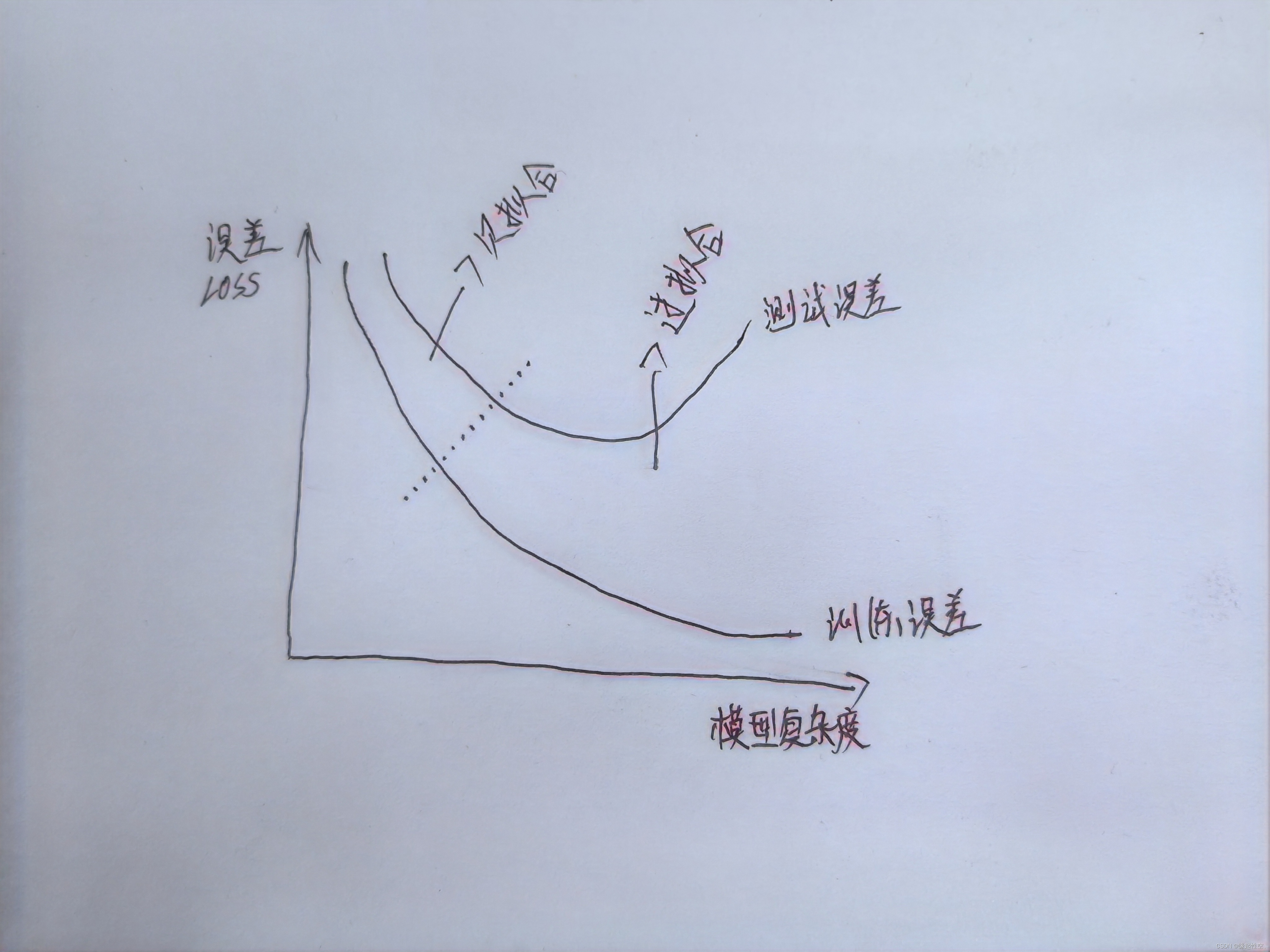
欠拟合
? ? ? ?欠拟合是指模型在训练数据上的性能不佳,并且在测试数据上的性能也不佳。具体来说,欠拟合是指模型过于简单,无法捕捉到数据中的复杂模式或特征,导致模型在训练和测试数据上的误差都较大。
常见原因
- 模型过于简单:如果模型过于简单,它可能无法捕获数据中的复杂模式或特征,导致在训练和测试数据上的性能不佳。
- 特征选择不当:如果数据特征选择不当,或者忽略了重要的特征,模型可能无法捕获数据中的复杂模式或特征,导致欠拟合。
- 训练数据不足:如果训练数据量太小,模型可能无法充分学习数据中的模式或特征,导致欠拟合。
- 优化算法不当:如果使用的优化算法不合适,例如使用不合适的优化器或学习率设置不当,可能导致模型无法充分优化,从而出现欠拟合。
解决思路
- 增加模型的复杂度:根据实际情况增加模型的复杂度,可以让模型更好地适应数据的复杂模式或特征。例如,增加神经网络的层数或节点数,或者使用更复杂的机器学习算法。
- 增加训练数据量:通过增加训练数据量,可以让模型更好地学习数据的模式或特征。
- 改进特征选择:通过改进特征选择,可以选择更重要的特征,或者增加更多的特征,让模型更好地适应数据的复杂模式或特征。
- 调整优化算法:选择合适的优化器、调整优化算法的参数,例如学习率、动量等,可以改善模型的优化效果,从而减少欠拟合的发生。
- 使用正则化技术:正则化技术,可以在损失函数中添加额外的项,以惩罚模型的复杂性。这样可以在训练过程中防止模型过拟合,并提高模型的泛化能力。常用的正则化技术包括L1正则化和L2正则化等。
过拟合
? ? ? ? 过拟合是指模型在训练数据上的性能很好,但在测试数据上的性能不佳。这是因为模型过于复杂,过度拟合了训练数据中的噪声和无关信息,导致无法泛化到新的、未见过的数据。
常见原因
- 模型复杂度过高:如果模型过于复杂,例如神经网络层数过多或节点数过多,它可能会学习到训练数据中的噪声和无关信息,导致在测试数据上的性能不佳。
- 训练数据量不足:如果训练数据量不足,模型可能无法充分学习数据的模式或特征,从而导致在测试数据上的性能不佳。
- 数据分布变化:如果训练数据和测试数据的分布不同,模型可能无法泛化到测试数据上,从而导致过拟合。
- 优化算法不当:如果使用的优化算法不合适,例如学习率设置不当或使用了不合适的优化器,可能导致模型无法充分优化,从而出现过拟合。
解决思路
- 简化模型:通过简化模型,降低模型的复杂度,可以减少对训练数据中的噪声和无关信息的拟合,从而提高模型的泛化能力。例如,减少神经网络的层数或节点数。
- 增加训练数据量:通过增加训练数据量,可以让模型更好地学习数据的模式或特征,从而减少过拟合的发生。
- 数据增强:通过技术手段对训练数据进行扩充和增强,可以增加模型的泛化能力,从而减少过拟合的发生。例如,使用随机裁剪、旋转等方法对图像数据进行增强。
- Dropout技术:Dropout是一种技术,在训练过程中随机将神经网络中的一部分节点置为0,从而减少模型的复杂性和过拟合的发生。Dropout可以通过随机关闭神经网络中的一部分节点来防止神经网络中的某些特征只依赖某些特定的节点。
- 正则化技术:正则化技术,可以在损失函数中添加额外的项,以惩罚模型的复杂性。常用的正则化技术包括L1正则化和L2正则化等。这些技术可以帮助防止模型过拟合,并提高模型的泛化能力
- 早停法:早停法是一种技术,在验证损失不再显著下降时停止训练模型。这样可以防止模型在训练数据上过拟合,从而提高泛化能力。早停法可以与Dropout等技术结合使用,进一步减少过拟合的发生。
正则化技术
? ? ? ?正则化是指通过添加一个额外的损失函数项,以约束模型的参数,防止模型过拟合训练数据,从而提高模型的泛化能。以L1正则化和L2正则化为例,都是通过在损失函数中添加一个正则化项来实现。不同的是L1正则化向损失函数中添加了所有参数的绝对值之和,而L2正则化向损失函数中添加了所有参数的平方和。这两种正则化技术的不同之处在于它们惩罚模型参数的方式不同。
示例?
以Keras框架模型为例
from keras.models import Sequential
from keras.layers import Dense
#创建模型
model = Sequential()
#添加一个全连接层,输入维度为10,激活函数为ReLU
model.add(Dense(64, input_dim=10, activation='relu'))
#添加一个全连接层,输出维度为1,激活函数为Sigmoid
model.add(Dense(1, activation='sigmoid'))
#编译模型,添加正则化项
#regularization_loss_factor参数用于控制正则化项的系数,取值范围为0到1之间
#如果取值为0,表示不使用正则化
#如果取值为1,表示使用与损失函数等效的正则化项
#其他值表示使用介于0和1之间的权重来平衡正则化项和损失函数项
#设置损失函数为二元交叉熵,优化器为Adam,正则化项系数为0.01
model.compile(loss='binary_crossentropy', optimizer='adam', regularization_loss_factor=0.01)
#训练模型
model.fit(X_train, y_train, epochs=10, batch_size=32)
文章来源:https://blog.csdn.net/lymake/article/details/135463116
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!